


a distributed multi-agent system each in OpenClaw and AWS AgentCore for some time now. In my OpenClaw setup alone, it has a analysis agent, a writing agent, a simulation engine, a heartbeat scheduler, and a number of other extra. They collaborate asynchronously, hand off context by shared recordsdata, and keep state throughout periods spanning days or perhaps weeks.
After I usher in different agentic techniques like Claude Code or the brokers I’ve deployed in AgentCore, coordination, reminiscence, and state all develop into tougher to resolve for.
Finally, I got here to a realization: most of what makes these brokers truly work isn’t the mannequin alternative. It’s the reminiscence structure.
So once I got here throughout “Reminiscence for Autonomous LLM Brokers: Mechanisms, Analysis, and Rising Frontiers” (arxiv 2603.07670), I used to be curious whether or not the formal taxonomy matched what I’d constructed by really feel and iteration. It does, fairly carefully. Nevertheless, it codifies lots of what I had discovered alone and helped me see that a few of my present ache factors aren’t distinctive to me and are being seen extra broadly.
Let’s stroll by the survey and talk about its findings as I share my experiences.
Why Reminiscence Issues Extra Than You Assume
The paper leads with an empirical statement that ought to recalibrate your priorities if it hasn’t already:
“The hole between ‘has reminiscence’ and ‘doesn’t have reminiscence’ is commonly bigger than the hole between completely different LLM backbones.”
This can be a big declare. Swapping your underlying mannequin issues lower than whether or not your agent can keep in mind issues. I’ve felt this intuitively, however seeing it said this plainly in a proper survey is helpful. Practitioners spend huge power on mannequin choice and immediate tuning whereas treating reminiscence as an afterthought. That’s backward.
The paper frames agent reminiscence inside a Partially Observable Markov Choice Course of (POMDP) construction, the place reminiscence capabilities because the agent’s perception state over {a partially} observable world. That’s a tidy formalization. In apply, it means the agent can’t see the whole lot, so it builds and maintains an inside mannequin of what’s true. Reminiscence is that mannequin. Get it mistaken, and each downstream resolution degrades.
The Write-Handle-Learn Loop
The paper characterizes agent reminiscence as a write-manage-read loop, not simply “retailer and retrieve.”
- Write: New info enters reminiscence (observations, outcomes, reflections)
- Handle: Reminiscence is maintained, pruned, compressed, and consolidated
- Learn: Related reminiscence is retrieved and injected into the context
Most implementations I see nail “write” and “learn” and utterly neglect “handle.” They accumulate with out curation. The result’s noise, contradiction, and bloated context. Managing is the exhausting half, and it’s the place most techniques wrestle or outright fail.
Earlier than the latest OpenClaw enhancements, I used to be dealing with this with a heuristic management coverage: guidelines for what to retailer, what to summarize, when to escalate to long-term reminiscence, and when to let issues age out. It’s not elegant, however it forces me to be express in regards to the administration step somewhat than ignoring it.
In different techniques I construct, I usually depend on mechanisms similar to AgentCore Quick/Lengthy-term reminiscence, Vector Databases, and Agent Reminiscence techniques. The file-based reminiscence system doesn’t scale effectively for big, distributed techniques (although for brokers or chatbots, it’s not off the desk).
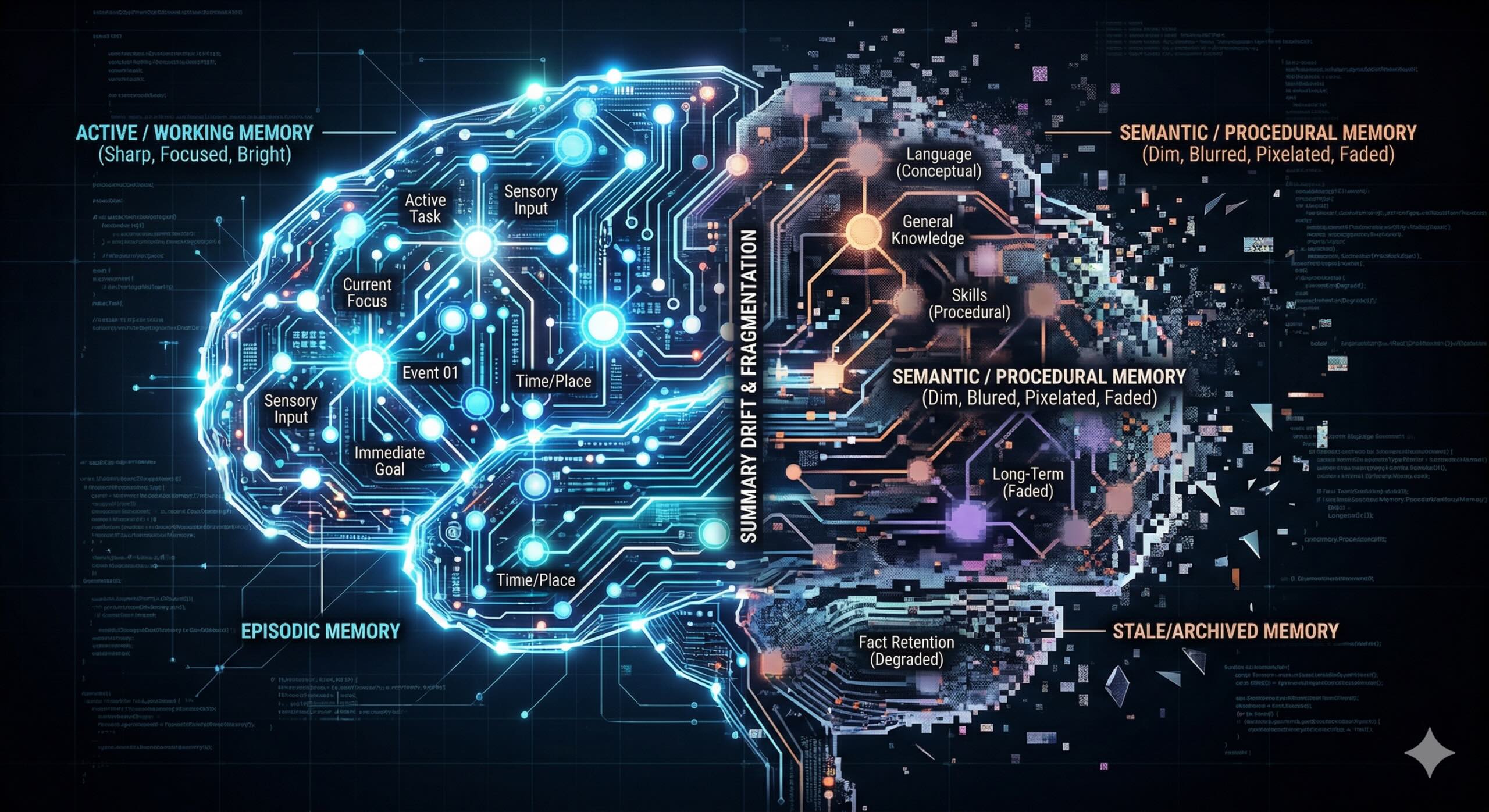
4 Temporal Scopes (And The place I See Them in Follow)
The paper breaks reminiscence into 4 temporal scopes.
Working Reminiscence
That is the context window.
It’s ephemeral, high-bandwidth, and restricted. All the pieces lives right here briefly. The failure mode is attentional dilution and the “misplaced within the center” impact, the place related content material will get ignored as a result of the window is simply too crowded. I’ve hit this, as have many of the groups I’ve labored with.
When OpenClaw, Claude Code, or your chatbot context will get lengthy, agent habits degrades in methods which are exhausting to debug as a result of the mannequin technically “has” the knowledge however isn’t utilizing it. The commonest factor I see from groups (and myself) is to create new threads for various chunks of labor. You don’t maintain Claude Code open all day whereas engaged on 20+ completely different JIRA duties; it degrades over time and performs poorly.
Episodic Reminiscence
This captures concrete experiences; what occurred, when, and in what sequence.
In my OpenClaw occasion, that is the day by day standup logs. Every agent writes a quick abstract of what it did, what it discovered, and what it escalated. These accumulate as a searchable timeline. The sensible worth is gigantic: brokers can look again at yesterday’s work, spot patterns, and keep away from repeating failures. Instruments like Claude Code wrestle, except you arrange directions to power the habits.
Manufacturing brokers can leverage issues like Agent Core’s short-term reminiscence to maintain these episodic recollections. There are even mechanisms to know what deserves to be endured past a single interplay.
The paper validates this as a definite and essential tier.
Semantic Reminiscence
Is answerable for abstracted, distilled information, details, heuristics, and discovered conclusions.
In my OpenClaw, that is the MEMORY.md file in every agent’s workspace. It’s curated. Not the whole lot goes in. The agent (or I, periodically) decides what’s value preserving as a long-lasting reality versus what was situational.
In Agent Core Reminiscence, that is primarily the Lengthy-term reminiscence characteristic.
This curation step is important; with out it, semantic reminiscence turns into a junk drawer.
Procedural Reminiscence
It’s encoded executable expertise, behavioral patterns, and discovered habits.
In OpenClaw, this maps principally to the AGENTS.md and SOUL.md recordsdata, which comprise persona directions, behavioral constraints, and escalation guidelines. When the agent reads these initially of the session, it’s loading procedural reminiscence. These needs to be up to date based mostly on person suggestions, and even by ‘dream’ processes that analyze interactions.
That is an space that I’ve been remiss in (as have groups that I’ve labored with). I spend time tuning a immediate, however the suggestions mechanisms that drive the storage of procedural reminiscence and the iteration on these personas usually get ignored.
The paper formalizes this as a definite tier, which I discovered validating. These aren’t simply system prompts. They’re a type of long-term discovered habits that shapes each motion.
5 Mechanism Households
Now that we’ve got some widespread definitions across the varieties of recollections, let’s dive into reminiscence mechanisms.
Context-Resident Compression
This covers sliding home windows, rolling summaries, and hierarchical compression. These are the “keep in context” methods. Rolling summaries are seductive as a result of they really feel clear (they’re not, I’ll get to why in a second).
I’m certain everybody has run into Claude Code or Kiro CLI compressing a dialog when it will get too massive for the context window. Oftentimes, you’re higher off restarting a brand new thread.
Retrieval-Augmented Shops
That is RAG utilized to agent interplay historical past somewhat than static paperwork. The agent embeds previous observations and retrieves by similarity. That is highly effective for long-running brokers with deep historical past, however retrieval high quality turns into a bottleneck quick. In case your embeddings don’t seize semantic intent effectively, you’ll miss related recollections and floor stale ones.
You additionally run into points the place questions like ‘what occurred final Monday’ don’t retrieve high quality recollections.
Reflective Self-Enchancment
This contains techniques similar to Reflexion and ExpeL, the place brokers write verbal post-mortems and retailer conclusions for future runs. The concept is compelling; brokers be taught from errors and enhance. The failure mode is extreme, although (we are going to cowl it in additional element in a minute).
I consider different ‘dream’ based mostly reflection and techniques just like the Google Reminiscence Agent sample belong to this class as effectively.
Hierarchical Digital Context
A MemGPT’s OS-inspired structure (see GitHub repo additionally). A principal context window is “RAM”, a recall database is the “disk”, and archival storage is “chilly storage”, whereas the agent manages its personal paging. Whereas this class is attention-grabbing, the overhead/work of sustaining these separate tiers is burdensome and tends to fail.
The MemGPT paper and git repo are each nearly 3 years previous, and I’ve but to see any precise use in manufacturing.
Coverage-Discovered Administration
This can be a new frontier strategy, the place RL-trained operators (similar to retailer, retrieve, replace, summarize, and discard) that fashions be taught to invoke optimally. I feel there’s lots of promise right here, however I haven’t seen actual harnesses for builders to make use of or any precise manufacturing use.
Failure Modes
We’ve coated the varieties of recollections and the techniques that make them. Subsequent is how these can fail.
Context-Resident Failures
Summarization drift happens whenever you repeatedly compress historical past to suit it inside a context window. Every compression/summarization throws away particulars, and ultimately, you’re left with reminiscence that doesn’t actually match what occurred. Once more, you see this Claude Code and Kiro CLI when coding periods cowl too many options with out creating new threads. A technique I’ve seen groups fight that is to maintain uncooked recollections linked to the summarized/consolidated recollections.
Consideration dilution is the opposite failure mode on this class. Even for those who can maintain the whole lot in context (as with the brand new 1 million-token home windows), bigger prompts “lose” info within the center. Whereas brokers technically have all of the recollections, they will’t give attention to the precise elements on the proper time.
Retrieval Failures
Semantic vs. causal mismatch happens when similarity searches return recollections that appear associated however aren’t. Embeddings are nice at figuring out when textual content ‘appear like’ one another, however are horrible with figuring out ‘that is the trigger’. In apply, I usually see this when debugging by coding assistants. They see related errors however can miss the underlying trigger, which regularly results in thrashing/churning, lots of adjustments, however by no means fixes the actual subject.
Reminiscence blindness happens in tiered techniques when essential details by no means resurface. The info exists, however the agent by no means sees it once more. This may be as a result of a sliding window has moved on, since you solely retrieve 10 recollections from an information supply, however what you want would have been the eleventh reminiscence.
Silent orchestration failures are probably the most harmful on this class. Paging, eviction, or archival insurance policies do the mistaken issues, however no errors are thrown (or are misplaced within the noise by the autonomous system or by people working it). The one symptom can be that responses worsen, get extra generic, and get much less grounded. Whereas I’ve seen this come up in a number of methods, the latest for me was when OpenClaw failed to write down day by day reminiscence recordsdata, so day by day stand-ups/summarizations had nothing to do. I solely seen as a result of it saved forgetting issues we labored on throughout these days.
Information-Integrity Failures
Staleness might be commonest. The surface world adjustments, however your system reminiscence doesn’t. Addresses, machine states, person preferences, and something that your system depends on to make choices can drift over time. Lengthy-lived brokers will act on knowledge from 2024 even in 2026 (who hasn’t seen an LLM insist the date is mistaken, the mistaken President is in workplace, or that the newest expertise hasn’t truly hit the scene but?).
Self-reinforcing errors (affirmation loops) happen when a system treats a reminiscence as floor reality, however that reminiscence is mistaken. Whilst you usually need techniques to be taught and construct a brand new foundation of reality, if a system creates a nasty reminiscence, its view of the world is affected. In my OpenClaw occasion, it determined that my SmartThings integration with my Dwelling Assistant was defective; subsequently, all info from a SmartThings machine was deemed misguided, and it ignored the whole lot from it (actually, there have been only a few lifeless batteries in my system).
Over-generalization is a quieter model of self-reinforcement. Brokers be taught a lesson in a slender context, then apply it in every single place. A workaround for a single buyer or a single error is a default sample.
Environmental Failure
Contradiction dealing with might be extremely irritating. As new info is collected, if it conflicts with current info, techniques can’t all the time decide the precise reality. In my OpenClaw system, I requested it to create some N8N workflows. All of them created accurately, however the motion timed out, so it thought it failed. I verified the workflows existed, advised my OpenClaw agent to recollect it, and it agreed. For the following a number of interactions, the agent oscillated between believing the workflow was obtainable and believing it had didn’t arrange.
Design Tensions
There may be going to be push-and-pull towards all these for brokers and reminiscence techniques.
Utility vs. Effectivity
Higher reminiscence normally means extra tokens, extra latency, extra storage, extra techniques.
Utility vs. Adaptivity
Reminiscence that’s helpful now can be stale in some unspecified time in the future. Updating is pricey and dangerous.
Adaptivity vs. Faithfulness
The extra you replace, revise, and compress, the extra you danger distorting what truly occurred.
Faithfulness vs. Governance
Correct reminiscence might comprise delicate info (PHI, PII, and so forth) that you could be be required to delete, obfuscate, or defend.
All the above vs. Governance
Enterprises have advanced compliance necessities that may battle with all these.
Sensible Takeaways for Builders
I’m usually requested by engineering groups for the perfect reminiscence system or the place they need to begin their journey. Right here’s what I say.
Begin with express temporal scopes
Don’t construct “reminiscence”. Once you want episodic reminiscence, construct it. When your use case grows and wishes semantic reminiscence, construct it. Don’t attempt to discover one system that does all of it, and don’t construct each type of reminiscence earlier than you want it.
Take the administration step critically
Plan learn how to keep your reminiscence. Don’t plan on accumulating indefinitely; determine for those who want compression or reminiscence connection/dream habits. How will you already know what goes into semantic reminiscence versus RAG reminiscence? How do you deal with updates? With out figuring out these, you’ll accumulate noise, get contradictions, and your system will degrade.
Maintain uncooked episodic information
Don’t simply depend on summaries; they will drift or lose particulars. Uncooked information allow you to return to what truly occurred and pull them in when essential.
Model reflective reminiscence
To assist keep away from contradictions in summaries, long-term recollections, and compressions, add timestamps or variations to every. This will help your brokers decide what’s true and what’s the most correct reflection of the system.
Deal with procedural reminiscence as code
In OpenClaw, your Brokers.MD, Reminiscence.MD, private recordsdata, and behavioral configs are all a part of your reminiscence structure. Assessment them and maintain them underneath supply management so you possibly can look at what adjustments and when. That is particularly essential in case your autonomous system can alter these based mostly on suggestions.
Wrapup
The write-manage-read framing is probably the most helpful takeaway from this paper. It’s easy, it’s full, and it forces you to consider all three phases as a substitute of simply “retailer stuff, retrieve stuff.”
The taxonomy maps surprisingly effectively to what I in-built OpenClaw by iteration and frustration. That’s both validating or humbling, relying on the way you take a look at it (in all probability each.) The paper formalizes patterns that practitioners have been discovering independently, which is what an excellent survey ought to do.
The open issues part is trustworthy about how a lot is unsolved. Analysis continues to be primitive. Governance is usually ignored in apply. Coverage-learned administration is promising however immature. There’s lots of runway right here.
Reminiscence is the place the actual differentiation occurs in agent techniques. Not the mannequin, not the prompts. The reminiscence structure. The paper provides you a vocabulary and a framework to assume extra clearly about it.
About
Nicholaus Lawson is a Resolution Architect with a background in software program engineering and AIML. He has labored throughout many verticals, together with Industrial Automation, Well being Care, Monetary Providers, and Software program corporations, from start-ups to massive enterprises.
This text and any opinions expressed by Nicholaus are his personal and never a mirrored image of his present, previous, or future employers or any of his colleagues or associates.
Be happy to attach with Nicholaus by way of LinkedIn at https://www.linkedin.com/in/nicholaus-lawson/













{kind=link}