


, multimodal recommender system just isn’t trivial particularly when it must scale, adapt in close to actual time, and run reliably on cloud.
On this publish, I stroll by way of my expertise designing and deploying such a system finish‑to‑finish overlaying knowledge preparation, mannequin coaching to serving the fashions in manufacturing.
We’ll discover the total pipeline together with retrieval, filtering, scoring, and rating together with the infrastructure and essential choices that makes all of it work. This contains function shops, Bloom‑filters, Kubeflow, close to actual‑time desire adaptation, and a significant latency win from in‑reminiscence function caching.
It’s an extended learn, however for those who’re constructing or scaling recommender programs, you’ll discover sensible patterns right here which you can apply on to your personal tasks.
The principle sections of this publish
- Some details about the system
- Why the present design was chosen
- System parts
- Information supply
- Full Coaching and Deployment pipeline
- Continuous fine-tuning pipeline
- Processing requests by way of the 14 fashions in NVIDIA Triton Inference server
- Bettering merchandise function lookup latency with in-memory caching
- Autoscaling the Triton Inference Server on EKS
- Validating contextual suggestions, Bloom filter filtering, and close to real-time advice updates (with Demo)
- Limitations and Future Work
- Conclusion
- Sources
Some details about the system
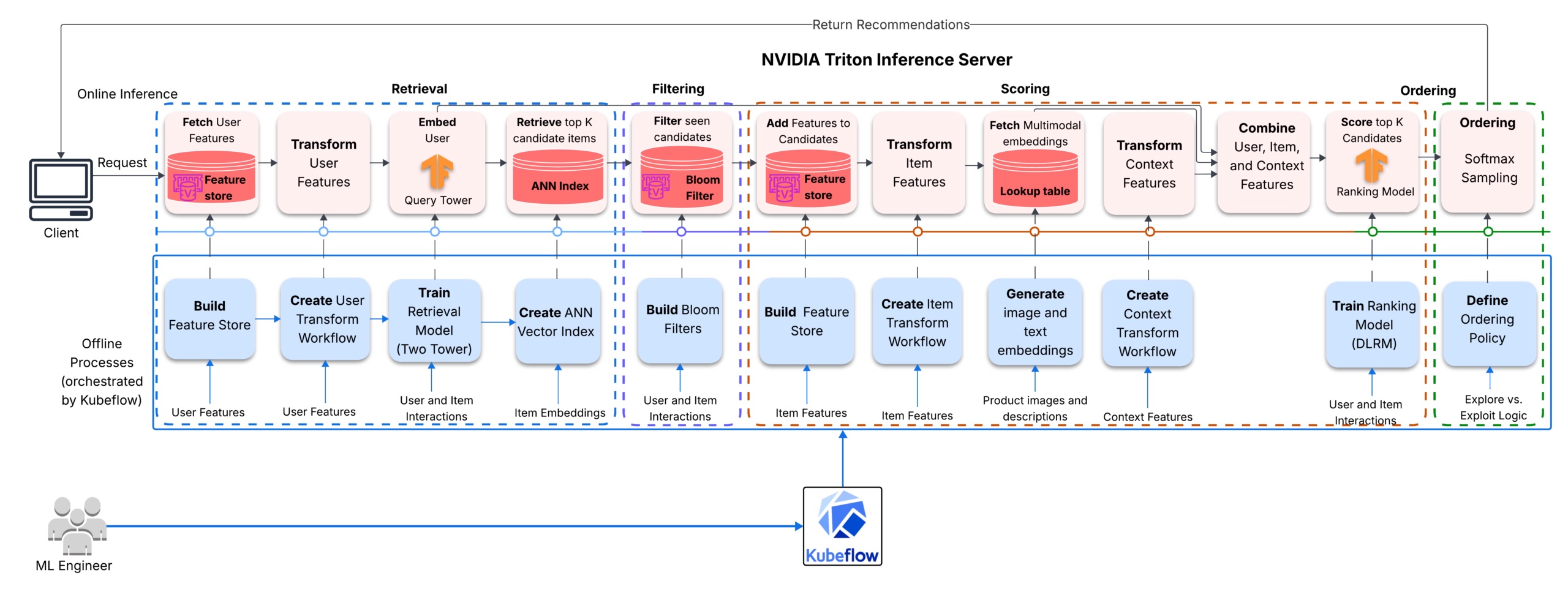
The recommender system consists of 4 most important phases: a Two-Tower mannequin generates candidates, a Bloom filter quickly hides gadgets the person lately interacted with, a DLRM ranker scores the remaining gadgets utilizing person, merchandise, and context options, and a remaining reranking stage orders and samples from these scores to supply the ultimate suggestions. The fashions use each tabular collaborative options and precomputed CLIP picture embeddings and Sentence-BERT textual content embeddings.
Within the retrieval mannequin, these pretrained embeddings are fed into the candidate tower along with discovered merchandise options, offering the candidate tower with each content-based semantic indicators and collaborative indicators. The dot product between the query-tower output and candidate-tower output is then used as a discovered relevance rating on this shared embedding house.
Within the DLRM ranker, the pretrained picture and textual content embeddings take part within the dot-product interplay layer. These pairwise interactions are then handed to the highest MLP, permitting content-based indicators from the pretrained embeddings to enhance the collaborative and contextual indicators used for click on prediction.
Why the present design was chosen
The goal use case is an ecommerce platform that should suggest related merchandise as quickly as customers land on the homepage. The platform serves each registered customers and nameless guests, and person habits can differ considerably with the request context, similar to gadget kind, time of day, or day of week. Meaning the advice service should present cheap cold-start suggestions for brand spanking new customers and should adapt suggestions to the context of the present request.
The answer additionally must scale. As extra retailers are onboarded, the product catalog might develop to thousands and thousands of things. At that time, scoring the total catalog on each request is impractical. A multistage design solves this drawback through the use of a lightweight weight retrieval stage to fetch candidates shortly and a heavier rating stage to attain these candidates.
Additionally, the advice fashions want to remain updated with new interactions, nevertheless rebuilding the total retrieval stack every single day just isn’t sensible. For that reason, two Kubeflow pipelines are outlined. The primary pipeline units up the preprocessing workflows, trains the fashions from scratch, builds the ANN index, and deploys the Triton server and fashions. The second pipeline manages each day finetuning which primarily updates the question tower and the ranker; the fashions are up to date with new interplay indicators however the merchandise embeddings are usually not regenerated.
System parts
All parts of the system work collectively to make sure the general objective of serving related suggestions quick and at cheap scale is achieved.
- Kubeflow Pipelines manages each the total coaching workflow and the each day fine-tuning workflow on the Kubernetes-based system.
- The NVIDIA Merlin stack handles GPU-accelerated function engineering, preprocessing, coaching retrieval and rating fashions. Triton Inference server hosts the multistage serving graph as a single ensemble mannequin.
- FAISS serves because the approximate nearest neighbor index for candidate retrieval.
- Feast manages the person and merchandise options throughout coaching and serving. ElastiCache for Valkey (Redis) backs the web function retailer, manages every person’s Bloom filter to permit filtering of already-seen gadgets from a person’s advice checklist, and shops international and category-based merchandise recognition data primarily based on interplay counts. Amazon Athena (with S3 and Glue) backs the offline function retailer.
- Amazon Elastic Kubernetes Service (EKS) runs the containerized machine studying workflows and scales compute to satisfy altering workload calls for.
Information supply
The coaching knowledge comes from a modified model of the AWS Retail Demo Retailer interplay generator. The person pool was scaled to 300,000 whereas the product catalog was saved at 2,465 gadgets, with the related pictures and descriptions. The dataset comprises 13 million interactions throughout 14 days, saved as each day partitioned parquets (day_00.parquet — day_13.parquet).
Full Coaching and Deployment pipeline
The primary Kubeflow pipeline handles the preliminary knowledge copy, knowledge preprocessing, mannequin coaching, FAISS indexing, and Triton Inference Server deployment.
Information copy
The pipeline begins by copying all of the inputs wanted by downstream duties from S3 bucket to a persistent quantity mounted at an area path. These embody the interplay knowledge, function tables, product pictures, pretrained CLIP and Sentence-BERT fashions.
Preprocessing
The preprocessing step merges interplay knowledge with person and merchandise function tables, then defines and suits three NVTabular workflows, one for the person options [jump to CODE], one for the merchandise options [ jump to CODE] , and one for the context options [jump to CODE]. It additionally compiles the subgraphs right into a full workflow. Splitting the workflows made it simpler to construct separate triton fashions for function transformations which may be independently up to date.
One other preprocessing step simulates cold-start situations (see code snippet under) throughout coaching. In 5% of coaching rows, the person ID, gender, and top_category options are changed with sentinel values, adopted by a separate 5% random masking of gadget kind. Transformation with the NVTabular workflows maps the sentinels to out-of-vocabulary (OOV) index.
#MASK some customers and context options in practice knowledge with 5% likelihood
ANONYMOUS_USER = -1
OOV_GENDER = -1
OOV_TOP_CATEGORY = -1
OOV_DEVICE = -1
masked_train_dir = os.path.be a part of(input_path, "masked_train")
os.makedirs(masked_train_dir, exist_ok=True)
for i in vary(train_days):
day = cudf.read_parquet(os.path.be a part of(input_path, f"train_day_{i:02d}.parquet"))
n=len(day)
user_mask = cupy.random.random(n) < 0.05
day.loc[user_mask, "user_id"] = ANONYMOUS_USER
day.loc[user_mask, "gender"] = OOV_GENDER
day.loc[user_mask, "top_category"] = OOV_TOP_CATEGORY
device_mask = cupy.random.random(n) < 0.05
day.loc[device_mask, "device_type"] = OOV_DEVICE
day.to_parquet(os.path.be a part of(masked_train_dir, f"train_day_{i:02d}.parquet"), index=False)
del day
gc.gather()
masked_train_paths = [os.path.join(masked_train_dir, f"train_day_{i:02d}.parquet") for i in range(train_days)]
masked_train_ds = Dataset(masked_train_paths)
full_workflow.remodel(masked_train_ds).to_parquet(os.path.be a part of(output_path, "practice"))
full_workflow.remodel(valid_raw).to_parquet(os.path.be a part of(output_path, "legitimate"))To acquire the multimodal merchandise options, the product pictures are encoded utilizing OpenAI CLIP and the product descriptions are encoded utilizing Sentence-BERT. Each embeddings are decreased to 64-dimensional vectors by way of PCA and saved as lookup tables keyed by the NVTabular reworked merchandise IDs. The imply age computed by the person workflow is saved for later injection into the feast_user_lookup mannequin config. One other step prepares the offline and on-line function artifacts. This step provides timestamps to the person and merchandise options, writes the ensuing options to the offline retailer, and materializes them into the web retailer for serving. On the similar time, international and category-specific recognition data are computed from the interplay knowledge and written to the Valkey database (db=3).

Coaching the retrieval mannequin
The Two-Tower mannequin [jump to CODE] is educated on person and merchandise options solely, with in-batch negatives and a contrastive loss. The question tower ingests the user-side options whereas the candidate tower consumes the merchandise options along with the precomputed picture and textual content embeddings. See Figures 5 and 6 for details about the NVTabular preprocessing and the enter block processing steps for every tower.
Coaching makes use of the primary 9 days of interplay knowledge; analysis makes use of days 10 by way of 12. After coaching, the candidate encoder is run over the total merchandise catalog to compute merchandise embeddings. For this, a customized LookupEmbeddings operator (primarily based on Merlin’s BaseOperator) handles the multimodal embedding lookup when loading gadgets options in batches with Merlin’s knowledge loader. These merchandise embeddings are used to construct the FAISS index for approximate nearest-neighbor retrieval. The question encoder is saved individually for on-line inference.
Coaching the rating mannequin
The DLRM ranker [jump to CODE] is educated on the identical interplay knowledge however with an expanded function set. The function set contains merchandise options, person options, request-time context options (similar to gadget kind and cyclical time-of-day and day-of-week options). The educational goal is a binary click on label. These context options symbolize situational elements that may form a buyer’s alternative. As an illustration, a person would possibly interact extra with sure gadgets when searching on their telephone versus a desktop, or present totally different preferences relying on the time of day or day of the week.
Mannequin preparation and deployment
As soon as each fashions are educated, the pipeline assembles the serving artifacts wanted by Triton. These embody the saved question tower, the DLRM ranker, the NVTabular remodel fashions, the FAISS index and the lookup tables for the multimodal merchandise embeddings. The Triton mannequin repository is structured forward of time, so every deployment solely wants to repeat the mannequin artifacts into their versioned listing and inject runtime values like the common person age (for cold-start default), the retrieval topK, the rating topK and range mode into the mannequin config information.
A helm chart deploys Triton Inference Server on EKS, begins the server in specific mode after which masses all of the fashions (see the beginning script).
#Triton beginning script
set -e
MODELS_DIR=${1:-"/mannequin/triton_model_repository"}
echo "Beginning Triton Inference Server"
echo "Fashions listing: $MODELS_DIR"
tritonserver
--model-repository="$MODELS_DIR"
--model-control-mode=specific
--load-model=nvt_user_transform
--load-model=nvt_item_transform
--load-model=nvt_context_transform
--load-model=multimodal_embedding_lookup
--load-model=query_tower
--load-model=faiss_retrieval
--load-model=dlrm_ranking
--load-model=item_id_decoder
--load-model=feast_user_lookup
--load-model=feast_item_lookup
--load-model=filter_seen_items
--load-model=softmax_sampling
--load-model=context_preprocessor
--load-model=unroll_features
--load-model=ensemble_modelContinuous fine-tuning pipeline
This Kubeflow pipeline handles each day mannequin updates. The pipeline depends on among the artifacts generated by the total coaching pipeline, due to this fact its parts mount the identical persistent quantity containing the saved artifacts.
Copy incremental knowledge
At first of this run, the pipeline copies the most recent interplay knowledge from Amazon S3 along with a smaller replay set of older interactions. The replay portion provides the fine-tuning job a broader behavioral context and prevents the fashions from overfitting to solely the latest sample.
Preprocess knowledge
This step merges the historic person and merchandise options with the brand new interplay knowledge, then transforms the info utilizing the fitted NVTabular workflows from the current full coaching job.
High-quality-tune fashions
This step updates the question tower and the ranker. It initializes the Two-Tower mannequin from the earlier checkpoint however with the candidate encoder frozen so solely the question tower parameters are trainable. This enables the mannequin to adapt to the current person habits whereas preserving the item-side embeddings utilized by the present ANN index. A abstract of the Two-Tower mannequin exhibiting the frozen layers may be present in right here.
The pipeline additionally initializes the DLRM ranker from the earlier checkpoint however trains all of the parameters utilizing a smaller studying charge and for fewer epochs.
As soon as coaching completes, it saves the fine-tuned question tower and the DLRM ranker to new model folders within the present Triton mannequin repository.
Promote fine-tuned fashions
This step calls Triton to load the brand new fashions. Triton serves in-flight requests on the present mannequin variations whereas loading the brand new fashions within the background. Then it hot-swaps to the most recent mannequin variations as soon as they’re prepared.

Processing requests by way of the 14 fashions in NVIDIA Triton Inference server
The mannequin repository comprises 14 fashions throughout two backends. Python backends for function lookups, function transforms, and filtering; TensorFlow backends for the question tower and the DLRM ranker. An ensemble configuration wires all these fashions right into a directed acyclic graph (DAG) that NVIDIA Triton Inference server executes.
How context and person options are ready
Every request arrives with a person ID and an non-compulsory gadget kind and request timestamp. If any context was lacking, the context_preprocessor imputes the defaults. For instance, the present server time is imputed for a lacking timestamp and an OOV sentinel is imputed for lacking gadget kind. The context workflow transforms the context knowledge into categorified gadget index and 4 temporal options (hour sine/cosine, day-of-week sine/cosine).
Within the person path, feast_user_lookup fetches the person options from the web function retailer (backed by ElastiCache for Valkey), then nvt_user_transform transforms the options utilizing the person workflow earlier than passing them to the question tower (query_tower). The question tower produces the person embeddings which faiss_retrieval makes use of to carry out similarity search, returning the topK merchandise IDs.
Dealing with person cold-start
When a person ID just isn’t discovered within the on-line function retailer, feast_user_lookup makes use of defaults, i.e., user_id = -1, age = the coaching imply, gender = -1, and top_category=-1. The nvt_user_transform maps these user_id, gender, and top_category sentinels to their OOV indices and the imply age to the normalized worth and categorified age bucket. Then the query_tower generates the person embedding from the reworked options. Though faiss_retrieval returns the identical popularity-biased candidates for unknown customers, the DLRM ranker can nonetheless personalize the candidates ordering utilizing obtainable context.
Seen-items filtering with a Bloom Filter
The candidate merchandise IDs are checked towards a Bloom filter in ElastiCache for Valkey. This step can eradicate a major variety of candidates, due to this fact over‑fetching on the retrieval stage is essential because it ensures the ranker receives sufficient candidates to supply a significant advice checklist.
The filtered merchandise IDs enter the merchandise function pipeline the place feast_item_lookup retrieves the merchandise options from the web function retailer, nvt_item_transform transforms these options utilizing the person workflow, and multimodal_embedding_lookup returns the pretrained CLIP (picture) and Sentence BERT (textual content) embeddings for the gadgets.

Rating and ordering
The unroll_features mannequin tiles the person and context options to match the retrieval candidate measurement. Then DLRM ranker (dlrm_ranking) scores the candidates. In softmax_sampling if DIVERSITY_MODE is disabled, the mannequin returns the topK candidates by descending rating; whether it is enabled, the mannequin makes use of score-based weighted sampling with out alternative to pick a various topK whereas nonetheless favoring higher-scoring gadgets. Lastly, item_id_decoder maps the ordered candidate IDs (NVTabular indices) again to the unique merchandise IDs, and Triton returns the chosen merchandise IDs along with their corresponding scores.
Bettering merchandise function lookup latency with in-memory caching
Server Profiling with Triton Efficiency Analyzer at retrieval measurement of 300 revealed that feast_item_lookup consumes 195 ms, which was roughly 52% of whole request latency at concurrency=1. Beneath load, the queue time ballooned from 36 ms (at concurrency=1) to 988 ms (at concurrency=4). This capped throughput at 2.9 inferences per second no matter what number of concurrent requests have been issued.

The bottleneck was feast_item_lookup fetching options for 300 candidates from Feast’s on-line retailer on each request. To alleviate this, Feast requires merchandise options have been changed with an in-process NumPy array cache. Basically, at feast_item_lookup initialization, all merchandise options are fetched as soon as from Feast and saved as NumPy arrays listed by merchandise ID, so each request reads options from reminiscence as a substitute of creating community calls to the web function retailer. This optimization resulted in about 99.7% enchancment within the feast_item_lookup latency, and a 54% enchancment within the end-to-end latency (at concurrency=1). Additionally, the throughput (at concurrency=4) improved by 310%. The one trade-off is that the cached options solely refresh on Triton restart, nevertheless, for a catalog with pretty static merchandise attributes, this isn’t problematic.

After this transformation, the three NVTabular remodel fashions nvt_user_transform (72ms), nvt_item_transform (41ms), and nvt_context_transform (39ms) accounted for about 88% of remaining latency. Additional mannequin optimizations are deferred to a future model of this undertaking.
Autoscaling the Triton Inference Server on EKS
on this undertaking, the Triton Inference Server is autoscaled by way of Kubernetes Horizontal Pod Autoscaler (HPA) primarily based on a customized metric — the common time (in milliseconds) that every request spent ready within the queue during the last 30 seconds. When this latency exceeds the goal, the HPA scales up the Triton deployment by rising the specified pod reproduction rely. If the brand new Triton pod can’t be scheduled as a result of no GPU node has capability for a brand new pod, Karpenter provisions a brand new GPU node and provides it to the cluster. As soon as the node turns into obtainable, the Kubernetes scheduler locations the Triton pod on it. As soon as the brand new pod is prepared, the load balancer can start routing site visitors to it.
Validating contextual suggestions, Bloom filter filtering, and close to real-time advice updates.
To validate the system, range mode was turned off throughout deployment to isolate its impact from these of context varieties, Bloom filter filtering, and desire shift on suggestions.
Validating contextual suggestions
To validate contextual suggestions, I experimented with a number of request varieties, together with requests with solely a person ID and requests that mixed person ID with contextual options similar to gadget kind and timestamp. These exams confirmed that suggestions for unknown customers differ with context. A chilly-start person can obtain totally different ranked merchandise lists relying on the gadget kind and request time. For present customers, the impact of context was much less pronounced. The general rating remained largely secure throughout contexts, though the output scores assorted.
Validating Bloom filter seen-items filtering
To validate seen-item exclusion by the Bloom filter, a number of gadgets from the Beneficial for You carousel have been clicked. These gadgets have been excluded from subsequent suggestions by the Bloom filter. To keep away from shifting the person’s inferred desire and confounding the Bloom filter check, click on gadgets from totally different classes.
Within the video demonstrating the Bloom filter filtering, we observe that clicked gadgets similar to Decadent Chocolate Dream Cake and Classic Explorer’s Canvas Backpack are excluded from Person 12345678‘s subsequent suggestions.
Validating close to real-time advice updates
To validate close to real-time advice updates for present customers, the check begins by first fetching suggestions for a person to ascertain the person’s present desire. That is adopted by clicking a number of gadgets from the identical class, for instance, gadgets belonging to solely Equipment or Furnishings or Groceries, then ready for about 5 seconds for the updates to take impact. The repeated interactions with gadgets in the identical class can shift the person’s inferred desire if that class differs from the person’s present top_category. The top_category function represents the dominant class among the many gadgets a person has interacted inside the previous 24 hours and is recomputed after every interplay. On the following request, the mannequin can rank gadgets from that newly expressed curiosity class greater and floor them among the many prime suggestions.
Within the video demonstrating reside modifications in suggestions, we discover Person 1003‘s prime suggestions change from Equipment to House Decor (and furnishings) on account of repeated interactions with gadgets within the Furnishings class.
Observe, nevertheless, that the top_category function is a crude approximation of short-term curiosity used to exhibit the system’s potential to adapt to person habits in real-time. For richer short-term curiosity modeling, the following iteration of this undertaking would substitute the static question tower with a session-based transformer encoder.
Limitations and Future Work
Within the present structure, request-side context, similar to gadget kind and timestamp-derived options, is used solely by the ranker. This was an implementation option to hold the retrieval easy, since including context at retrieval time would require computing further options throughout candidate technology. Nonetheless, if request context influences which gadgets must be retrieved, related candidates could also be filtered out earlier than the ranker sees them.
A future course is so as to add request-side context options to the question tower, so each retrieval and rating develop into context-aware. One other course is to switch the present question tower with a session encoder, which might extra faithfully seize brief‑time period person behaviour than the present behavioural function approximation (i.e., top_category).
Conclusion
This publish walked by way of a multistage multimodal recommender system for an ecommerce use case, deployed on Amazon EKS. The system combines Two-Tower candidate retrieval, context-aware DLRM rating, and a score-based range rating. The system makes use of tabular person and merchandise options, multimodal embeddings primarily based on product pictures and textual content descriptions, and context data.
Chilly-start is addressed by way of function masking throughout coaching, which forces the fashions to depend on a discovered OOV embedding and context indicators when person is new or unknown. This implies nameless and new customers obtain suggestions that adapt to their gadget kind and the time of their request, slightly than a static fallback checklist. Bloom filters stop already-seen gadgets from resurfacing throughout repeated periods, and in-memory caching of merchandise options helped resolve the latency bottleneck on the merchandise function lookup stage. Additionally, real-time adaptation of the system to altering behavioral sign is demonstrated by way of the top_category function.
On the MLOps aspect, two Kubeflow pipelines handle the system lifecycle. One pipeline for full coaching and deployment, and the opposite for each day fine-tuning of the question tower and ranker with out rebuilding the merchandise embedding index. Karpenter and Kubernetes HPA deal with compute scaling in response to request load.
The system exhibits a production-style recommender programs through which a retrieval stage optimized for velocity and recall is mixed with a rating stage optimized for precision, and an infrastructure layer designed to maintain fashions up to date with out full retraining on each cycle. Please discover the total code on this repository: MustaphaU/multistage-recommender-system-on-kubernetes
I hope you loved studying this! I look ahead to your questions.
Sources
- Mustapha Unubi Momoh, Multistage Multimodal Recommender System on Kubernetes, GitHub repository. Obtainable: https://github.com/MustaphaU/multistage-recommender-system-on-kubernetes
- Even Oldridge and Karl Byleen‑Higley, “Recommender Programs, Not Simply Recommender Fashions,” NVIDIA Merlin (Medium), Apr. 2022. Obtainable: https://medium.com/nvidia-merlin/recommender-systems-not-just-recommender-models-485c161c755e
- Radek Osmulski, “Exploring Manufacturing‑Prepared Recommender Programs with Merlin,” NVIDIA Merlin (Medium), Jul. 2022. Obtainable: https://medium.com/nvidia-merlin/exploring-production-ready-recommender-systems-with-merlin-66bba65d18f2
- Jacopo Tagliabue, Hugo Bowne‑Anderson, Ronay Ak, Gabriel de Souza Moreira, and Sara Rabhi, “NVIDIA Merlin Meets the MLOps Ecosystem: Constructing a Manufacturing‑Prepared RecSys Pipeline on Cloud,” NVIDIA Merlin (Medium), Feb. 2023. Obtainable: https://medium.com/nvidia-merlin/nvidia-merlin-meets-the-mlops-ecosystem-building-a-production-ready-recsys-pipeline-on-cloud-1a16c156166b.
- Benedikt Schifferer, “Fixing the Chilly‑Begin Downside Utilizing Two‑Tower Neural Networks for NVIDIA’s E‑Mail Recommender Programs,” NVIDIA Merlin (Medium), Jan. 2023. Obtainable: https://medium.com/nvidia-merlin/solving-the-cold-start-problem-using-two-tower-neural-networks-for-nvidias-e-mail-recommender-2d5b30a071a4.
- Ziyou “Eugene” Yan, “System Design for Suggestions and Search,” eugeneyan.com, Jun. 2021. Obtainable: https://eugeneyan.com/writing/system-design-for-discovery/.
- Haoran Yuan and Alejandro A. Hernandez, “Person Chilly Begin Downside in Suggestion Programs: A Systematic Overview,” IEEE Entry, vol. 11, pp. 136958–136977, 2023. Obtainable: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10339320
- Justin Wortz and Justin Totten, “Scaling Deep Retrieval with TensorFlow Recommenders and Vertex AI Matching Engine,” Google Cloud Weblog, Apr. 19, 2023. Obtainable: https://cloud.google.com/weblog/merchandise/ai-machine-learning/scaling-deep-retrieval-tensorflow-two-towers-architecture
- Sam Partee, Tyler Hutcherson, and Nathan Stephens, “Offline to On-line: Function Storage for Actual‑time Suggestion Programs with NVIDIA Merlin,” NVIDIA Technical Weblog, Mar. 1, 2023. Obtainable: https://developer.nvidia.com/weblog/offline-to-online-feature-storage-for-real-time-recommendation-systems-with-nvidia-merlin/
















{kind=link}