


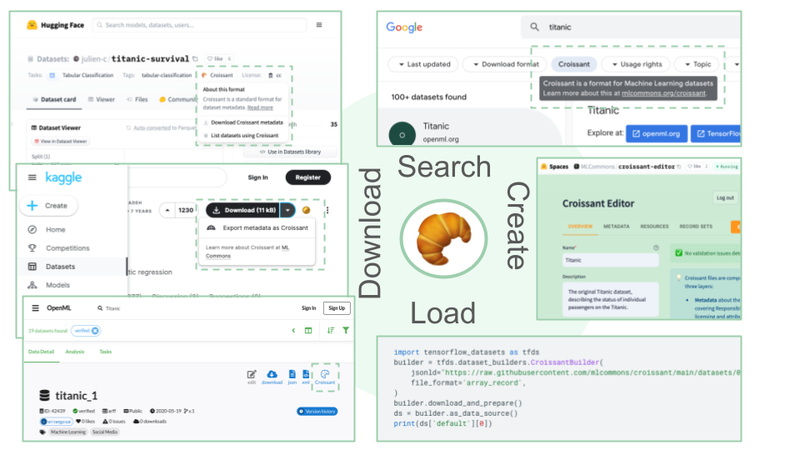
Immediately, we’re introducing Croissant, a brand new metadata format for ML-ready datasets. Croissant was developed collaboratively by a group from business and academia, as a part of the MLCommons effort.
Machine studying (ML) practitioners trying to reuse current datasets to coach an ML mannequin typically spend plenty of time understanding the information, making sense of its group, or determining what subset to make use of as options. A lot time, the truth is, that progress within the subject of ML is hampered by a elementary impediment: the wide range of knowledge representations.
ML datasets cowl a broad vary of content material varieties, from textual content and structured information to photographs, audio, and video. Even inside datasets that cowl the identical sorts of content material, each dataset has a singular advert hoc association of recordsdata and information codecs. This problem reduces productiveness all through your entire ML growth course of, from discovering the information to coaching the mannequin. It additionally impedes growth of badly wanted tooling for working with datasets.
There are common goal metadata codecs for datasets akin to schema.org and DCAT. Nevertheless, these codecs had been designed for information discovery quite than for the precise wants of ML information, akin to the power to extract and mix information from structured and unstructured sources, to incorporate metadata that will allow accountable use of the information, or to explain ML utilization traits akin to defining coaching, check and validation units.
Immediately, we’re introducing Croissant, a brand new metadata format for ML-ready datasets. Croissant was developed collaboratively by a group from business and academia, as a part of the MLCommons effort. The Croissant format would not change how the precise information is represented (e.g., picture or textual content file codecs) — it offers an ordinary technique to describe and manage it. Croissant builds upon schema.org, the de facto normal for publishing structured information on the Net, which is already utilized by over 40M datasets. Croissant augments it with complete layers for ML related metadata, information sources, information group, and default ML semantics.
As well as, we’re asserting help from main instruments and repositories: Immediately, three extensively used collections of ML datasets — Kaggle, Hugging Face, and OpenML — will start supporting the Croissant format for the datasets they host; the Dataset Search instrument lets customers seek for Croissant datasets throughout the Net; and standard ML frameworks, together with TensorFlow, PyTorch, and JAX, can load Croissant datasets simply utilizing the TensorFlow Datasets (TFDS) package deal.
Croissant
This 1.0 launch of Croissant features a full specification of the format, a set of instance datasets, an open supply Python library to validate, eat and generate Croissant metadata, and an open supply visible editor to load, examine and create Croissant dataset descriptions in an intuitive means.
Supporting Accountable AI (RAI) was a key purpose of the Croissant effort from the beginning. We’re additionally releasing the primary model of the Croissant RAI vocabulary extension, which augments Croissant with key properties wanted to explain necessary RAI use instances akin to information life cycle administration, information labeling, participatory information, ML security and equity analysis, explainability, and compliance.
Why a shared format for ML information?
The vast majority of ML work is definitely information work. The coaching information is the “code” that determines the conduct of a mannequin. Datasets can range from a group of textual content used to coach a big language mannequin (LLM) to a group of driving situations (annotated movies) used to coach a automobile’s collision avoidance system. Nevertheless, the steps to develop an ML mannequin usually observe the identical iterative data-centric course of: (1) discover or gather information, (2) clear and refine the information, (3) prepare the mannequin on the information, (4) check the mannequin on extra information, (5) uncover the mannequin doesn’t work, (6) analyze the information to search out out why, (7) repeat till a workable mannequin is achieved. Many steps are made tougher by the shortage of a typical format. This “information growth burden” is very heavy for resource-limited analysis and early-stage entrepreneurial efforts.
The purpose of a format like Croissant is to make this complete course of simpler. As an illustration, the metadata will be leveraged by search engines like google and yahoo and dataset repositories to make it simpler to search out the fitting dataset. The info sources and group data make it simpler to develop instruments for cleansing, refining, and analyzing information. This data and the default ML semantics make it doable for ML frameworks to make use of the information to coach and check fashions with a minimal of code. Collectively, these enhancements considerably cut back the information growth burden.
Moreover, dataset authors care concerning the discoverability and ease of use of their datasets. Adopting Croissant improves the worth of their datasets, whereas solely requiring a minimal effort, due to the obtainable creation instruments and help from ML information platforms.
What can Croissant do immediately?
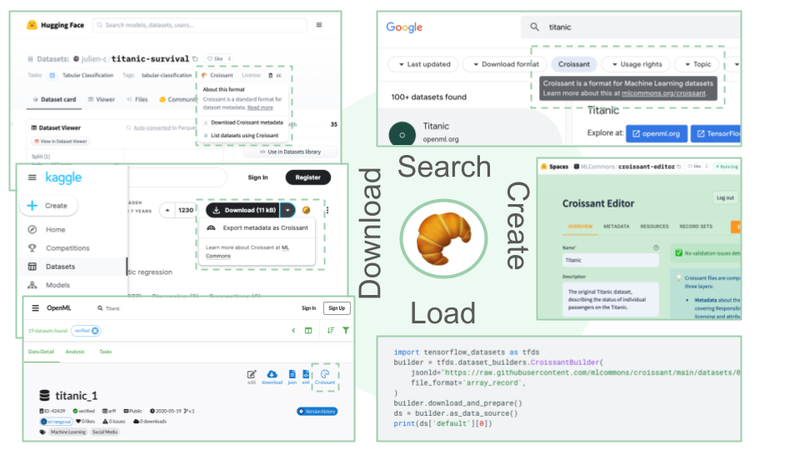
The Croissant ecosystem: Customers can Seek for Croissant datasets, obtain them from main repositories, and simply load them into their favourite ML frameworks. They will create, examine and modify Croissant metadata utilizing the Croissant editor.
Immediately, customers can discover Croissant datasets at:
With a Croissant dataset, it’s doable to:
To publish a Croissant dataset, customers can:
- Use the Croissant editor UI (github) to generate a big portion of Croissant metadata mechanically by analyzing the information the consumer offers, and to fill necessary metadata fields akin to RAI properties.
- Publish the Croissant data as a part of their dataset Net web page to make it discoverable and reusable.
- Publish their information in one of many repositories that help Croissant, akin to Kaggle, HuggingFace and OpenML, and mechanically generate Croissant metadata.
Future route
We’re enthusiastic about Croissant’s potential to assist ML practitioners, however making this format really helpful requires the help of the group. We encourage dataset creators to contemplate offering Croissant metadata. We encourage platforms internet hosting datasets to offer Croissant recordsdata for obtain and embed Croissant metadata in dataset Net pages in order that they are often made discoverable by dataset search engines like google and yahoo. Instruments that assist customers work with ML datasets, akin to labeling or information evaluation instruments must also take into account supporting Croissant datasets. Collectively, we are able to cut back the information growth burden and allow a richer ecosystem of ML analysis and growth.
We encourage the group to be part of us in contributing to the trouble.
Acknowledgements
Croissant was developed by the Dataset Search, Kaggle and TensorFlow Datasets groups from Google, as a part of an MLCommons group working group, which additionally consists of contributors from these organizations: Bayer, cTuning Basis, DANS-KNAW, Dotphoton, Harvard, Hugging Face, Kings Faculty London, LIST, Meta, NASA, North Carolina State College, Open Information Institute, Open College of Catalonia, Sage Bionetworks, and TU Eindhoven.
















{kind=link}