



we’ve in all probability all had the expertise of getting responses that weren’t fairly what we wished. Often we’ll strive rewording the prompts a couple of instances till we get one thing cheap. We typically should be extra clear, extra exact, give examples, describe why we’d like the response, current a persona, or in any other case present sufficient context and data that the LLM is ready to present an acceptable response.
This may be high-quality once we’re working immediately with the LLM. Nevertheless, it’s fairly completely different once we’re writing an LLM-based utility — software program that can execute by itself, and that doing so will work together with a number of LLMs. Right here, the software program will work with predefined prompts and can move these to the LLMs. If it doesn’t go effectively, we’re not there to reword the prompts and check out once more. Which implies, they should be written in a method that’s strong and dependable within the first place — we’d like prompts that we may be assured will work persistently effectively in manufacturing.
Creating such a immediate may be difficult. On this article, we’ll go over why that’s, and in addition how a Python instrument known as DSPy can assist creating prompts that might be dependable. DSPy not solely generates prompts routinely for you, it additionally evaluates them totally, so that you may be assured of how effectively they’ll possible work in manufacturing.
I’ll additionally present an excerpt from my most up-to-date e-book with Manning Publishing, Constructing LLM Functions with DSPy, co-authored with Serj Smorodinsky. That gives an entire description of DSPy and how you can use it to create LLM-based functions.
 Guide cowl picture
Guide cowl picture
The trick of making a immediate that may work reliably in manufacturing
A part of what makes it tough to create a dependable immediate is that we will’t absolutely predict the enter we’ll have for the immediate. Say, for instance, we’re making a software program utility that can course of paperwork. The paperwork could also be discovered on-line, or probably submitted by customers of the software program. As a part of processing the paperwork, the appliance might ask an LLM to summarize them, translate them, extract key items of data, or to carry out another such activity. For this instance, let’s say the software program will ask the LLM to critique how believable the content material within the paperwork seems to be. To do this we might write a immediate akin to:
prompt_text = f"Assess how believable the next textual content is: {document_text}"That makes use of a Python f-string to kind the immediate, with a slot for the textual content of the doc. Different prompts might have a number of slots for the inputs, however for simplicity, we’ll assume right here that every immediate has only one enter — the piece of content material you’ll need the LLM to course of (which is the half that’s unpredictable).
This immediate may fit sufficiently effectively, however it additionally might not. There are any variety of methods the LLM might reply in a method we don’t like, a minimum of often. We might discover that the LLM picks up on irrelevant particulars within the paperwork. Or might have a distinct sense of ‘believable’ than we supposed. Or it could point out nearly each doc is absolutely believable (or the alternative, that nearly none are). Or the responses might not be formatted as we want.
We might have to tweak the immediate to persistently get the responses we might anticipate. To get began, we will do that and some different easy prompts, however the closing immediate might find yourself being significantly longer and extra detailed that this.
Often, as we check with extra inputs (on this case, extra paperwork), we’ll discover extra instances the place the present immediate doesn’t deal with the enter effectively, so we’ll tweak the immediate to deal with these instances higher. Typically we might reword the immediate to be extra clear, and different instances add some sentences to the immediate to deal with these particular instances. For instance, “If the doc makes claims which are metaphorical, assess the final intent and never the literal which means.” We will find yourself with any variety of further directions like this within the immediate, which can assist the immediate work effectively for these instances, however, in fact, can even trigger the immediate to work worse for different inputs.
And, because the prompts get longer and extra difficult, they’ll get more durable to tweak. It may well get much less and fewer clear what the impact might be of including, eradicating, re-ordering, or re-wording phrases within the immediate might be.
Different LLM-based functions may fit with different sorts of textual content information: textual content messages, emails, essays, journal articles, patent functions, and so forth. Or might course of picture, audio, video, or different modalities. However, no matter the kind of enter, for a non-trivial utility, the particular enter the appliance encounters (and passes on to the LLM) might be a minimum of considerably unpredictable. Which implies, we’ll want a strong, well-specified immediate to deal with a variety of real looking enter.
To take the instance of e mail, if an LLM-based utility is processing a set of emails (that it’s going to encounter in manufacturing, and that we will’t absolutely predict), there may be emails which are unusually: lengthy, advanced, nuanced, complicated, meandering, or in any other case not as we anticipated when forming the immediate. The one strategy to check that your utility will work reliably in manufacturing is to check with a big, numerous, and real looking set of inputs (on this case, a big, numerous assortment of real looking emails).
And for every check case, we have to rigorously study the LLM’s response and examine that it’s appropriate. In some instances, that is easy. For instance, we might move some textual content to an LLM and ask to categorise it ultimately. The LLM might classify the textual content when it comes to figuring out the language (English, French, and so on.), the sentiment, toxicity, and so forth. In these instances, there’s a real class for every enter, and there’s the category the LLM returns. We simply should examine they’re the identical: if the textual content is in Spanish and the LLM predicts Spanish, it’s appropriate; in any other case not. Many different LLM duties produce output that’s simple to judge as effectively.
In some instances, although, evaluating the responses is just not so easy. An instance is the place we ask the LLM to generate an extended response, akin to a abstract, translation, critique, ideas for follow-up steps, or every other such long-form output based mostly on the enter. Should you’ve ever checked out two or extra completely different responses from an LLM (the place each are a number of full sentences lengthy, and probably for much longer) and tried to evaluate which is best, you realize that is time consuming. And error susceptible. Some could also be extra succinct, others extra nuanced, others extra clear. However — as arduous as these are to judge — we do want to judge them to be able to assess how effectively every immediate we strive is working. One of many good issues about DSPy is, it enables you to automate this analysis.
Immediate Engineering
To see the worth of instruments like DSPy, it’s good to have a look at the choice, and on the downside that DSPy is fixing. Usually how we work with LLMs is utilizing a way referred to as immediate engineering. Doing this, we write one immediate, check it (often with only a few inputs and easily eye-balling the outputs), write one other immediate, check it in an analogous method, and proceed.
In less complicated instances, this could work, however it does have numerous limitations. One is: it’s very time-consuming to check every candidate immediate with greater than a small variety of inputs. So in follow, we usually check every immediate far lower than we must always. Which may trigger issues — testing every immediate with only a few inputs may give us a poor sense of which prompts work higher.
Making this extra difficult — with every enter, we actually ought to check the immediate a number of instances (and never simply as soon as), because the LLMs are stochastic. If given the identical immediate (together with the identical values within the slots) a number of instances, an LLM might return completely different responses every time. And a few could also be higher than others. If we have now, say, 20 paperwork to check with (in instance the place the LLM might be used to estimate the plausibility of every doc), ideally we’d check every a number of instances. If we check every 3 instances, which means 60 checks in whole. Which, realistically, we gained’t really do. Most likely not even shut.
And, as indicated, that is even more durable the place the place the LLMs return longer outputs, because it’s time-consuming to learn them, and nearly unattainable to be constant in how we consider them.
So, testing every candidate immediate is time consuming. Testing many candidate prompts is rather more so. And it’s not clear we will actually evaluate them pretty.
All because of this, generally, immediate engineering has the attention-grabbing high quality of being each time-consuming and unreliable. It’s a really gradual, tedious, and error-prone course of. Skilled builders can typically spend hours, and even days, on a single immediate. And ultimately, can’t make sure the one they selected is de facto the strongest.
Is there a greater method?
If we step again for a minute, we will have a look at how we deal with an analogous state of affairs when working with machine studying. If we’re constructing a neural community, Random Forest, XGBoost mannequin (or something alongside these traces), every time we prepare it, we don’t manually check every aspect within the check set one after the other. The truth is, the concept of doing that feels a bit foolish. The method is automated; testing is kind of easy. We merely run every aspect within the check set by the mannequin, get a prediction for every, and execute a operate to generate an general rating.
For instance, we might use Imply Squared Error or R Squared for a regression downside, and probably F1 Rating, MCC, or AUROC for a classification downside. Utilizing a instrument akin to scikit-learn, we will take the mannequin’s predictions for the check set and the corresponding floor fact values, and easily move these to a operate to calculate the general rating. We then have a single quantity indicating how effectively that mannequin labored.
We will subsequent, if we want, strive once more with completely different options, completely different hyperparameters, completely different coaching information (or another such change from the earlier mannequin), re-train, and re-execute the testing — getting one other rating.
So, with ML initiatives, we have now a course of that’s clear and environment friendly. However when working with LLMs, we are inclined to do one thing fairly completely different, one thing nearer to immediate engineering — working and not using a framework to make sure consistency, repeatability, and effectivity. We basically ignore many years of expertise growing finest practices for software program improvement.
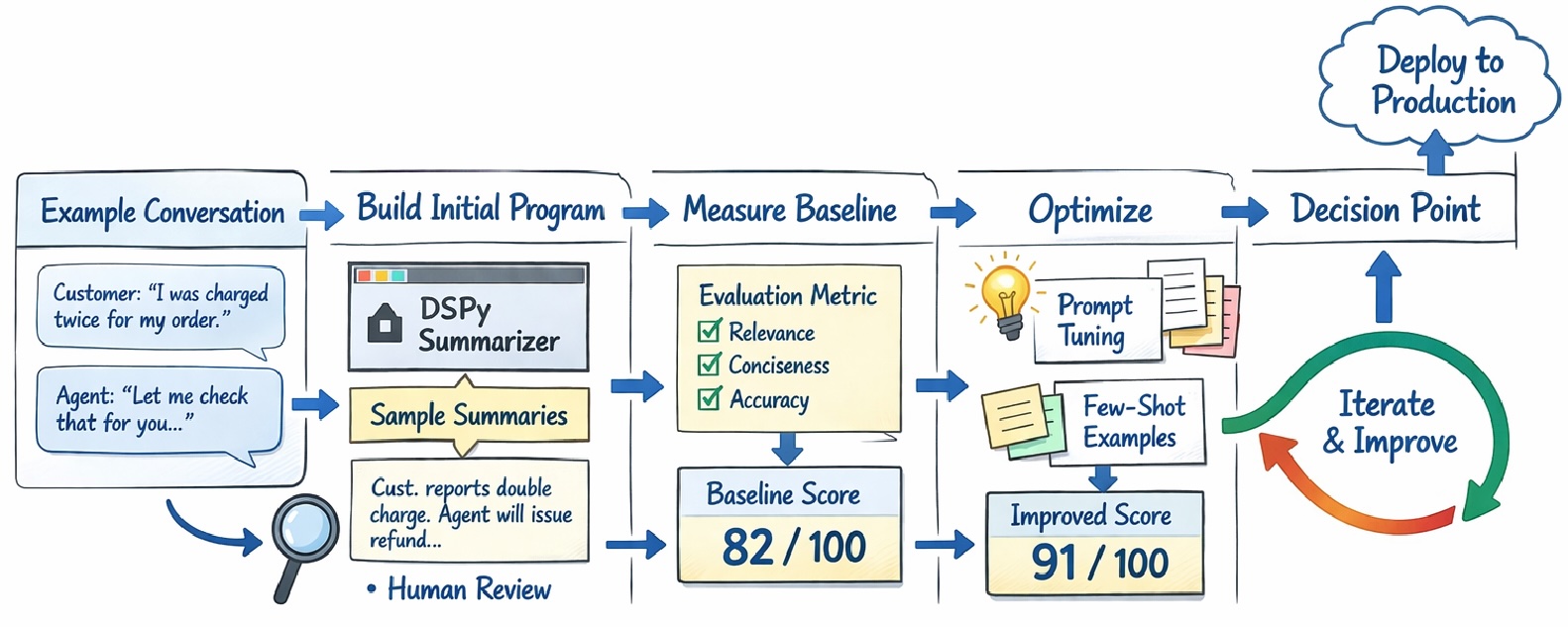
Nevertheless, that’s not mandatory. Working with LLMs, there are a selection of instruments that permit us work in an analogous method as we do when creating machine studying fashions — in a method that’s environment friendly, thorough, and repeatable. DSPy is probably going the cutting-edge of those, a minimum of in the intervening time. Utilizing it, we specify our check information and a way to judge how good a response is. There may be a while required to try this, however as soon as that’s performed, just about every little thing else is dealt with for us.
Within the instance the place we ask an LLM to estimate the plausibility of paperwork, we might collect a set of paperwork (probably 10 or 20 or 30, although extra is best) to be our check set. And for every, we might present a floor fact for its plausibility. This may very well be a numeric worth, let’s say, on a scale from 0 to 10.
We even have to offer a method for DSPy to evaluate how robust every LLM response is — within the type of a Python operate. This might be a operate that accepts the enter to the LLM and the LLM’s response, and that returns both: 1) a numeric worth (indicating how good the response is); or 2) a boolean worth (indicating merely if the response is sweet or unhealthy). On this instance, the operate may be pretty easy, alongside the traces of:
def evaluate_answer(test_instance, model_prediction):
return abs(test_instance.ground_truth - model_prediction)This isn’t exactly the DSPy syntax (I’m skipping some small particulars for simplicity right here, however this offers the final thought). On this case, we assume every check occasion comprises a doc that may be despatched to the LLM and a floor fact worth (a quantity between 0 and 10 — indicating how believable it really is, in all probability based mostly on human analysis). And we assume the mannequin prediction can also be a quantity between 0 and 10. To attain the response, we merely take the distinction between these two scores, so the smaller the distinction, the higher the response (the nearer it was to the bottom fact).
To check a given immediate, DSPy would routinely execute the immediate on a specified LLM, as soon as for every of the check paperwork. On this instance, for every, it might ask for a rating from 0 to 10 indicating their plausibility, and would evaluate the response to the bottom fact.
It could then give an general rating on the check set (averaged over all check cases within the check set), which is our estimate of how robust that immediate is.
Then, if we want to strive a distinct immediate, or a distinct LLM, we will merely re-execute the testing course of. That may generate one other rating, indicating how robust that mixture of LLM and immediate is. If we strive a number of prompts (or a number of LLMs), we will see which works finest simply by taking the one with the most effective general rating.
It’s a course of that makes loads of sense. It does require us to gather a good quantity of check information, however that is mandatory if we wish to present any form of analysis of a immediate in any case. And it requires us to put in writing a operate that may, given an enter to the LLM and the LLM’s response, rating how robust the response is. This is usually a bit of labor to do in some instances (we do clarify how to do that within the e-book!), however, as soon as written, we will consider any variety of responses to any variety of prompts. And it lets us achieve this in a method that’s constant and unbiased.
As indicated, if the LLM returns a brief reply, akin to with a classification downside, writing the operate goes to be very simple. And, as we simply noticed, the place the LLM returns a numeric rating, the operate can be fairly simple.
If the LLM returns an extended reply, typically (although not at all times) we’ll use an LLM-as-a-judge method, the place we get one LLM to judge the response of one other LLM. This isn’t excellent, however it does take away human biases, and it may be automated. Which makes it possible to check many candidate prompts and to check every totally.
So, DSPy basically does for you what you’d possible find yourself coding your self for those who took a step again and considered how you possibly can automate this course of — how you possibly can automate trying to find a robust immediate. A minimum of, you’d possible find yourself coding this your self for those who had an infinite quantity of free time, and have been the one particular person on the planet fixing this downside — the issue of getting to craft and consider many candidate prompts for every LLM-based activity. Nevertheless, given so many people are going through the identical challenges, having instruments maintain the repetitive work for us is, a minimum of looking back, very pure.
What DSPy does for you
DSPy does for you a lot of the work that you simply’d have to do manually if taking a immediate engineering method. It does a minimum of three main issues (really, it does a bit extra, however for this text, we’ll simply have a look at what are possible an important).
- It routinely generates a immediate for you. You merely want to offer a brief, high-level overview of the duty, which may be supplied in a string (or in different codecs, however strings are the best). On this instance, we might specify: “doc -> assessment_of_plausibility”. One other instance could also be: “journal_article -> abstract, critique”, which signifies that the LLM ought to take a journal article and return a abstract of it and a critique. DSPy does permit us to offer extra details about the duty as effectively, however typically we will maintain it fairly high-level.
- It routinely evaluates the immediate for you. You do want to offer the check information and a Python operate to judge every response, however provided that, DSPy means that you can absolutely, and persistently, consider every immediate (and every LLM) you strive.
- It routinely optimizes the immediate for you. That is probably probably the most highly effective aspect of DSPy. I’ll describe this subsequent.
Optimizing your prompts
To optimize your prompts DSPy basically goes right into a loop that appears like the next (this can be a bit over simplified; we do describe it absolutely within the e-book, however this offers the final thought):
best_prompt = ""
loop
generate a brand new candidate immediate
consider this candidate immediate
if that is the most effective immediate thus far:
best_prompt = present immediateThis loops for so long as you point out (the longer it searches for higher prompts, the stronger prompts it’ll have a tendency to search out, although there are, in fact, diminishing returns). Because it loops, it generates new candidate prompts. To do that, DSPy makes use of a way known as meta-prompting, the place one LLM is used to generate the immediate used for one more LLM. For every candidate immediate generated, DSPy then evaluates it.
With weaker prompts, DSPy may very well use early stopping for effectivity, and so might give up analysis early for any prompts that seem to carry out poorly relative to the previously-tested candidate prompts. That’s, if it generates any prompts that do poorly on a portion of the check information, there’s no want to check these prompts on the total check set. It’s going to, although, utterly consider the extra promising prompts, and so can determine with confidence the strongest of the prompts that have been examined.
DSPy contains numerous completely different processes to generate the prompts. The more practical really study as they go. As every candidate immediate is evaluated, DSPy can study the place every immediate performs effectively and the place it performs poorly (it may see which check instances do effectively and poorly, however DSPy can really additionally see why every immediate does effectively in some instances and poorly in others). It may well then make the most of this to counsel increasingly more promising candidate prompts, and so the prompts are inclined to work higher and higher as the method continues.
After working DSPy
When you’ve run DSPy, you’ll have a immediate to your activity and also you’ll even have an estimate of how effectively it’ll work in manufacturing — based mostly on how effectively it behaves in your check information. (Very like with machine studying, we typically divide the information we have now into coaching, validation, and check information, so will ideally have a maintain out set used just for a closing analysis).
That may present an excellent foundation for deciding if it’s robust sufficient to place in manufacturing or not. If not, you possibly can allocate extra time to optimizing the immediate. Or you possibly can have a look at one other LLM — as soon as your code is ready up, evaluating one other LLM simply requires specifying the LLM and re-executing the code. You’ll have to pay for the LLM calls (until utilizing a hosted LLM), however you’ll have possible zero extra work to do.
Pattern code
More often than not the code you’ll want to put in writing to make use of DSPy might be fairly quick and easy. I’ll embrace an instance right here, although gained’t absolutely clarify it (I’ll, hopefully, in future articles). This could, although, provide the gist of what’s concerned with working with DSPy. It does require a pip set up and a few imports. After getting that, it’s all pretty easy.
import dspy
OPENAI_API_KEY = [indicate your API key]
lm = dspy.LM("openai/gpt-4o-mini", api_key=OPENAI_API_KEY)
dspy.settings.configure(lm=lm)
predictor = dspy.Predict("query, context -> reply, confidence")
prediction = predictor(query="What's the capital of France?", context="")
print(prediction.reply, prediction.confidence)This code doesn’t embrace any optimization or analysis (it’ll merely produce a immediate and deal with interacting with the LLM), however does present a completely working DSPy programme. It first imports dspy, then specifies the LLM to make use of and the API key for that. On this instance, an OpenAI mannequin is used, however DSPy helps dozens of various suppliers. It then specifies at a excessive stage the duty: given a query and a few context, the LLM ought to return the reply and the arrogance for that reply. It then asks a particular query (on this instance, “What’s the capital of France?”, with none extra context), and shows the reply. In testing this, we persistently acquired:
Paris, ExcessiveThis means the reply is Paris and that the LLM has excessive confidence within the reply.
Given some analysis and optimization, the code might be a bit longer, however not gigantically. This instance reveals a quite simple activity, however with tougher duties, analysis and optimization will usually be necessary. Doing that is all fairly manageable, as DSPy retains a lot of the complexity underneath the hood.
Conclusions
DSPy can’t assure a particularly efficient immediate for each activity with each LLM. However, it does prevent loads of labour, and can are inclined to do as effectively, or higher, than an expert immediate engineer will do. In future articles, I’ll hopefully cowl some experiments pitting DSPy towards handbook immediate engineering, however in a nutshell, DSPy has come out forward persistently thus far. For any LLM-based functions we create, it’s often price utilizing DSPy to create and consider the prompts. The framework doesn’t take too lengthy to study, and when you do, you’re set on any initiatives you’re employed on.
Realistically, I gained’t at all times use DSPy in contexts the place I don’t want a robust immediate, or the place the duty is so easy for an LLM that any primary immediate will do. However any time I’m in a state of affairs the place it appears to be like like I’ll have to do some immediate engineering, I’d use DSPy to automate all that work for me. As an alternative of manually creating and testing each candidate immediate, I can simply arrange some DSPy code and let it do the work. It’s like having my very own immediate engineering assistant.
It may well take a while to execute. I’ll typically let it run for 20 or half-hour or extra to get an excellent immediate. Nevertheless it’s doing the work, not me. One factor to look at for is LLM prices, although DSPy does allow you to monitor that. Normally, having greater high quality prompts is cheaper in the long term, although in some instances that gained’t be true, and we must always constrain the time DSPy spends making an attempt to provide you with stronger prompts.
That is simple sufficient to do — we simply should watch out to specify to spend an inexpensive period of time trying to find the most effective immediate it may discover. We will, for instance, specify to simply strive a small variety of candidate prompts and take the strongest. In different instances it may be effectively price letting it check many candidate prompts.
I’ll hopefully get some extra articles up explaining DSPy sooner or later.















{kind=link}