




Picture by Writer
# Introduction
You’ve got shipped what appears like a successful take a look at: conversion up 8%, engagement metrics glowing inexperienced. Then it crashes in manufacturing or quietly fails a month later.
If that sounds acquainted, you are not alone. Most A/B take a look at failures do not come from dangerous product concepts; they arrive from dangerous experimentation practices.
The info misled you, the stopping rule was ignored, or nobody checked if the “win” was simply noise dressed as a sign. Here is the uncomfortable fact: the infrastructure round your take a look at issues greater than the variant itself, and most groups get it flawed.
Let’s break down the 4 silent killers of A/B testing — from deceptive knowledge to flawed logic — and reveal the disciplined practices that separate the very best from the remainder.
Picture by Writer
# When Information Lies: SRM and Information High quality Failures
Pitfall: Most “shocking” take a look at outcomes aren’t insights; they’re data-quality bugs sporting a disguise.
Pattern Ratio Mismatch (SRM) is the canary within the coal mine. You anticipate a 50/50 break up, you get 52/48. Sounds innocent. It isn’t. SRM alerts damaged randomization, biased site visitors routing, or logging failures that silently corrupt your outcomes.
Actual-world case: Microsoft discovered that SRM alerts extreme knowledge high quality points that invalidate experiment outcomes, that means checks with SRM usually result in flawed ship choices.
DoorDash detected SRM after low-intent customers dropped out disproportionately from one group following a bug repair, skewing outcomes and creating phantom wins.
What to test when you’ve got SRM:

Picture by Writer
- Chi-squared take a look at for site visitors splits: automate this earlier than any evaluation.
- Person-level vs. session-level logging: mismatched granularity creates phantom results.
- Time-based bucketing bugs: Monday customers in management, Friday customers in remedy = confounded outcomes.
Answer: The repair is not statistical cleverness. It is knowledge hygiene. Run SRM checks earlier than taking a look at metrics. If the take a look at fails the ratio test, cease. Examine. Repair the randomization. No exceptions.
Wish to follow recognizing data-quality points like SRM or logging mismatches? Strive a number of actual SQL data-cleaning and anomaly-detection challenges on StrataScratch. You may discover datasets from actual corporations to check your debugging and knowledge validation abilities.
Most groups skip this step. That is why most “profitable” checks fail in manufacturing.
# Cease Peeking: How Early Seems Wreck Validity
Pitfall: Checking your take a look at outcomes each morning feels productive. It isn’t. It is systematically inflating your false constructive charge.
Here is why: each time you take a look at p-values and resolve whether or not to cease, you are giving randomness one other likelihood to idiot you. Run 20 peeks on a null impact, and you may ultimately see p < 0.05 by pure luck. Optimizely‘s analysis discovered that uncorrected peeking can increase false positives from 5% to over 25%, that means one in 4 “wins” is noise.
How you can acknowledge a naive strategy:
- Run the take a look at for 2 weeks.
- Test every day.
- Cease when p < 0.05.
- End result: You’ve got run 14 a number of comparisons with out adjustment.
Answer: Use sequential testing or always-valid inference strategies that alter for a number of appears.
Actual-world case:
- Spotify‘s strategy: Group sequential checks (GST) with alpha spending features optimally account for a number of appears by exploiting the correlation construction between interim checks.
- Optimizely’s resolution: All the time-valid p-values that account for steady monitoring, permitting secure peeking with out inflating error charges.
- Netflix‘s methodology: Sequential testing with anytime-valid confidence sequences switches from fixed-horizon to steady monitoring whereas preserving Sort I error ensures.
For those who should peek, use instruments constructed for it. Do not wing it with t-tests.
Backside line: Predefine your stopping rule earlier than you begin. “Cease when it appears good” is not a rule; it is a recipe for idiot’s gold.
# Energy That Works: CUPED and Fashionable Variance Discount
Pitfall: Working longer checks is not the reply. Working smarter checks is.
Answer: CUPED (Managed-experiment Utilizing Pre-Experiment Information) is Microsoft’s resolution to noisy metrics. The idea includes utilizing pre-experiment habits to foretell post-experiment outcomes, then measuring solely the residual distinction. By eradicating predictable variance, you shrink confidence intervals with out amassing extra knowledge.
Actual-world instance: Microsoft reported that for one product workforce, CUPED was akin to including 20% extra site visitors to experiments. Netflix discovered variance reductions of roughly 40% on key engagement metrics. Statsig noticed that CUPED decreased variance by 50% or extra for a lot of widespread metrics, that means checks reached significance in half the time, or with half the site visitors.
The way it works:
Adjusted_metric = Raw_metric - θ × (Pre_period_metric - Mean_pre_period)
Translation: If a consumer spent $100/week earlier than the take a look at, and your take a look at cohort averages $90/week pre-test, CUPED adjusts downward for customers who had been already excessive spenders. You are measuring the remedy impact, not pre-existing variance.
When to make use of CUPED?
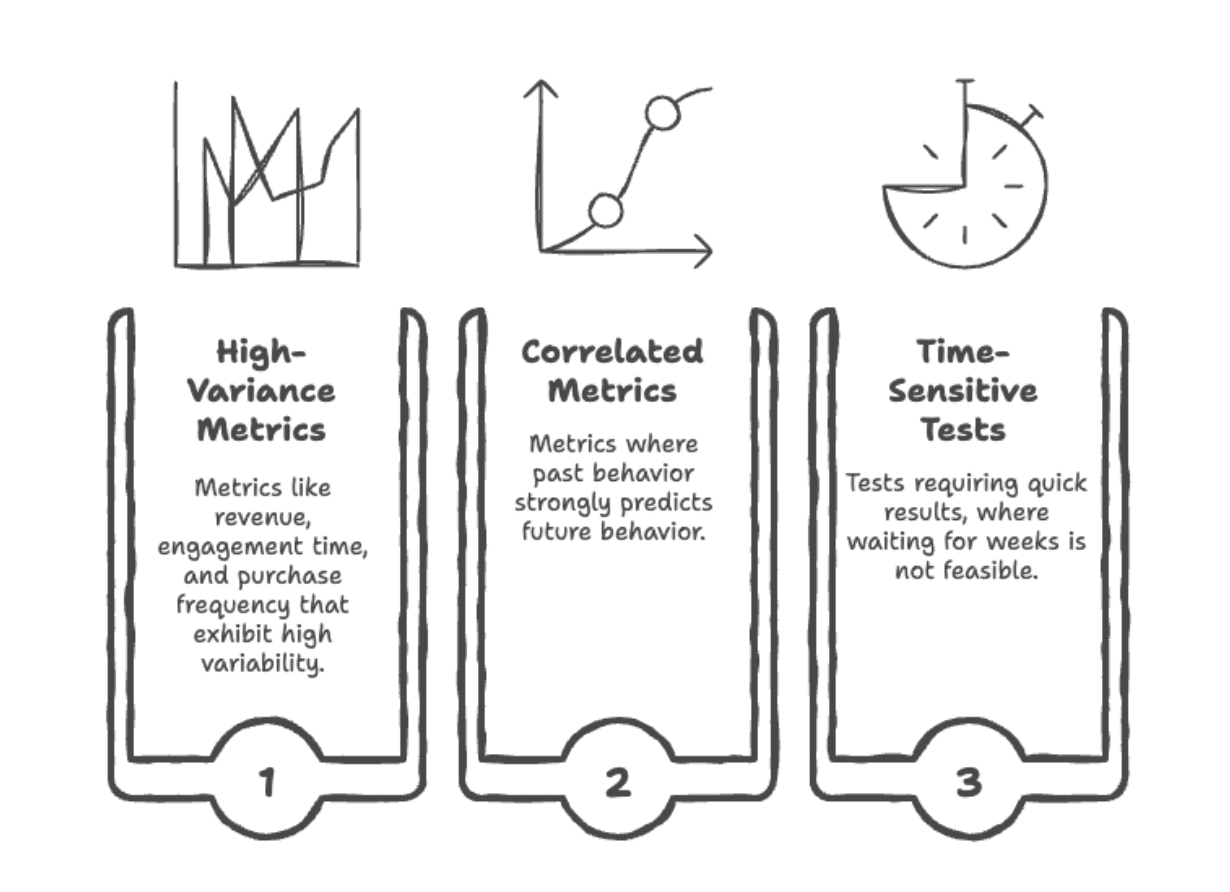
Picture by Writer
When to not use CUPED?
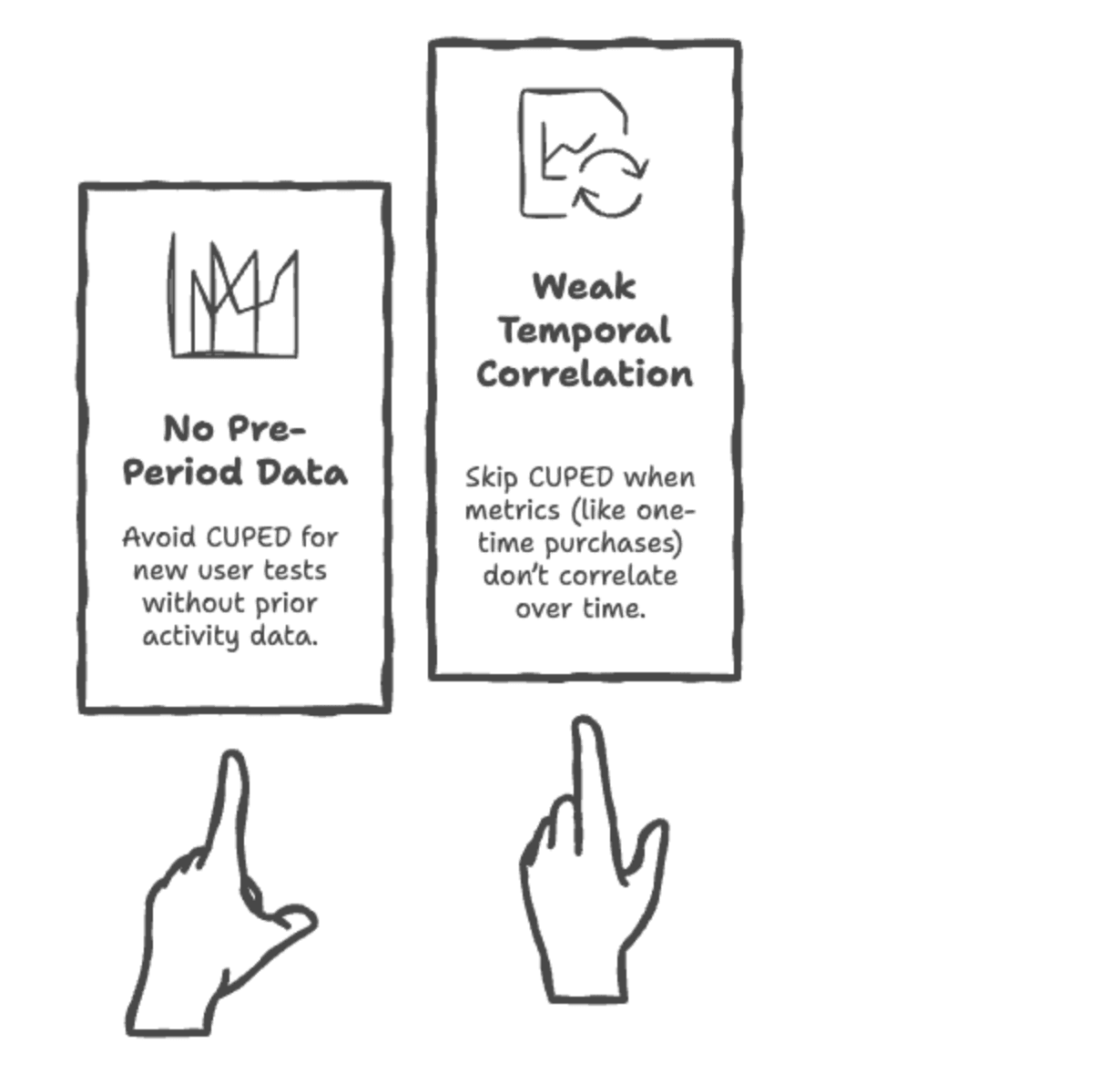
Picture by Writer
Newer strategies like CUPAC (combining covariates throughout metrics) and stratified sampling push this additional, however the precept stays the identical: cut back noise earlier than you analyze, not after.
Implementation observe: Most fashionable experimentation platforms (Optimizely, Eppo, GrowthBook) help CUPED out of the field. For those who’re rolling your personal, add pre-period covariates to your evaluation pipeline; the statistical raise is definitely worth the engineering effort.
# Measuring What Issues: Guardrails and Lengthy-Time period Actuality Checks
Pitfall: Optimizing for the flawed metric is worse than working no take a look at in any respect.
A traditional lure: You take a look at a function that reinforces clicks by 12%. Ship it. Three months later, retention is down 8%. What occurred? You optimized an arrogance metric with out defending in opposition to downstream hurt.
Answer: Guardrail metrics are your security web. They’re the metrics you do not optimize for, however you monitor to catch unintended penalties:
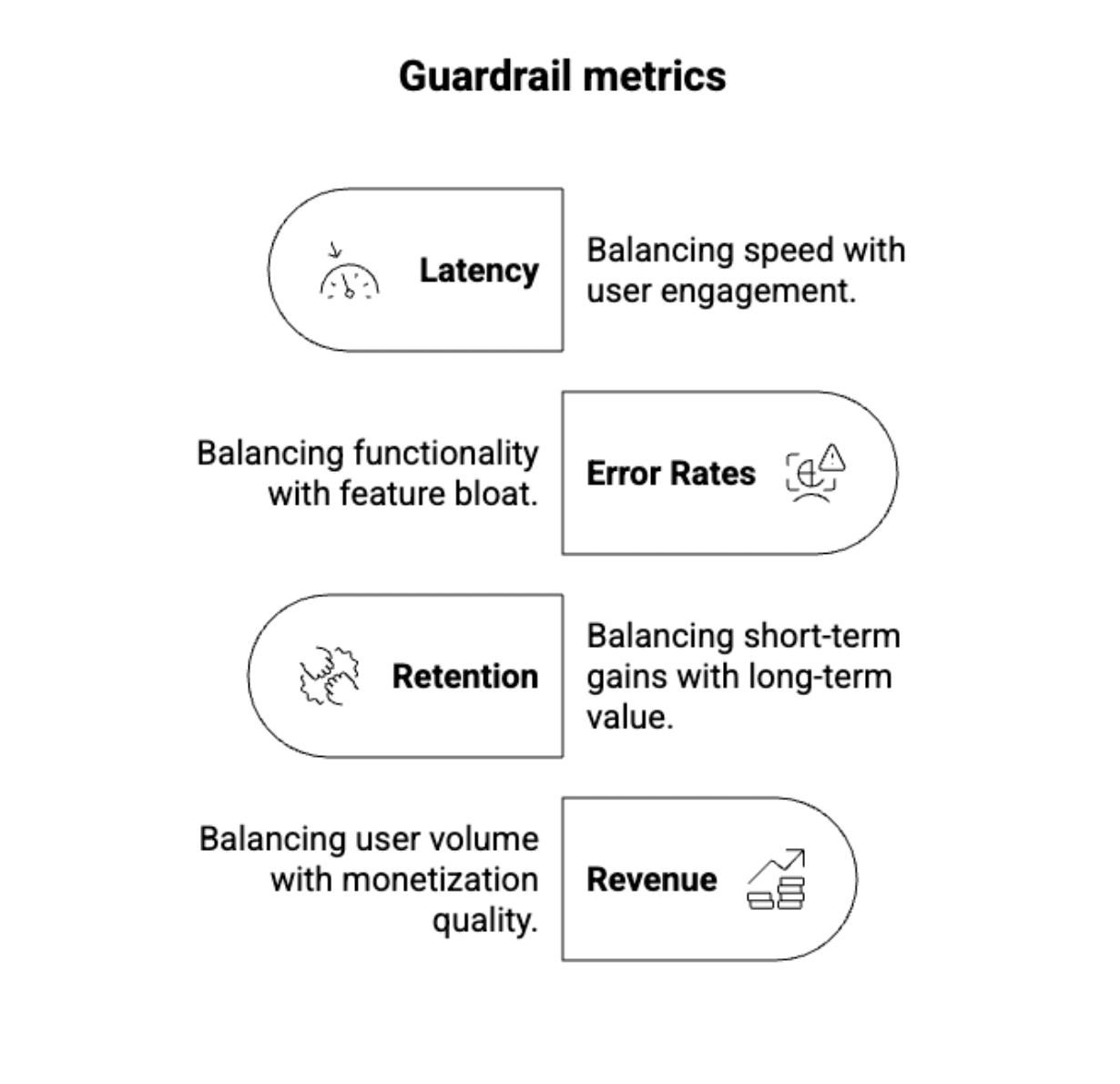
Picture by Writer
Actual-world instance: Airbnb found {that a} take a look at growing bookings additionally decreased overview rankings; the change attracted extra bookings however damage long-term satisfaction. Guardrail metrics caught the issue earlier than full rollout. Out of hundreds of month-to-month experiments, Airbnb’s guardrails flag roughly 25 checks for stakeholder overview, stopping about 5 probably main adverse impacts every month.
How you can construction guardrails:
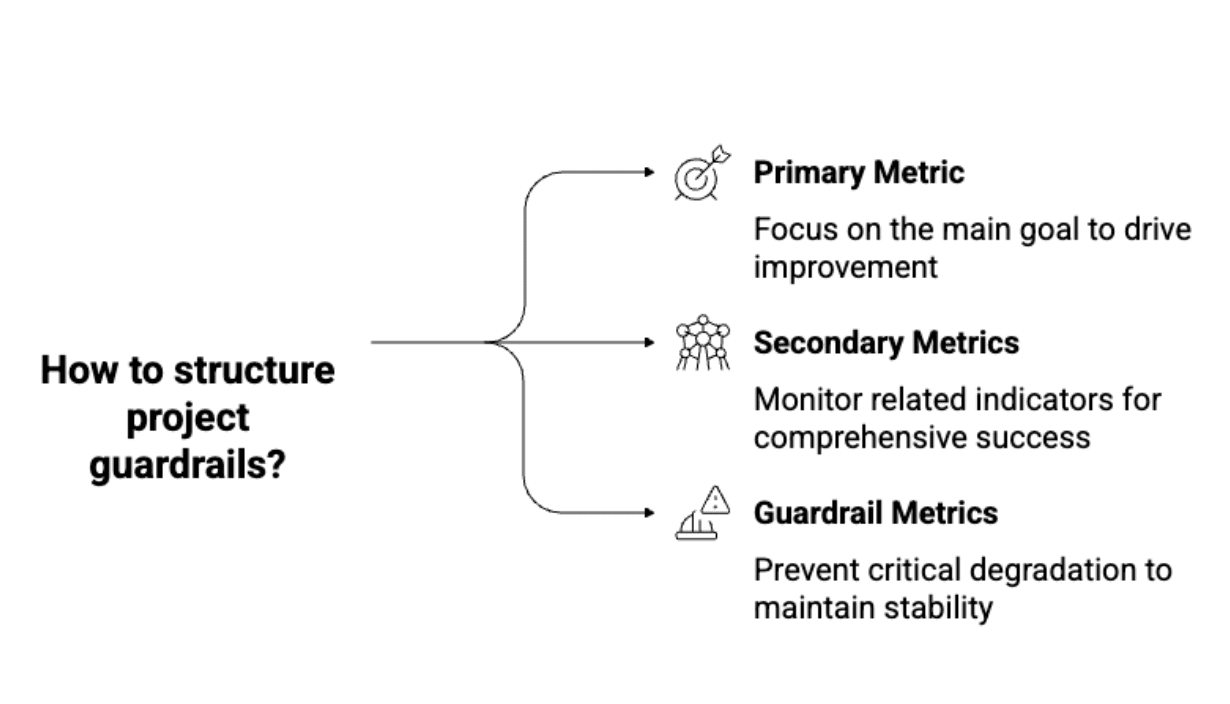
Picture by Writer
The novelty downside: Quick-term checks seize novelty results, not sustained influence. Customers click on new buttons as a result of they’re new, not as a result of they’re higher. Corporations use holdout teams to measure whether or not results persist weeks or months after launch, usually holding 5–10% of customers within the pre-change expertise whereas monitoring long-term metrics.
Greatest follow: Each take a look at wants validation past the preliminary experiment:
- Section 1: Normal A/B take a look at (1–4 weeks) to measure fast influence.
- Section 2: Lengthy-term monitoring with holdout teams or prolonged monitoring to validate persistence.
If the impact disappears in Section 2, it wasn’t an actual win: it was curiosity.
# What High Experimenters Do In another way
The hole between good and nice experimentation groups is not statistical sophistication; it is operational self-discipline.
Here is what corporations like Reserving.com, Netflix, and Microsoft try this others do not:
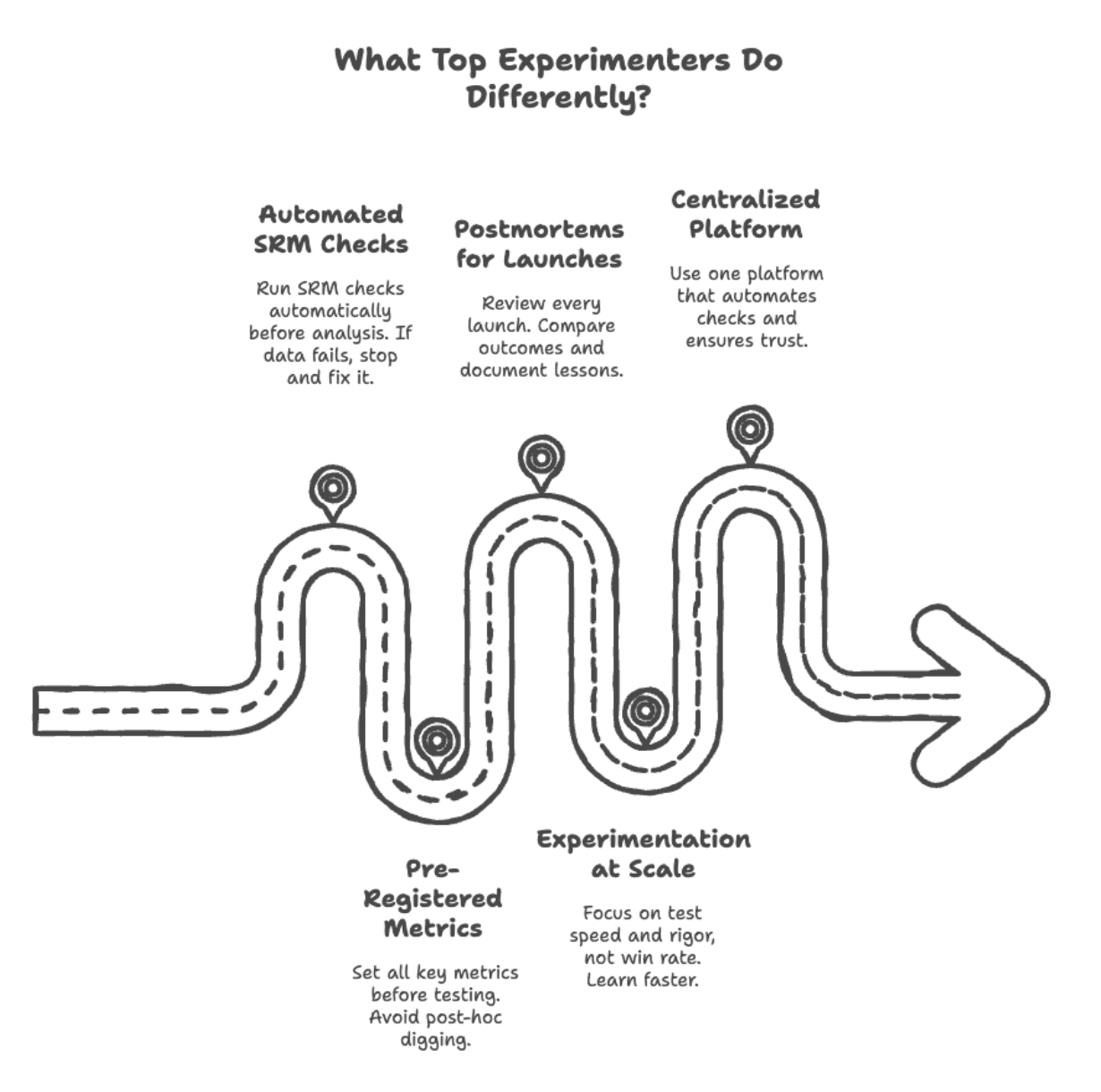
Picture by Writer
// Automating SRM Checks
Trade follow: Fashionable experimentation platforms like Optimizely and Statsig mechanically run SRM checks on each experiment. If the test fails, the dashboard exhibits a warning. No override choice. No “we’ll examine later.” Repair it or do not ship.
Reserving.com‘s experimentation tradition calls for that knowledge high quality points get caught earlier than outcomes are analyzed, treating SRM checks as non-negotiable guardrails, not non-obligatory diagnostics.
// Pre-Registering Metrics
Greatest follow: Outline main, secondary, and guardrail metrics earlier than the take a look at begins. No post-hoc metric mining. No “let’s test if it moved income too.” For those who did not plan to measure it, you do not get to say it as a win.
Netflix’s strategy: Exams embody predefined main metrics plus guardrail metrics (like customer support contact charges) to catch unintended adverse penalties.
// Working Postmortems for Each Launch
Microsoft’s ExP platform follow: Win or lose, each shipped experiment will get a postmortem:
- Did the impact match the prediction?
- Did guardrails maintain?
- What would we do otherwise?
This is not paperwork; it is studying infrastructure.
// Experimenting at Scale
Reserving.com’s outcomes: Working 1,000+ concurrent experiments, they’ve discovered that almost all checks (90%) fail, however that is the purpose. Testing quantity is not about wins; it is about studying sooner than rivals.
Groups are measured not on win charge, however on:
- Check velocity (experiments per quarter).
- Information high quality (holding SRM charges low).
- Observe-through (% of legitimate wins that really ship).
This discourages gaming the system and rewards rigorous execution.
// Constructing a Centralized Experimentation Platform
Nice groups do not let engineers roll their very own A/B checks. They construct (or purchase) a platform that:
- Enforces randomization correctness.
- Auto-calculates pattern sizes.
- Runs SRM and energy checks mechanically.
- Logs each choice for audit.
Why this issues: Success in experimentation is not about working extra checks. It is about working reliable checks. The groups that win are those who make rigor automated.
# Conclusion
The toughest fact in A/B testing is not statistical; it is cultural. You possibly can grasp sequential testing, implement CUPED, and outline excellent guardrails, however none of it issues in case your workforce checks outcomes too early, ignores SRM warnings, or ships wins with out validation.
The distinction between groups that scale experimentation and groups that drown in false positives is not smarter knowledge scientists; it is automated rigor, enforced self-discipline, and a shared settlement that “it regarded important” is not ok.
Subsequent time you are tempted to peek at a take a look at or skip the SRM test, bear in mind: the costliest mistake in experimentation is convincing your self the information is clear when it isn’t.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from high corporations. Nate writes on the newest developments within the profession market, provides interview recommendation, shares knowledge science initiatives, and covers every thing SQL.















{kind=link}