


We automated the evaluation and made the code accessible on GitHub.
got here to me after I tried to breed the paper “Studying Phrase Vectors for Sentiment Evaluation” by Maas et al. (2011).
On the time, I used to be nonetheless in my remaining 12 months of engineering college. The objective was to breed the paper, problem the authors’ strategies, and, if attainable, evaluate them with different phrase representations, together with LLM-based approaches.
What struck me was how easy and stylish the tactic was. In a method, it jogged my memory of logistic regression in credit score scoring: easy, interpretable, and nonetheless highly effective when used appropriately.
I loved studying this paper a lot that I made a decision to share what I realized from it.
I strongly advocate studying the unique paper. It would allow you to perceive what’s at stake in phrase illustration, particularly the way to analyze the proximity between two phrases from each a semantic perspective and a sentiment polarity perspective, given the precise contexts through which these phrases are used.
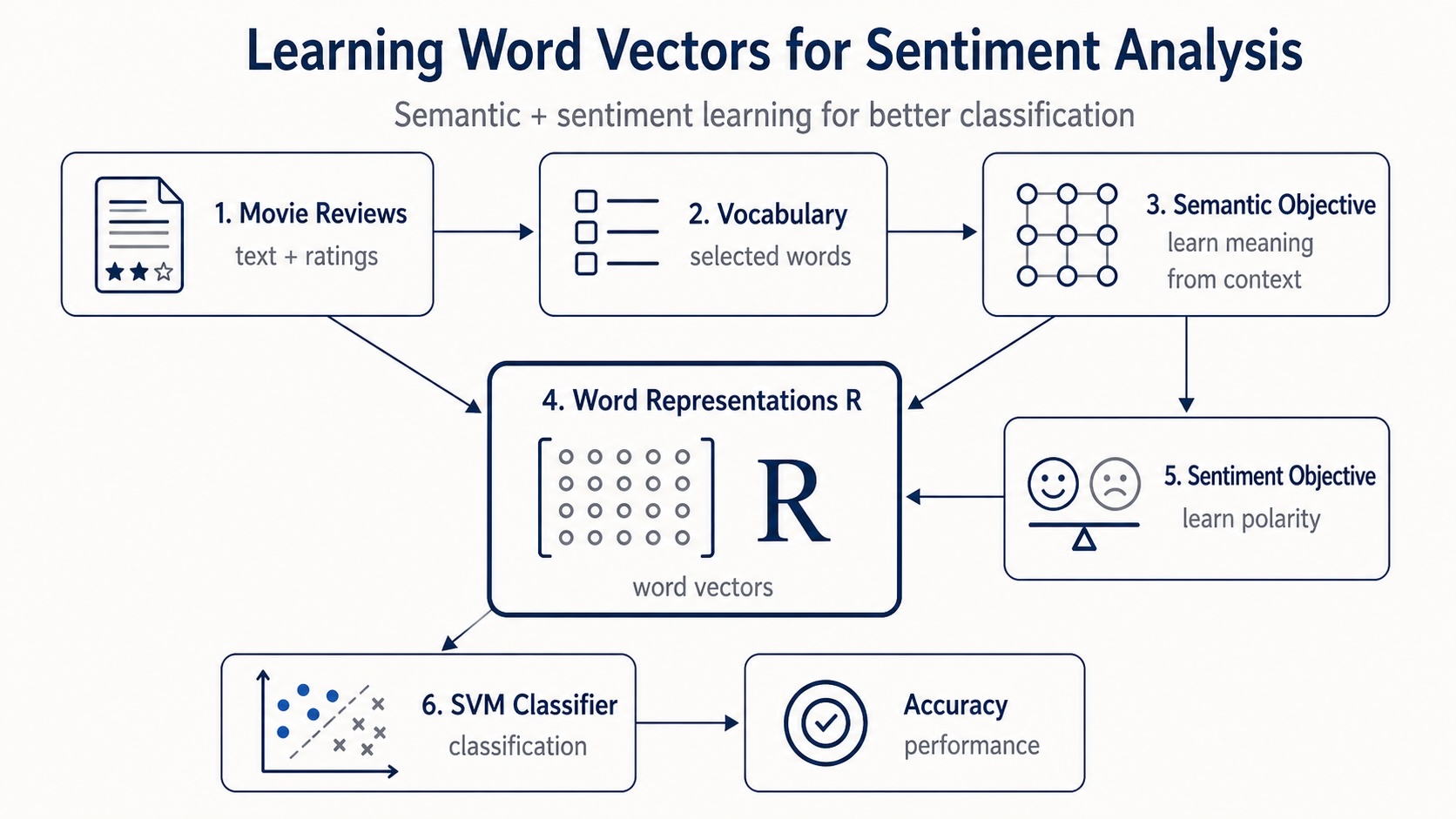
At first, the mannequin appears easy: construct a vocabulary, be taught phrase vectors, incorporate sentiment data, and consider the outcomes on IMDb critiques.
However after I began implementing it, I spotted that a number of particulars matter loads: how the vocabulary is constructed, how doc vectors are represented, how the semantic goal is optimized, and the way the sentiment sign is injected into the phrase vectors.
On this article, we are going to reproduce the principle concepts of the paper utilizing Python.
We are going to first clarify the instinct behind the mannequin. Then we are going to current the construction of knowledge used within the article, assemble the vocabulary, implement the semantic part, add the sentiment goal, and eventually consider the realized representations utilizing the linear SVM classifier.
The SVM will permit us to measure the classification accuracy and evaluate our outcomes with these reported within the paper.
What drawback does the paper remedy?
Conventional Bag of Phrases fashions are helpful for classification, however they don’t be taught significant relationships between phrases. For instance, the phrases great and wonderful must be shut as a result of they categorical comparable which means and comparable sentiment. Alternatively, great and horrible could seem in comparable film evaluation contexts, however they categorical reverse sentiments.
The objective of the paper is to be taught phrase vectors that seize each semantic similarity and sentiment orientation.
Information construction
The dataset accommodates:
- 25,000 labeled coaching critiques or paperwork
- 50,000 unlabeled coaching critiques
- 25,000 labeled check critiques
The labeled critiques are polarized:
- Adverse critiques have scores from 1 to 4
- Optimistic critiques have scores from 7 to 10
The scores are linearly mapped to the interval [0, 1], which permits the mannequin to deal with sentiment as a steady likelihood of optimistic polarity.
aclImdb/
├── practice/
│ ├── pos/ "0_10.txt" -> evaluation #0, 10 stars, very optimistic
│ │ "1_7.txt" -> evaluation #1, 7 stars, optimistic
│ ├── neg/ "10_2.txt" -> evaluation #10, 2 stars, very damaging
│ │ "25_4.txt" -> evaluation #25, 4 stars, damaging
│ └── unsup/ "938_0.txt" -> evaluation #938, 0 stars, unlabeled
└── check/
├── pos/ optimistic critiques, by no means seen throughout coaching
└── neg/ damaging critiques, by no means seen throughout coachingWe are able to subsequently retailer every doc in a Assessment class with the next attributes: textual content, stars, label, and bucket.
In fact, it doesn’t need to be a category particularly named Assessment. Any object can be utilized so long as it gives not less than these attributes.
from dataclasses import dataclass
from typing import Elective
@dataclass
class Assessment:
textual content: str
stars: int
label: str
bucket: strVocabulary building
The paper builds a hard and fast vocabulary by first ignoring the 50 most frequent phrases, then conserving the subsequent 5,000 most frequent tokens.
No stemming is utilized. No customary stopword removing is used. That is essential as a result of some stopwords, particularly negations, can carry sentiment data.
Earlier than constructing this vocabulary, we first want to take a look at the uncooked knowledge.
We seen that the critiques aren’t absolutely cleaned. Some paperwork include HTML tags, so we take away them in the course of the knowledge loading step. We additionally take away punctuation connected to phrases, corresponding to ".", ",", "!", or "?".
It is a slight distinction from the unique paper. The authors preserve some non-word tokens as a result of they might assist seize sentiment. For instance, "!" or ":-)" can carry emotional data. In our implementation, we select to take away this punctuation and later consider how a lot this determination impacts the ultimate mannequin efficiency.
When working with textual content knowledge, the subsequent query is at all times the identical:
How ought to we signify paperwork and phrases numerically?
The authors begin by gathering all tokens from the coaching set, together with each labeled and unlabeled critiques. We are able to consider this as placing all phrases from the coaching paperwork into one massive basket.
Then, to signify phrases in an area the place we are able to practice a mannequin, they construct a set of phrases known as the vocabulary.
The authors construct a dictionary that maps every token, which we are going to loosely name a phrase, to its frequency. This frequency is just the variety of instances the token seems within the full coaching set, together with each labeled and unlabeled critiques.
Then they choose the 5,000 most frequent phrases, after eradicating the 50 most frequent phrases.
These 5,000 phrases type the vocabulary V.
Every phrase in V will correspond to 1 column of the illustration matrix R. The authors select to signify every phrase in a 50-dimensional house. Due to this fact, the matrix R has the next form:
Every column of R is the vector illustration of 1 phrase:
The objective of the mannequin is to be taught this matrix R in order that the phrase vectors seize two issues on the similar time:
- Semantic data, which means phrases utilized in comparable contexts must be shut;
- Sentiment data, which means phrases carrying comparable polarity, must also be shut.
That is the central thought of the paper.
As soon as the info is loaded, cleaned, and the vocabulary is constructed, we are able to transfer to the development of the mannequin itself.
The primary a part of the mannequin is unsupervised. It learns semantic phrase representations from each labeled and unlabeled critiques.
Then, the second half provides supervision through the use of the star scores to inject sentiment into the identical vector house.
Semantic part
The semantic part defines a probabilistic mannequin of a doc.
Every doc is related to a latent vector theta. This vector represents the semantic path of the doc.
Every phrase has a vector illustration , saved as a column of the matrix R.
The likelihood of observing a phrase w in a doc is given by a softmax mannequin:
Intuitively, a phrase turns into seemingly when its vector is effectively aligned with the doc vector theta.
MAP estimation of theta
The mannequin alternates between two steps.
First, it fixes R and b and estimates one theta vector for every doc.
Then, it fixes theta and updates R and b.
The theta vectors aren’t saved as remaining parameters. They’re non permanent document-specific variables used to replace the phrase representations.
To estimate the parameters of the mannequin, the authors use most probability.
The thought is straightforward: we need to discover the parameters R and b that make the noticed paperwork as seemingly as attainable underneath the mannequin.
Ranging from the probabilistic formulation of a doc, they introduce a MAP estimate θ̂ₖ for every doc dₖ. Then, by taking the logarithm of the probability and including regularization phrases, they get hold of the target perform used to be taught the phrase illustration matrix R and the bias vector b:
which is maximized with respect to R and b. The hyperparameters within the mannequin are the regularization weights (λ and ν) and the phrase vector dimensionality β.
On this step, we be taught the semantic illustration matrix. This matrix captures how phrases relate to one another primarily based on the contexts through which they seem.
Sentiment part
The semantic mannequin alone can be taught that phrases happen in comparable contexts. However this isn’t sufficient to seize sentiment.
For instance, great and horrible could each happen in film critiques, however they categorical reverse opinions.
To resolve this, the paper provides a supervised sentiment goal:
The vector ψ defines a sentiment path within the phrase vector house. Right here, solely the labelled knowledge are used.
If a phrase vector lies on one facet of the hyperplane, it’s thought-about optimistic. If it lies on the opposite facet, it’s thought-about damaging.
They mixed the sentiment goal and the sentiment half to construct the ultimate and the complete goal studying:
The primary half learns semantic similarity. The second half injects sentiment data. The regularization phrases stop the vectors from rising too massive.
|| denotes the variety of paperwork within the dataset with the identical rounded worth of . The weighting is launched to fight the well-known imbalance in scores current in evaluation collections.
Classification and outcomes
As soon as the phrase illustration matrix R has been realized, we are able to use it to construct document-level options.
The target is now to categorise every film evaluation as optimistic or damaging.
To do that, the authors practice a linear SVM on the 25,000 labeled coaching critiques and consider it on the 25,000 labeled check critiques.
The essential query just isn’t solely whether or not the phrase vectors are significant, however whether or not they assist enhance sentiment classification.
To reply this query, we consider a number of doc representations and evaluate them with the outcomes reported in Desk 2 of the paper.
The one factor that adjustments from one configuration to a different is the way in which every evaluation is represented earlier than being handed to the classifier.
1. Bag of Phrases baseline
The primary illustration is a regular Bag of Phrases. Within the paper, this baseline is reported as Bag of Phrases (bnc). The notation means:
- b = binary weighting
- n = no IDF weighting
- c = cosine normalization
A evaluation or doc is represented by a vector v of dimension 5000, as a result of the vocabulary accommodates 5,000 phrases.
For every phrase j within the vocabulary:
So this illustration solely data whether or not a phrase seems not less than as soon as. It doesn’t depend what number of instances it seems.
Then the vector is normalized by its Euclidean norm:
This provides the Bag of Phrases baseline used to coach the SVM.
This baseline is robust as a result of sentiment classification usually depends on direct lexical clues. Phrases corresponding to glorious, boring, terrible, or nice already carry helpful sentiment data.
2. Semantic-only phrase vector illustration
The second illustration makes use of the phrase vectors realized by the semantic-only mannequin.
The authors first signify a doc as a Bag of Phrases vector v. Then they compute a dense doc illustration by multiplying this vector by the realized matrix:
The place
This vector could be interpreted as a weighted mixture of the phrase vectors that seem within the evaluation.
Within the paper, when producing doc options by the product Rv, the authors use bnn weighting for v. This implies:
- b = binary weighting
- n = no IDF weighting
- n = no cosine normalization earlier than projection
Then, after computing Rv, they apply cosine normalization to the ultimate dense vector.
So the ultimate illustration is:
This illustration makes use of semantic data realized from the coaching critiques, together with each labeled and unlabeled paperwork.
3. Full semantic + sentiment illustration
The third illustration follows the identical building, however makes use of the complete matrix Rfull.
This matrix is realized with each parts of the mannequin:
- the semantic goal, which learns contextual similarity between phrases;
- The sentiment goal, which injects polarity data from the star scores.
For every doc, we compute:
Then we normalize:
The instinct is that ought to produce doc options that seize each what the evaluation is about and whether or not the language is optimistic or damaging.
That is the principle contribution of the paper: studying phrase vectors that mix semantic similarity and sentiment orientation.
4. Full illustration + Bag of Phrases
The ultimate configuration combines the realized dense illustration with the unique Bag of Phrases illustration.
We concatenate the 2 representations to acquire:
This provides the classifier two complementary sources of knowledge:
- a dense 50-dimensional illustration realized by the mannequin;
- a sparse lexical illustration that preserves actual word-presence data.
This mix is beneficial as a result of phrase vectors can generalize throughout comparable phrases, whereas Bag of Phrases options preserve exact lexical proof.
For instance, the dense illustration could be taught that great and wonderful are shut, whereas the Bag of Phrases illustration nonetheless preserves the precise presence of every phrase.
We then practice a linear SVM on the labeled coaching set and consider it on the check set.
This permits us to reply two questions.
First, do the realized phrase vectors enhance sentiment classification?
Second, does including sentiment data to the phrase vectors assist past semantic data alone?
Implementation in Python
We implement the mannequin in 5 steps:
- Load and clear the IMDb dataset
- Construct the vocabulary
- Practice the semantic part
- Practice the complete semantic + sentiment mannequin
- Consider the realized representations utilizing SVM
The desk beneath reveals the closest neighbors of chosen goal phrases within the realized vector house.

For every goal phrase, we report the 5 most comparable phrases in accordance with cosine similarity. The complete mannequin, which mixes the semantic and sentiment aims, tends to retrieve phrases which can be shut each in which means and in sentiment orientation. The semantic-only mannequin captures contextual and lexical similarity, however it doesn’t explicitly use sentiment labels throughout coaching.
The desk beneath compares our outcomes with the outcomes reported within the paper. For every illustration, we practice a linear SVM on the labeled coaching critiques and report the classification accuracy on the check set. This permits us to guage how effectively every doc illustration performs on the IMDb sentiment classification activity.

The complete mannequin may be very near the consequence reported within the paper. This implies that the sentiment goal is carried out appropriately.
The most important hole seems within the semantic-only mannequin. This may increasingly come from optimization particulars, preprocessing, or the way in which document-level options are constructed for classification.
Conclusion
On this article, we reproduced the principle parts of the mannequin proposed by Maas et al. (2011).
We carried out the semantic goal, added the sentiment goal, and evaluated the realized phrase vectors on IMDb sentiment classification.
The mannequin reveals how unlabeled knowledge can assist be taught semantic construction, whereas labeled knowledge can inject sentiment data into the identical vector house.
It is a easy however highly effective thought: phrase vectors mustn’t solely seize what phrases imply, but in addition how they really feel.
Whereas this publish doesn’t cowl each element of the paper, we extremely advocate studying the authors’ authentic work. Our objective was to share the concepts that impressed us and the enjoyment we discovered each in studying the paper and scripting this publish.
We hope you get pleasure from it as a lot as we did.
Picture Credit
All photos and visualizations on this article have been created by the creator utilizing Python (pandas, matplotlib, seaborn, and plotly) and excel, until in any other case acknowledged.
References
[1] 𝗔𝗻𝗱𝗿𝗲𝘄 𝗟. 𝗠𝗮𝗮𝘀, 𝗥𝗮𝘆𝗺𝗼𝗻𝗱 𝗘. 𝗗𝗮𝗹𝘆, 𝗣𝗲𝘁𝗲𝗿 𝗧. 𝗣𝗵𝗮𝗺, 𝗗𝗮𝗻 𝗛𝘂𝗮𝗻𝗴, 𝗔𝗻𝗱𝗿𝗲𝘄 𝗬. 𝗡𝗴, 𝗮𝗻𝗱 𝗖𝗵𝗿𝗶𝘀𝘁𝗼𝗽𝗵𝗲𝗿 𝗣𝗼𝘁𝘁𝘀. 2011. Studying Phrase Vectors for Sentiment Evaluation. In Proceedings of the forty ninth Annual Assembly of the Affiliation for Computational Linguistics: Human Language Applied sciences, pages 142–150, Portland, Oregon, USA. Affiliation for Computational Linguistics.
Dataset: IMDb Massive Film Assessment Dataset (CC BY 4.0).















{kind=link}