


On this article, you’ll discover ways to apply a structured choice tree to decide on the best agentic design sample for any AI system you might be constructing.
Subjects we are going to cowl embrace:
- Why sample choice is a important design choice, and what assumptions underlie every main agentic design sample.
- A five-question choice tree that maps concrete activity properties to probably the most applicable beginning sample.
- Widespread failure alerts for every sample and the focused fixes that handle them.
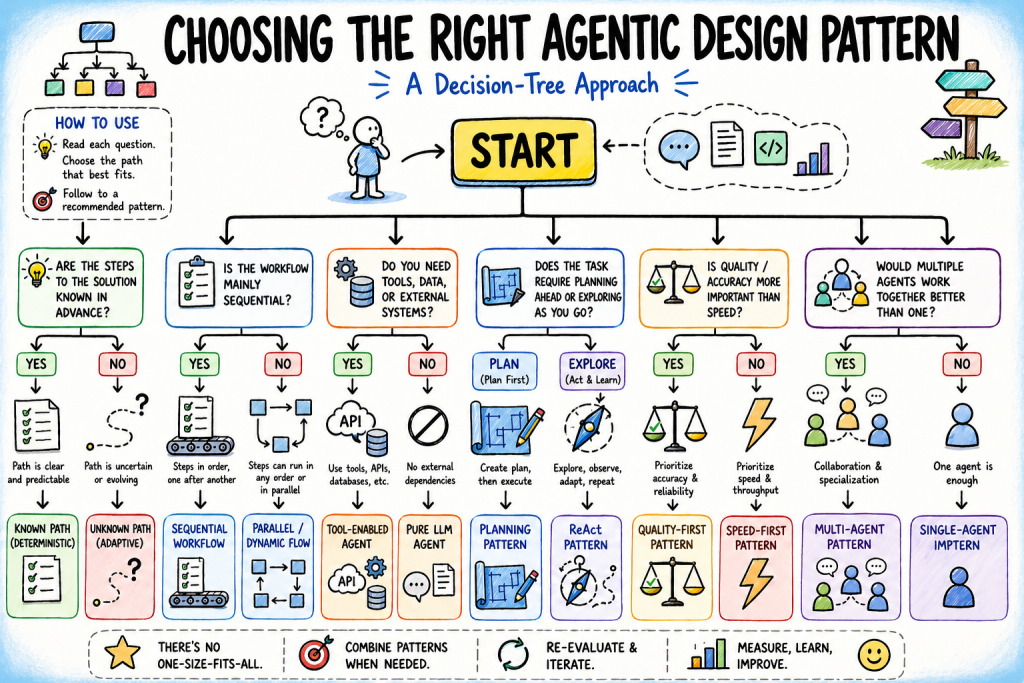
Selecting the Proper Agentic Design Sample: A Resolution Tree Method (click on to enlarge)
Introduction
Most agentic structure errors begin with a easy misinterpret of the issue. Builders usually decide a sample based mostly on what seems spectacular or acquainted, not what the duty really wants. A multi-agent system from a chat can seem like the “proper” reply, so that they spend weeks constructing orchestration for one thing a single well-prompted agent with a few instruments may deal with in a day. Or they go the opposite route, hold issues too easy, and solely uncover in manufacturing that the system can’t adapt or scale, forcing a redesign beneath strain.
Sample choice is the place the actual design work occurs. The agentic design patterns themselves are nicely documented. What’s much less documented is the choice logic for selecting between them. That logic is what this text is about.
The method here’s a choice tree: a collection of questions on your activity, your constraints, and your acceptable trade-offs that leads you to the best beginning sample. The tree doesn’t produce a closing reply; agent architectures evolve as suggestions accumulates. However it offers you a principled start line, and it makes the reasoning behind your alternative clear sufficient to revisit when issues change.
Why Is Agentic Design Sample Choice Necessary?
Earlier than working by means of the choice tree, it is very important clearly outline what’s at stake when choosing a design sample.
Every agentic design sample is predicated on particular assumptions in regards to the construction and calls for of a activity. Listed below are a few of them:
- ReAct sample treats the following finest motion as not absolutely knowable upfront, and depends on combining reasoning with device use at every step to enhance selections.
- Planning is predicated on the concept that the foremost construction of the duty could be recognized upfront, and that defining an execution roadmap improves downstream reliability.
- Reflection sample is grounded within the expectation that first-pass outputs are sometimes incomplete or flawed, and that iterative self-critique and refinement enhance closing high quality sufficient to justify the added value.
- Multi-agent approaches function on the assumption that the duty advantages from decomposition into specialised roles, the place parallel or modular execution outweighs the overhead of coordination.
When these assumptions match the duty, the sample provides actual worth. After they don’t, it provides overhead with out enhancing outcomes. As an illustration, planning can develop into inflexible when activity construction solely emerges throughout execution, reflection can waste sources on easy queries, and multi-agent setups can add pointless complexity for issues a single agent can clear up.
The choice tree beneath helps information deliberate sample choice. Every department displays a key activity property that determines which assumptions really maintain.
Additional studying on agentic design patterns: The Roadmap to Mastering Agentic AI Design Patterns
A Resolution Tree for Selecting the Proper Agentic Design Sample
The tree has 5 branching questions, each narrowing the sample house based mostly on a concrete property of the duty at hand. Work by means of them so as.
Query 1: Is the Answer Path Recognized in Advance?
This query separates mounted workflows from adaptive ones.
A recognized answer path means the total step-by-step course of could be outlined earlier than execution. For instance:
- Bill processing: extract fields → validate → retailer → verify
- Worker onboarding: create accounts → ship welcome electronic mail → assign supervisor → schedule orientation
These are predictable workflows the place the identical steps apply each time.
An unknown answer path means every step is dependent upon earlier outputs. Analysis duties that comply with new proof, buyer help that branches based mostly on person enter, or debugging that shifts hypotheses based mostly on earlier outcomes can’t be absolutely deliberate upfront.
If the trail is thought → go to Query 2a. If unknown → go to Query 2b.
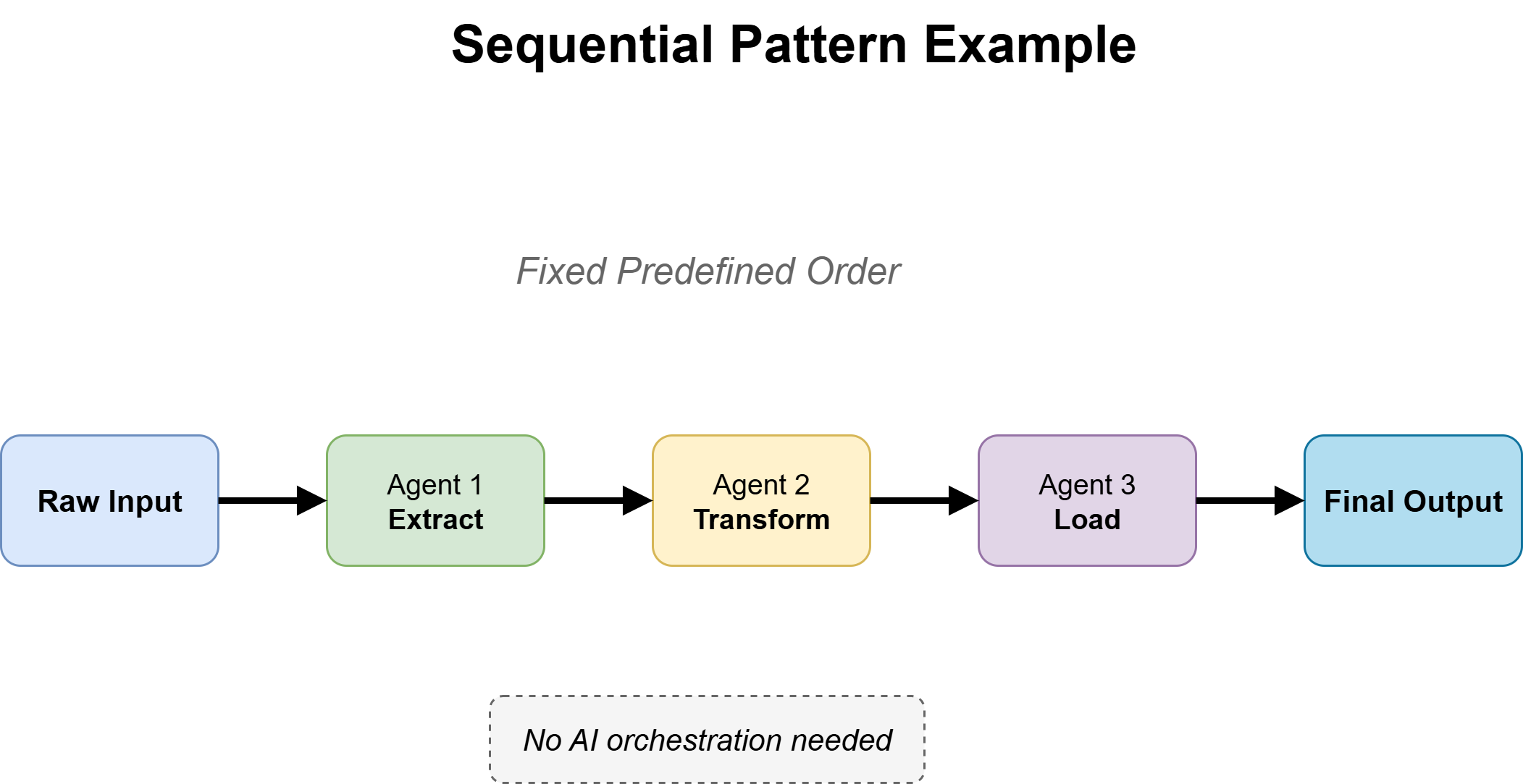
Query 2a: Is This a Fastened Workflow?
For recognized, secure paths, use a sequential workflow sample. The agent follows express steps so as, passing outputs from one stage to the following till completion.
Sequential workflow sample
The important thing design alternative is the place reasoning is required. Use the mannequin just for duties like interpretation or technology, whereas deterministic code handles every part else. This retains methods quick, predictable, and cost-efficient.
The principle failure mode is over-engineering — including ReAct-style reasoning the place each step is already outlined. If the method is absolutely deterministic, the agent ought to execute, not determine.
If the workflow begins breaking on edge circumstances or requires new steps not initially outlined, it might be time to maneuver to Query 2b.
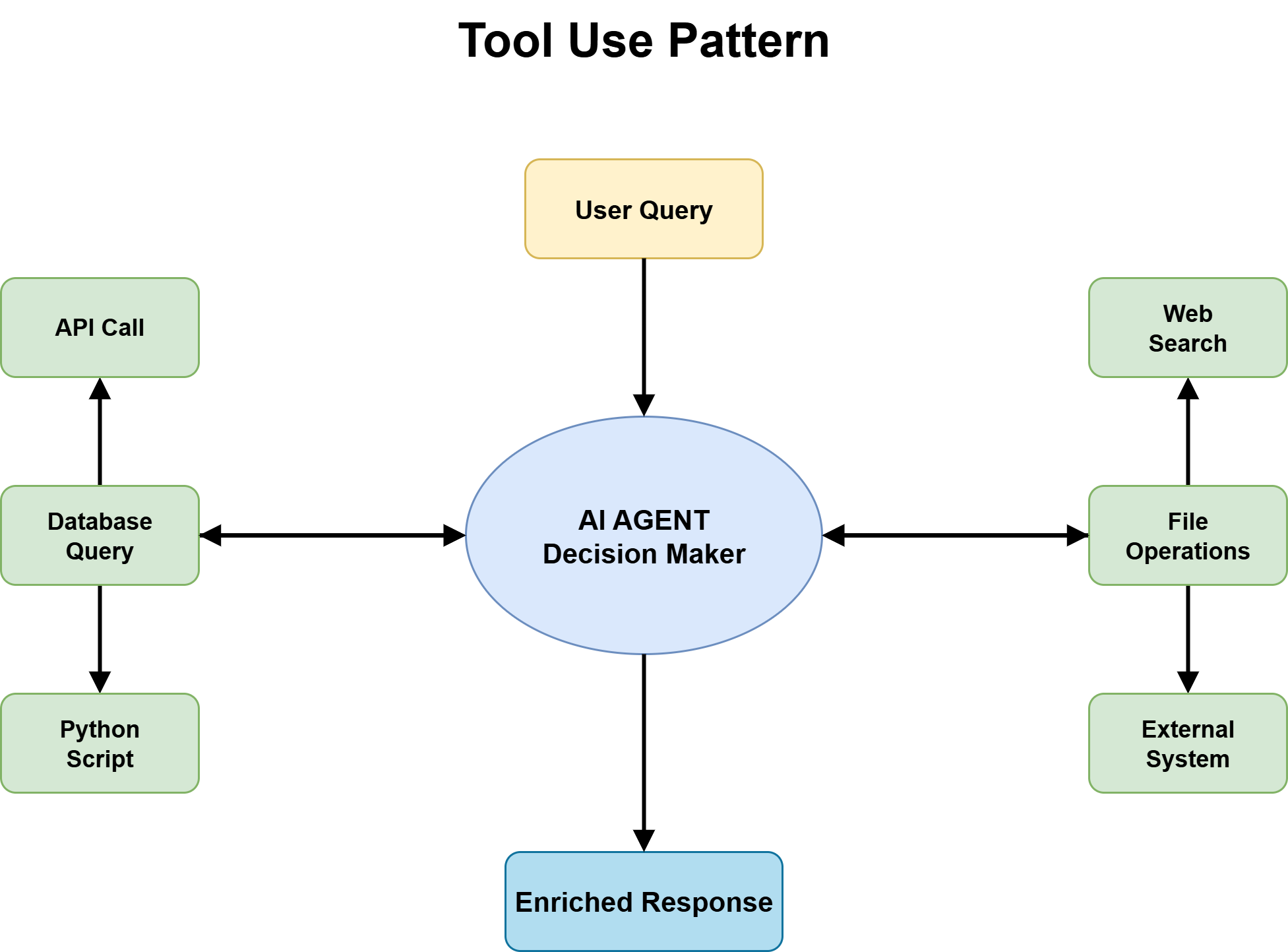
Query 2b: Does the Activity Require Device Entry or Exterior Data?
For duties with unknown answer paths, the following query is whether or not the agent must work together with the exterior world — question databases, name APIs, retrieve paperwork, run code — or whether or not it could function purely on info already in its context.
Device use sample
The reply is sort of at all times sure: device use is required. An agent that may solely purpose over its coaching information and the dialog context handles a slender slice of real-world duties. The second the duty entails present info, exterior state, or system-level actions, device use turns into the muse every part else sits on.
Efficient device design with clear contracts, inputs, and outputs issues, however for sample choice the principle level is less complicated: instruments add functionality with out altering the reasoning sample. A ReAct agent with instruments remains to be ReAct, and a planning agent with instruments remains to be planning. Device use sits beneath the reasoning layer, not alongside it.
Transfer ahead to Query 3 with device use assumed except the duty is genuinely self-contained.
Query 3: Is the Activity Construction Articulable Earlier than Execution Begins?
This query separates Planning from ReAct and is usually skipped in apply, with builders defaulting to ReAct. ReAct works by iteratively alternating between reasoning steps and gear actions, utilizing the outcomes of every step to determine what to do subsequent till a stopping situation is met.
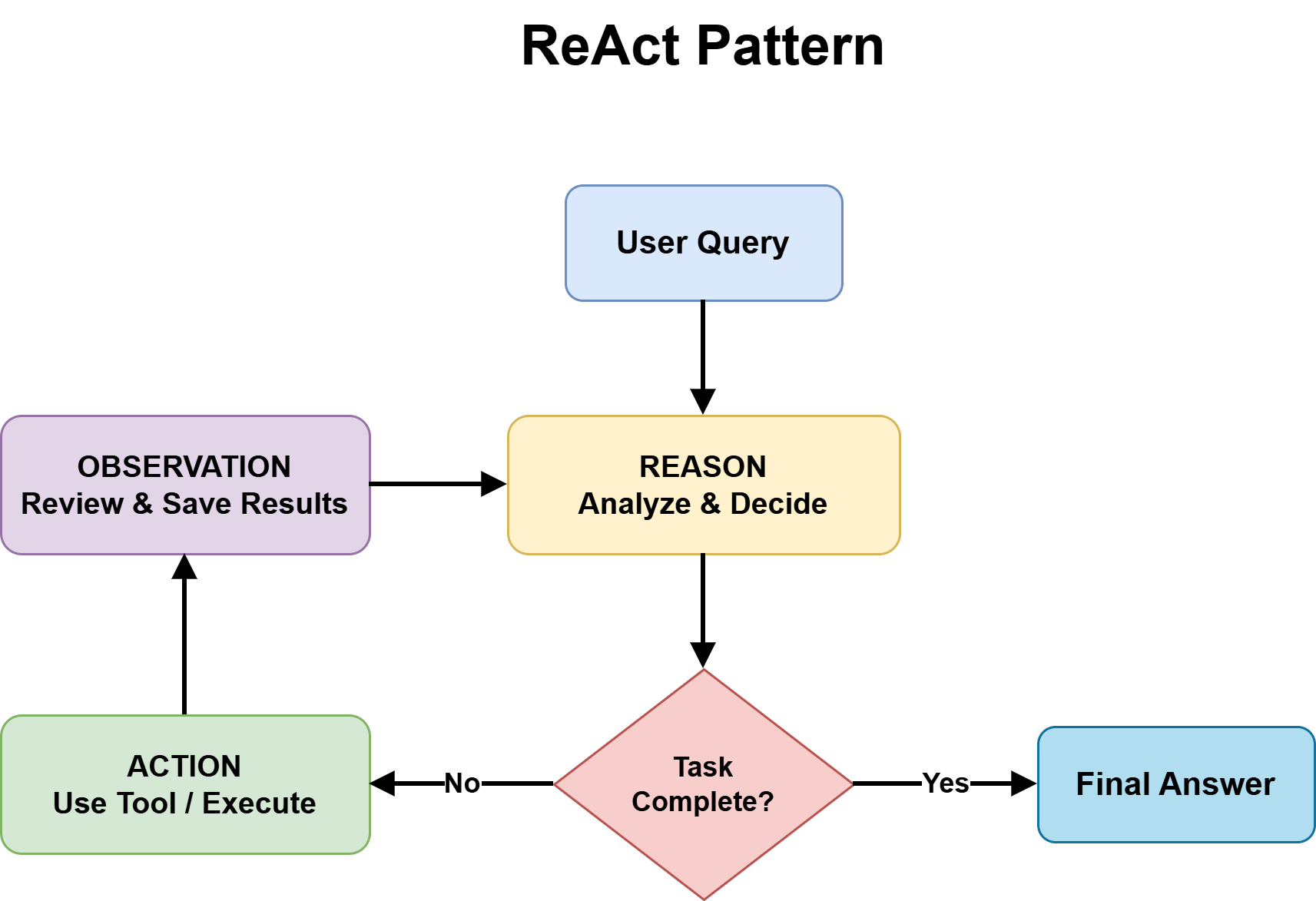
ReAct Sample
A activity is structurally articulable when it may be damaged into ordered subtasks with clear dependencies earlier than execution. The complete particulars could also be unknown, however the principle levels and sequence are clear. For instance, constructing a characteristic (design → implement → take a look at), provisioning methods so as, or producing a analysis report (collect → synthesize → write) all have an outlined construction.
The planning sample works nicely when this construction exists, as a result of it exposes dependencies early and avoids mid-execution surprises. With out it, brokers can solely uncover errors after spending time and compute on the unsuitable path.
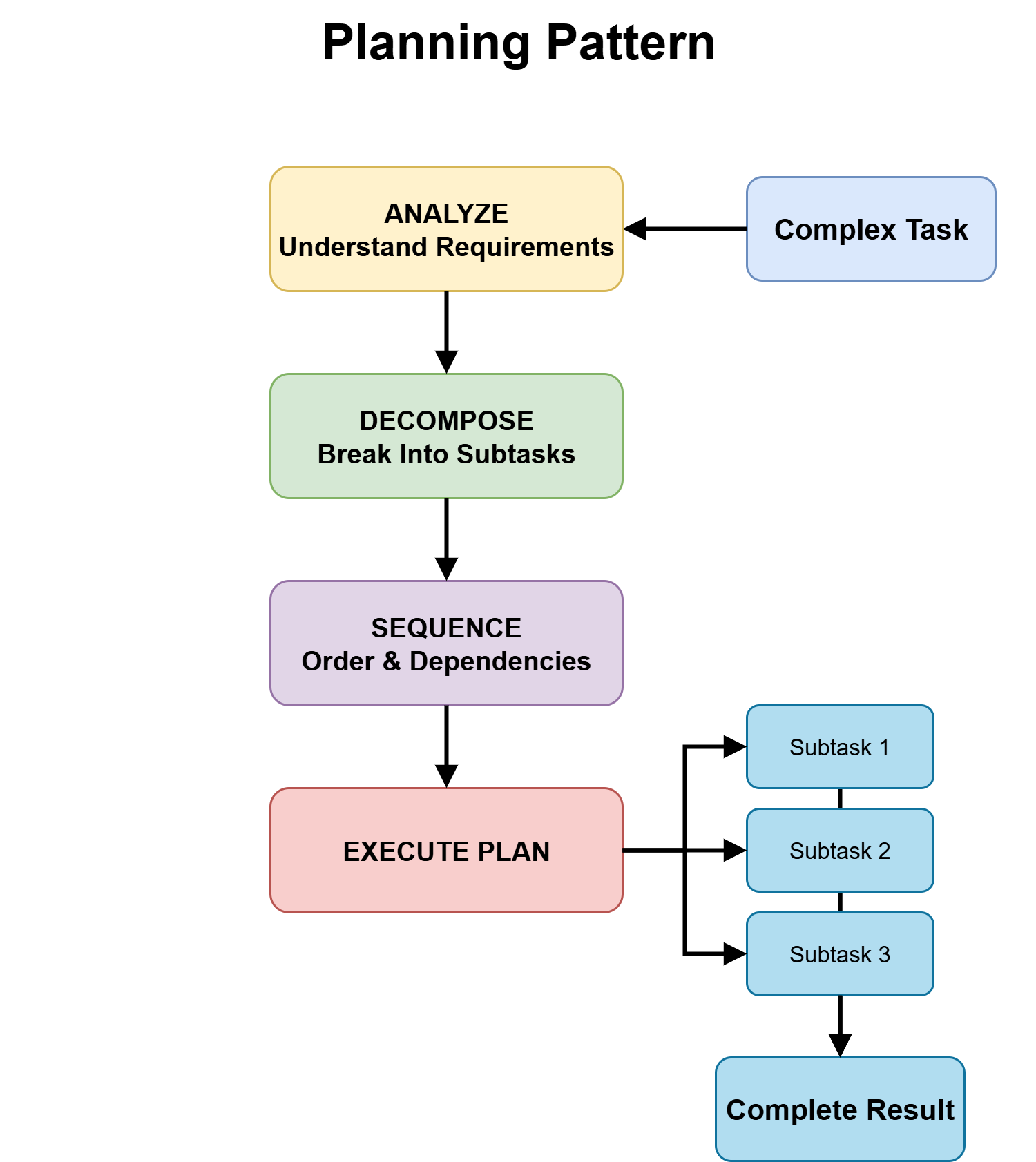
Planning Sample
However planning additionally has prices: an additional upfront step, reliance on the standard of the preliminary plan, and lowered flexibility when real-world circumstances differ from expectations. When construction solely turns into clear by means of interplay and suggestions, planning could be deceptive.
If the duty is structurally clear → use Planning with ReAct inside steps. If construction emerges throughout execution → use ReAct and transfer to Query 4.
Query 4: Does Output High quality Matter Extra Than Response Velocity?
This query introduces the reflection sample — the generate–critique–refine cycle — and determines whether or not it ought to be added on prime of the chosen sample.
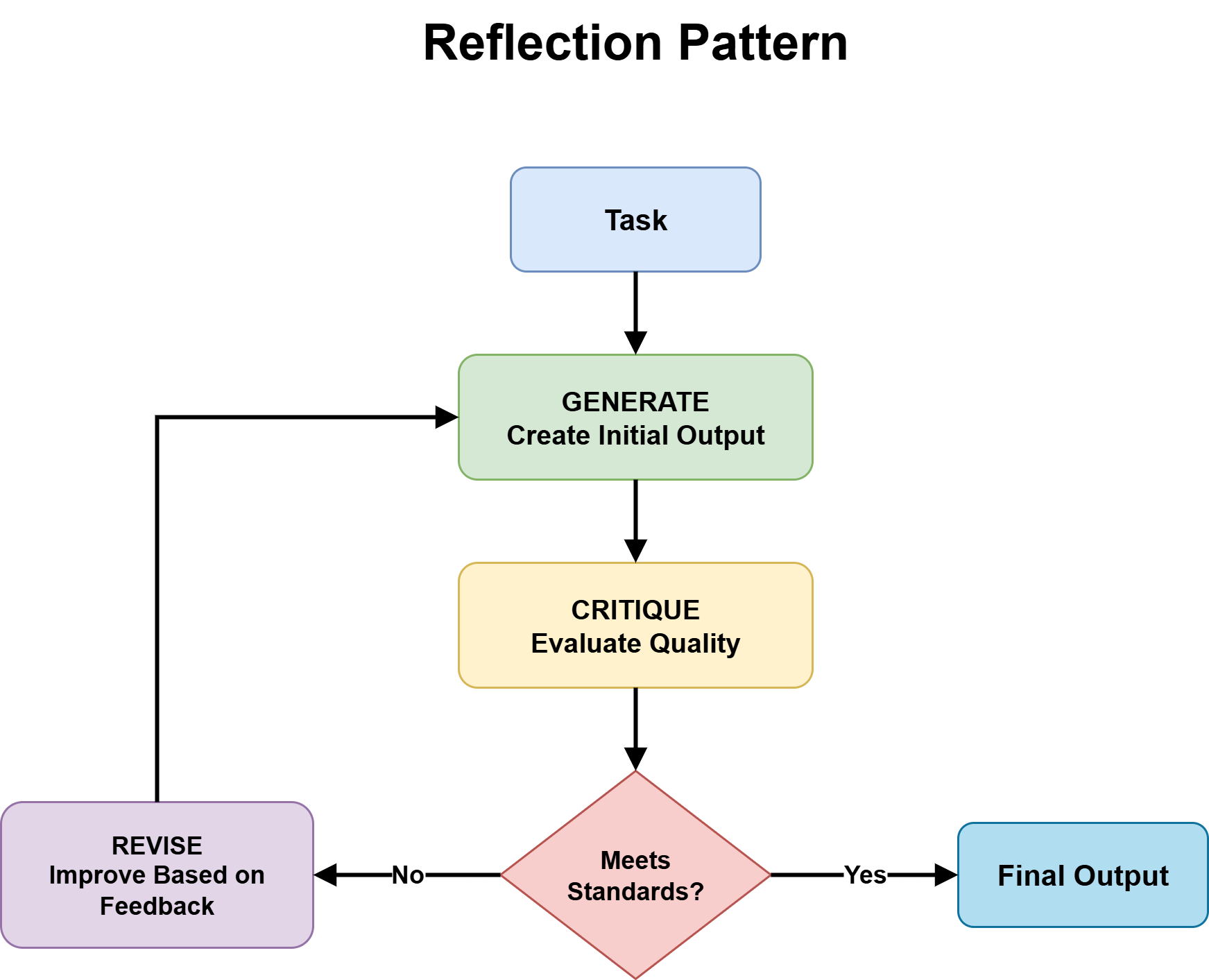
Reflection Sample
Reflection is beneficial when two circumstances are met:
- First, there are clear high quality standards the output could be checked in opposition to — resembling a sound SQL question, a well-reasoned argument, or a contract with lacking parts.
- Second, the value of errors is excessive sufficient to justify an additional go, resembling deployed code or client-facing paperwork.
It’s not helpful when these circumstances don’t maintain. With out clear analysis standards, the critic produces obscure or deceptive suggestions. And when pace is necessary — as in dwell methods or high-throughput duties — the additional latency is a disadvantage.
A key element is critic independence. If the critic mirrors the generator too carefully, it tends to agree slightly than consider. Robust reflection usually requires a separate framing or perhaps a completely different mannequin.
If high quality is necessary and standards are clear → add Reflection. If pace issues extra or analysis is unclear → skip it and transfer to Query 5.
Query 5: Does the Activity Have a Specialization or Scale Downside That One Agent Can’t Deal with?
That is the place you determine whether or not you want a multi-agent structure, and it ought to solely be thought-about after the earlier steps have been evaluated rigorously.
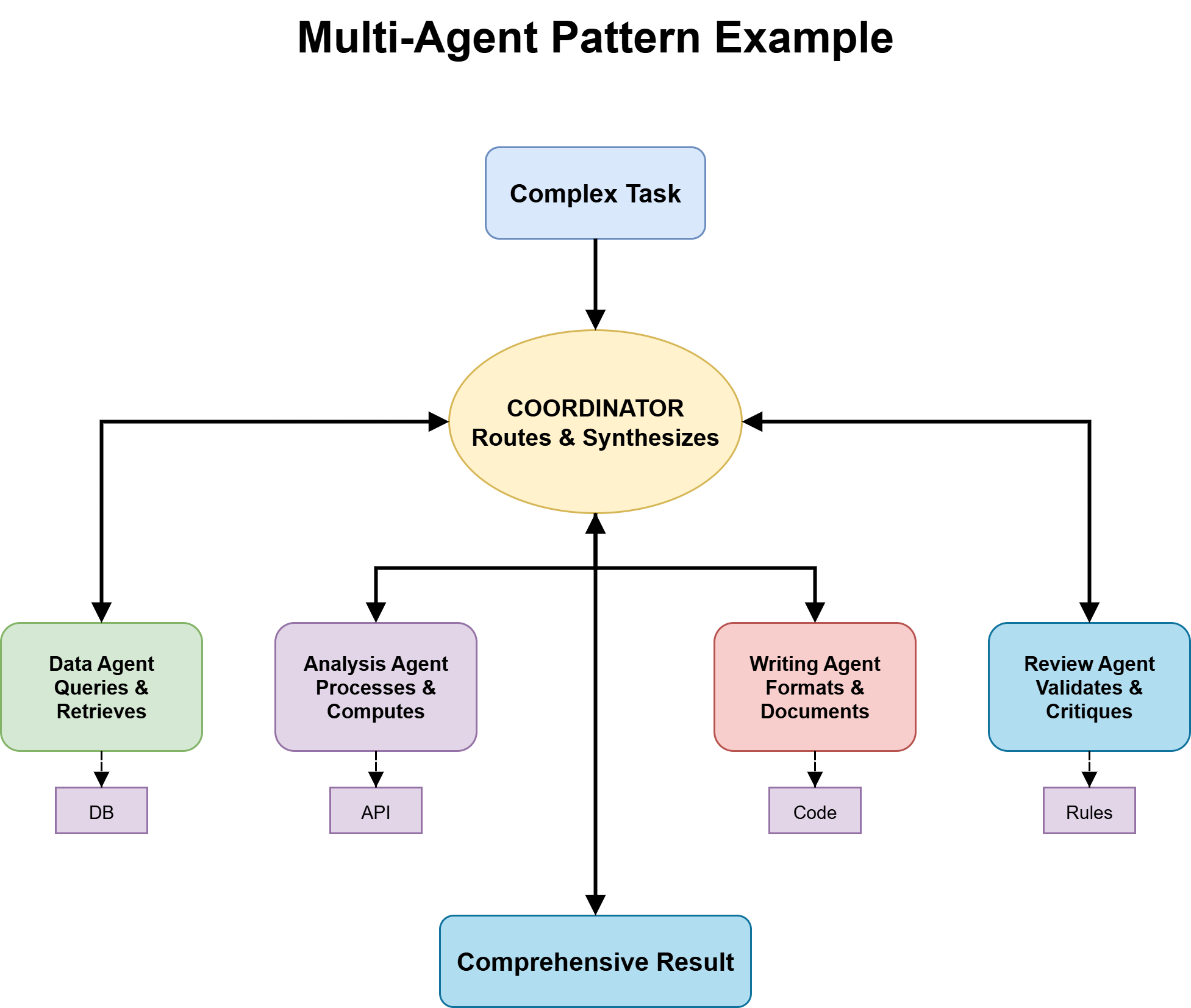
Multi-Agent Sample
Multi-agent methods are helpful when duties are too giant for a single context window, require completely different varieties of experience throughout levels, or profit from parallel execution to scale back general time. They will enhance efficiency by splitting work throughout specialised brokers, however additionally they add coordination overhead, shared state complexity, and extra failure factors.
The specialization subject seems when completely different elements of the duty want clearly completely different reasoning types — resembling authorized overview vs. monetary modeling, or coding vs. safety auditing. The size subject seems when work can’t match into one agent’s context or is being unnecessarily serialized.
If neither applies, a single robust agent is often sufficient; the overhead of a number of brokers outweighs the profit. The set off for multi-agent use ought to be a transparent bottleneck that specialization or scale really solves, not architectural choice.
When wanted, key design decisions embrace activity possession, routing logic, and topology, which could be sequential, parallel, or debate-style coordination.
Placing all of it collectively, we’ve got the next choice tree:
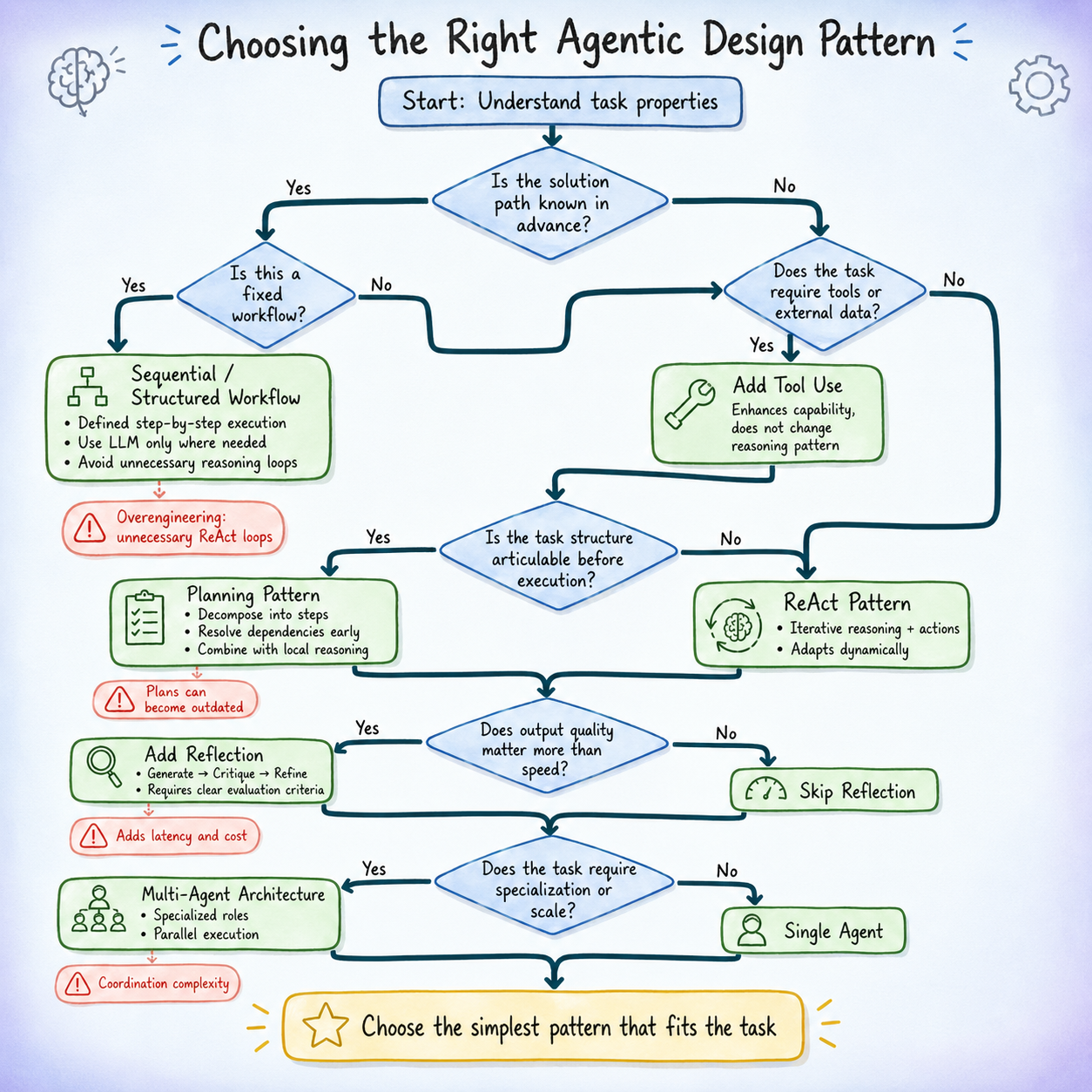
Resolution Tree for Selecting the Proper Agentic Design Sample
Resolution Tree → Agentic Design Sample Mapping
Working by means of all 5 questions produces certainly one of 4 widespread vacation spot patterns. In apply, most manufacturing brokers find yourself someplace between these, with parts of a number of patterns layered collectively. These are beginning factors, not closing states.
| Ensuing Agent Sample | When to Use | Why It Works |
|---|---|---|
| Single Agent + Instruments + ReAct | Unknown answer path, no clear upfront construction, no strict high quality constraints, no specialization wants. | Finest default for real-world duties. Versatile exploration by way of device use and step-by-step reasoning. Cheap failure detection and iterative enchancment. |
| Planning Agent + ReAct Execution | Activity construction is knowable upfront, however every step requires adaptive reasoning throughout execution. | Planner defines levels and dependencies; ReAct handles native uncertainty. Reduces mid-execution failure from hidden complexity. |
| Single Agent + Reflection | Excessive-quality output required and latency is appropriate. | Generate → Critique → Refine loop improves correctness. Works finest when analysis standards are express and verifiable. |
| Multi-Agent Specialist System | Robust specialization wants or scale exceeds single-agent capability. | Coordinator routes duties to specialists. Allows parallelism and area experience, however provides coordination overhead and system complexity. |
Widespread Agentic Design Sample Pitfalls (and Fixes)
Selecting a beginning sample from the choice tree is the 1st step. Understanding how you can diagnose when the chosen sample isn’t working is dependent upon studying just a few clear alerts.
| Sign | What It Means | Recommended Repair |
|---|---|---|
| ReAct looping excessively | Too many steps or revisiting resolved questions; agent is unsure about progress or construction. | Activity probably wants planning, higher device construction, or a clearer stopping situation. |
| Planning agent abandoning plan | Plan is created however not adopted; execution retains diverging from it. | Activity is much less structured than assumed; change to light-weight planning + ReAct. |
| Reflection not enhancing output | Critique cycles don’t meaningfully enhance output high quality. | Analysis standards are unclear or the critic is just too aligned with the generator; refine the critique setup. |
| Multi-agent routing failures | Incorrect specialist choice or outputs don’t mix nicely downstream. | Routing logic subject; use deterministic guidelines for predictable circumstances as a substitute of LLM routing. |
Subsequent Steps
The choice tree makes agentic sample choice express as a substitute of instinctive. It forces the important thing questions — answer path, construction, high quality wants, and specialization — earlier than any code is written, when errors are least expensive to repair.
Most points come from over-engineering too early or staying too easy too lengthy. The patterns themselves are secure; the problem is selecting appropriately. Let the choice tree information the place to begin, and let apply and outcomes information the evolution.
For prime-stakes functions, incorporate human-in-the-loop checkpoints the place reliability, security, or judgment calls matter most. Listed below are just a few helpful sources for additional studying:
On this article, you’ll discover ways to apply a structured choice tree to decide on the best agentic design sample for any AI system you might be constructing.
Subjects we are going to cowl embrace:
- Why sample choice is a important design choice, and what assumptions underlie every main agentic design sample.
- A five-question choice tree that maps concrete activity properties to probably the most applicable beginning sample.
- Widespread failure alerts for every sample and the focused fixes that handle them.
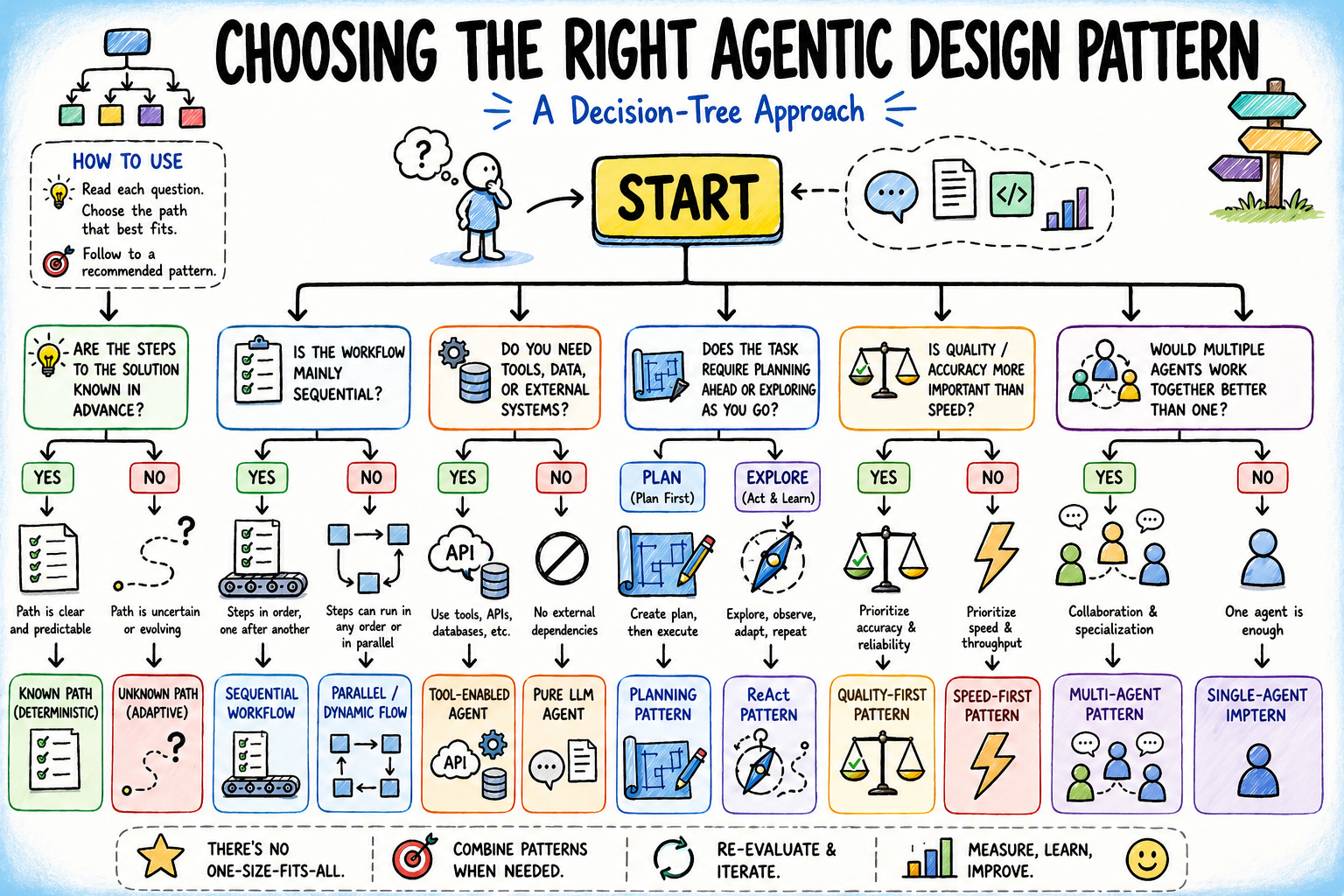
Selecting the Proper Agentic Design Sample: A Resolution Tree Method (click on to enlarge)
Introduction
Most agentic structure errors begin with a easy misinterpret of the issue. Builders usually decide a sample based mostly on what seems spectacular or acquainted, not what the duty really wants. A multi-agent system from a chat can seem like the “proper” reply, so that they spend weeks constructing orchestration for one thing a single well-prompted agent with a few instruments may deal with in a day. Or they go the opposite route, hold issues too easy, and solely uncover in manufacturing that the system can’t adapt or scale, forcing a redesign beneath strain.
Sample choice is the place the actual design work occurs. The agentic design patterns themselves are nicely documented. What’s much less documented is the choice logic for selecting between them. That logic is what this text is about.
The method here’s a choice tree: a collection of questions on your activity, your constraints, and your acceptable trade-offs that leads you to the best beginning sample. The tree doesn’t produce a closing reply; agent architectures evolve as suggestions accumulates. However it offers you a principled start line, and it makes the reasoning behind your alternative clear sufficient to revisit when issues change.
Why Is Agentic Design Sample Choice Necessary?
Earlier than working by means of the choice tree, it is very important clearly outline what’s at stake when choosing a design sample.
Every agentic design sample is predicated on particular assumptions in regards to the construction and calls for of a activity. Listed below are a few of them:
- ReAct sample treats the following finest motion as not absolutely knowable upfront, and depends on combining reasoning with device use at every step to enhance selections.
- Planning is predicated on the concept that the foremost construction of the duty could be recognized upfront, and that defining an execution roadmap improves downstream reliability.
- Reflection sample is grounded within the expectation that first-pass outputs are sometimes incomplete or flawed, and that iterative self-critique and refinement enhance closing high quality sufficient to justify the added value.
- Multi-agent approaches function on the assumption that the duty advantages from decomposition into specialised roles, the place parallel or modular execution outweighs the overhead of coordination.
When these assumptions match the duty, the sample provides actual worth. After they don’t, it provides overhead with out enhancing outcomes. As an illustration, planning can develop into inflexible when activity construction solely emerges throughout execution, reflection can waste sources on easy queries, and multi-agent setups can add pointless complexity for issues a single agent can clear up.
The choice tree beneath helps information deliberate sample choice. Every department displays a key activity property that determines which assumptions really maintain.
Additional studying on agentic design patterns: The Roadmap to Mastering Agentic AI Design Patterns
A Resolution Tree for Selecting the Proper Agentic Design Sample
The tree has 5 branching questions, each narrowing the sample house based mostly on a concrete property of the duty at hand. Work by means of them so as.
Query 1: Is the Answer Path Recognized in Advance?
This query separates mounted workflows from adaptive ones.
A recognized answer path means the total step-by-step course of could be outlined earlier than execution. For instance:
- Bill processing: extract fields → validate → retailer → verify
- Worker onboarding: create accounts → ship welcome electronic mail → assign supervisor → schedule orientation
These are predictable workflows the place the identical steps apply each time.
An unknown answer path means every step is dependent upon earlier outputs. Analysis duties that comply with new proof, buyer help that branches based mostly on person enter, or debugging that shifts hypotheses based mostly on earlier outcomes can’t be absolutely deliberate upfront.
If the trail is thought → go to Query 2a. If unknown → go to Query 2b.
Query 2a: Is This a Fastened Workflow?
For recognized, secure paths, use a sequential workflow sample. The agent follows express steps so as, passing outputs from one stage to the following till completion.
Sequential workflow sample
The important thing design alternative is the place reasoning is required. Use the mannequin just for duties like interpretation or technology, whereas deterministic code handles every part else. This retains methods quick, predictable, and cost-efficient.
The principle failure mode is over-engineering — including ReAct-style reasoning the place each step is already outlined. If the method is absolutely deterministic, the agent ought to execute, not determine.
If the workflow begins breaking on edge circumstances or requires new steps not initially outlined, it might be time to maneuver to Query 2b.
Query 2b: Does the Activity Require Device Entry or Exterior Data?
For duties with unknown answer paths, the following query is whether or not the agent must work together with the exterior world — question databases, name APIs, retrieve paperwork, run code — or whether or not it could function purely on info already in its context.
Device use sample
The reply is sort of at all times sure: device use is required. An agent that may solely purpose over its coaching information and the dialog context handles a slender slice of real-world duties. The second the duty entails present info, exterior state, or system-level actions, device use turns into the muse every part else sits on.
Efficient device design with clear contracts, inputs, and outputs issues, however for sample choice the principle level is less complicated: instruments add functionality with out altering the reasoning sample. A ReAct agent with instruments remains to be ReAct, and a planning agent with instruments remains to be planning. Device use sits beneath the reasoning layer, not alongside it.
Transfer ahead to Query 3 with device use assumed except the duty is genuinely self-contained.
Query 3: Is the Activity Construction Articulable Earlier than Execution Begins?
This query separates Planning from ReAct and is usually skipped in apply, with builders defaulting to ReAct. ReAct works by iteratively alternating between reasoning steps and gear actions, utilizing the outcomes of every step to determine what to do subsequent till a stopping situation is met.
ReAct Sample
A activity is structurally articulable when it may be damaged into ordered subtasks with clear dependencies earlier than execution. The complete particulars could also be unknown, however the principle levels and sequence are clear. For instance, constructing a characteristic (design → implement → take a look at), provisioning methods so as, or producing a analysis report (collect → synthesize → write) all have an outlined construction.
The planning sample works nicely when this construction exists, as a result of it exposes dependencies early and avoids mid-execution surprises. With out it, brokers can solely uncover errors after spending time and compute on the unsuitable path.
Planning Sample
However planning additionally has prices: an additional upfront step, reliance on the standard of the preliminary plan, and lowered flexibility when real-world circumstances differ from expectations. When construction solely turns into clear by means of interplay and suggestions, planning could be deceptive.
If the duty is structurally clear → use Planning with ReAct inside steps. If construction emerges throughout execution → use ReAct and transfer to Query 4.
Query 4: Does Output High quality Matter Extra Than Response Velocity?
This query introduces the reflection sample — the generate–critique–refine cycle — and determines whether or not it ought to be added on prime of the chosen sample.
Reflection Sample
Reflection is beneficial when two circumstances are met:
- First, there are clear high quality standards the output could be checked in opposition to — resembling a sound SQL question, a well-reasoned argument, or a contract with lacking parts.
- Second, the value of errors is excessive sufficient to justify an additional go, resembling deployed code or client-facing paperwork.
It’s not helpful when these circumstances don’t maintain. With out clear analysis standards, the critic produces obscure or deceptive suggestions. And when pace is necessary — as in dwell methods or high-throughput duties — the additional latency is a disadvantage.
A key element is critic independence. If the critic mirrors the generator too carefully, it tends to agree slightly than consider. Robust reflection usually requires a separate framing or perhaps a completely different mannequin.
If high quality is necessary and standards are clear → add Reflection. If pace issues extra or analysis is unclear → skip it and transfer to Query 5.
Query 5: Does the Activity Have a Specialization or Scale Downside That One Agent Can’t Deal with?
That is the place you determine whether or not you want a multi-agent structure, and it ought to solely be thought-about after the earlier steps have been evaluated rigorously.
Multi-Agent Sample
Multi-agent methods are helpful when duties are too giant for a single context window, require completely different varieties of experience throughout levels, or profit from parallel execution to scale back general time. They will enhance efficiency by splitting work throughout specialised brokers, however additionally they add coordination overhead, shared state complexity, and extra failure factors.
The specialization subject seems when completely different elements of the duty want clearly completely different reasoning types — resembling authorized overview vs. monetary modeling, or coding vs. safety auditing. The size subject seems when work can’t match into one agent’s context or is being unnecessarily serialized.
If neither applies, a single robust agent is often sufficient; the overhead of a number of brokers outweighs the profit. The set off for multi-agent use ought to be a transparent bottleneck that specialization or scale really solves, not architectural choice.
When wanted, key design decisions embrace activity possession, routing logic, and topology, which could be sequential, parallel, or debate-style coordination.
Placing all of it collectively, we’ve got the next choice tree:
Resolution Tree for Selecting the Proper Agentic Design Sample
Resolution Tree → Agentic Design Sample Mapping
Working by means of all 5 questions produces certainly one of 4 widespread vacation spot patterns. In apply, most manufacturing brokers find yourself someplace between these, with parts of a number of patterns layered collectively. These are beginning factors, not closing states.
| Ensuing Agent Sample | When to Use | Why It Works |
|---|---|---|
| Single Agent + Instruments + ReAct | Unknown answer path, no clear upfront construction, no strict high quality constraints, no specialization wants. | Finest default for real-world duties. Versatile exploration by way of device use and step-by-step reasoning. Cheap failure detection and iterative enchancment. |
| Planning Agent + ReAct Execution | Activity construction is knowable upfront, however every step requires adaptive reasoning throughout execution. | Planner defines levels and dependencies; ReAct handles native uncertainty. Reduces mid-execution failure from hidden complexity. |
| Single Agent + Reflection | Excessive-quality output required and latency is appropriate. | Generate → Critique → Refine loop improves correctness. Works finest when analysis standards are express and verifiable. |
| Multi-Agent Specialist System | Robust specialization wants or scale exceeds single-agent capability. | Coordinator routes duties to specialists. Allows parallelism and area experience, however provides coordination overhead and system complexity. |
Widespread Agentic Design Sample Pitfalls (and Fixes)
Selecting a beginning sample from the choice tree is the 1st step. Understanding how you can diagnose when the chosen sample isn’t working is dependent upon studying just a few clear alerts.
| Sign | What It Means | Recommended Repair |
|---|---|---|
| ReAct looping excessively | Too many steps or revisiting resolved questions; agent is unsure about progress or construction. | Activity probably wants planning, higher device construction, or a clearer stopping situation. |
| Planning agent abandoning plan | Plan is created however not adopted; execution retains diverging from it. | Activity is much less structured than assumed; change to light-weight planning + ReAct. |
| Reflection not enhancing output | Critique cycles don’t meaningfully enhance output high quality. | Analysis standards are unclear or the critic is just too aligned with the generator; refine the critique setup. |
| Multi-agent routing failures | Incorrect specialist choice or outputs don’t mix nicely downstream. | Routing logic subject; use deterministic guidelines for predictable circumstances as a substitute of LLM routing. |
Subsequent Steps
The choice tree makes agentic sample choice express as a substitute of instinctive. It forces the important thing questions — answer path, construction, high quality wants, and specialization — earlier than any code is written, when errors are least expensive to repair.
Most points come from over-engineering too early or staying too easy too lengthy. The patterns themselves are secure; the problem is selecting appropriately. Let the choice tree information the place to begin, and let apply and outcomes information the evolution.
For prime-stakes functions, incorporate human-in-the-loop checkpoints the place reliability, security, or judgment calls matter most. Listed below are just a few helpful sources for additional studying:
















{kind=link}