


Why retrieval, not technology, makes RAG methods magical
Fast POCs
Most fast proof of ideas (POCs) which permit a consumer to discover knowledge with the assistance of conversational AI merely blow you away. It looks like pure magic when you possibly can hastily discuss to your paperwork, or knowledge, or code base.
These POCs work wonders on small datasets with a restricted rely of docs. Nevertheless, as with virtually something whenever you convey it to manufacturing, you shortly run into issues at scale. Whenever you do a deep dive and also you examine the solutions the AI provides you, you discover:
- Your agent doesn’t reply with full data. It missed some vital items of information
- Your agent doesn’t reliably give the identical reply
- Your agent isn’t capable of inform you how and the place it acquired which data, making the reply considerably much less helpful
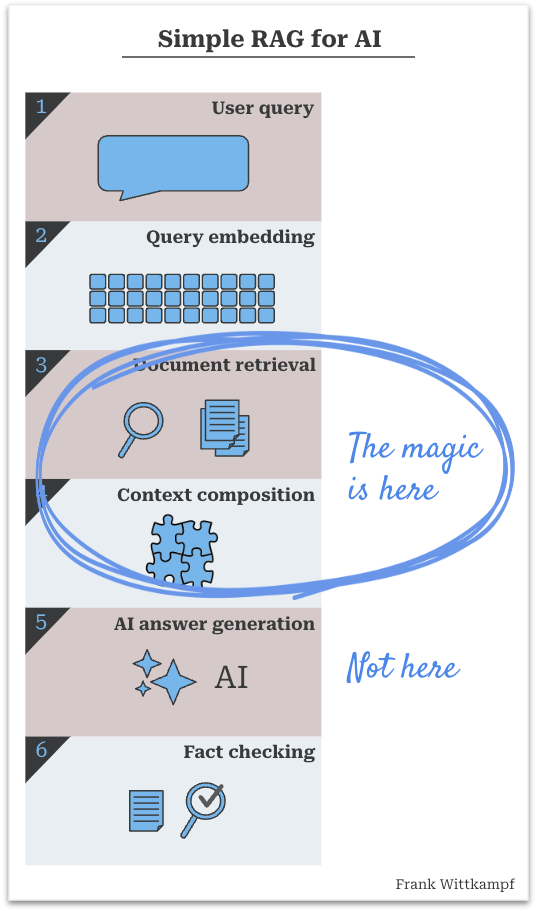
It seems that the actual magic in RAG doesn’t occur within the generative AI step, however within the means of retrieval and composition. When you dive in, it’s fairly apparent why…
* RAG = Retrieval Augmented Technology — Wikipedia Definition of RAG

A fast recap of how a easy RAG course of works:
- All of it begins with a question. The consumer requested a query, or some system is attempting to reply a query. E.g. “Does affected person Walker have a damaged leg?”
- A search is finished with the question. Principally you’d embed the question and do a similarity search, however you may also do a traditional elastic search or a mix of each, or a straight lookup of data
- The search result’s a set of paperwork (or doc snippets, however let’s merely name them paperwork for now)
- The paperwork and the essence of the question are mixed into some simply readable context in order that the AI can work with it
- The AI interprets the query and the paperwork and generates a solution
- Ideally this reply is truth checked, to see if the AI primarily based the reply on the paperwork, and/or whether it is acceptable for the viewers
The soiled little secret is that the essence of the RAG course of is that you must present the reply to the AI (earlier than it even does something), in order that it is ready to provide the reply that you simply’re in search of.
In different phrases:
- the work that the AI does (step 5) is apply judgement, and correctly articulate the reply
- the work that the engineer does (step 3 and 4) is discover the reply and compose it such that AI can digest it
Which is extra vital? The reply is, after all, it relies upon, as a result of if judgement is the crucial aspect, then the AI mannequin does all of the magic. However for an countless quantity of enterprise use circumstances, discovering and correctly composing the items that make up the reply, is the extra vital half.
The primary set of issues to unravel when working a RAG course of are the info ingestion, splitting, chunking, doc interpretation points. I’ve written about a couple of of those in prior articles, however am ignoring them right here. For now let’s assume you might have correctly solved your knowledge ingestion, you might have a beautiful vector retailer or search index.
Typical challenges:
- Duplication — Even the only manufacturing methods typically have duplicate paperwork. Extra so when your system is giant, you might have intensive customers or tenants, you hook up with a number of knowledge sources, otherwise you take care of versioning, and so on.
- Close to duplication — Paperwork which largely comprise the identical knowledge, however with minor modifications. There are two sorts of close to duplication:
— Significant — E.g. a small correction, or a minor addition, e.g. a date subject with an replace
— Meaningless — E.g.: minor punctuation, syntax, or spacing variations, or simply variations launched by timing or consumption processing - Quantity — Some queries have a really giant related response knowledge set
- Information freshness vs high quality — Which snippets of the response knowledge set have probably the most prime quality content material for the AI to make use of vs which snippets are most related from a time (freshness) perspective?
- Information selection — How can we guarantee quite a lot of search outcomes such that the AI is correctly knowledgeable?
- Question phrasing and ambiguity — The immediate that triggered the RAG circulation, won’t be phrased in such a means that it yields the optimum consequence, or may even be ambiguous
- Response Personalization — The question may require a distinct response primarily based on who asks it
This checklist goes on, however you get the gist.
Brief reply: no.
The price and efficiency affect of utilizing extraordinarily giant context home windows shouldn’t be underestimated (you simply 10x or 100x your per question value), not together with any observe up interplay that the consumer/system has.
Nevertheless, placing that apart. Think about the next state of affairs.
We put Anne in room with a chunk of paper. The paper says: *affected person Joe: advanced foot fracture.* Now we ask Anne, does the affected person have a foot fracture? Her reply is “sure, he does”.
Now we give Anne 100 pages of medical historical past on Joe. Her reply turns into “effectively, relying on what time you might be referring to, he had …”
Now we give Anne hundreds of pages on all of the sufferers within the clinic…
What you shortly discover, is that how we outline the query (or the immediate in our case) begins to get crucial. The bigger the context window, the extra nuance the question wants.
Moreover, the bigger the context window, the universe of potential solutions grows. This could be a optimistic factor, however in follow, it’s a technique that invitations lazy engineering conduct, and is more likely to cut back the capabilities of your software if not dealt with intelligently.
As you scale a RAG system from POC to manufacturing, right here’s how you can deal with typical knowledge challenges with particular options. Every method has been adjusted to swimsuit manufacturing necessities and consists of examples the place helpful.
Duplication
Duplication is inevitable in multi-source methods. Through the use of fingerprinting (hashing content material), doc IDs, or semantic hashing, you possibly can determine actual duplicates at ingestion and stop redundant content material. Nevertheless, consolidating metadata throughout duplicates may also be invaluable; this lets customers know that sure content material seems in a number of sources, which may add credibility or spotlight repetition within the dataset.
# Fingerprinting for deduplication
def fingerprint(doc_content):
return hashlib.md5(doc_content.encode()).hexdigest()# Retailer fingerprints and filter duplicates, whereas consolidating metadata
fingerprints = {}
unique_docs = []
for doc in docs:
fp = fingerprint(doc['content'])
if fp not in fingerprints:
fingerprints[fp] = [doc]
unique_docs.append(doc)
else:
fingerprints[fp].append(doc) # Consolidate sources
Close to Duplication
Close to-duplicate paperwork (comparable however not equivalent) typically comprise vital updates or small additions. Given {that a} minor change, like a standing replace, can carry crucial data, freshness turns into essential when filtering close to duplicates. A sensible method is to make use of cosine similarity for preliminary detection, then retain the freshest model inside every group of near-duplicates whereas flagging any significant updates.
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.cluster import DBSCAN
import numpy as np# Cluster embeddings with DBSCAN to search out close to duplicates
clustering = DBSCAN(eps=0.1, min_samples=2, metric="cosine").match(doc_embeddings)
# Manage paperwork by cluster label
clustered_docs = {}
for idx, label in enumerate(clustering.labels_):
if label == -1:
proceed
if label not in clustered_docs:
clustered_docs[label] = []
clustered_docs[label].append(docs[idx])
# Filter clusters to retain solely the freshest doc in every cluster
filtered_docs = []
for cluster_docs in clustered_docs.values():
# Select the doc with the newest timestamp or highest relevance
freshest_doc = max(cluster_docs, key=lambda d: d['timestamp'])
filtered_docs.append(freshest_doc)
Quantity
When a question returns a excessive quantity of related paperwork, efficient dealing with is essential. One method is a **layered technique**:
- Theme Extraction: Preprocess paperwork to extract particular themes or summaries.
- Prime-k Filtering: After synthesis, filter the summarized content material primarily based on relevance scores.
- Relevance Scoring: Use similarity metrics (e.g., BM25 or cosine similarity) to prioritize the highest paperwork earlier than retrieval.
This method reduces the workload by retrieving synthesized data that’s extra manageable for the AI. Different methods might contain batching paperwork by theme or pre-grouping summaries to additional streamline retrieval.
Information Freshness vs. High quality
Balancing high quality with freshness is crucial, particularly in fast-evolving datasets. Many scoring approaches are potential, however right here’s a common tactic:
- Composite Scoring: Calculate a top quality rating utilizing elements like supply reliability, content material depth, and consumer engagement.
- Recency Weighting: Regulate the rating with a timestamp weight to emphasise freshness.
- Filter by Threshold: Solely paperwork assembly a mixed high quality and recency threshold proceed to retrieval.
Different methods might contain scoring solely high-quality sources or making use of decay elements to older paperwork.
Information Selection
Guaranteeing various knowledge sources in retrieval helps create a balanced response. Grouping paperwork by supply (e.g., totally different databases, authors, or content material varieties) and choosing prime snippets from every supply is one efficient methodology. Different approaches embody scoring by distinctive views or making use of variety constraints to keep away from over-reliance on any single doc or perspective.
# Guarantee selection by grouping and choosing prime snippets per supplyfrom itertools import groupby
okay = 3 # Variety of prime snippets per supply
docs = sorted(docs, key=lambda d: d['source'])
grouped_docs = {key: checklist(group)[:k] for key, group in groupby(docs, key=lambda d: d['source'])}
diverse_docs = [doc for docs in grouped_docs.values() for doc in docs]
Question Phrasing and Ambiguity
Ambiguous queries can result in suboptimal retrieval outcomes. Utilizing the precise consumer immediate is usually not be the easiest way to retrieve the outcomes they require. E.g. there may need been an data trade earlier on within the chat which is related. Or the consumer pasted a considerable amount of textual content with a query about it.
To make sure that you employ a refined question, one method is to make sure that a RAG software offered to the mannequin asks it to rephrase the query right into a extra detailed search question, just like how one may rigorously craft a search question for Google. This method improves alignment between the consumer’s intent and the RAG retrieval course of. The phrasing beneath is suboptimal, nevertheless it gives the gist of it:
instruments = [{
"name": "search_our_database",
"description": "Search our internal company database for relevent documents",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "A search query, like you would for a google search, in sentence form. Take care to provide any important nuance to the question."
}
},
"required": ["query"]
}
}]
Response Personalization
For tailor-made responses, combine user-specific context straight into the RAG context composition. By including a user-specific layer to the ultimate context, you permit the AI to have in mind particular person preferences, permissions, or historical past with out altering the core retrieval course of.















{kind=link}