

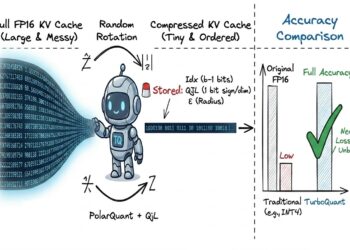
KV Cache Is Consuming Your VRAM. Right here’s How Google Mounted It With TurboQuant.
any time with Transformers, you already know consideration is the mind of the entire operation. It's what lets the mannequin ...
any time with Transformers, you already know consideration is the mind of the entire operation. It's what lets the mannequin ...

, we talked intimately about what Immediate Caching is in LLMs and the way it can prevent some huge cash ...

On this article, you'll discover ways to add each exact-match and semantic inference caching to giant language mannequin functions to ...









