



TL;DR: In RLHF, there’s pressure between the reward studying part, which makes use of human choice within the type of comparisons, and the RL fine-tuning part, which optimizes a single, non-comparative reward. What if we carried out RL in a comparative approach?
Determine 1:
This diagram illustrates the distinction between reinforcement studying from absolute suggestions and relative suggestions. By incorporating a brand new element – pairwise coverage gradient, we are able to unify the reward modeling stage and RL stage, enabling direct updates based mostly on pairwise responses.
Giant Language Fashions (LLMs) have powered more and more succesful digital assistants, equivalent to GPT-4, Claude-2, Bard and Bing Chat. These programs can reply to complicated consumer queries, write code, and even produce poetry. The approach underlying these wonderful digital assistants is Reinforcement Studying with Human Suggestions (RLHF). RLHF goals to align the mannequin with human values and eradicate unintended behaviors, which might usually come up because of the mannequin being uncovered to a big amount of low-quality information throughout its pretraining part.
Proximal Coverage Optimization (PPO), the dominant RL optimizer on this course of, has been reported to exhibit instability and implementation problems. Extra importantly, there’s a persistent discrepancy within the RLHF course of: regardless of the reward mannequin being educated utilizing comparisons between numerous responses, the RL fine-tuning stage works on particular person responses with out making any comparisons. This inconsistency can exacerbate points, particularly within the difficult language technology area.
Given this backdrop, an intriguing query arises: Is it potential to design an RL algorithm that learns in a comparative method? To discover this, we introduce Pairwise Proximal Coverage Optimization (P3O), a technique that harmonizes the coaching processes in each the reward studying stage and RL fine-tuning stage of RLHF, offering a passable answer to this subject.
Background
Determine 2:
An outline of the three phases of RLHF from an OpenAI weblog submit. Notice that the third stage falls beneath Reinforcement Studying with Absolute Suggestions as proven on the left aspect of Determine 1.
In conventional RL settings, the reward is specified manually by the designer or supplied by a well-defined reward perform, as in Atari video games. Nonetheless, to steer a mannequin towards useful and innocent responses, defining reward is just not simple. RLHF addresses this drawback by studying the reward perform from human suggestions, particularly within the type of comparisons, after which making use of RL to optimize the discovered reward perform.
The RLHF pipeline is split into a number of phases, detailed as follows:
Supervised Nice-Tuning Stage: The pre-trained mannequin undergoes the utmost chance loss on a top quality dataset, the place it learns to reply to human queries by means of mimicking.
Reward Modeling Stage: The SFT mannequin is prompted with prompts (x) to provide pairs of solutions (y_1,y_2sim pi^{textual content{SFT}}(yvert x)). These generated responses type a dataset. The response pairs are offered to human labellers who specific a choice for one reply over the opposite, denoted as (y_w succ y_l). A comparative loss is then used to coach a reward mannequin (r_phi):
[mathcal{L}_R = mathbb{E}_{(x,y_l,y_w)simmathcal{D}}log sigmaleft(r_phi(y_w|x)-r_phi(y_l|x)right)]
RL Nice-Tuning Stage: The SFT mannequin serves because the initialization of this stage, and an RL algorithm optimizes the coverage in the direction of maximizing the reward whereas limiting the deviation from the preliminary coverage. Formally, that is executed by means of:
[max_{pi_theta}mathbb{E}_{xsim mathcal{D}, ysim pi_theta(cdotvert x)}left[r_phi(yvert x)-beta D_{text{KL}}(pi_theta(cdotvert x)Vert pi^{text{SFT}}(cdotvert x))right]]
An inherent problem with this strategy is the non-uniqueness of the reward. For example, given a reward perform (r(yvert x)), a easy shift within the reward of the immediate to (r(yvert x)+delta(x)) creates one other legitimate reward perform. These two reward capabilities end in the identical loss for any response pairs, however they differ considerably when optimized towards with RL. In an excessive case, if the added noise causes the reward perform to have a wide variety, an RL algorithm is perhaps misled to extend the chance of responses with larger rewards, regardless that these rewards will not be significant. In different phrases, the coverage is perhaps disrupted by the reward scale info within the immediate (x), but fails to be taught the helpful half – relative choice represented by the reward distinction. To handle this subject, our purpose is to develop an RL algorithm that’s invariant to reward translation.
Derivation of P3O
Our concept stems from the vanilla coverage gradient (VPG). VPG is a broadly adopted first-order RL optimizer, favored for its simplicity and ease of implementation. In a contextual bandit (CB) setting, the VPG is formulated as:
[nabla mathcal{L}^{text{VPG}} = mathbb{E}_{ysimpi_{theta}} r(y|x)nablalogpi_{theta}(y|x)]
By some algebraic manipulation, we are able to rewrite the coverage gradient in a comparative type that entails two responses of the identical immediate. We identify it Pairwise Coverage Gradient:
[mathbb{E}_{y_1,y_2simpi_{theta}}left(r(y_1vert x)-r(y_2vert x)right)nablaleft(logfrac{pi_theta(y_1vert x)}{pi_theta(y_2vert x)}right)/2]
In contrast to VPG, which instantly depends on absolutely the magnitude of the reward, PPG makes use of the reward distinction. This permits us to bypass the aforementioned subject of reward translation. To additional increase efficiency, we incorporate a replay buffer utilizing Significance Sampling and keep away from giant gradient updates by way of Clipping.
Significance sampling: We pattern a batch of responses from the replay buffer which encompass responses generated from (pi_{textual content{previous}}) after which compute the significance sampling ratio for every response pair. The gradient is the weighted sum of the gradients computed from every response pair.
Clipping: We clip the significance sampling ratio in addition to the gradient replace to penalize excessively giant updates. This system allows the algorithm to trade-off KL divergence and reward extra effectively.
There are two alternative ways to implement the clipping approach, distinguished by both separate or joint clipping. The ensuing algorithm is known as Pairwise Proximal Coverage Optimization (P3O), with the variants being V1 or V2 respectively. Yow will discover extra particulars in our unique paper.
Analysis
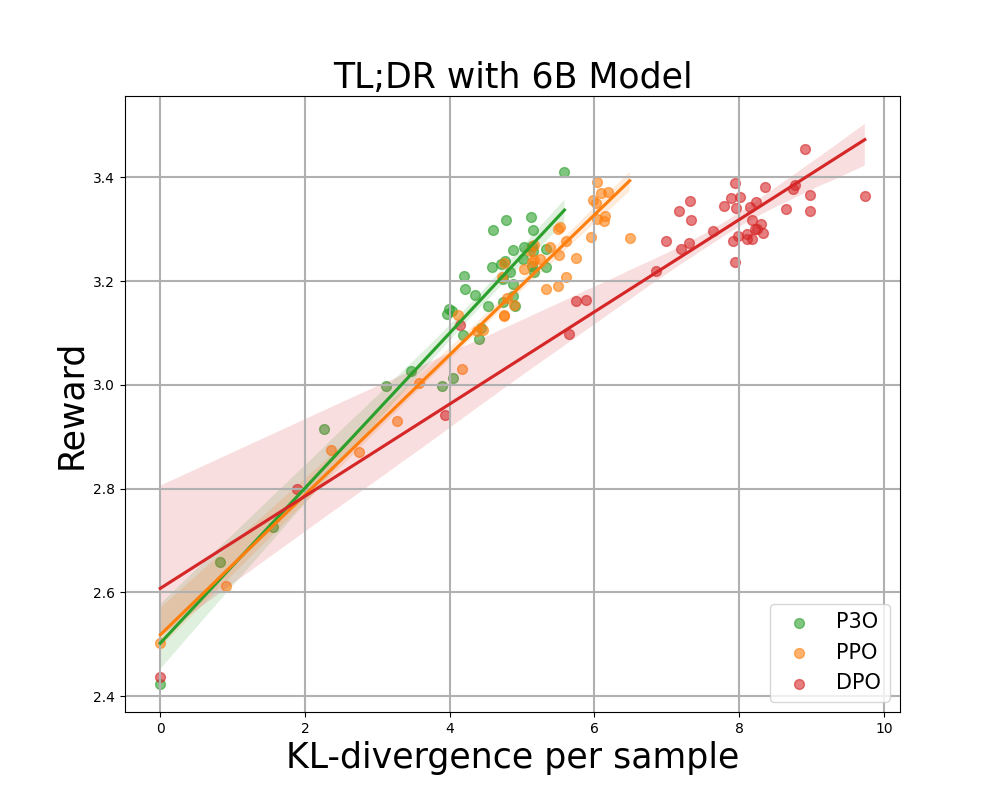
Determine 3:
KL-Reward frontier for TL;DR, each sequence-wise KL and reward are averaged over 200 check prompts and computed each 500 gradient steps. We discover {that a} easy linear perform suits the curve effectively. P3O has the perfect KL-Reward trade-off among the many three.
We discover two totally different open-ended textual content technology duties, summarization and question-answering. In summarization, we make the most of the TL;DR dataset the place the immediate (x) is a discussion board submit from Reddit, and (y) is a corresponding abstract. For question-answering, we use Anthropic Useful and Innocent (HH), the immediate (x) is a human question from numerous subjects, and the coverage ought to be taught to provide an interesting and useful response (y).
We evaluate our algorithm P3O with a number of efficient and consultant approaches for LLM alignment. We begin with the SFT coverage educated by most chance. For RL algorithms, we think about the dominant strategy PPO and the newly proposed DPO. DPO instantly optimizes the coverage in the direction of the closed-form answer of the KL-constrained RL drawback. Though it’s proposed as an offline alignment methodology, we make it on-line with the assistance of a proxy reward perform.
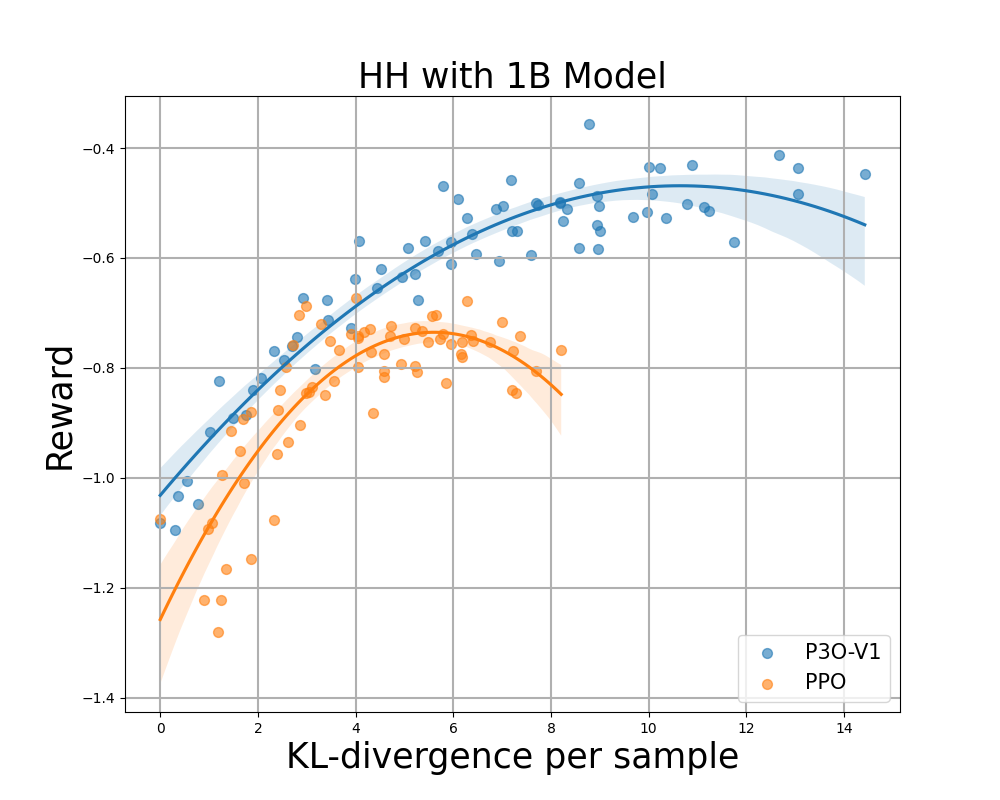
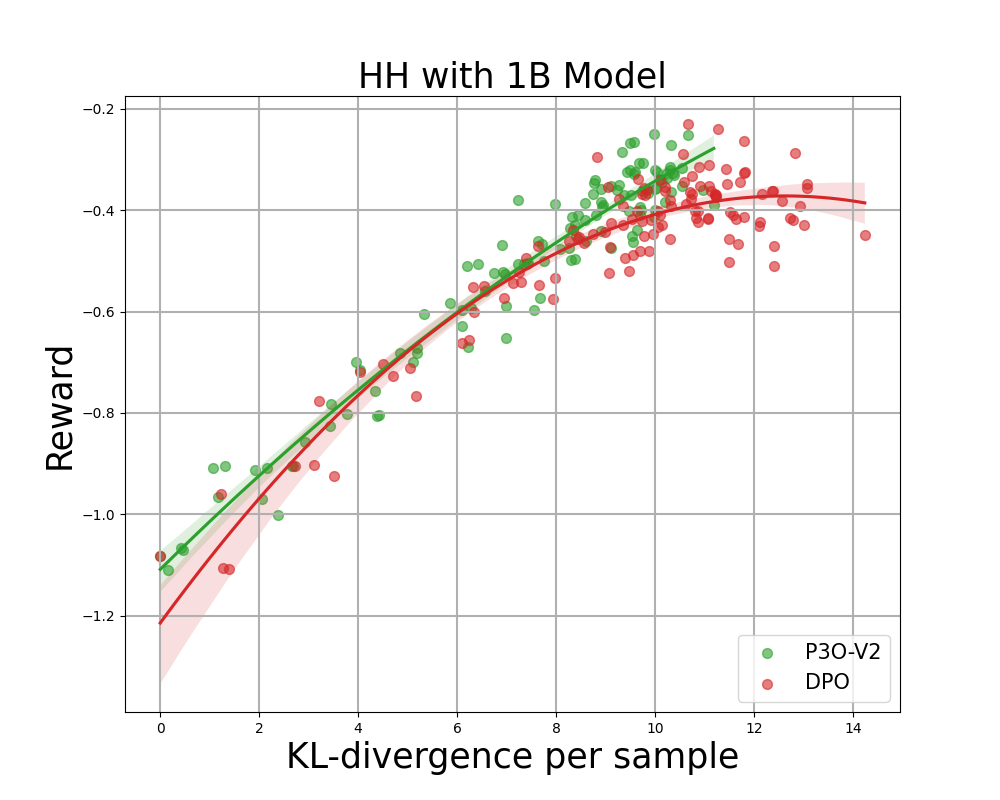
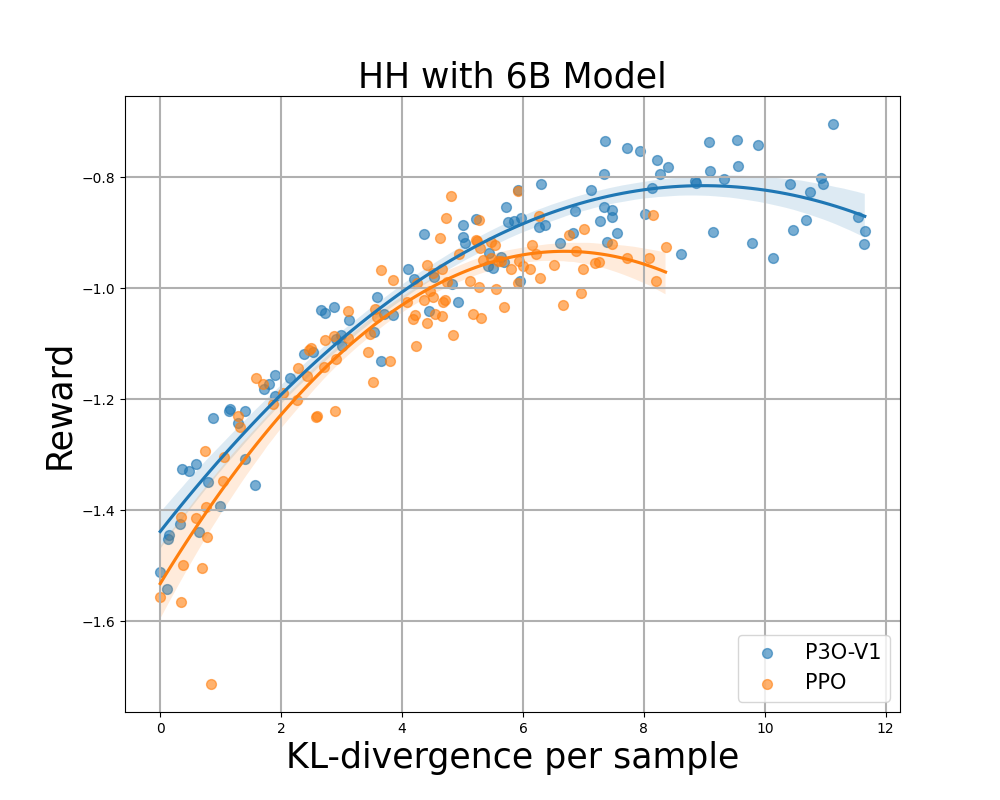
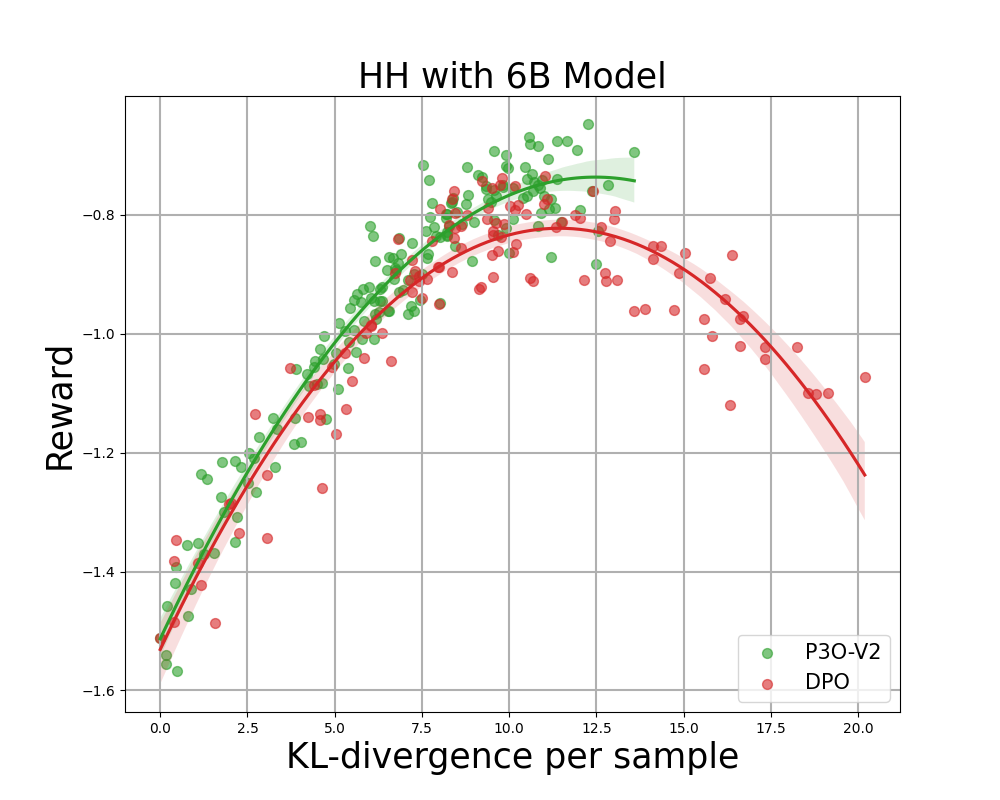
Determine 4:
KL-Reward frontier for HH, every level represents a mean of outcomes over 280 check prompts and calculated each 500 gradient updates. Left two figures evaluate P3O-V1 and PPO with various base mannequin sizes; Proper two figures evaluate P3O-V2 and DPO. Outcomes exhibiting that P3O cannot solely obtain larger reward but in addition yield higher KL management.
Deviating an excessive amount of from the reference coverage would lead the web coverage to chop corners of the reward mannequin and produce incoherent continuations, as identified by earlier works. We’re excited about not solely the effectively established metric in RL literature – the reward, but in addition in how far the discovered coverage deviates from the preliminary coverage, measured by KL-divergence. Subsequently, we examine the effectiveness of every algorithm by its frontier of achieved reward and KL-divergence from the reference coverage (KL-Reward Frontier). In Determine 4 and Determine 5, we uncover that P3O has strictly dominant frontiers than PPO and DPO throughout numerous mannequin sizes.
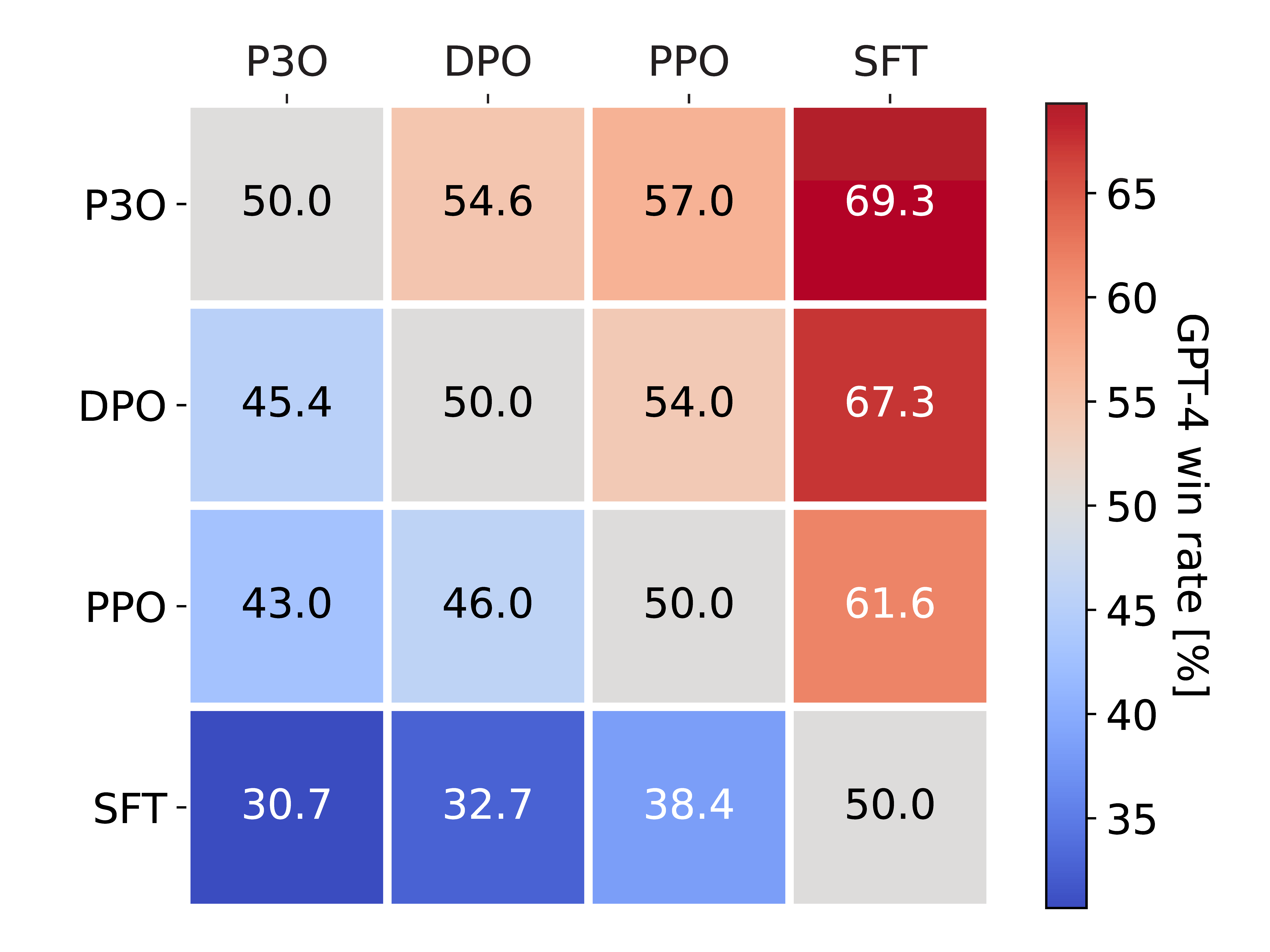
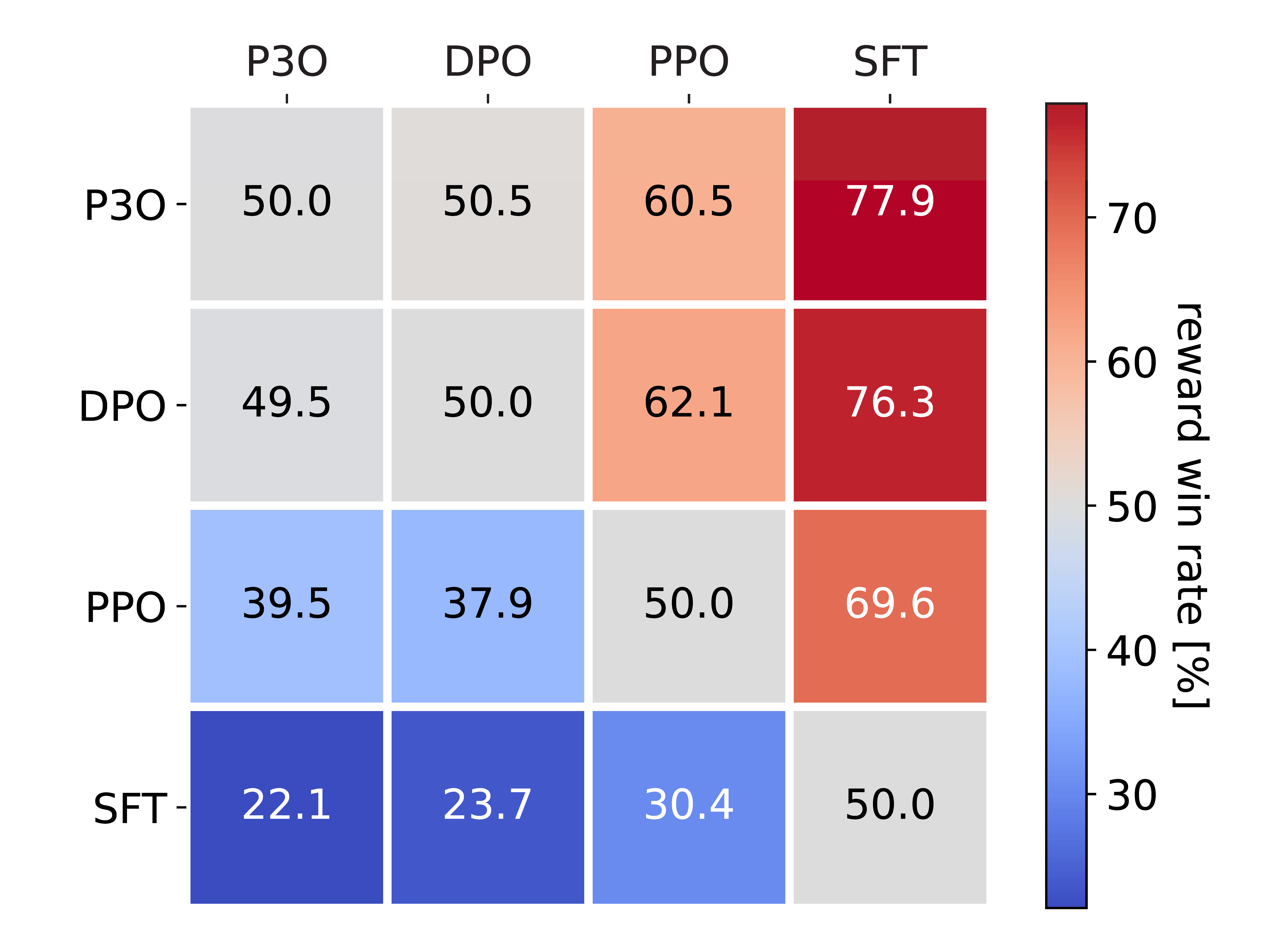
Determine 5:
Left determine shows the win charge evaluated by GPT-4. Proper determine presents the win charge based mostly on direct comparability of the proxy reward. Regardless of the excessive correlation between two figures, we discovered that the reward win charge have to be adjusted in accordance with the KL to be able to align with the GPT-4 win charge.
To instantly assess the standard of generated responses, we additionally carry out Head-to-Head Comparisons between each pair of algorithms within the HH dataset. We use two metrics for analysis: (1) Reward, the optimized goal throughout on-line RL, (2) GPT-4, as a trustworthy proxy for human analysis of response helpfulness. For the latter metric, we level out that earlier research present that GPT-4 judgments correlate strongly with people, with human settlement with GPT-4 sometimes comparable or larger than inter-human annotator settlement.
Determine 5 presents the excellent pairwise comparability outcomes. The common KL-divergence and reward rating of those fashions is DPO > P3O > PPO > SFT. Though DPO marginally surpasses P3O in reward, it has a significantly larger KL-divergence, which can be detrimental to the standard of technology. In consequence, DPO has a reward win charge of 49.5% towards P3O, however solely 45.4% as evaluated by GPT-4. In contrast with different strategies, P3O reveals a GPT-4 win charge of 57.0% towards PPO and 69.3% towards SFT. This result’s in keeping with our findings from the KL-Reward frontier metric, affirming that P3O may higher align with human choice than earlier baselines.
Conclusion
On this weblog submit, we current new insights into aligning giant language fashions with human preferences by way of reinforcement studying. We proposed the Reinforcement Studying with Relative Suggestions framework, as depicted in Determine 1. Below this framework, we develop a novel coverage gradient algorithm – P3O. This strategy unifies the elemental ideas of reward modeling and RL fine-tuning by means of comparative coaching. Our outcomes present that P3O surpasses prior strategies by way of the KL-Reward frontier in addition to GPT-4 win-rate.
BibTex
This weblog is predicated on our current paper and weblog. If this weblog evokes your work, please think about citing it with:
@article{wu2023pairwise,
title={Pairwise Proximal Coverage Optimization: Harnessing Relative Suggestions for LLM Alignment},
writer={Wu, Tianhao and Zhu, Banghua and Zhang, Ruoyu and Wen, Zhaojin and Ramchandran, Kannan and Jiao, Jiantao},
journal={arXiv preprint arXiv:2310.00212},
yr={2023}
}
TL;DR: In RLHF, there’s pressure between the reward studying part, which makes use of human choice within the type of comparisons, and the RL fine-tuning part, which optimizes a single, non-comparative reward. What if we carried out RL in a comparative approach?
Determine 1:
This diagram illustrates the distinction between reinforcement studying from absolute suggestions and relative suggestions. By incorporating a brand new element – pairwise coverage gradient, we are able to unify the reward modeling stage and RL stage, enabling direct updates based mostly on pairwise responses.
Giant Language Fashions (LLMs) have powered more and more succesful digital assistants, equivalent to GPT-4, Claude-2, Bard and Bing Chat. These programs can reply to complicated consumer queries, write code, and even produce poetry. The approach underlying these wonderful digital assistants is Reinforcement Studying with Human Suggestions (RLHF). RLHF goals to align the mannequin with human values and eradicate unintended behaviors, which might usually come up because of the mannequin being uncovered to a big amount of low-quality information throughout its pretraining part.
Proximal Coverage Optimization (PPO), the dominant RL optimizer on this course of, has been reported to exhibit instability and implementation problems. Extra importantly, there’s a persistent discrepancy within the RLHF course of: regardless of the reward mannequin being educated utilizing comparisons between numerous responses, the RL fine-tuning stage works on particular person responses with out making any comparisons. This inconsistency can exacerbate points, particularly within the difficult language technology area.
Given this backdrop, an intriguing query arises: Is it potential to design an RL algorithm that learns in a comparative method? To discover this, we introduce Pairwise Proximal Coverage Optimization (P3O), a technique that harmonizes the coaching processes in each the reward studying stage and RL fine-tuning stage of RLHF, offering a passable answer to this subject.
Background
Determine 2:
An outline of the three phases of RLHF from an OpenAI weblog submit. Notice that the third stage falls beneath Reinforcement Studying with Absolute Suggestions as proven on the left aspect of Determine 1.
In conventional RL settings, the reward is specified manually by the designer or supplied by a well-defined reward perform, as in Atari video games. Nonetheless, to steer a mannequin towards useful and innocent responses, defining reward is just not simple. RLHF addresses this drawback by studying the reward perform from human suggestions, particularly within the type of comparisons, after which making use of RL to optimize the discovered reward perform.
The RLHF pipeline is split into a number of phases, detailed as follows:
Supervised Nice-Tuning Stage: The pre-trained mannequin undergoes the utmost chance loss on a top quality dataset, the place it learns to reply to human queries by means of mimicking.
Reward Modeling Stage: The SFT mannequin is prompted with prompts (x) to provide pairs of solutions (y_1,y_2sim pi^{textual content{SFT}}(yvert x)). These generated responses type a dataset. The response pairs are offered to human labellers who specific a choice for one reply over the opposite, denoted as (y_w succ y_l). A comparative loss is then used to coach a reward mannequin (r_phi):
[mathcal{L}_R = mathbb{E}_{(x,y_l,y_w)simmathcal{D}}log sigmaleft(r_phi(y_w|x)-r_phi(y_l|x)right)]
RL Nice-Tuning Stage: The SFT mannequin serves because the initialization of this stage, and an RL algorithm optimizes the coverage in the direction of maximizing the reward whereas limiting the deviation from the preliminary coverage. Formally, that is executed by means of:
[max_{pi_theta}mathbb{E}_{xsim mathcal{D}, ysim pi_theta(cdotvert x)}left[r_phi(yvert x)-beta D_{text{KL}}(pi_theta(cdotvert x)Vert pi^{text{SFT}}(cdotvert x))right]]
An inherent problem with this strategy is the non-uniqueness of the reward. For example, given a reward perform (r(yvert x)), a easy shift within the reward of the immediate to (r(yvert x)+delta(x)) creates one other legitimate reward perform. These two reward capabilities end in the identical loss for any response pairs, however they differ considerably when optimized towards with RL. In an excessive case, if the added noise causes the reward perform to have a wide variety, an RL algorithm is perhaps misled to extend the chance of responses with larger rewards, regardless that these rewards will not be significant. In different phrases, the coverage is perhaps disrupted by the reward scale info within the immediate (x), but fails to be taught the helpful half – relative choice represented by the reward distinction. To handle this subject, our purpose is to develop an RL algorithm that’s invariant to reward translation.
Derivation of P3O
Our concept stems from the vanilla coverage gradient (VPG). VPG is a broadly adopted first-order RL optimizer, favored for its simplicity and ease of implementation. In a contextual bandit (CB) setting, the VPG is formulated as:
[nabla mathcal{L}^{text{VPG}} = mathbb{E}_{ysimpi_{theta}} r(y|x)nablalogpi_{theta}(y|x)]
By some algebraic manipulation, we are able to rewrite the coverage gradient in a comparative type that entails two responses of the identical immediate. We identify it Pairwise Coverage Gradient:
[mathbb{E}_{y_1,y_2simpi_{theta}}left(r(y_1vert x)-r(y_2vert x)right)nablaleft(logfrac{pi_theta(y_1vert x)}{pi_theta(y_2vert x)}right)/2]
In contrast to VPG, which instantly depends on absolutely the magnitude of the reward, PPG makes use of the reward distinction. This permits us to bypass the aforementioned subject of reward translation. To additional increase efficiency, we incorporate a replay buffer utilizing Significance Sampling and keep away from giant gradient updates by way of Clipping.
Significance sampling: We pattern a batch of responses from the replay buffer which encompass responses generated from (pi_{textual content{previous}}) after which compute the significance sampling ratio for every response pair. The gradient is the weighted sum of the gradients computed from every response pair.
Clipping: We clip the significance sampling ratio in addition to the gradient replace to penalize excessively giant updates. This system allows the algorithm to trade-off KL divergence and reward extra effectively.
There are two alternative ways to implement the clipping approach, distinguished by both separate or joint clipping. The ensuing algorithm is known as Pairwise Proximal Coverage Optimization (P3O), with the variants being V1 or V2 respectively. Yow will discover extra particulars in our unique paper.
Analysis
Determine 3:
KL-Reward frontier for TL;DR, each sequence-wise KL and reward are averaged over 200 check prompts and computed each 500 gradient steps. We discover {that a} easy linear perform suits the curve effectively. P3O has the perfect KL-Reward trade-off among the many three.
We discover two totally different open-ended textual content technology duties, summarization and question-answering. In summarization, we make the most of the TL;DR dataset the place the immediate (x) is a discussion board submit from Reddit, and (y) is a corresponding abstract. For question-answering, we use Anthropic Useful and Innocent (HH), the immediate (x) is a human question from numerous subjects, and the coverage ought to be taught to provide an interesting and useful response (y).
We evaluate our algorithm P3O with a number of efficient and consultant approaches for LLM alignment. We begin with the SFT coverage educated by most chance. For RL algorithms, we think about the dominant strategy PPO and the newly proposed DPO. DPO instantly optimizes the coverage in the direction of the closed-form answer of the KL-constrained RL drawback. Though it’s proposed as an offline alignment methodology, we make it on-line with the assistance of a proxy reward perform.
Determine 4:
KL-Reward frontier for HH, every level represents a mean of outcomes over 280 check prompts and calculated each 500 gradient updates. Left two figures evaluate P3O-V1 and PPO with various base mannequin sizes; Proper two figures evaluate P3O-V2 and DPO. Outcomes exhibiting that P3O cannot solely obtain larger reward but in addition yield higher KL management.
Deviating an excessive amount of from the reference coverage would lead the web coverage to chop corners of the reward mannequin and produce incoherent continuations, as identified by earlier works. We’re excited about not solely the effectively established metric in RL literature – the reward, but in addition in how far the discovered coverage deviates from the preliminary coverage, measured by KL-divergence. Subsequently, we examine the effectiveness of every algorithm by its frontier of achieved reward and KL-divergence from the reference coverage (KL-Reward Frontier). In Determine 4 and Determine 5, we uncover that P3O has strictly dominant frontiers than PPO and DPO throughout numerous mannequin sizes.
Determine 5:
Left determine shows the win charge evaluated by GPT-4. Proper determine presents the win charge based mostly on direct comparability of the proxy reward. Regardless of the excessive correlation between two figures, we discovered that the reward win charge have to be adjusted in accordance with the KL to be able to align with the GPT-4 win charge.
To instantly assess the standard of generated responses, we additionally carry out Head-to-Head Comparisons between each pair of algorithms within the HH dataset. We use two metrics for analysis: (1) Reward, the optimized goal throughout on-line RL, (2) GPT-4, as a trustworthy proxy for human analysis of response helpfulness. For the latter metric, we level out that earlier research present that GPT-4 judgments correlate strongly with people, with human settlement with GPT-4 sometimes comparable or larger than inter-human annotator settlement.
Determine 5 presents the excellent pairwise comparability outcomes. The common KL-divergence and reward rating of those fashions is DPO > P3O > PPO > SFT. Though DPO marginally surpasses P3O in reward, it has a significantly larger KL-divergence, which can be detrimental to the standard of technology. In consequence, DPO has a reward win charge of 49.5% towards P3O, however solely 45.4% as evaluated by GPT-4. In contrast with different strategies, P3O reveals a GPT-4 win charge of 57.0% towards PPO and 69.3% towards SFT. This result’s in keeping with our findings from the KL-Reward frontier metric, affirming that P3O may higher align with human choice than earlier baselines.
Conclusion
On this weblog submit, we current new insights into aligning giant language fashions with human preferences by way of reinforcement studying. We proposed the Reinforcement Studying with Relative Suggestions framework, as depicted in Determine 1. Below this framework, we develop a novel coverage gradient algorithm – P3O. This strategy unifies the elemental ideas of reward modeling and RL fine-tuning by means of comparative coaching. Our outcomes present that P3O surpasses prior strategies by way of the KL-Reward frontier in addition to GPT-4 win-rate.
BibTex
This weblog is predicated on our current paper and weblog. If this weblog evokes your work, please think about citing it with:
@article{wu2023pairwise,
title={Pairwise Proximal Coverage Optimization: Harnessing Relative Suggestions for LLM Alignment},
writer={Wu, Tianhao and Zhu, Banghua and Zhang, Ruoyu and Wen, Zhaojin and Ramchandran, Kannan and Jiao, Jiantao},
journal={arXiv preprint arXiv:2310.00212},
yr={2023}
}
















{kind=link}