


On this article, you’ll learn to construct environment friendly long-context retrieval-augmented technology (RAG) techniques utilizing fashionable methods that handle consideration limitations and price challenges.
Matters we are going to cowl embrace:
- How reranking mitigates the “Misplaced within the Center” drawback.
- How context caching reduces latency and computational value.
- How hybrid retrieval, metadata filtering, and question growth enhance relevance.
Introduction
Retrieval-augmented technology (RAG) is present process a significant shift. For years, the RAG mantra was easy: “Break your paperwork into smaller items, embed them, and retrieve probably the most related items.” This was obligatory as a result of massive language fashions (LLMs) had context home windows that have been costly and restricted, sometimes starting from 4,000 to 32,000 tokens.
Now, fashions like Gemini Professional and Claude Opus have damaged these limits, providing context home windows of 1 million tokens or extra. In principle, you might now paste a complete assortment of novels right into a immediate. In follow, nonetheless, this functionality introduces two main challenges:
- The “Misplaced within the Center” Drawback: Analysis has proven that fashions typically ignore data positioned in the midst of a large immediate, favoring the start and the top.
- The Value Drawback: Processing 1,000,000 tokens for each question is computationally costly and sluggish. It’s like rereading a complete encyclopedia each time somebody asks a easy query.
This tutorial explores 5 sensible methods for constructing environment friendly long-context RAG techniques. We transfer past easy partitioning and look at methods for mitigating consideration loss and enabling context reuse from a developer’s perspective.
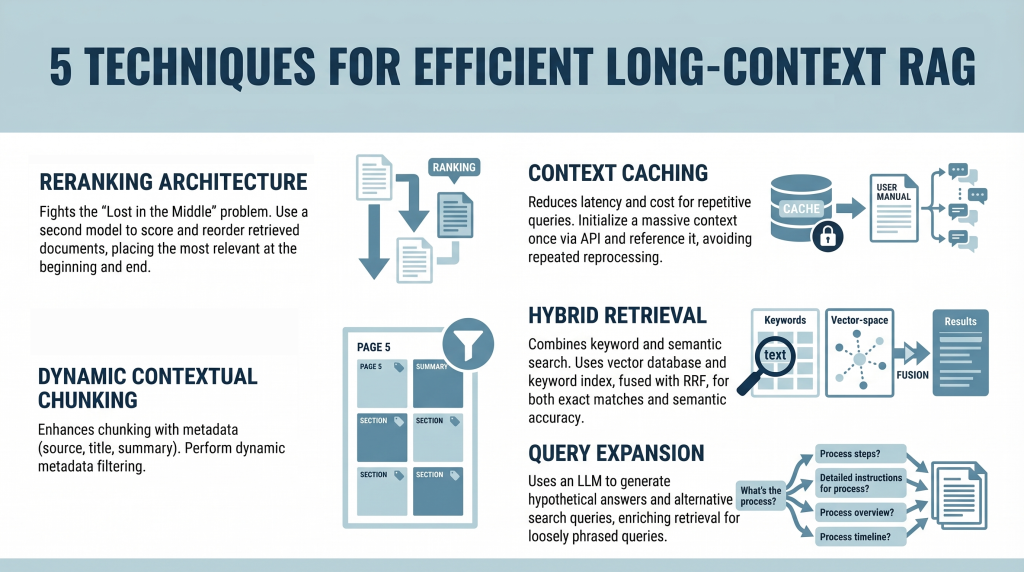
1. Implementing a Reranking Structure to Combat “Misplaced within the Center”
The “Misplaced within the Center” drawback, recognized in a 2023 examine by Stanford and UC Berkeley, reveals a vital limitation in LLM consideration mechanisms. When offered with lengthy context, mannequin efficiency peaks when related data seems at first or finish. Data buried within the center is considerably extra more likely to be ignored or misinterpreted.
As a substitute of inserting retrieved paperwork straight into the immediate of their unique order, introduce a reranking step.
Right here is the developer workflow:
- Retrieval: Use a typical vector database (resembling Pinecone or Weaviate) to retrieve a bigger candidate set (e.g. prime 20 as a substitute of prime 5)
- Reranking: Cross these candidates by way of a specialised cross-encoder reranker (such because the Cohere Rerank API or a Sentence-Transformers cross-encoder mannequin) that scores every doc in opposition to the question
- Reordering: Choose the highest 5 most related paperwork
- Context Placement: Place probably the most related doc at first and the second-most related on the finish of the immediate. Place the remaining three within the center
This strategic placement ensures that a very powerful data receives most consideration.
2. Leveraging Context Caching for Repetitive Queries
Lengthy contexts introduce latency and price overhead. Processing a whole lot of hundreds of tokens repeatedly is inefficient. Context caching addresses this concern.
Consider this as initializing a persistent context in your mannequin.
- Create the Cache: Add a big doc (e.g. a 500,000-token handbook) as soon as through an API and outline a time-to-live (TTL)
- Reference the Cache: For subsequent queries, ship solely the consumer’s query together with a reference ID to the cached context
- Value Financial savings: You cut back enter token prices and latency, because the doc doesn’t have to be reprocessed every time
This method is particularly helpful for chatbots constructed on static information bases.
3. Utilizing Dynamic Contextual Chunking with Metadata Filters
Even with massive context home windows, relevance stays vital. Merely rising context dimension doesn’t get rid of noise.
This method enhances conventional chunking with structured metadata.
- Clever Chunking: Break up paperwork into segments (e.g. 500–1000 tokens) and connect metadata resembling supply, part title, web page quantity, and summaries
- Hybrid Filtering: Use a two-step retrieval course of:
- Metadata Filtering: Slim the search area primarily based on structured attributes (e.g. date ranges or doc sections)
- Semantic Search: Carry out similarity search solely on filtered candidates
This reduces irrelevant context and improves precision.
4. Combining Key phrase and Semantic Search with Hybrid Retrieval
Vector search captures which means however can miss actual key phrase matches, that are important for technical queries.
Hybrid search combines semantic and keyword-based retrieval.
- Twin Retrieval:
- Vector database for semantic similarity
- Key phrase index (e.g. Elasticsearch) for actual matches
- Fusion: Use Reciprocal Rank Fusion (RRF) to mix rankings, prioritizing outcomes that rating extremely in each techniques
- Context Inhabitants: Insert the fused outcomes into the immediate utilizing reranking ideas
This ensures each semantic relevance and lexical accuracy.
5. Making use of Question Growth with Summarize-Then-Retrieve
Person queries typically differ from how data is expressed in paperwork. Question growth helps bridge this hole.
Use a light-weight LLM to generate different search queries.
This improves efficiency on inferential and loosely phrased queries.
Conclusion
The emergence of million-token context home windows doesn’t get rid of the necessity for retrieval-augmented technology—it reshapes it. Whereas lengthy contexts cut back the necessity for aggressive chunking, they introduce challenges associated to consideration distribution and price.
By making use of reranking, context caching, metadata filtering, hybrid retrieval, and question growth, you’ll be able to construct techniques which might be each scalable and exact. The aim isn’t merely to offer extra context, however to make sure the mannequin constantly focuses on probably the most related data.
References
About Shittu Olumide
Shittu Olumide is a software program engineer and technical author obsessed with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You can even discover Shittu on Twitter.














{kind=link}