



of birds in flight.
There’s no chief. No central command. Every chicken aligns with its neighbors—matching path, adjusting pace, sustaining coherence by purely native coordination. The result’s international order rising from native consistency.
Now think about one chicken flying with the identical conviction because the others. Its wingbeats are assured. Its pace is appropriate. However its path doesn’t match its neighbors. It’s the pink chicken.
It’s not misplaced. It’s not hesitating. It merely doesn’t belong to the flock.
Hallucinations in LLMs are pink birds.
The issue we’re truly making an attempt to unravel
LLMs generate fluent, assured textual content which will include fabricated data. They devise authorized circumstances that don’t exist. They cite papers that have been by no means written. They state details with the identical tone whether or not these details are true or utterly made up.
The usual method to detecting that is to ask one other language mannequin to verify the output. LLM-as-judge. You possibly can see the issue instantly: we’re utilizing a system that hallucinates to detect hallucinations. It’s like asking somebody who can’t distinguish colours to kind paint samples. They’ll offer you a solution. It’d even be proper generally. However they’re not truly seeing what you want them to see.
The query we requested was totally different: can we detect hallucinations from the geometric construction of the textual content itself, with no need one other language mannequin’s opinion?
What embeddings truly do
Earlier than attending to the detection methodology, I need to step again and set up what we’re working with.
Once you feed textual content right into a sentence encoder, you get again a vector—a degree in high-dimensional area. Texts which are semantically comparable land close to one another. Texts which are unrelated land far aside. That is what contrastive coaching optimizes for. However there’s a extra refined tructure than simply “comparable issues are shut.”
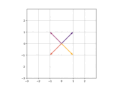
Contemplate what occurs whenever you embed a query and its reply. The query lands someplace on this embeddings area. The reply lands elsewhere. The vector connecting them—what we name the displacement—factors in a selected path. We have now a vector: a magnitude and an angle.
We additionally noticed that for grounded responses inside a selected area, these displacement vectors level in constant instructions. We have now discovered one thing in widespread: angles.
If you happen to ask 5 comparable questions and get 5 grounded solutions, the displacements from query to reply shall be roughly parallel. Not an identical—the magnitudes differ, the precise angles differ barely—however the general path is constant.
When a mannequin hallucinates, one thing totally different occurs. The response nonetheless lands someplace in embedding area. It’s nonetheless fluent. It nonetheless feels like a solution. However the displacement doesn’t comply with the native sample. It factors elsewhere. A vector with a very totally different angle.
The pink chicken is flying confidently. However not with the flock. Flies in the other way with an angle completely totally different from the remainder of the birds.
Displacement Consistency (DC)
We formalize this as Displacement Consistency (DC). The concept is straightforward:
- Construct a reference set of grounded question-answer pairs out of your area
- For a brand new question-answer pair, discover the neighboring questions within the reference set
- Compute the imply displacement path of these neighbors
- Measure how properly the brand new displacement aligns with that imply path
Grounded responses align properly. Hallucinated responses don’t. That’s it. One cosine similarity. No supply paperwork wanted at inference time. No a number of generations. No mannequin internals.
And it really works remarkably properly. Throughout 5 architecturally distinct embedding fashions, throughout a number of hallucination benchmarks together with HaluEval and TruthfulQA, DC achieves near-perfect discrimination. The distributions barely overlap.
The catch: area locality
We examined DC throughout 5 embedding fashions chosen to span architectural variety: MPNet-based contrastive fine-tuning (all-mpnet-base-v2), weakly-supervised pre-training (E5-large-v2), instruction-tuned coaching with laborious negatives (BGE-large-en-v1.5), encoder-decoder adaptation (GTR-T5-large), and environment friendly long-context architectures (nomic-embed-text-v1.5). If DC solely labored with one structure, it may be an artifact of that particular mannequin. Constant outcomes throughout architecturally distinct fashions would recommend the construction is key.
The outcomes have been constant. DC achieved AUROC of 1.0 throughout all 5 fashions on our artificial benchmark. However artificial benchmarks may be deceptive—maybe domain-shuffled responses are just too straightforward to detect.
So we validated on established hallucination datasets: HaluEval-QA, which incorporates LLM-generated hallucinations particularly designed to be refined; HaluEval-Dialogue, with responses that deviate from dialog context; and TruthfulQA, which checks widespread misconceptions that people ceaselessly imagine.
DC maintained good discrimination on all of them. Zero degradation from artificial to practical benchmarks.
For comparability, ratio-based strategies that measure the place responses land relative to queries (slightly than the path they transfer) achieved AUROC round 0.70–0.81. The hole—roughly 0.20 absolute AUROC—is substantial and constant throughout all fashions examined.
The rating distributions inform the story visually. Grounded responses cluster tightly at excessive DC values (round 0.9). Hallucinated responses unfold at decrease values (round 0.3). The distributions barely overlap.
DC achieves good detection inside a slim area. However should you attempt to use a reference set from one area to detect hallucinations in one other area, efficiency drops to random—AUROC round 0.50. That is telling us one thing elementary about how embeddings encode grounding. It’s equal to see totally different flocks within the sky: each flock can have a distinct path.
For LLMs, the best option to perceive that is by the picture of what in geometry is known as a “fiber bundle”.

The floor in Determine 1 is the bottom manifold representing all doable questions. At every level on this floor, there’s a fiber: a line pointing within the path that grounded responses transfer. Inside any native area of the floor (one particular area), all of the fibers level roughly the identical approach. That’s why DC works so properly domestically.
However globally, throughout totally different areas, the fibers level in numerous instructions. The “grounded path” for authorized questions is totally different from the “grounded path” for medical questions. There’s no single international sample. Solely native coherence.
Now take a look at the next video. Birds flight paths connecting Europe and Africa. We are able to see the fiber bundles. Totally different birds (medium/massive small, bugs) have totally different instructions.
In differential geometry, this construction is known as native triviality with out international triviality. Every patch of the manifold seems to be easy and constant internally. However the patches can’t be stitched collectively into one international coordinate system.
This has a noticeable implication:
grounding is just not a common geometric property
There’s no single “truthfulness path” in embedding area. Every area—every sort of activity, every LLM—develops its personal displacement sample throughout coaching. The patterns are actual and detectable, however they’re domain-specific. Birds don’t migrate in the identical path.
What this implies virtually
For deployment, the domain-locality discovering means you want a small calibration set (round 100 examples) matched to your particular use case. A authorized Q&A system wants authorized examples. A medical chatbot wants medical examples. It is a one-time upfront price—the calibration occurs offline—however it will possibly’t be skipped.
For understanding embeddings, the discovering suggests these fashions encode richer construction than we sometimes assume. They’re not simply studying “similarity.” They’re studying domain-specific mappings whose disruption reliably indicators hallucination.
The pink chicken doesn’t d
The hallucinated response has no marker that claims “I’m fabricated.” It’s fluent. It’s assured. It seems to be precisely like a grounded response on each surface-level metric.
But it surely doesn’t transfer with the flock. And now we will measure that.
The geometry has been there all alongside, implicit in how contrastive coaching shapes embedding area. We’re simply studying to learn it.
Notes:
You could find the entire paper at https://cert-framework.com/docs/analysis/dc-paper.
You probably have any questions concerning the mentioned subjects, be happy to contact me at [email protected]














{kind=link}