



companion in Enterprise Doc Intelligence, the collection that builds an enterprise RAG system from 4 bricks. It extends Article 5 (doc parsing) on one desk: image_df, which locates each image within the PDF with out studying any of them. This half builds the studying toolbox: a cost-ordered cascade (an affordable filter, a sort test, basic OCR, a imaginative and prescient mannequin) that turns the few photos value paying for into searchable textual content.

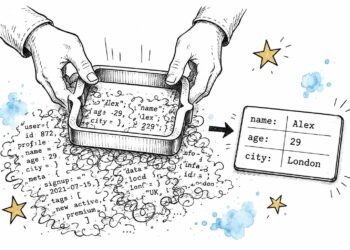
The parsing brick offers you image_df: one row per picture within the PDF, with its web page, its bounding field, its dimension, a content material hash. That locates each image. It doesn’t say what any of them reveals. For retrieval, that’s the identical as not having them: a bounding field isn’t one thing a person can search, and the picture’s textual content slot, the place an outline would reside, is empty.
The reflex is to throw a imaginative and prescient mannequin at each picture and be carried out. That’s the unsuitable default. An actual doc is stuffed with photos that carry nothing a reader would ever seek for: the corporate brand in each web page header, a horizontal rule drawn as a 2-pixel-tall image, a bullet glyph, an ornamental banner. Captioning these with a imaginative and prescient LLM is paying a mannequin to explain a brand 300 instances.
So the job splits in two. First, the strategies that flip a picture into textual content, and what every one prices: an affordable filter, a sort test, basic OCR, a imaginative and prescient mannequin. Second, which photos are literally value spending on in a given run. That second half is pushed by context. A physique line that reads “Determine 3 under reveals…” is the cue to learn that determine with a imaginative and prescient mannequin, and never its neighbours; the query being requested narrows it additional. This text lays down the strategies and reveals what every returns, ordered by value. Selecting which photos to pay for, per doc and per question, is adaptive parsing, and it has its personal article (Article 10). Right here we construct the toolbox.

1. Most photos are usually not value a mannequin name
Step one spends nothing. Earlier than any OCR or imaginative and prescient name, an affordable filter seems at indicators already in image_df plus a few pixel statistics, and drops the photographs with no retrieval worth:
- Too small. A picture whose shortest aspect is a couple of dozen pixels, or whose complete space is under a small flooring, is an icon or a bullet, not a determine. A dimension threshold removes most of them.
- The unsuitable form. An image that could be very lengthy and really skinny is a rule or a divider, not content material. A facet-ratio guard catches these.
- Repeated all over the place. The identical content material hash on most pages of the doc is chrome: a header brand, a footer mark, a watermark. Counting what number of pages a picture hash seems on flags it as ornament, not info.
is_worth_analyzing applies these dimension and form guidelines per picture, and flag_worth_analyzing first derives the per-page repeat frequency from the content material hash, then provides a worth_analyzing column to image_df. Each reside in docintel.parsing.pdf.photos. The thresholds are intentionally unfastened: a false hold prices one mannequin name later, a false drop loses content material with no hint, so when unsure the filter retains the picture. Flat, contentless photos which are too huge to fail the dimensions take a look at (a strong color panel, say) are usually not pressured by right here; they’re caught one step later as ornamental and skipped simply the identical.
In:
image_df(+ per-image pixel stats). Out: the identical desk with aworth_analyzingflag.
On a typical report, this alone removes the big majority of photos earlier than a single mannequin runs. What’s left is the handful that really carry that means.
2. What sort of picture is it?
The pictures that survive the filter are usually not all learn the identical approach. A screenshot of a desk is textual content: basic OCR reads it cheaply and precisely. A line chart isn’t textual content in any respect; its that means is within the axes and the pattern, and solely a imaginative and prescient mannequin can put that into phrases. Sending the chart to OCR returns a couple of stray axis labels; sending the screenshot to a imaginative and prescient mannequin pays chart costs for one thing OCR does at no cost.
So the second step classifies every saved picture into one sort:
ornamental: a clean or near-uniform panel. Skip.textual content: a screenshot, a scanned area, a desk rendered as a picture. Reads with OCR.chart/diagram/picture: the that means is visible. Reads with a imaginative and prescient mannequin.
classify_image returns one ImageType from low cost pixel indicators: how a lot the pixels differ, how saturated they’re, how a lot of the picture is near-white background, how dense its edges are. A near-uniform panel is ornamental. The take a look at there’s value dwelling on, as a result of the plain model is unsuitable: you can not detect a clean panel by counting its colors. An actual “all-black” or “all-white” area isn’t pixel-perfect; sensor noise and JPEG compression give it tons of of near-identical colors, so a color depend sails proper previous it. What stays close to zero on a clean panel, noise and all, is the dispersion of the pixel values, their customary deviation. Low dispersion means clean, regardless of the color depend, so that’s the sign. Black ink on a white web page, near-zero saturation with actual stroke construction, is textual content. A saturated, full-bleed picture with no white margins is a picture. Every thing else, each unsure case, falls by to chart.
Discover what’s not in that record: a step that decides “this seems like a brand”. That’s on function, and it’s the identical lesson because the clean panel. A brand may be two flat colors, a black wordmark on white, or a full-colour gradient with mushy edges. Counting colors catches the primary and misses the second, and worse, the two-colour take a look at additionally catches a bilevel scan of actual textual content you needed to learn. Look doesn’t let you know it’s a brand. Behaviour does: a brand is chrome as a result of it repeats, the identical mark in each web page header. That sign already ran, again within the filter, which drops a picture whose content material hash recurs throughout pages regardless of what number of colors it has. A brand that seems solely as soon as, a mark on a canopy web page, isn’t value a particular case; it will get learn like anything, a wordmark falling to free OCR, a graphic to a single imaginative and prescient name. The rule all through is similar: skip solely what you’re positive is empty or chrome, and browse every thing else, as a result of a unsuitable skip loses content material silently.
That fall-through to chart is the opposite vital design selection. Classifying a chart in opposition to a diagram in opposition to a photograph on low cost indicators alone isn’t dependable, so the classifier doesn’t attempt to be intelligent: it solely diverts a picture to low cost OCR when it’s assured the picture is clear monochrome textual content, and sends every thing else to the imaginative and prescient mannequin, which reads charts, diagrams, photographs, and any textual content they occur to include. The bias is uneven on function. A missed OCR shortcut prices one imaginative and prescient name; OCR run on a diagram returns a handful of stray axis labels and nonsense. So when unsure, the classifier pays for imaginative and prescient. Classification itself stays low cost, no mannequin name, as a result of it needs to be cheaper than the evaluation it’s there to keep away from.
In: a picture that handed the filter. Out: its
ImageType.
3. The cascade: the most affordable technique that may learn it
Sort decides technique. METHOD_BY_TYPE maps every sort to one among three actions, ordered by value, and describe_figure dispatches on it. The entire resolution, for the instances you truly meet in a doc, suits in a single desk: what catches the picture, what it prices, and what you get again.

Learn it high to backside and also you learn the cascade so as. The primary three rows by no means attain a mannequin in any respect: the filter throws them out on dimension, form, or repetition. The subsequent row is caught by the classifier as a clean panel and skipped too. Solely the underside 5 value something, and of these solely the real text-image will get the free path. The remainder attain the imaginative and prescient mannequin, which is strictly the place you need your cash going.
Be careful: sideways figures. A large desk or a panorama chart is usually laid at 90 levels to suit a portrait web page. The flip not often reveals up the place you’ll look first: the web page’s rotation flag stays at 0, and the angle sits within the picture’s personal placement matrix as a substitute. Rendered as-is, the determine reaches OCR or the imaginative and prescient mannequin on its aspect, the place OCR returns noise and a imaginative and prescient mannequin reads it with misplaced confidence and no warning that it struggled. So the cascade reads the position angle and counter-rotates the area earlier than both technique sees it: automated, actual, no orientation-guessing. The one residual case is a scan with the flip baked into its pixels, with no matrix to learn; there the OCR department retries the quarter-turns and retains the best-scoring one.
3.1. Skip: pay nothing for the noise
ornamental: no name. A clean or near-uniform panel retains its empty textual content slot. Along with the photographs the filter already dropped (the too-small, the wrong-shaped, the repeated chrome), that is the place most of a clear doc’s photos find yourself, which is the purpose.
3.2. Traditional OCR for text-images
textual content: a screenshot, a scanned desk, a determine that’s actually rendered textual content. Traditional OCR reads it regionally, in milliseconds, at no cost. The collection makes use of EasyOCR (docintel.parsing.pdf.easyocr); Tesseract is the opposite widespread selection. OCR is actual on clear printed textual content and by no means invents phrases, which is strictly what you need when the picture is textual content. Its companion article (Article 5 quinquies) covers OCR as a parser back-end in full; right here it’s one department of the cascade.
The catch is handwriting. A handwritten notice seems like textual content to the classifier, however basic OCR is skilled on print and reads cursive as a string of guesses. The repair is to let OCR report how positive it’s. EasyOCR returns a confidence rating with each line, so describe_figure reads the textual content and its imply confidence: a assured learn is returned as is, a low-confidence learn is handled as a failed try and the picture falls by to the imaginative and prescient mannequin, which handles handwriting much better. Identical path covers the rarer case the place the classifier mistyped a non-text picture as textual content. So the OCR department isn’t “belief OCR blindly”; it’s “strive the free reader, hold its reply solely when it’s positive, in any other case pay for imaginative and prescient”.
3.3. Imaginative and prescient LLM for charts, diagrams, and photographs
chart, diagram, picture: the one photos the place the that means is genuinely visible. A imaginative and prescient mannequin seems on the image and writes a brief description, “a line chart of commodity costs since 2022, rising then flat after Q3”, “the Transformer structure, an encoder of N stacked layers feeding a decoder”. That sentence is textual content, so retrieval can lastly match it. That is the one factor no textual parser can do, and it’s the costliest step, so the entire cascade exists to ensure solely these photos attain it. The imaginative and prescient name itself goes by docintel.core.analyze_image, the one place each mannequin name within the collection lives (alongside llm_parse and llm_chat); the price it carries is the topic of Article 5quater (imaginative and prescient studying).
The classifier already is aware of the kind, so the immediate is tuned to it as a substitute of 1 generic “describe this picture”. A chart is requested for its axes, items, and pattern; a diagram for its parts and the way they join, with each label transcribed; a desk rendered as a picture is requested for its rows again as markdown; a photograph for what it reveals. The appropriate query pulls the proper reply: ask a chart for its pattern and also you get the pattern, ask it to “describe the picture” and also you get a sentence about colors. A caller can nonetheless go one express immediate to override the type-specific ones, which is how a project-scoped or user-edited instruction flows by.
In: a typed picture. Out: a brief description, or
Nonefor a skip.
4. Writing the outline again
The outline is barely helpful if retrieval can discover it. The picture already has a line slot in line_df (a picture sits at a place on the web page, so it occupies a line, with an empty textual content cell, as coated in Article 5B (the relational information mannequin)). The cascade writes its description into that cell. describe_image_df provides a description column to image_df, and the caller joins it again onto the picture’s line.
The impact is that “the structure diagram” or “the income chart” now retrieves the proper web page, by the identical key phrase and embedding path as another line. Nothing downstream must know the textual content got here from an image.
The enrichment is incremental by design. You’ll be able to run the cascade at parse time for a small corpus, or lazily, solely on the photographs a given run truly wants. The textual content slot is empty till one thing fills it, and filling it by no means adjustments the contract: it’s nonetheless one row, one line, one textual content worth. When to fill it’s the open query this text leaves for adaptive parsing (Article 10): slightly than learn each determine up entrance, a budget textual content is learn first, and a cross-reference in that textual content (“Determine 3 under reveals the beneficial properties”) is what triggers a imaginative and prescient name on the determine it factors to. The strategies listed here are what that coverage will name; the coverage itself is the following article.
The entire cascade ships as one name. Hand it the image_df from parse_pdf and the pdf_path it was parsed from, learn again the identical body with the three new columns the cascade fills.
parsed = parse_pdf("information/paper/1706.03762v7.pdf") # image_df locates the photographs
enriched = describe_image_df(parsed["image_df"], pdf_path="information/paper/1706.03762v7.pdf")
# describe_image_df provides three columns to image_df:
enriched[["page_num", "worth_analyzing", "image_type", "description", "prompt"]].head()
# worth_analyzing : a budget filter's verdict (True/False)
# image_type : "ornamental" | "textual content" | "chart" | "diagram" | "picture" | None
# description : the searchable textual content written into the picture's line slot
# immediate : the instruction despatched to the imaginative and prescient mannequin (None for OCR / skip)That is additionally the a part of the cascade a person can see and proper. The screenshot under is a desktop doc app working the identical pipeline on NIST AI 100-1 (the AI Danger Administration Framework, a US Authorities work, public area): the Pictures tab lists each determine the parser positioned, the chosen diagram carries the outline gpt-4.1 wrote for it, and the outline stays editable. Per-image controls re-run OCR or drive the imaginative and prescient mannequin when a budget path acquired it unsuitable.

5. Price and latency: pay per picture, not per web page
The cascade’s complete function is to make the price monitor the worth. A budget filter and the classifier run on each saved picture however cheaply nothing. OCR is native and free. The imaginative and prescient mannequin, the one line merchandise that really prices cash and seconds, runs solely on charts, diagrams, and photographs, which on most enterprise paperwork are a small fraction of the photographs and a tiny fraction of the pages.
The choice, captioning each picture with a imaginative and prescient mannequin, prices the identical per picture whether or not it’s a brand or a chart, and most photos are logos. The cascade replaces a flat per-image imaginative and prescient invoice with a filter, an affordable classifier, and a imaginative and prescient name solely the place nothing else can learn the image. On a report with one brand per web page and two actual figures, that’s two imaginative and prescient calls as a substitute of dozens.
The identical picture can be by no means paid for twice. The filter already drops chrome that recurs on most pages, however an actual determine can nonetheless seem on a handful of pages (a reference diagram, a repeated exhibit). The cascade keys on the content material hash, so a determine that reveals up on ten pages is learn as soon as and the outline is reused for the opposite 9. One picture, one mannequin name, nevertheless many instances it seems.
6. Conclusion
image_df locates each image; it doesn’t learn any of them. Studying them is a separate brick, and this text lays down its strategies, ordered by value: drop the noise at no cost, classify what’s left cheaply, learn clear textual content with OCR, and hold the imaginative and prescient mannequin for the charts and diagrams the place the that means is genuinely visible. Every technique leaves its end result within the picture’s textual content slot, and from there a picture is simply one other searchable line. What this text intentionally doesn’t settle is which photos to run in a given go: studying each determine up entrance is never what you need, and the context-driven selection, letting the encompassing textual content and the query determine, is adaptive parsing (Article 10). The toolbox first; the coverage subsequent.
Sources and additional studying
- Article 5 (parsing) and Article 5B (the relational tables) introduce
image_dfand the road slot the outline is written again into. - Article 5 quater (imaginative and prescient studying) covers the vision-LLM back-end and its value.
- Article 5 quinquies (EasyOCR) covers basic OCR as a parser back-end.
- Article 10 (adaptive parsing) is the place the selection this text defers will get made: which photos to learn in a given run, escalating from low cost textual content to a imaginative and prescient name solely the place the context asks for it.
Earlier within the collection:
- Doc Intelligence: collection intro. What the collection builds, brick by brick, and in what order.
- Baseline Enterprise RAG, from PDF to highlighted reply. The four-brick pipeline finish to finish: PDF in, highlighted reply out.
- Embeddings Aren’t Magic: The Predictable Failure Modes of RAG Retrieval. The place embedding similarity wins (synonyms, typos, paraphrase), the place it predictably breaks (unknown phrases, negation, term-vs-answer relevance), and find out how to use it anyway.
- Rerankers Aren’t Magic Both: When the Cross-Encoder Layer Is Well worth the Price. What a cross-encoder provides over bi-encoder embeddings, measured, and when it’s definitely worth the latency.
- RAG isn’t machine studying, and the ML toolkit solves the unsuitable drawback. Why chunk-size sweeps and finetuning optimize the unsuitable factor; route by query sort as a substitute.
- From regex to imaginative and prescient fashions: which RAG method suits which drawback. Two axes, doc complexity and query management, that decide the method for every case.
- 10 widespread RAG errors we hold seeing in manufacturing. Ten manufacturing errors, organized brick by brick, with the repair for every.
- Past extract_text: the 2 layers of a PDF that drive RAG high quality. The primary half of the parsing brick: the doc’s nature, indicators, and abstract.
- Cease returning flat textual content from a PDF: the relational form RAG wants. The second half of the parsing brick: the relational tables each downstream brick reads.














{kind=link}