


On this article, you’ll learn the way vector databases and graph RAG differ as reminiscence architectures for AI brokers, and when every method is the higher match.
Matters we’ll cowl embrace:
- How vector databases retailer and retrieve semantically related unstructured data.
- How graph RAG represents entities and relationships for exact, multi-hop retrieval.
- How to decide on between these approaches, or mix them in a hybrid agent-memory structure.
With that in thoughts, let’s get straight to it.
Vector Databases vs. Graph RAG for Agent Reminiscence: When to Use Which
Picture by Creator
Introduction
AI brokers want long-term reminiscence to be genuinely helpful in advanced, multi-step workflows. An agent with out reminiscence is actually a stateless perform that resets its context with each interplay. As we transfer towards autonomous programs that handle persistent duties (corresponding to like coding assistants that monitor venture structure or analysis brokers that compile ongoing literature critiques) the query of how one can retailer, retrieve, and replace context turns into crucial.
At present, the trade commonplace for this activity is the vector database, which makes use of dense embeddings for semantic search. But, as the necessity for extra advanced reasoning grows, graph RAG, an structure that mixes data graphs with giant language fashions (LLMs), is gaining traction as a structured reminiscence structure.
At a look, vector databases are perfect for broad similarity matching and unstructured information retrieval, whereas graph RAG excels when context home windows are restricted and when multi-hop relationships, factual accuracy, and complicated hierarchical buildings are required. This distinction highlights vector databases’ deal with versatile matching, in contrast with graph RAG’s skill to cause by means of express relationships and protect accuracy below tighter constraints.
To make clear their respective roles, this text explores the underlying principle, sensible strengths, and limitations of each approaches for agent reminiscence. In doing so, it gives a sensible framework to information the selection of system, or mixture of programs, to deploy.
Vector Databases: The Basis of Semantic Agent Reminiscence
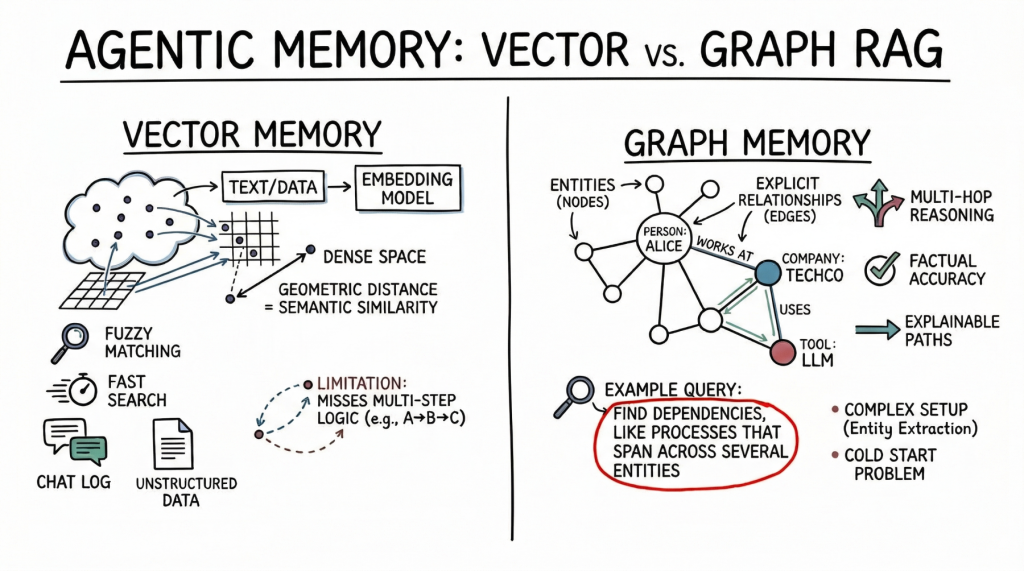
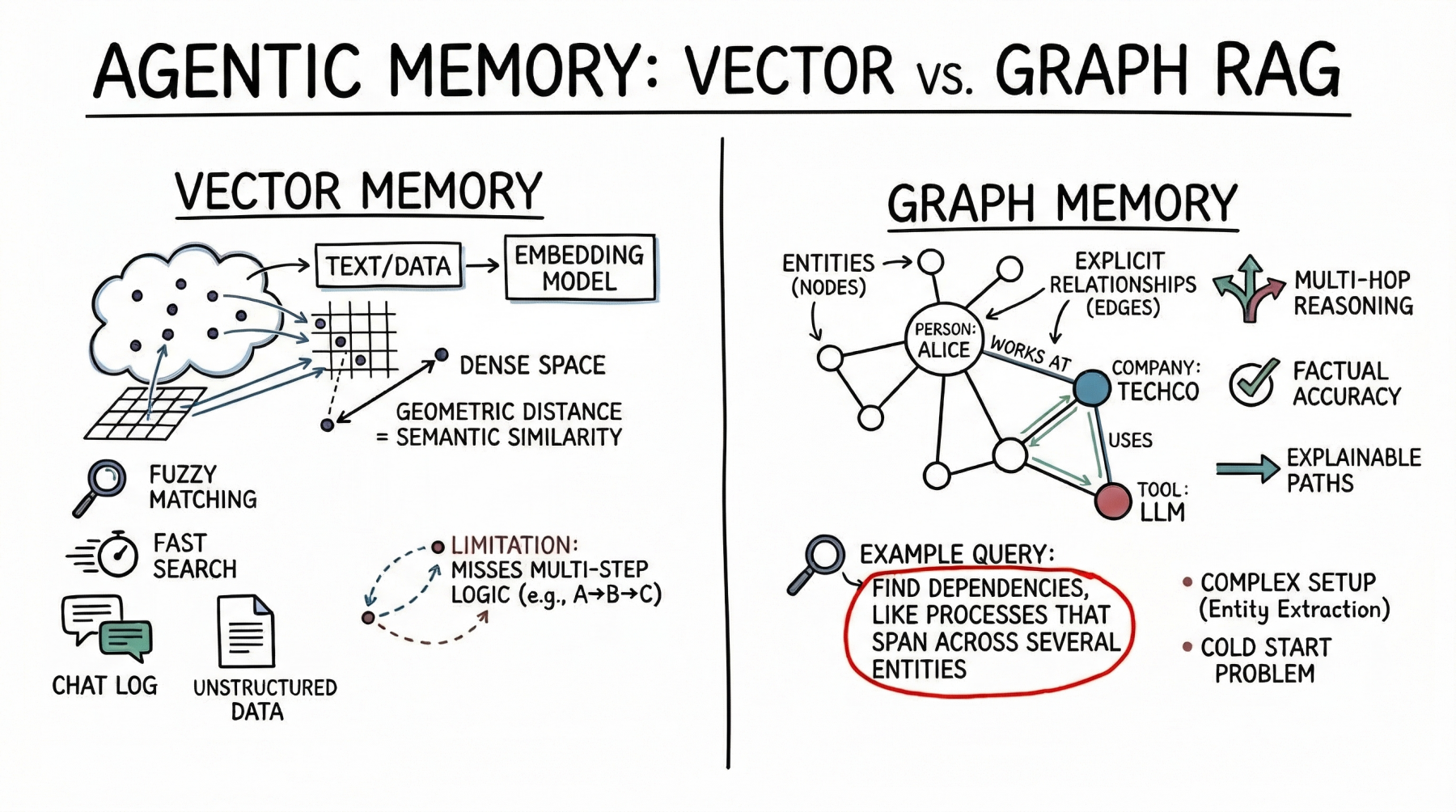
Vector databases signify reminiscence as dense mathematical vectors, or embeddings, located in high-dimensional area. An embedding mannequin maps textual content, pictures, or different information to arrays of floats, the place the geometric distance between two vectors corresponds to their semantic similarity.
AI brokers primarily use this method to retailer unstructured textual content. A standard use case is storing conversational historical past, permitting the agent to recall what a consumer beforehand requested by looking out its reminiscence financial institution for semantically associated previous interactions. Brokers additionally leverage vector shops to retrieve related paperwork, API documentation, or code snippets primarily based on the implicit which means of a consumer’s immediate, which is a much more strong method than counting on actual key phrase matches.
Vector databases are sturdy selections for agent reminiscence. They provide quick search, even throughout billions of vectors. Builders additionally discover them simpler to arrange than structured databases. To combine a vector retailer, you cut up the textual content, generate embeddings, and index the outcomes. These databases additionally deal with fuzzy matching properly, accommodating typos and paraphrasing with out requiring strict queries.
However semantic search has limits for superior agent reminiscence. Vector databases typically can’t comply with multi-step logic. As an example, if an agent wants to seek out the hyperlink between entity A and entity C however solely has information exhibiting that A connects to B and B connects to C, a easy similarity search could miss vital data.
These databases additionally battle when retrieving giant quantities of textual content or coping with noisy outcomes. With dense, interconnected information (from software program dependencies to firm organizational charts) they’ll return associated however irrelevant data. This may crowd the agent’s context window with much less helpful information.
Graph RAG: Structured Context and Relational Reminiscence
Graph RAG addresses the constraints of semantic search by combining data graphs with LLMs. On this paradigm, reminiscence is structured as discrete entities represented as nodes (for instance, an individual, an organization, or a expertise), and the express relationships between them are represented as edges (for instance, “works at” or “makes use of”).
Brokers utilizing graph RAG create and replace a structured world mannequin. As they collect new data, they extract entities and relationships and add them to the graph. When looking out reminiscence, they comply with express paths to retrieve the precise context.
The primary power of graph RAG is its precision. As a result of retrieval follows express relationships slightly than semantic closeness alone, the chance of error is decrease. If a relationship doesn’t exist within the graph, the agent can’t infer it from the graph alone.
Graph RAG excels at advanced reasoning and is right for answering structured questions. To search out the direct reviews of a supervisor who accredited a finances, you hint a path by means of the group and approval chain — a easy graph traversal, however a troublesome activity for vector search. Explainability is one other main benefit. The retrieval path is a transparent, auditable sequence of nodes and edges, not an opaque similarity rating. This issues for enterprise purposes that require compliance and transparency.
On the draw back, graph RAG introduces vital implementation complexity. It calls for strong entity-extraction pipelines to parse uncooked textual content into nodes and edges, which frequently requires rigorously tuned prompts, guidelines, or specialised fashions. Builders should additionally design and preserve an ontology or schema, which could be inflexible and troublesome to evolve as new domains are encountered. The cold-start downside can be distinguished: in contrast to a vector database, which is helpful the second you embed textual content, a data graph requires substantial upfront effort to populate earlier than it could possibly reply advanced queries.
The Comparability Framework: When to Use Which
When architecting reminiscence for an AI agent, remember that vector databases excel at dealing with unstructured, high-dimensional information and are properly suited to similarity search, whereas graph RAG is advantageous for representing entities and express relationships when these relationships are essential. The selection needs to be pushed by the info’s inherent construction and the anticipated question patterns.
Vector databases are ideally suited to purely unstructured information — chat logs, normal documentation, or sprawling data bases constructed from uncooked textual content. They excel when the question intent is to discover broad themes, corresponding to “Discover me ideas just like X” or “What have we mentioned relating to subject Y?” From a project-management perspective, they provide a low setup value and supply good normal accuracy, making them the default selection for early-stage prototypes and general-purpose assistants.
Conversely, graph RAG is preferable for information with inherent construction or semi-structured relationships, corresponding to monetary data, codebase dependencies, or advanced authorized paperwork. It’s the acceptable structure when queries demand exact, categorical solutions, corresponding to “How precisely is X associated to Y?” or “What are all of the dependencies of this particular element?” The upper setup value and ongoing upkeep overhead of a graph RAG system are justified by its skill to ship excessive precision on particular connections the place vector search would hallucinate, overgeneralize, or fail.
The way forward for superior agent reminiscence, nonetheless, doesn’t lie in selecting one or the opposite, however in a hybrid structure. Main agentic programs are more and more combining each strategies. A standard method makes use of a vector database for the preliminary retrieval step, performing semantic search to find probably the most related entry nodes inside a large data graph. As soon as these entry factors are recognized, the system shifts to graph traversal, extracting the exact relational context related to these nodes. This hybrid pipeline marries the broad, fuzzy recall of vector embeddings with the strict, deterministic precision of graph traversal.
Conclusion
Vector databases stay probably the most sensible place to begin for general-purpose agent reminiscence due to their ease of deployment and powerful semantic matching capabilities. For a lot of purposes, from buyer assist bots to fundamental coding assistants, they supply ample context retrieval.
Nonetheless, as we push towards autonomous brokers able to enterprise-grade workflows, consisting of brokers that should cause over advanced dependencies, guarantee factual accuracy, and clarify their logic, graph RAG emerges as a crucial unlock.
Builders could be properly suggested to undertake a layered method: begin agent reminiscence with a vector database for fundamental conversational grounding. Because the agent’s reasoning necessities develop and method the sensible limits of semantic search, selectively introduce data graphs to construction high-value entities and core operational relationships.
On this article, you’ll learn the way vector databases and graph RAG differ as reminiscence architectures for AI brokers, and when every method is the higher match.
Matters we’ll cowl embrace:
- How vector databases retailer and retrieve semantically related unstructured data.
- How graph RAG represents entities and relationships for exact, multi-hop retrieval.
- How to decide on between these approaches, or mix them in a hybrid agent-memory structure.
With that in thoughts, let’s get straight to it.
Vector Databases vs. Graph RAG for Agent Reminiscence: When to Use Which
Picture by Creator
Introduction
AI brokers want long-term reminiscence to be genuinely helpful in advanced, multi-step workflows. An agent with out reminiscence is actually a stateless perform that resets its context with each interplay. As we transfer towards autonomous programs that handle persistent duties (corresponding to like coding assistants that monitor venture structure or analysis brokers that compile ongoing literature critiques) the query of how one can retailer, retrieve, and replace context turns into crucial.
At present, the trade commonplace for this activity is the vector database, which makes use of dense embeddings for semantic search. But, as the necessity for extra advanced reasoning grows, graph RAG, an structure that mixes data graphs with giant language fashions (LLMs), is gaining traction as a structured reminiscence structure.
At a look, vector databases are perfect for broad similarity matching and unstructured information retrieval, whereas graph RAG excels when context home windows are restricted and when multi-hop relationships, factual accuracy, and complicated hierarchical buildings are required. This distinction highlights vector databases’ deal with versatile matching, in contrast with graph RAG’s skill to cause by means of express relationships and protect accuracy below tighter constraints.
To make clear their respective roles, this text explores the underlying principle, sensible strengths, and limitations of each approaches for agent reminiscence. In doing so, it gives a sensible framework to information the selection of system, or mixture of programs, to deploy.
Vector Databases: The Basis of Semantic Agent Reminiscence
Vector databases signify reminiscence as dense mathematical vectors, or embeddings, located in high-dimensional area. An embedding mannequin maps textual content, pictures, or different information to arrays of floats, the place the geometric distance between two vectors corresponds to their semantic similarity.
AI brokers primarily use this method to retailer unstructured textual content. A standard use case is storing conversational historical past, permitting the agent to recall what a consumer beforehand requested by looking out its reminiscence financial institution for semantically associated previous interactions. Brokers additionally leverage vector shops to retrieve related paperwork, API documentation, or code snippets primarily based on the implicit which means of a consumer’s immediate, which is a much more strong method than counting on actual key phrase matches.
Vector databases are sturdy selections for agent reminiscence. They provide quick search, even throughout billions of vectors. Builders additionally discover them simpler to arrange than structured databases. To combine a vector retailer, you cut up the textual content, generate embeddings, and index the outcomes. These databases additionally deal with fuzzy matching properly, accommodating typos and paraphrasing with out requiring strict queries.
However semantic search has limits for superior agent reminiscence. Vector databases typically can’t comply with multi-step logic. As an example, if an agent wants to seek out the hyperlink between entity A and entity C however solely has information exhibiting that A connects to B and B connects to C, a easy similarity search could miss vital data.
These databases additionally battle when retrieving giant quantities of textual content or coping with noisy outcomes. With dense, interconnected information (from software program dependencies to firm organizational charts) they’ll return associated however irrelevant data. This may crowd the agent’s context window with much less helpful information.
Graph RAG: Structured Context and Relational Reminiscence
Graph RAG addresses the constraints of semantic search by combining data graphs with LLMs. On this paradigm, reminiscence is structured as discrete entities represented as nodes (for instance, an individual, an organization, or a expertise), and the express relationships between them are represented as edges (for instance, “works at” or “makes use of”).
Brokers utilizing graph RAG create and replace a structured world mannequin. As they collect new data, they extract entities and relationships and add them to the graph. When looking out reminiscence, they comply with express paths to retrieve the precise context.
The primary power of graph RAG is its precision. As a result of retrieval follows express relationships slightly than semantic closeness alone, the chance of error is decrease. If a relationship doesn’t exist within the graph, the agent can’t infer it from the graph alone.
Graph RAG excels at advanced reasoning and is right for answering structured questions. To search out the direct reviews of a supervisor who accredited a finances, you hint a path by means of the group and approval chain — a easy graph traversal, however a troublesome activity for vector search. Explainability is one other main benefit. The retrieval path is a transparent, auditable sequence of nodes and edges, not an opaque similarity rating. This issues for enterprise purposes that require compliance and transparency.
On the draw back, graph RAG introduces vital implementation complexity. It calls for strong entity-extraction pipelines to parse uncooked textual content into nodes and edges, which frequently requires rigorously tuned prompts, guidelines, or specialised fashions. Builders should additionally design and preserve an ontology or schema, which could be inflexible and troublesome to evolve as new domains are encountered. The cold-start downside can be distinguished: in contrast to a vector database, which is helpful the second you embed textual content, a data graph requires substantial upfront effort to populate earlier than it could possibly reply advanced queries.
The Comparability Framework: When to Use Which
When architecting reminiscence for an AI agent, remember that vector databases excel at dealing with unstructured, high-dimensional information and are properly suited to similarity search, whereas graph RAG is advantageous for representing entities and express relationships when these relationships are essential. The selection needs to be pushed by the info’s inherent construction and the anticipated question patterns.
Vector databases are ideally suited to purely unstructured information — chat logs, normal documentation, or sprawling data bases constructed from uncooked textual content. They excel when the question intent is to discover broad themes, corresponding to “Discover me ideas just like X” or “What have we mentioned relating to subject Y?” From a project-management perspective, they provide a low setup value and supply good normal accuracy, making them the default selection for early-stage prototypes and general-purpose assistants.
Conversely, graph RAG is preferable for information with inherent construction or semi-structured relationships, corresponding to monetary data, codebase dependencies, or advanced authorized paperwork. It’s the acceptable structure when queries demand exact, categorical solutions, corresponding to “How precisely is X associated to Y?” or “What are all of the dependencies of this particular element?” The upper setup value and ongoing upkeep overhead of a graph RAG system are justified by its skill to ship excessive precision on particular connections the place vector search would hallucinate, overgeneralize, or fail.
The way forward for superior agent reminiscence, nonetheless, doesn’t lie in selecting one or the opposite, however in a hybrid structure. Main agentic programs are more and more combining each strategies. A standard method makes use of a vector database for the preliminary retrieval step, performing semantic search to find probably the most related entry nodes inside a large data graph. As soon as these entry factors are recognized, the system shifts to graph traversal, extracting the exact relational context related to these nodes. This hybrid pipeline marries the broad, fuzzy recall of vector embeddings with the strict, deterministic precision of graph traversal.
Conclusion
Vector databases stay probably the most sensible place to begin for general-purpose agent reminiscence due to their ease of deployment and powerful semantic matching capabilities. For a lot of purposes, from buyer assist bots to fundamental coding assistants, they supply ample context retrieval.
Nonetheless, as we push towards autonomous brokers able to enterprise-grade workflows, consisting of brokers that should cause over advanced dependencies, guarantee factual accuracy, and clarify their logic, graph RAG emerges as a crucial unlock.
Builders could be properly suggested to undertake a layered method: begin agent reminiscence with a vector database for fundamental conversational grounding. Because the agent’s reasoning necessities develop and method the sensible limits of semantic search, selectively introduce data graphs to construction high-value entities and core operational relationships.
















{kind=link}