


landed on arXiv simply earlier than Christmas 2025, very a lot an early current from the group at Google DeepMind, with the title “In the direction of a Science of Scaling Agent Methods.” I discovered this paper to be a genuinely helpful learn for engineers and information scientists. It’s peppered with concrete, measurement-driven recommendation, and filled with takeaways you possibly can apply instantly. The authors run a big multi-factorial examine, facilitated by the super compute accessible at these frontier labs, to systematically various key design parameters with a purpose to actually perceive what drives efficiency in agentic programs.
Like many business AI practitioners, I spend a variety of time constructing Multi-Agent Methods (MAS). This entails a taking complicated, multi-step workflow and dividing it throughout a set of brokers, every specialised for a selected process. Whereas the dominant paradigm for AI chatbots is zero-shot, request-response interplay, Multi-Agent Methods (MAS) supply a extra compelling promise: the power to autonomously “divide and conquer” complicated duties. By parallelizing analysis, reasoning, and gear use, these programs considerably enhance effectiveness over monolithic fashions.
To maneuver past easy interactions, the DeepMind analysis highlights that MAS efficiency is decided by the interaction of 4 components:
- Agent Amount: The variety of specialised models deployed.
- Coordination Construction: The topology (Centralised, Decentralised, and so forth.) governing how they work together.
- Mannequin Functionality: The baseline intelligence of the underlying LLMs.
- Activity Properties: The inherent complexity and necessities of the work.
The Science of Scaling means that MAS efficiency success is discovered on the intersection of Amount, Topology, Functionality, and Activity Complexity. If we get the stability flawed we find yourself scaling noise slightly than the outcomes. This publish will enable you discover that secret sauce on your personal duties in a means that can reliably enable you construct a performant and sturdy MAS that can impress your stakeholders.
A compelling latest success story of the place an optimum stability was discovered for a fancy process comes from Cursor, the AI-powered software program growth firm behind a preferred IDE. They describe utilizing massive numbers of brokers working in live performance to automate complicated duties over prolonged runs, together with producing substantial quantities of code to construct an online browser (you possibly can see the code right here) and translating codebases (e.g., from Strong to React). Their write-up on scaling agentic AI to tough duties over weeks of computation is an interesting learn.
Cursor report that immediate engineering is crucial to efficiency, and the precise agent coordination structure is essential. Particularly, they report higher outcomes with a structured planner–employee decomposition than with a flat swarm (or bag) of brokers. The function of coordination is especially attention-grabbing, and it’s a side of MAS design we’ll return to on this article. Very like real-world groups profit from a supervisor, the Cursor group discovered {that a} hierarchical setup, with a planner in management, was important. This labored much better than a free-for-all through which brokers picked duties at will. The planner enabled managed delegation and accountability, guaranteeing employee brokers tackled the suitable sub-tasks and delivered concrete challenge progress. Apparently additionally they discover that it’s necessary to match the suitable mannequin to the suitable, discovering that GPT-5.2 is the very best planner and employee agent in comparison with Claude Opus 4.5.
Nevertheless, regardless of this early glimpse of success from the Cursor group, Multi-Agent System growth in the actual world continues to be on the boundary of scientific data and subsequently a difficult process. Multi-Agent Methods will be messy with unreliable outputs, token budgets misplaced to coordination chatter, and efficiency that drifts, typically worsening as an alternative of enhancing. Cautious thought is required into the design, mapping it to the particulars of a given use-case.
When creating a MAS, I saved coming again to the identical questions: when ought to I cut up a step throughout a number of brokers, and what standards ought to drive that call? What coordination structure ought to I select? With so many permutations of decomposition and agent roles, it’s simple to finish up overwhelmed. Moreover, how ought to I be desirous about the kind of Brokers accessible and their roles?
That hole between promise and actuality is what makes creating a MAS such a compelling engineering and information science downside. Getting these programs to work reliably, and to ship tangible enterprise worth, nonetheless entails a variety of trial, error, and hard-won instinct. In some ways, the sphere can really feel such as you’re working off the overwhelmed path, at the moment with out sufficient shared idea or customary follow.
This paper by the DeepMind group helps so much. It brings construction to the area and, importantly, proposes a quantitative approach to predict when a given agent structure is more likely to shine and when it’s extra more likely to underperform.
Within the rush to construct complicated AI, most builders fall into the ‘Bag of Brokers’ trap by throwing extra LLMs at an issue and hoping for emergent intelligence. However because the latest Science of Scaling analysis by DeepMind exhibits, a bag of brokers isn’t an efficient group, slightly it may be a supply of 17.2x error amplification. With out the fences and lanes of a proper topology to constrain the agentic interplay, we find yourself scaling noise slightly than an clever functionality that’s more likely to clear up a enterprise process.
I’ve little doubt that mastering the standardised build-out of Multi-Agent Methods is the following nice technical moat. Corporations that may rapidly bridge the hole between ‘messy’ autonomous brokers and rigorous, plane-based topologies will reap the dividends of maximum effectivity and high-fidelity output at scale, bringing large aggressive benefits inside their market.
In response to the DeepMind scaling analysis, multi-agent coordination yields the very best returns when a single-agent baseline is under 45%. In case your base mannequin is already hitting 80%, including extra brokers may really introduce extra noise than worth.
On this publish I distill nuggets just like the above right into a playbook that gives you with the suitable psychological map to construct the very best Multi-Agent Methods. You’ll find golden guidelines for setting up a Multi-Agent System for a given process, referring to what brokers to construct and the way they need to be coordinated. Additional, I’ll outline a set of ten core agent archetypes that will help you map the panorama of capabilities and make it simpler to decide on the suitable setup on your use-case. I’ll then draw out the principle design classes from the DeepMind Science of Scaling paper, utilizing them to indicate the right way to configure and coordinate these brokers successfully for various sorts of labor.
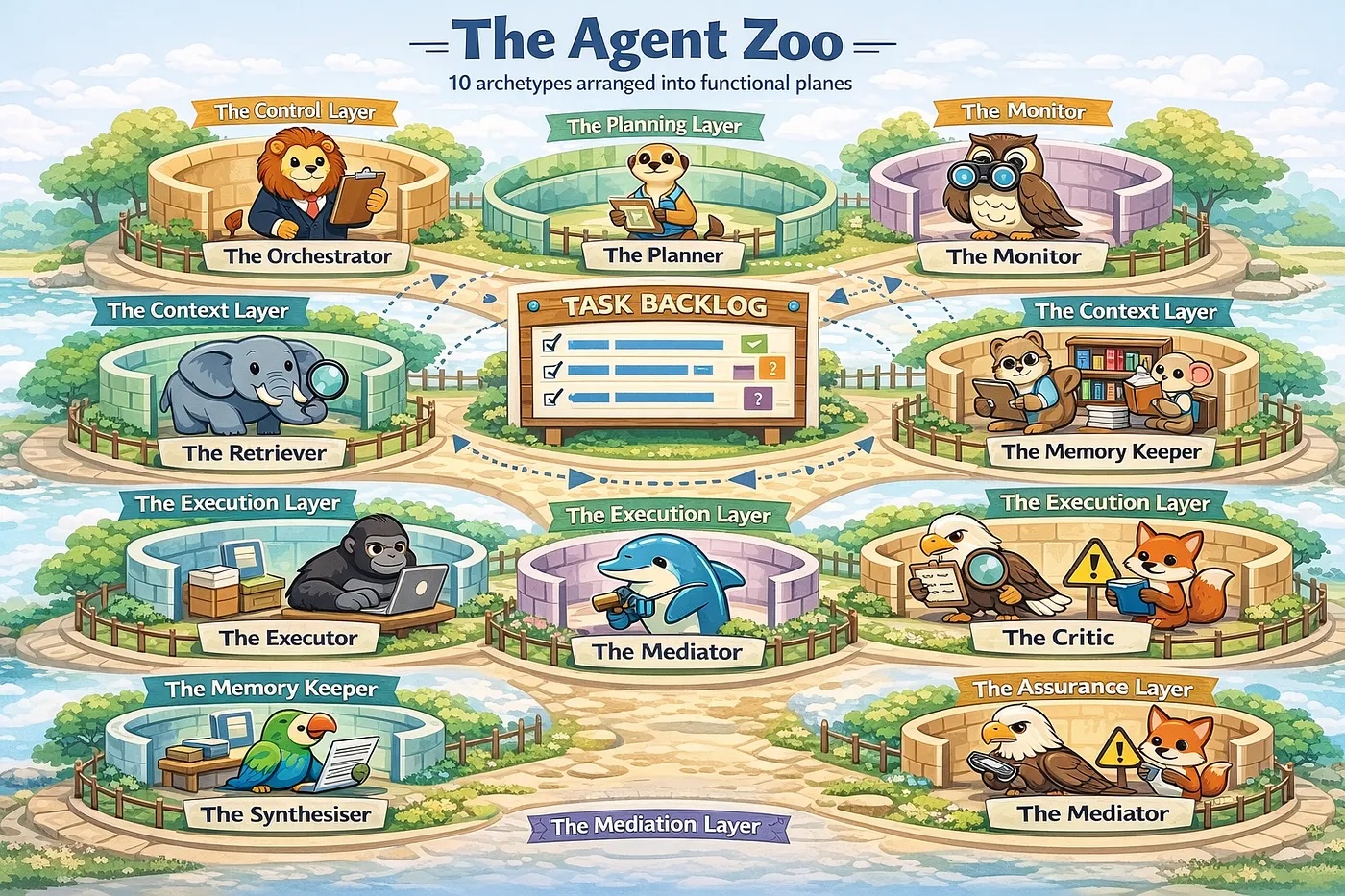
Defining a Taxonomy of Core Agent Archetypes
On this part we’ll map out the design area of Brokers, specializing in the overarching sorts accessible for fixing complicated duties. Its helpful to distill the varieties of Brokers down into 10 fundamental sorts, following intently the definitions within the 2023 autonomous agent survey of Wang et al.: Orchestrator, Planner, Executor, Evaluator, Synthesiser, Critic, Retriever, Reminiscence Keeper, Mediator, and Monitor. In my expertise, nearly all helpful Multi-Agent Methods will be designed by utilizing a combination of those Brokers linked collectively into a selected topology.
Up to now now we have a free assortment of various agent sorts, it’s helpful if now we have an related psychological reference level for a way they are often grouped and utilized. We are able to set up these brokers by two complementary lenses: a static structure of Useful Management Planes and a dynamic runtime cycle of Plan–Do–Confirm. The best way to think about that is that the management planes present the construction, whereas the runtime cycle drives the workflow:
- Plan: The Orchestrator (Management Airplane) defines the high-level goal and constraints. It delegates to the Planner, which decomposes the target right into a process graph — mapping dependencies, priorities, and steps. As new info surfaces, the Orchestrator sequences and revises this plan dynamically.
- Do: The Executor interprets summary duties into tangible outputs (artifacts, code adjustments, choices). To make sure this work is grounded and environment friendly, the Retriever (Context Airplane) provides the Executor with just-in-time context, corresponding to related recordsdata, documentation, or prior proof.
- Confirm: That is the standard gate. The Evaluator validates outputs in opposition to goal acceptance standards, whereas the Critic probes for subjective weaknesses like edge circumstances or hidden assumptions. Suggestions loops again to the Planner for iteration. Concurrently, the Monitor watches for systemic well being — monitoring drift, stalls, or finances spikes — able to set off a reset if the cycle degrades.

As illustrated in our Multi-Agent Cognitive Structure (Determine 2), these specialised brokers are located inside Horizontal Management Planes, which group capabilities by purposeful accountability. This construction transforms a chaotic “Bag of Brokers” right into a high-fidelity system by compartmentalising info movement.
To floor these technical layers, we are able to prolong our human office analogy to outline how these planes operate:
The Management Layer — The Administration
- The Orchestrator: Consider this because the Mission Supervisor. It holds the high-level goal. It doesn’t write code or search the net; its job is to delegate. It decides who does what subsequent.
- The Monitor: That is the “Well being & Security” officer. It watches the Orchestrator. If the agent will get caught in a loop, burns an excessive amount of cash (tokens), or drifts away from the unique purpose, the Monitor pulls the emergency brake or triggers an alert.
The Planning Layer — The Technique
- The Planner: Earlier than appearing, the agent should suppose. The Planner takes the Orchestrator’s purpose and breaks it down.
- Activity Graph / Backlog (Artifact): That is the “To-Do Record.” It’s dynamic — because the agent learns new issues, steps is likely to be added or eliminated. The Planner continuously updates this graph so the Orchestrator is aware of the candidate subsequent steps.
The Context Layer — The Reminiscence
- The Retriever: The Librarian. It fetches particular info (docs, earlier code) wanted for the present process.
- The Reminiscence Keeper: The Archivist. Not every part must be remembered. This function summarizes (compresses) what occurred and decides what’s necessary sufficient to retailer within the Context Retailer for the long run.
The Execution Layer — The Staff
- The Executor: The Specialist. This acts on the plan. It writes the code, calls the API, or generates the textual content.
- The Synthesiser: The Editor. The Executor’s output is likely to be messy or too verbose. The Synthesiser cleans it up and codecs it into a transparent end result for the Orchestrator to overview.
The Assurance Layer — High quality Management
- The Evaluator: Checks for goal correctness. (e.g., “Did the code compile?” “Did the output adhere to the JSON schema?”)
- The Critic: Checks for subjective dangers or edge circumstances. (e.g., “This code runs, but it surely has a safety vulnerability,” or “This logic is flawed.”)
- Suggestions Loops (Dotted Arrows): Discover the dotted strains going again as much as the Planner in Determine 2. If the Assurance layer fails the work, the agent updates the plan to repair the precise errors discovered.
The Mediation Layer — Battle Decision
- The Mediator: Generally the Evaluator says “Cross” however the Critic says “Fail.” Or maybe the Planner needs to do one thing the Monitor flags as dangerous. The Mediator acts because the tie-breaker to forestall the system from freezing in a impasse.

To see these archetypes in motion, we are able to hint a single request by the system. Think about we submit the next goal: “Write a script to scrape pricing information from a competitor’s web site and put it aside to our database.” The request doesn’t simply go to a “employee”; it triggers a choreographed sequence throughout the purposeful planes.
Step 1: Initialisation — Management Lane
The Orchestrator receives the target. It checks its “guardrails” (e.g., “Do now we have permission to scrape? What’s the finances?”).
- The Motion: It arms the purpose to the Planner.
- The Monitor begins a “stopwatch” and a “token counter” to make sure the agent doesn’t spend $50 making an attempt to scrape a $5 web site.
Step 2: Decomposition — Planning Lane
The Planner realises that is really 4 sub-tasks: (1) Analysis the location construction, (2) Write the scraper, (3) Map the information schema, (4) Write the DB ingestion logic.
- The Motion: It populates the Activity Graph / Backlog with these steps and identifies dependencies (e.g., you possibly can’t map the schema till you’ve researched the location).
Step 3: Grounding — Context Lane
Earlier than the employee begins, the Retriever appears to be like into the Context Retailer.
- The Motion: It pulls our “Database Schema Docs” and “Scraping Greatest Practices” and arms them to the Executor.
- This prevents the agent from “hallucinating” a database construction that doesn’t exist.
Step 4: Manufacturing — Execution Lane
The Executor writes the Python code for Step 1 and a couple of.
- The Motion: It locations the code within the Workspace / Outputs.
- The Synthesiser may take that uncooked code and wrap it in a “Standing Replace” for the Orchestrator, saying “I’ve a draft script prepared for verification.”
Step 5: The “Trial” — Assurance Lane
That is the place the dotted suggestions strains spring into motion:
- The Evaluator runs the code. It fails due to a
403 Forbiddenerror (anti-scraping bot). It sends a Dotted Arrow again to the Planner: “Goal web site blocked us; we want a header-rotation technique.” - The Critic appears to be like on the code and sees that the database password is hardcoded. It sends a Dotted Arrow to the Planner: “Safety threat: credentials should be setting variables.”
Step 6: Battle & Decision — Mediation Lane
Think about the Planner tries to repair the Critic’s safety concern, however the Evaluator says the brand new code now breaks the DB connection. They’re caught in a loop.
- The Motion: The Mediator steps in, appears to be like on the two conflicting “opinions,” and decides: “Prioritize the safety repair; I’ll instruct the Planner so as to add a selected step for Debugging the DB Connection particularly.”
- The Orchestrator receives this decision and updates the state.
Step 7: Remaining Supply
The loop repeats till the Evaluator (Code works) and Critic (Code is secure) each give a “Cross.”
- The Motion: The Synthesiser takes the ultimate, verified code and returns it to the person.
- The Reminiscence Keeper summarises the “403 Forbidden” encounter and shops it within the Context Retailer in order that subsequent time the agent is requested to scrape a web site, it remembers to make use of header-rotation from the beginning.
Core Software Archetypes: The ten Constructing Blocks of Dependable Agentic Methods
In the identical means we outlined widespread Agent archetypes, we are able to undertake an analogous train for his or her instruments. Software archetypes outline how that work is grounded, executed, and verified and which failure modes are contained because the system scales.

As we cowl in Determine 5 above, retrieval instruments can stop hallucination by forcing proof; schema validators and check harnesses stop silent failures by making correctness machine-checkable; finances meters and observability stop runaway loops by exposing (and constraining) token burn and drift; and permission gates plus sandboxes stop unsafe unwanted effects by limiting what brokers can do in the actual world.
The Bag of Brokers Anti-Sample
Earlier than exploring the Scaling Legal guidelines of Company, it’s instructive to outline the anti-pattern at the moment stalling most agentic AI deployments and that we goal to enhance upon: the “Bag of Brokers.” On this naive setup, builders throw a number of LLMs at an issue with no formal topology, leading to a system that sometimes reveals three deadly traits:
- Flat Topology: Each agent has an open line to each different agent. There isn’t a hierarchy, no gatekeeper, and no specialised planes to compartmentalize info movement.
- Noisy Chatter: With out an Orchestrator, brokers descend into round logic or “hallucination loops,” the place they echo and validate one another’s errors slightly than correcting them.
- Open-Loop Execution: Info flows unchecked by the group. There isn’t a devoted Assurance Airplane (Evaluators or Critics) to confirm information earlier than it reaches the following stage of the workflow.
To make use of a office analogy: the leap from a “Bag” to a “System” is identical leap a startup makes when it hires its first supervisor. Early-stage groups rapidly notice that headcount doesn’t equal output with out an organizational construction to comprise it. As Brooks put it in The Legendary Man-Month, “Including manpower to a late software program challenge makes it later.”
However how a lot construction is sufficient?
The reply lies within the Scaling Legal guidelines of Company from the DeepMind paper. This analysis uncovers the exact mathematical trade-offs between including extra LLM “brains” and the rising friction of their coordination.
The Scaling Legal guidelines of Company: Coordination, Topology, and Commerce-offs
The Science of Scaling Agent Methods’ paper’s core discovery is that cranking up the agent amount shouldn’t be a silver bullet for larger efficiency. Slightly there exists a rigorous trade-off between coordination overhead and process complexity. And not using a deliberate topology, including brokers is like including engineers to a challenge with out an orchestrating supervisor: you sometimes don’t get extra invaluable output; you’ll possible simply get extra conferences, undirected and doubtlessly wastful work and noisy chatter.

Experimental Setup for MAS Analysis
The DeepMind group evaluated their Multi-Agent Methods throughout 4 process suites and examined the agent designs throughout very completely different workloads to keep away from tying the conclusions to a selected duties or benchmark:
- BrowseComp-Plus (2025): Internet looking / info retrieval, framed as multi-website info location — a check of search, navigation, and proof gathering.
- Finance-Agent (2025): Finance duties designed to imitate entry-level analyst efficiency — checks structured reasoning, quantitative interpretation, and determination assist.
- PlanCraft (2024): Agent planning in a Minecraft setting — a basic long-horizon planning setup with state, constraints, and sequencing.
- WorkBench (2024): Planning and gear choice for widespread enterprise actions — checks whether or not brokers can decide instruments/actions and execute sensible workflows.
5 coordination topologies are examined in In the direction of a Science of Scaling Agent Methods: a Single-Agent System (SAS)and 4 Multi-Agent System (MAS) designs — Impartial, Decentralised, Centralised, and Hybrid. Topology issues as a result of it determines whether or not including brokers buys helpful parallel work or simply buys extra communication.
- SAS (Single Agent): One agent does every part sequentially. Minimal coordination overhead, however restricted parallelism.
- MAS (Impartial): Many brokers work in parallel, then outputs are synthesised right into a remaining reply. Sturdy for breadth (analysis, ideation), weaker for tightly coupled reasoning chains.
- MAS (Decentralised): Brokers debate over a number of rounds and determine by way of majority vote. This will enhance robustness, however communication grows rapidly and errors can compound by repeated cross-talk.
- MAS (Centralised): A single Orchestrator coordinates specialist sub-agents. This “supervisor + group” design is often extra steady at scale as a result of it constrains chatter and accommodates failure modes.
- MAS (Hybrid): Central orchestration plus focused peer-to-peer trade. Extra versatile, but additionally probably the most complicated to handle and the best to overbuild.

This framing additionally clarifies why unstructured “bag of brokers” designs will be very harmful. Kim et al. report as much as 17.2× error amplification in poorly coordinated networks, whereas centralised coordination accommodates this to ~4.4× by appearing as a circuit breaker.
Importantly, the paper exhibits these dynamics are benchmark-dependent.
- On Finance-Agent (extremely decomposable monetary reasoning), MAS delivers the largest positive factors — Centralised +80.8%, Decentralised +74.5%, Hybrid +73.1% over SAS — as a result of brokers can cut up the work into parallel analytic threads after which synthesise.
- On BrowseComp-Plus (dynamic net navigation and synthesis), enhancements are modest and topology-sensitive: Decentralised performs finest (+9.2%), whereas Centralised is basically flat (+0.2%) and Impartial can collapse (−35%) on account of unchecked propagation and noisy cross-talk.
- Workbench sits within the center, exhibiting solely marginal motion (~−11% to +6% total; Decentralised +5.7%), suggesting a near-balance between orchestration profit and coordination tax.
- And on PlanCraft (strictly sequential, state-dependent planning), each MAS variant degrades efficiency (~−39% to −70%), as a result of coordination overhead consumes finances with out offering actual parallel benefit.
The sensible antidote is to impose some construction in your MAS by mapping brokers into purposeful planes and utilizing central management to suppress error propagation and coordination sprawl.
That takes us to the paper’s core contribution: the Scaling Legal guidelines of Company.
The Scaling Legal guidelines of Company
Based mostly on the findings from Kim et al., we are able to derive three Golden Guidelines for setting up an efficient Agentic coordination structure:
- The 17x Rule: Unstructured networks amplify errors exponentially. Our Centralized Management Airplane (the Orchestrator) suppresses this by appearing as a single level of verification.
- The Software-Coordination Commerce-off: Extra instruments require extra grounding. Our Context Airplane (Retriever) ensures brokers don’t “guess” the right way to use instruments, decreasing the noise that results in overhead.
- The 45% Saturation Level: Agent coordination yields the very best returns when single-agent efficiency is low. As fashions get smarter, we should lean on the Monitor Agent to simplify the topology and keep away from pointless complexity.

In my expertise the Assurance layer is usually the largest differentiator to enhancing MAS efficiency. The “Assurance → Planner” loop transforms our MAS from an Open-Loop (fireplace and overlook) system to a Closed-Loop (self-correcting) system that accommodates error propagation and permitting intelligence to scale to extra complicated duties.
Combined-Mannequin Agent Groups: When Heterogeneous LLMs Assist (and When They Harm)
The DeepMind group explicitly check heterogeneous groups, in different phrases a unique base LLM for the Orchestrator than for the sub-agents, and mixing capabilities in decentralised debate. The teachings listed here are very attention-grabbing from a sensible standapoint. They report three predominant findings (proven on BrowseComp-Plus process/dataset):
- Centralised MAS: mixing will help or damage relying on mannequin household
- For Anthropic, a low-capability orchestrator + high-capability sub-agents beats an all–high-capability centralised group (0.42 vs 0.32, +31%).
- For OpenAI and Gemini, heterogeneous centralised setups degrade versus homogeneous high-capability.
Takeaway: a weak orchestrator can turn into a bottleneck in some households, even when the employees are robust (as a result of it’s the routing/synthesis chokepoint).
2. Decentralised MAS: mixed-capability debate is surprisingly sturdy
- Combined-capability decentralised debate is near-optimal or typically higher than homogeneous high-capability baselines (they offer examples: OpenAI 0.53 vs 0.50; Anthropic 0.47 vs 0.37; Gemini 0.42 vs 0.43).
Takeaway: voting/peer verification can “common out” weaker brokers, so heterogeneity hurts lower than you may anticipate.
3. In centralised programs, sub-agent functionality issues greater than orchestrator functionality.
Throughout all households, configurations with high-capability sub-agents outperform these with high-capability orchestrators.
The sensible total key message from the DeepMind group is that in the event you’re spending cash selectively, spend it on the employees (the brokers producing the substance), not essentially on the supervisor however validate in your mannequin household as a result of the “low-cost orchestrator + robust staff” sample didn’t generalise uniformly.
Understanding the Price of a Multi-Agent System
A ceaselessly requested query is the right way to outline the price of a MAS i.e., the token finances that in the end interprets into {dollars}. Topology determines whether or not including brokers buys parallel work or just buys extra communication. To make value concrete, we are able to mannequin it with a small set of knobs:
- okay = max iterations per agent (what number of plan/act/mirror steps every agent is allowed)
- n = variety of brokers (what number of “staff” we spin up)
- r = orchestrator rounds (what number of assign → gather → revise cycles we run)
- d = debate rounds (what number of back-and-forth rounds earlier than a vote/determination)
- p = peer-communication rounds (how usually brokers discuss instantly to one another)
- m = common peer requests per spherical (what number of peer messages every agent sends per peer spherical)
A sensible means to consider whole value is:
Complete MAS value ≈ Work value + Coordination value
- Work value is pushed primarily by n × okay (what number of brokers you run, and what number of steps every takes).
- Coordination value is pushed by rounds × fan-out, i.e. what number of occasions we re-coordinate (r, d, p) multiplied by what number of messages are exchanged (n, m) — plus the hidden tax of brokers having to learn all that further context.
To transform this into {dollars}, first use the knobs (n, okay, r, d, p, m) to estimate whole enter/output tokens generated and consumed, then multiply by your mannequin’s per-token value:
$ Price ≈ (InputTokens ÷ 1M × $/1M_input) + (OutputTokens ÷ 1M × $/1M_output)
The place:
- InputTokens embrace every part brokers learn (shared transcript, retrieved docs, software outputs, different brokers’ messages).
- OutputTokens embrace every part brokers write (plans, intermediate reasoning, debate messages, remaining synthesis).
For this reason decentralised and hybrid topologies can get costly very quick: debate and peer messaging inflate each message quantity and context size, so we pay twice as brokers generate extra textual content, and everybody has to learn extra textual content. In follow, as soon as brokers start broadly speaking with one another, coordination can begin to really feel nearer to an n² impact.
The important thing takeaway is that agent scaling is simply useful if the duty positive factors extra from parallelism than it loses to coordination overhead. We should always use extra brokers when the work will be cleanly parallelised (analysis, search, impartial answer makes an attempt). Conversely we ought to be cautious when the duty is sequential and tightly coupled (multi-step reasoning, lengthy dependency chains), as a result of further rounds and cross-talk can break the logic chain and switch “extra brokers” into “extra noise.”
MAS Structure Scaling Legislation: Making MAS Design Knowledge-Pushed As an alternative of Exhaustive
A pure query is whether or not multi-agent programs have “structure scaling legal guidelines,” analogous to the empirical scaling legal guidelines for LLM parameters. Kim et al. argue the reply is sure. To sort out the combinatorial search downside — topology × agent depend × rounds × mannequin household — they evaluated 180 configurations throughout 4 benchmarks, then educated a predictive mannequin on coordination traces (e.g., effectivity vs. overhead, error amplification, redundancy). The mannequin can forecast which topology is more likely to carry out finest, reaching R² ≈ 0.513 and choosing the right coordination technique for ~87% of held-out configurations. The sensible shift is from “strive every part” to operating a small set of quick probe configurations (less expensive and sooner), measure early coordination dynamics, and solely then commit full finances to the architectures the mannequin predicts will win.
Conclusions & Remaining Ideas
On this publish, we reviewed DeepMind’s In the direction of a Science of Scaling Agent Methods and distilled probably the most sensible classes for constructing higher-performing multi-agent programs. These design guidelines helps us keep away from poking round in the dead of night and hoping for the very best. The headline takeaway is that extra brokers shouldn’t be a assured path to raised outcomes. Agent scaling entails actual trade-offs, ruled by measurable scaling legal guidelines, and the “proper” variety of brokers will depend on process problem, the bottom mannequin’s functionality, and the way the system is organised.
Right here’s what the analysis suggests about agent amount:
- Diminishing returns (saturation): Including brokers doesn’t produce indefinite positive factors. In lots of experiments, efficiency rises initially, then plateaus — usually round ~4 brokers — after which extra brokers contribute little.
- The “45% rule”: Further brokers assist most when the bottom mannequin performs poorly on the duty (under ~45%). When the bottom mannequin is already robust, including brokers can set off functionality saturation, the place efficiency stagnates or turns into noisy slightly than enhancing.
- Topology issues: Amount alone shouldn’t be the story; organisation dominates outcomes.
- Centralised designs are inclined to scale extra reliably, with an Orchestrator serving to comprise errors and implement construction.
- Decentralised “bag of brokers” designs can turn into risky because the group grows, typically amplifying errors as an alternative of refining reasoning.
- Parallel vs. sequential work: Extra brokers shine on parallelisable duties (e.g., broad analysis), the place they will materially enhance protection and throughput. However for sequential reasoning, including brokers can degrade efficiency because the “logic chain” weakens when handed by too many steps.
- The coordination tax: Each extra agent provides overhead. Extra messages, extra latency, extra alternatives for drift. If the duty isn’t complicated sufficient to justify that overhead, coordination prices outweigh the advantages of additional LLM “brains”.
With these Golden Guidelines of Company in thoughts, I wish to finish by wishing you the very best in your MAS build-out. Multi-Agent Methods sit proper on the frontier of present utilized AI, primed to convey the following degree of enterprise worth in 2026 — and so they include the sorts of technical trade-offs that make this work genuinely attention-grabbing: balancing functionality, coordination, and design to get dependable efficiency. In constructing your individual MAS you’ll undoubtedly uncover Golden Guidelines of your individual that broaden our data over this uncharted territory.
A remaining thought on DeepMind’s “45%” threshold: multi-agent programs are, in some ways, a workaround for the bounds of immediately’s LLMs. As base fashions turn into extra succesful, fewer duties will sit within the low-accuracy regime the place further brokers add actual worth. Over time, we may have much less decomposition and coordination, and extra issues could also be solvable by a single mannequin end-to-end, as we transfer towards synthetic basic intelligence (AGI).
Paraphrasing Tolkien: one mannequin might but rule all of them.
📚 Additional Studying
- Yubin Kim et al. (2025) — In the direction of a Science of Scaling Agent Methods — A big managed examine deriving quantitative scaling ideas for agent programs throughout a number of coordination topologies, mannequin households, and benchmarks (together with saturation results and coordination overhead).
- Cursor Workforce (2026) — Scaling long-running autonomous coding — A sensible case examine describing how Cursor coordinates massive numbers of coding brokers over prolonged runs (together with their “construct an online browser” experiment) and what that suggests for planner–employee type topologies.
- Lei Wang et al. (2023) — A Survey on Giant Language Mannequin based mostly Autonomous Brokers — A complete survey that maps the agent design area (planning, reminiscence, instruments, interplay patterns), helpful for grounding your 10-archetype taxonomy in prior literature.
- Qingyun Wu et al. (2023) — AutoGen: Enabling Subsequent-Gen LLM Purposes by way of Multi-Agent Dialog — A framework paper on programming multi-agent conversations and interplay patterns, with empirical outcomes throughout duties and agent configurations.
- Shunyu Yao et al. (2022) — ReAct: Synergizing Reasoning and Appearing in Language Fashions — Introduces the interleaved “purpose + act” loop that underpins many trendy tool-using agent designs and helps cut back hallucination by way of grounded actions.
- Noah Shinn et al. (2023) — Reflexion: Language Brokers with Verbal Reinforcement Studying — A clear template for closed-loop enchancment: brokers mirror on suggestions and retailer “classes realized” in reminiscence to enhance subsequent makes an attempt with out weight updates.
- LangChain (n.d.) — Multi-agent — Sensible documentation protecting widespread multi-agent patterns and the right way to construction interplay so you possibly can keep away from uncontrolled “bag of brokers” chatter.
- LangChain (n.d.) — LangGraph overview — A centered overview of orchestration options that matter for actual programs (sturdy execution, human-in-the-loop, streaming, and control-flow).
- langchain-ai (n.d.) — LangGraph (GitHub repository) — The reference implementation for a graph-based orchestration layer, helpful if readers wish to examine concrete design decisions and primitives for stateful brokers.
- Frederick P. Brooks, Jr. (1975) — The Legendary Man-Month — The basic coordination lesson (Brooks’s Legislation) that interprets surprisingly properly to agent programs: including extra “staff” can enhance overhead and sluggish progress with out the suitable construction.















{kind=link}