


- : Why I Wrote This
- The Evolution of Device Integration with LLMs
- What Is Mannequin Context Protocol (MCP), Actually?
- Wait, MCP seems like RAG… however is it?
- Fast recap!
- Core Capabilities of an MCP Server
- Actual-World Instance: Claude Desktop + MCP (Pre-built Servers)
- Construct Your Personal: Customized MCP Server from Scratch
- 🎉 Congrats, You’ve Mastered MCP!
- References
: Why I Wrote This
I will probably be sincere. Once I first noticed the time period “Mannequin Context Protocol (mcp),” I did what most builders do when confronted with yet one more new acronym: I skimmed a tutorial, noticed some JSON, and quietly moved on. “Too summary,” I assumed. Quick-forward to once I really tried to combine some customized instruments with Claude Desktop— one thing that wanted reminiscence or entry to exterior instruments — and all of the sudden, MCP wasn’t simply related. It was important.
The issue? Not one of the tutorials I got here throughout felt beginner-friendly. Most jumped straight into constructing a customized MCP server with out explaining in particulars why you’d want a server within the first place — not to mention mentioning that prebuilt MCP servers exist already and work out of the field. So, I made a decision to be taught it from the bottom up.
I learn every little thing I may, experimented with each prebuilt and customized servers, built-in it with Claude Desktop and examined whether or not I may clarify it to my pals —folks with zero prior context. Once I lastly received the nod from them, I knew I may break it down for anybody, even for those who’ve by no means heard of MCP till 5 minutes in the past.
This text breaks down what MCP is, why it issues, and the way it compares to different widespread architectures like RAG. We’ll go from “what even is that this?” to spinning up your personal working Claude integration — no prior MCP data required. Should you’ve ever struggled to get your AI mannequin to really feel rather less like a goldfish, that is for you.
The Evolution of Device Integration with LLMs
Earlier than diving into MCP, let’s perceive the development of how we join Giant Language Fashions (LLMs) to exterior instruments and information:

- Standalone LLMs: Initially, fashions like GPT and Claude operated in isolation, relying solely on their coaching information. They couldn’t entry real-time info or work together with exterior programs.
- Device Binding: As LLMs superior, builders created strategies to “bind” instruments on to fashions. For instance, with LangChain or related frameworks, you can do one thing like:
llm = ChatAnthropic()
augmented_llm = llm.bind_tools([search_tool, calculator_tool])This works properly for particular person scripts however doesn’t scale simply throughout functions. Why? As a result of device binding in frameworks like LangChain is often designed round single-session, stateless interactions, that means each time you spin up a brand new agent or perform name, you’re typically re-defining which instruments it may well entry. There’s no centralized option to handle instruments throughout a number of interfaces or person contexts.
3. Utility Integration Problem: The actual complexity arises once you need to combine instruments with AI-powered functions like IDEs (Cursor, VS Code), chat interfaces (Claude Desktop), or different productiveness instruments. Every utility would wish customized connectors for each doable device or information supply, making a tangled net of integrations.
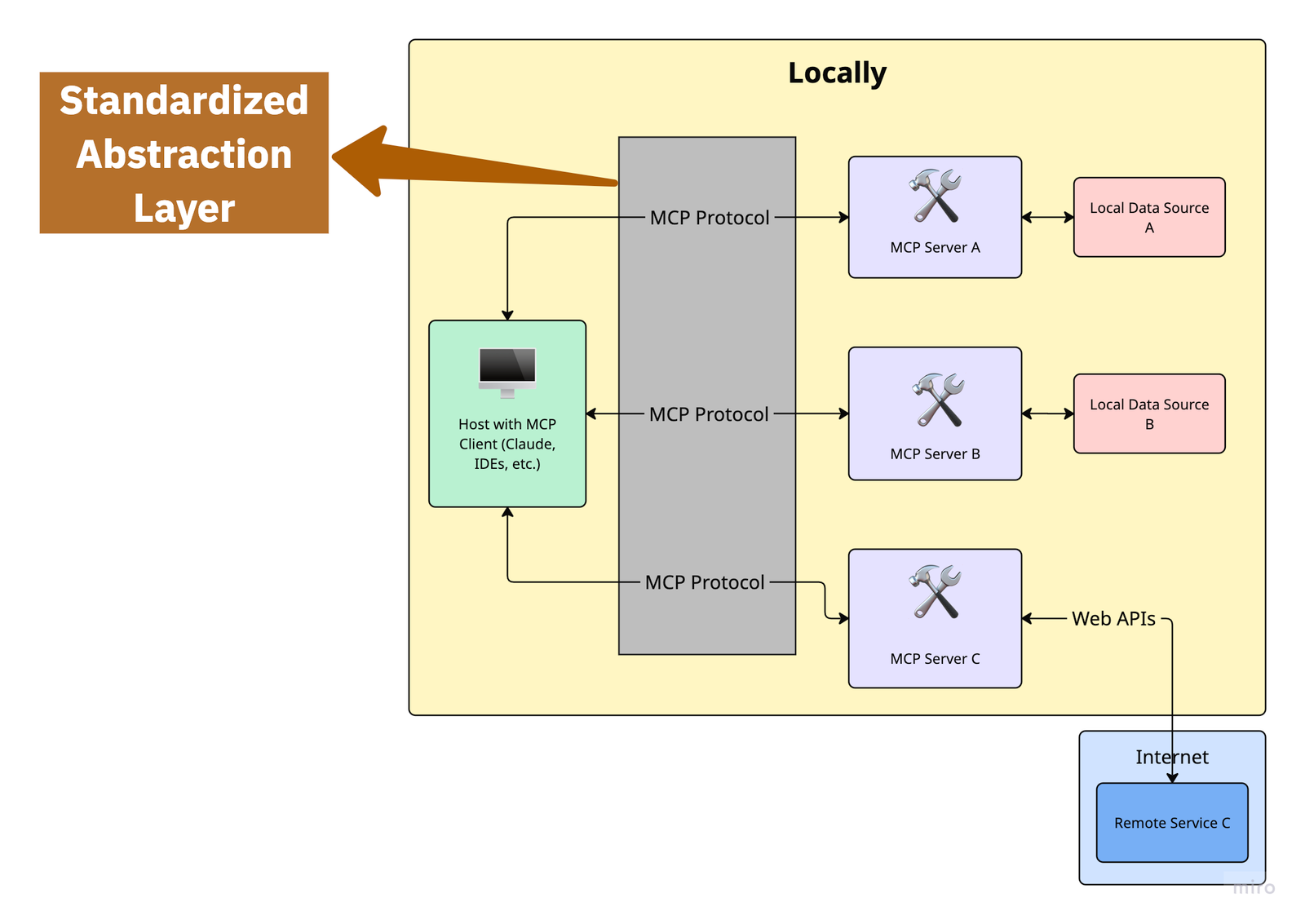
That is the place MCP enters the image — offering a standardized layer of abstraction for connecting AI functions to exterior instruments and information sources.
What Is Mannequin Context Protocol (MCP), Actually?
Let’s break it down:
- Mannequin: The LLM on the coronary heart of your utility — GPT, Claude, no matter. It’s a strong reasoning engine however restricted by what it was educated on and the way a lot context it may well maintain.
- Context: The additional info your mannequin must do its job — paperwork, search outcomes, person preferences, current historical past. Context extends the mannequin’s capabilities past its coaching set.
- Protocol: A standardized means of speaking between parts. Consider it as a typical language that lets your mannequin work together with instruments and information sources in a predictable means.
Put these three collectively, and MCP turns into a framework that connects fashions to contextual info and instruments via a constant, modular, and interoperable interface.
Very like HTTP enabled the net by standardizing how browsers speak to servers, MCP standardizes how AI functions work together with exterior information and capabilities.
Professional tip! A straightforward option to visualize MCP is to think about it like device binding for the complete AI stack, not only a single agent. That’s why Anthropic describes MCP as “a USB-C port for AI functions.”

Wait, MCP seems like RAG… however is it?
Lots of people ask, “How is that this completely different from RAG?” Nice query.
At a look, each MCP and RAG purpose to unravel the identical drawback: give language fashions entry to related, exterior info. However how they do it — and the way maintainable they’re — differs considerably.
In an MCP-based setup
- Your AI app (host/shopper) connects to an MCP doc server
- You work together with context utilizing a standardized protocol
- You may add new paperwork or instruments with out modifying the app
- Every thing works through the identical interface, persistently

In a conventional RAG system
- Your app manually builds and queries a vector database
- You typically want customized embedding logic, retrievers, and loaders
- Including new sources means rewriting a part of your app code
- Each integration is bespoke, tightly coupled to your app logic
The important thing distinction is abstraction: The Protocol in Mannequin Context Protocol is nothing however a standardized abstraction layer that defines bidirectional communication between MCP Consumer/Host and MCP Servers.

MCP provides your app the flexibility to ask, “Give me details about X,” with out realizing how that data is saved or retrieved. RAG programs require your app to handle all of that.
With MCP, your utility logic stays the identical, whilst your doc sources evolve.
Let’s take a look at some high-level codes to see how these approaches differ:
Conventional RAG Implementation
In a conventional RAG implementation, your utility code immediately manages connections to doc sources:
# Hardcoded vector retailer logic
vectorstore = FAISS.load_local("retailer/embeddings")
retriever = vectorstore.as_retriever()
response = retriever.invoke("question about LangGraph")With device binding, you outline instruments and bind them to an LLM, however nonetheless want to switch the device implementation to include new information sources. You continue to have to replace the device implementation when your backend modifications.
@device
def search_docs(question: str):
return search_vector_store(question)MCP Implementation
With MCP, your utility connects to a standardized interface, and the server handles the specifics of doc sources:
# MCP Consumer/Host: Consumer/Host stays the identical
# MCP Server: Outline your MCP server
# Import obligatory libraries
from typing import Any
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("your-server")
# Implement your server's instruments
@mcp.device()
async def example_tool(param1: str, param2: int) -> str:
"""An instance device that demonstrates MCP performance.
Args:
param1: First parameter description
param2: Second parameter description
Returns:
A string consequence from the device execution
"""
# Device implementation
consequence = f"Processed {param1} with worth {param2}"
return consequence
# Instance of including a useful resource (elective)
@mcp.useful resource()
async def get_example_resource() -> bytes:
"""Gives instance information as a useful resource.
Returns:
Binary information that may be learn by shoppers
"""
return b"Instance useful resource information"
# Instance of including a immediate template (elective)
mcp.add_prompt(
"example-prompt",
"It is a template for {{function}}. You need to use it to {{motion}}."
)
# Run the server
if __name__ == "__main__":
mcp.run(transport="stdio")Then, you configure the host or shopper (like Claude Desktop) to make use of the server by updating its configuration file.
{
"mcpServers": {
"your-server": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/PARENT/FOLDER/your-server",
"run",
"your-server.py"
]
}
}
}Should you change the place or how the sources/paperwork are saved, you replace the server — not the shopper.
That’s the magic of abstraction.
And for a lot of use circumstances — particularly in manufacturing environments like IDE extensions or industrial functions — you can’t contact the shopper code in any respect. MCP’s decoupling is greater than only a nice-to-have: it’s a necessity. It isolates the appliance code in order that solely the server-side logic (instruments, information sources, or embeddings) must evolve. The host utility stays untouched. This permits fast iteration and experimentation with out risking regression or violating utility constraints.
Fast recap!
Hopefully, by now, it’s clear why MCP really issues.
Think about you’re constructing an AI assistant that should:
- Faucet right into a data base
- Execute code or scripts
- Hold monitor of previous person conversations
With out MCP, you’re caught writing customized glue code for each single integration. Positive, it really works — till it doesn’t. It’s fragile, messy, and a nightmare to take care of at scale.
MCP fixes this by appearing as a common adapter between your mannequin and the skin world. You may plug in new instruments or information sources with out rewriting your mannequin logic. Which means sooner iteration, cleaner code, fewer bugs, and AI functions which can be really modular and maintainable.
And I hope you had been paying consideration once I stated MCP permits bidirectional communication between the host (shopper) and the server — as a result of this unlocks considered one of MCP’s strongest use circumstances: persistent reminiscence.
Out of the field, LLMs are goldfish. They neglect every little thing except you manually stuff the complete historical past into the context window. However with MCP, you possibly can:
- Retailer and retrieve previous interactions
- Hold monitor of long-term person preferences
- Construct assistants that really “keep in mind” full initiatives or ongoing periods
No extra clunky prompt-chaining hacks or fragile reminiscence workarounds. MCP provides your mannequin a mind that lasts longer than a single chat.
Core Capabilities of an MCP Server
With all that in thoughts, it’s fairly clear: the MCP server is the MVP of the entire protocol.
It’s the central hub that defines the capabilities your mannequin can really use. There are three most important varieties:
- Assets: Consider these as exterior information sources — PDFs, APIs, databases. The mannequin can pull them in for context, however it may well’t change them. Learn-only.
- Instruments: These are the precise capabilities the mannequin can name — run code, search the net, generate summaries, you identify it.
- Prompts: Predefined templates that information the mannequin’s conduct or construction its responses. Like giving it a playbook.
What makes MCP highly effective is that each one of those are uncovered via a single, constant protocol. Which means the mannequin can request, invoke, and incorporate them with no need customized logic for each. Simply plug into the MCP server, and every little thing’s able to go.
Actual-World Instance: Claude Desktop + MCP (Pre-built Servers)
Out of the field, Anthropic provides a bunch of pre-built MCP servers you possibly can plug into your AI apps — issues like Claude Desktop, Cursor, and extra. Setup is tremendous fast and painless.
For the total checklist of obtainable servers, head over to the MCP Servers Repository. It’s your buffet of ready-to-use integrations.
On this part, I’ll stroll you thru a sensible instance: extending Claude Desktop so it may well learn out of your laptop’s file system, write new information, transfer them round, and even search via them.
This walkthrough is predicated on the Quickstart information from the official docs, however truthfully, that information skips just a few key particulars — particularly for those who’ve by no means touched these settings earlier than. So I’m filling within the gaps and sharing the additional suggestions I picked up alongside the way in which to avoid wasting you the headache.
1. Obtain Claude Desktop
First issues first — seize Claude Desktop. Select the model for macOS or Home windows (sorry Linux people, no help simply but).
Comply with the set up steps as prompted.
Have already got it put in? Be sure to’re on the newest model by clicking the Claude menu in your laptop and choosing “Test for Updates…”
2. Test the Conditions
You’ll want Node.js put in in your machine to get this operating easily.
To examine if you have already got Node put in:
- On macOS: Open the Terminal out of your Functions folder.
- On Home windows: Press
Home windows + R, kindcmd, and hit Enter. - Then run the next command in your terminal:
node --versionShould you see a model quantity, you’re good to go. If not, head over to nodejs.org and set up the newest LTS model.
3. Allow Developer Mode
Open Claude Desktop and click on on the “Claude” menu within the top-left nook of your display screen. From there, choose Assist.
On macOS, it ought to look one thing like this:

From the drop-down menu, choose “Allow Developer Mode.”
Should you’ve already enabled it earlier than, it gained’t present up once more — but when that is your first time, it ought to be proper there within the checklist.
As soon as Developer Mode is turned on:
- Click on on “Claude” within the top-left menu once more.
- Choose “Settings.”
- A brand new pop-up window will seem — search for the “Developer” tab within the left-hand navigation bar. That’s the place all the good things lives.

4. Set Up the Configuration File
Nonetheless within the Developer settings, click on on “Edit Config.”
This may create a configuration file if one doesn’t exist already and open it immediately in your file system.
The file location is dependent upon your OS:
- macOS:
~/Library/Utility Help/Claude/claude_desktop_config.json - Home windows:
%APPDATApercentClaudeclaude_desktop_config.json
That is the place you’ll outline the servers and capabilities you need Claude to make use of — so maintain this file open, we’ll be enhancing it subsequent.

Open the config file (claude_desktop_config.json) in any textual content editor. Exchange its contents with the next, relying in your OS:
For macOS:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"/Users/username/Desktop",
"/Users/username/Downloads"
]
}
}
}For Home windows:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"C:UsersusernameDesktop",
"C:UsersusernameDownloads"
]
}
}
}Be sure that to exchange "username" together with your precise system username. The paths listed right here ought to level to legitimate folders in your machine—this setup provides Claude entry to your Desktop and Downloads, however you possibly can add extra paths if wanted.
What This Does
This config tells Claude Desktop to mechanically begin an MCP server referred to as "filesystem" each time the app launches. That server runs utilizing npx and spins up @modelcontextprotocol/server-filesystem, which is what lets Claude work together together with your file system—learn, write, transfer information, search directories, and so on.
⚠️ Command Privileges
Only a heads-up: Claude will run these instructions together with your person account’s permissions, that means it may well entry and modify native information. Solely add instructions to the config file for those who perceive and belief the server you’re hooking up — no random packages from the web!
5. Restart Claude
When you’ve up to date and saved your configuration file, restart Claude Desktop to use the modifications.
After it boots up, it’s best to see a hammer icon within the bottom-left nook of the enter field. That’s your sign that the developer instruments — and your customized MCP server — are up and operating.

After clicking the hammer icon, it’s best to see the checklist of instruments uncovered by the Filesystem MCP Server — issues like studying information, writing information, looking out directories, and so forth.

Should you don’t see your server listed or nothing exhibits up, don’t fear. Leap over to the Troubleshooting part within the official documentation for some fast debugging tricks to get issues again on monitor.
6. Strive It Out!
Now that every little thing’s arrange, you can begin chatting with Claude about your file system — and it ought to know when to name the suitable instruments.
Right here are some things you possibly can strive asking:
- “Are you able to write a poem and put it aside to my Desktop?”
- “What are some work-related information in my Downloads folder?”
- “Can you are taking all the photographs on my Desktop and transfer them to a brand new folder referred to as ‘Photos’?”
When wanted, Claude will mechanically invoke the suitable instruments and ask on your approval earlier than doing something in your system. You keep in management, and Claude will get the job executed.
Construct Your Personal: Customized MCP Server from Scratch
Alright, able to stage up?
On this part, you’ll go from person to builder. We’re going to put in writing a customized MCP server that Claude can speak to — particularly, a device that lets it search the newest documentation from AI libraries like LangChain, OpenAI, MCP (sure, we’re utilizing MCP to be taught MCP), and LlamaIndex.
As a result of let’s be sincere — what number of occasions have you ever watched Claude confidently spit out deprecated code or reference libraries that haven’t been up to date since 2021?
This device makes use of real-time search, scrapes dwell content material, and provides your assistant contemporary data on demand. Sure, it’s as cool because it sounds.
The mission is constructed utilizing the official MCP SDK from Anthropic. Should you’re comfy with Python and the command line, you’ll be up and operating very quickly. And even for those who’re not — don’t fear. We’ll stroll via every little thing step-by-step, together with the elements most tutorials simply assume you already know.
Conditions
Earlier than we dive in, listed here are the belongings you want put in in your system:
- Python 3.10 or larger — that is the programming language we’ll use
- MCP SDK (v1.2.0 or larger) — this provides you all of the instruments to create a Claude-compatible server (which will probably be put in in upcoming elements)
- uv (bundle supervisor) — consider it like a contemporary model of pip, however a lot sooner and simpler to make use of for initiatives (which will probably be put in in upcoming elements)
Step 1: Set up uv (the Bundle Supervisor)
I
On macOS/Linux:
curl –LsSf https://astral.sh/uv/set up.sh | shOn Home windows:
powershell –ExecutionPolicy ByPass -c "irm https://astral.sh/uv/set up.ps1 | iex"This may obtain and set up uv in your machine. As soon as it’s executed, shut and reopen your terminal to verify the uv command is acknowledged. (Should you’re on Home windows, you should use WSL or comply with their Home windows directions.)
To examine that it’s working, run this command in your terminal:
uv --versionShould you see a model quantity, you’re good to go.
Step 2: Set Up Your Mission
Now we’re going to create a folder for our MCP server and get all of the items in place. In your terminal, run these instructions:
# Create and enter your mission folder
uv init mcp-server
cd mcp-server
# Create a digital surroundings
uv venv
# Activate the digital surroundings
supply .venv/bin/activate # Home windows: .venvScriptsactivateWait — what’s all this?
uv init mcp-serverunits up a clean Python mission namedmcp-server.uv venvcreates a digital surroundings (your non-public sandbox for this mission).supply .venv/bin/activateactivates that surroundings so every little thing you put in stays inside it.
Step 3: Set up the Required Packages
Inside your digital surroundings, set up the instruments you’ll want:
uv add "mcp[cli]" httpx beautifulsoup4 python-dotenvRight here’s what every bundle does:
mcp[cli]: The core SDK that permits you to construct servers Claude can speak tohttpx: Used to make HTTP requests (like fetching information from web sites)beautifulsoup4: Helps us extract readable textual content from messy HTMLpython-dotenv: Lets us load API keys from a.envfile
Earlier than we begin writing code, it’s a good suggestion to open the mission folder in a textual content editor so you possibly can see all of your information in a single place and edit them simply.
Should you’re utilizing VS Code (which I extremely suggest for those who’re undecided what to make use of), simply run this from inside your mcp-server folder:
code .This command tells VS Code to open the present folder (. simply means “proper right here”).
🛠️ If the
codecommand doesn’t work, you in all probability have to allow it:1. Open VS Code
2. Press
Cmd+Shift+P(orCtrl+Shift+Pon Home windows)3. Sort:
Shell Command: Set up 'code' command in PATH4. Hit Enter, then restart your terminal
Should you’re utilizing one other editor like PyCharm or Chic Textual content, you possibly can simply open the
mcp-serverfolder manually from throughout the app.
Step 3.5: Get Your Serper API Key (for Internet Search)
To energy our real-time documentation search, we’ll use Serper — a easy and quick Google Search API that works nice for AI brokers.
Right here’s how one can set it up:
- Head over to serper.dev and click on Signal Up:
It’s free for fundamental utilization and works completely for this mission. - As soon as signed in, go to your Dashboard:
You’ll see your API Key listed there. Copy it. - In your mission folder, create a file referred to as
.env:That is the place we’ll retailer the important thing securely (so we’re not hardcoding it). - Add this line to your
.envfile:
SERPER_API_KEY=your-api-key-hereExchange your-api-key-here with the precise key you copied
That’s it — now your server can speak to Google through Serper and pull in contemporary docs when Claude asks.
Step 4: Write the Server Code
Now that your mission is about up and your digital surroundings is operating, it’s time to really write the server.
This server goes to:
- Settle for a query like: “How do I exploit retrievers in LangChain?”
- Know which documentation web site to go looking (e.g., LangChain, OpenAI, and so on.)
- Use an online search API (Serper) to seek out the perfect hyperlinks from that web site
- Go to these pages and scrape the precise content material
- Return that content material to Claude
That is what makes your Claude smarter — it may well look issues up from actual docs as an alternative of creating issues up primarily based on previous information.
⚠️ Fast Reminder About Moral Scraping
At all times respect the positioning you’re scraping. Use this responsibly. Keep away from hitting pages too typically, don’t scrape behind login partitions, and examine the positioning’s robots.txt file to see what’s allowed. You may learn extra about it right here.
Your device is simply as helpful as it’s respectful. That’s how we construct AI programs that aren’t simply good — however sustainable too.
1. Create Your Server File
First, run this from inside your mcp-server folder to create a brand new file:
contact most important.pyThen open that file in your editor (if it isn’t open already). Exchange the code there with the next:
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
import httpx
import json
import os
from bs4 import BeautifulSoup
load_dotenv()
mcp = FastMCP("docs")
USER_AGENT = "docs-app/1.0"
SERPER_URL = "https://google.serper.dev/search"
docs_urls = {
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/secure",
"openai": "platform.openai.com/docs",
"mcp": "modelcontextprotocol.io"
}
async def search_web(question: str) -> dict | None:
payload = json.dumps({"q": question, "num": 2})
headers = {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content material-Sort": "utility/json",
}
async with httpx.AsyncClient() as shopper:
strive:
response = await shopper.put up(
SERPER_URL, headers=headers, information=payload, timeout=30.0
)
response.raise_for_status()
return response.json()
besides httpx.TimeoutException:
return {"natural": []}
besides httpx.HTTPStatusError as e:
print(f"HTTP error occurred: {e}")
return {"natural": []}
async def fetch_url(url: str) -> str:
async with httpx.AsyncClient(headers={"Person-Agent": USER_AGENT}) as shopper:
strive:
response = await shopper.get(url, timeout=30.0)
response.raise_for_status()
soup = BeautifulSoup(response.textual content, "html.parser")
# Attempt to extract most important content material and take away navigation, sidebars, and so on.
main_content = soup.discover("most important") or soup.discover("article") or soup.discover("div", class_="content material")
if main_content:
textual content = main_content.get_text(separator="n", strip=True)
else:
textual content = soup.get_text(separator="n", strip=True)
# Restrict content material size if it is too giant
if len(textual content) > 8000:
textual content = textual content[:8000] + "... [content truncated]"
return textual content
besides httpx.TimeoutException:
return "Timeout error when fetching the URL"
besides httpx.HTTPStatusError as e:
return f"HTTP error occurred: {e}"
@mcp.device()
async def get_docs(question: str, library: str) -> str:
"""
Search the newest docs for a given question and library.
Helps langchain, openai, mcp and llama-index.
Args:
question: The question to seek for (e.g. "Chroma DB")
library: The library to go looking in (e.g. "langchain")
Returns:
Textual content from the docs
"""
if library not in docs_urls:
elevate ValueError(f"Library {library} not supported by this device. Supported libraries: {', '.be part of(docs_urls.keys())}")
question = f"web site:{docs_urls[library]} {question}"
outcomes = await search_web(question)
if not outcomes or len(outcomes.get("natural", [])) == 0:
return "No outcomes discovered"
combined_text = ""
for i, end in enumerate(outcomes["organic"]):
url = consequence["link"]
title = consequence.get("title", "No title")
# Add separator between outcomes
if i > 0:
combined_text += "nn" + "="*50 + "nn"
combined_text += f"Supply: {title}nURL: {url}nn"
page_content = await fetch_url(url)
combined_text += page_content
return combined_text
if __name__ == "__main__":
mcp.run(transport="stdio")2. How The Code Works
First, we arrange the muse of our customized MCP server. It pulls in all of the libraries you’ll want — like instruments for making net requests, cleansing up webpages, and loading secret API keys. It additionally creates your server and names it "docs" so Claude is aware of what to name. Then, it lists the documentation websites (like LangChain, OpenAI, MCP, and LlamaIndex) your device will search via. Lastly, it units the URL for the Serper API, which is what the device will use to ship Google search queries. Consider it as prepping your workspace earlier than really constructing the device.
Click on right here to see the revelant code snippet
from mcp.server.fastmcp import FastMCP
from dotenv import load_dotenv
import httpx
import json
import os
from bs4 import BeautifulSoup
load_dotenv()
mcp = FastMCP("docs")
USER_AGENT = "docs-app/1.0"
SERPER_URL = "https://google.serper.dev/search"
docs_urls = {
"langchain": "python.langchain.com/docs",
"llama-index": "docs.llamaindex.ai/en/secure",
"openai": "platform.openai.com/docs",
"mcp": "modelcontextprotocol.io"
}Then, we outline a perform that lets our device speak to the Serper API, which we’ll use as a wrapper round Google Search.
This perform, search_web, takes in a question string, builds a request, and sends it off to the search engine. It contains your API key for authentication, tells Serper we’re sending JSON, and limits the variety of search outcomes to 2 for pace and focus. The perform returns a dictionary containing the structured outcomes, and it additionally gracefully handles timeouts or any errors that may come from the API. That is the half that helps Claude work out the place to look earlier than we even fetch the content material.
Click on right here to see the related code snippet
async def search_web(question: str) -> dict | None:
payload = json.dumps({"q": question, "num": 2})
headers = {
"X-API-KEY": os.getenv("SERPER_API_KEY"),
"Content material-Sort": "utility/json",
}
async with httpx.AsyncClient() as shopper:
strive:
response = await shopper.put up(
SERPER_URL, headers=headers, information=payload, timeout=30.0
)
response.raise_for_status()
return response.json()
besides httpx.TimeoutException:
return {"natural": []}
besides httpx.HTTPStatusError as e:
print(f"HTTP error occurred: {e}")
return {"natural": []}As soon as we’ve discovered just a few promising hyperlinks, we want a option to extract simply the helpful content material from these net pages. That’s what fetch_url does. It visits every URL, grabs the total HTML of the web page, after which makes use of BeautifulSoup to filter out simply the readable elements—issues like paragraphs, headings, and examples. We attempt to prioritize sections like ,
.content material class, which normally maintain the good things. If the web page is tremendous lengthy, we additionally trim it all the way down to keep away from flooding the output. Consider this because the “reader mode” for Claude—it turns cluttered webpages into clear textual content it may well perceive.
Click on right here to see the related code snippet
async def fetch_url(url: str) -> str:
async with httpx.AsyncClient(headers={"Person-Agent": USER_AGENT}) as shopper:
strive:
response = await shopper.get(url, timeout=30.0)
response.raise_for_status()
soup = BeautifulSoup(response.textual content, "html.parser")
# Attempt to extract most important content material and take away navigation, sidebars, and so on.
main_content = soup.discover("most important") or soup.discover("article") or soup.discover("div", class_="content material")
if main_content:
textual content = main_content.get_text(separator="n", strip=True)
else:
textual content = soup.get_text(separator="n", strip=True)
# Restrict content material size if it is too giant
if len(textual content) > 8000:
textual content = textual content[:8000] + "... [content truncated]"
return textual content
besides httpx.TimeoutException:
return "Timeout error when fetching the URL"
besides httpx.HTTPStatusError as e:
return f"HTTP error occurred: {e}"Now comes the principle act: the precise device perform that Claude will name.
The get_docs perform is the place every little thing comes collectively. Claude will go it a question and the identify of a library (like "llama-index"), and this perform will:
- Test if that library is supported
- Construct a site-specific search question (e.g.,
web site:docs.llamaindex.ai "vector retailer") - Use
search_web()to get the highest outcomes - Use
fetch_url()to go to and extract the content material - Format every little thing into a pleasant, readable string that Claude can perceive and return
We additionally embody titles, URLs, and a few visible separators between every consequence, so Claude can reference or cite them if wanted.
Click on right here to see the related code snippet
@mcp.device()
async def get_docs(question: str, library: str) -> str:
"""
Search the newest docs for a given question and library.
Helps langchain, openai, mcp and llama-index.
Args:
question: The question to seek for (e.g. "Chroma DB")
library: The library to go looking in (e.g. "langchain")
Returns:
Textual content from the docs
"""
if library not in docs_urls:
elevate ValueError(f"Library {library} not supported by this device. Supported libraries: {', '.be part of(docs_urls.keys())}")
question = f"web site:{docs_urls[library]} {question}"
outcomes = await search_web(question)
if not outcomes or len(outcomes.get("natural", [])) == 0:
return "No outcomes discovered"
combined_text = ""
for i, end in enumerate(outcomes["organic"]):
url = consequence["link"]
title = consequence.get("title", "No title")
# Add separator between outcomes
if i > 0:
combined_text += "nn" + "="*50 + "nn"
combined_text += f"Supply: {title}nURL: {url}nn"
page_content = await fetch_url(url)
combined_text += page_content
return combined_textLastly, this line kicks every little thing off. It tells the MCP server to begin listening for enter from Claude utilizing customary enter/output (which is how Claude Desktop talks to exterior instruments). This line all the time lives on the backside of your script.
if __name__ == "__main__":
mcp.run(transport="stdio")Step 5: Take a look at and Run Your Server
Alright, your server is coded and able to go — now let’s run it and see it in motion. There are two most important methods to check your MCP server:
Improvement Mode (Advisable for Constructing & Testing)
The best option to take a look at your server throughout growth is to make use of:
mcp dev most important.pyThis command launches the MCP Inspector, which opens up a neighborhood net interface in your browser. It’s like a management panel on your server.

Right here’s what you are able to do with it:
- Interactively take a look at your instruments (like
get_docs) - View detailed logs and error messages in actual time
- Monitor efficiency and response occasions
- Set or override surroundings variables briefly
Use this mode whereas constructing and debugging. You’ll have the ability to see precisely what Claude would see and shortly repair any points earlier than integrating with the total Claude Desktop app.
Claude Desktop Integration (For Common Use)
As soon as your server works and also you’re pleased with it, you possibly can set up it into Claude Desktop:
mcp set up most important.pyThis command will:
- Add your server into Claude’s configuration file (the JSON file we fiddled with earlier) mechanically
- Allow it to run each time you launch Claude Desktop
- Make it accessible via the Developer Instruments (🔨 hammer icon)
However maintain on — there’s one small catch…
⚠️ Present Concern: uv Command Is Hardcoded
Proper now, there’s an open problem within the mcp library: when it writes your server into Claude’s config file, it hardcodes the command as simply "uv". That works solely if uv is globally accessible in your PATH — which isn’t all the time the case, particularly for those who put in it domestically with pipx or a customized technique.
So we have to repair it manually. Right here’s how:
Manually Replace Claude’s Config File
- Open your Claude config file:
On MacOS:
code ~/Library/Utility Help/Claude/claude_desktop_config.jsonOn Home windows:
code $env:AppDataClaudeclaude_desktop_config.json💡 Should you’re not utilizing VS Code, change code together with your textual content editor of alternative (like open, nano, or subl).
2. Discover the part that appears like this:
"docs": {
"command": "uv",
"args": [
"run",
"--with",
"mcp[cli]",
"mcp",
"run",
"/PATH/TO/mcp-server/most important.py"
]
}3. Replace the "command" worth to absolutely the path of uv in your system.
- To seek out it, run this in your terminal:
which uv- It’ll return one thing like:
/Customers/your_username/.native/bin/uv- Now change
"uv"within the config with that full path:
"docs": {
"command": "/Customers/your_username/.native/bin/uv",
"args": [
"run",
"--with",
"mcp[cli]",
"mcp",
"run",
"PATH/TO/mcp-server/most important.py"
]
}4. Save the file and restart Claude Desktop.
✅ That’s It!
Now Claude Desktop will acknowledge your customized docs device, and anytime you open the Developer Instruments (🔨), it’ll present up. You may chat with Claude and ask issues like:
“Are you able to examine the newest MCP docs for how one can construct a customized server?”
And Claude will name your server, search the docs, pull the content material, and use it in its response — dwell. You may view a fast demo right here.

🎉 Congrats, You’ve Mastered MCP!
You probably did it. You’ve gone from zero to constructing, testing, and integrating your very personal Claude-compatible MCP server — and that’s no small feat.
Take a second. Stretch. Sip some espresso. Pat your self on the again. You didn’t simply write some Python — you constructed an actual, production-grade device that extends an LLM’s capabilities in a modular, safe, and highly effective means.
Severely, most devs don’t get this far. You now perceive:
- How MCP works beneath the hood
- The way to construct and expose instruments Claude can use
- The way to wire up real-time net search and content material extraction
- The way to debug, take a look at, and combine the entire thing with Claude Desktop
You didn’t simply be taught it — you shipped it.
Wish to go even deeper? There’s an entire world of agentic workflows, customized instruments, and collaborative LLMs ready to be constructed. However for now?
Take the win. You earned it. 🏆
Now go ask Claude one thing enjoyable and let your new device flex.
References
[1] Anthropic, Mannequin Context Protocol: Introduction (2024), modelcontextprotocol.io
[2] LangChain, MCP From Scratch (2024), Notion
[3] A. Alejandro, MCP Server Instance (2024), GitHub Repository
[4] O. Santos, Integrating Agentic RAG with MCP Servers: Technical Implementation Information (2024), Medium















{kind=link}