



{a photograph} of a kitchen in milliseconds. It may well section each object in a road scene, generate photorealistic pictures of rooms that don’t exist, and write convincing descriptions of locations it’s by no means been.
However ask it to stroll into an precise room and let you know which object sits on which shelf, how far the desk is from the wall, or the place the ceiling ends and the window begins in bodily house —
and the phantasm breaks.
The fashions that dominate pc imaginative and prescient benchmarks function in flatland. They purpose about pixels on a 2D grid.
They don’t have any native understanding of the 3D world these pixels depict.
🦚 Florent’s Word: This hole between pixel-level intelligence and spatial understanding isn’t a minor inconvenience. It’s the one largest bottleneck standing between present AI programs and the physical-world functions that matter most: robots that navigate warehouses, autonomous automobiles that plan round obstacles, and digital twins that precisely mirror actual buildings.
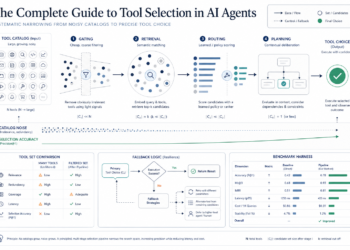
On this article, I break down the three AI layers which might be converging proper now to make spatial understanding potential from odd images.
I present how geometric fusion (the layer no one talks about) turns noisy per-image predictions into coherent 3D scene labels, and I share actual numbers from manufacturing pipelines: a 3.5x label amplification issue that turns 20% protection into 78%.
In the event you work with 3D knowledge, level clouds, or basis fashions, that is the piece of the puzzle you’ve been lacking.

The 3D annotation bottleneck that no one talks about
Reconstructing 3D geometry from images is, at this level, a solved drawback.
Construction-from-Movement pipelines have been matching keypoints and triangulating 3D positions for over twenty years. And the arrival of monocular depth estimation fashions like Depth-Something-3 means now you can generate dense 3D level clouds from a single smartphone video with none specialised {hardware}.
The geometry is there. What’s lacking is which means.
Some extent cloud with 800,000 factors and no labels is a good looking visualization that may’t reply a single sensible query. You possibly can’t ask it “present me solely the partitions” or “measure the floor space of the ground” or “choose all the pieces inside two meters of {the electrical} panel.”
These queries require each level to hold a semantic label, and producing these labels at scale stays brutally costly.
🦥 Geeky Word: The normal strategy depends on LiDAR scanners and groups of annotators who manually click on via tens of millions of factors in specialised software program. A single indoor ground of a business constructing can take a educated operator eight to 12 hours. Multiply that by a complete campus or a fleet of automobiles scanning streets, and the economics collapse.
Educated 3D segmentation networks like PointNet++ and MinkowskiNet can automate the method, however they want labeled coaching knowledge (the identical knowledge that’s costly to provide), and so they are typically domain-specific. A mannequin educated on workplace interiors will fail on development websites.
The zero-shot basis fashions which have reworked 2D pc imaginative and prescient (SAM, Grounded SAM, SEEM) function completely on pictures. They produce 2D masks, not 3D labels.
So the sector sits in a clumsy place the place each the geometric reconstruction and the semantic prediction are individually robust, however no one has a clear, general-purpose method to join them.
The query isn’t whether or not AI can perceive 3D house. It’s the way you bridge the predictions that work in 2D into the geometry that lives in 3D.

So what would it not seem like when you might truly stack these capabilities into one pipeline?
All pictures and animations are made by my very own little fingers, to higher make clear and illustrate the impression of Spatial AI. (c) F. Poux .
Three layers of spatial AI are converging proper now right into a single 3D labeling stack
One thing attention-grabbing occurred between 2023 and 2025. Three impartial analysis threads matured to the purpose the place they are often stacked right into a single pipeline. And the mixture is extra highly effective than any of them alone.

Layer 1: metric depth estimation from a single {photograph}
Fashions like Depth-Something and its successors (DA-V2, DA-3) take a single {photograph} and predict a per-pixel depth map.

The important thing breakthrough isn’t depth prediction itself (that has existed because the early deep studying period). It’s the shift from relative depth to metric depth.
Relative depth tells you that the desk is nearer than the wall, which is helpful for picture enhancing however ineffective for 3D reconstruction. Metric depth tells you the desk is 1.3 meters away and the wall is 4.1 meters away, which suggests you’ll be able to place these surfaces at their appropriate positions in a coordinate system.
Depth-Something-3 produces metric depth at roughly 30 frames per second on a client GPU. That makes it sensible for real-time functions.
Layer 2: basis segmentation from a textual content immediate
The Phase Something Mannequin and its descendants (SAM 2, Grounded SAM, FastSAM) can partition any picture into coherent areas from a single click on, a bounding field, or a textual content immediate.


These fashions are class-agnostic in essentially the most helpful sense: they don’t must have seen your particular object class throughout coaching. You possibly can level at an industrial valve, a surgical instrument, or a kids’s toy, and SAM will produce a pixel-accurate masks.
🌱 Rising Word: When mixed with a text-grounding module, the system goes from “section no matter I click on” to “section all the pieces that appears like a pipe” throughout hundreds of pictures with out human interplay. That’s the place the handbook portray step in right now’s pipelines will get automated tomorrow.
Layer 3: geometric fusion (the engineering no one provides you free of charge)
Right here’s the factor. The third layer is the place the true engineering problem lives: geometric fusion.
Digital camera intrinsics and extrinsics present the mathematical bridge between 2D picture coordinates and 3D world coordinates. If you already know the focal size of the digicam, the place and orientation from which every picture was taken, and the depth at each pixel, you’ll be able to mission any 2D prediction into its actual 3D location.

The back-projection itself is 5 traces of linear algebra:
# Pinhole back-projection: ixel (u,v) with depth d to 3D level
x_cam = (u - cx) * depth / fx y_cam = (v - cy) * depth / fy
z_cam = depth point_world = (np.stack([x_cam, y_cam, z_cam]) - t) @ RLayers one and two are commoditized. You obtain a pretrained mannequin, run inference, and get depth maps or masks which might be adequate for manufacturing use.
Layer three is the half no one provides you free of charge.
That’s as a result of it requires understanding digicam fashions, dealing with noisy depth, resolving conflicts between viewpoints, and propagating sparse predictions into dense protection. It’s the connective tissue that turns per-image AI predictions into coherent 3D understanding, and getting it proper is what separates a analysis demo from a working system.
🪐 System Considering Word: The three-layer stack is a concrete occasion of a common sample in AI programs: notion layers (depth, segmentation) commoditize quickly via basis fashions, whereas integration layers (geometric fusion, temporal consistency) stay engineering-intensive. The aggressive benefit shifts from having higher fashions to having higher integration.

The mathematics for projection is clear. However what occurs when the depth is flawed, the cameras disagree, and also you want labels on 800,000 factors from simply 5 pictures?
How geometric reasoning turns 2D pixels into labeled 3D locations
The central operation within the spatial AI stack is what I name dimensionality bridging: you carry out a process within the dimension the place it’s best, then switch the outcome to the dimension the place it’s wanted.

Truthfully, that is essentially the most underrated idea in the entire pipeline.
People and AI fashions are quick and correct at labeling 2D pictures.
Labeling 3D level clouds is gradual, costly, and error-prone. So that you label in 2D and mission into 3D, utilizing the digicam as your bridge.
🦚 Florent’s Word: I’ve carried out this projection operation in at the very least a dozen manufacturing pipelines, and the mathematics by no means adjustments. What adjustments is the way you deal with the noise. Each digicam, each depth mannequin, each scene kind introduces totally different failure modes. The projection is algebra. The noise dealing with is engineering judgment.

Depth maps from monocular estimation aren’t floor fact. They comprise errors at object boundaries, in reflective surfaces, and in textureless areas. A single back-projected masks will place some labels within the flawed 3D location. And if you mix masks from a number of viewpoints, totally different cameras will disagree about what label belongs at a given level.
That is the place the fusion algorithm earns its preserve.
The four-stage fusion pipeline for 3D label propagation
The fusion pipeline I’ve been refining throughout a number of initiatives follows 4 levels, every addressing a particular failure mode.
The operate signature captures the design philosophy:
def smart_label_fusion( points_3d, # Full scene level cloud (N, 3)
labels_3d, # Sparse labels from multi-view projection
camera_positions, # The place every digicam was in world house
max_distance=0.15, # Ball question radius for label propagation
max_camera_dist=5.0, # Noise gate: ignore factors removed from cameras
min_neighbors=3, # Quorum for democratic voting batch_size=50000 #
Reminiscence-bounded processing chunks )This materializes within the following:

Stage 1: noise gate. Factors that sit removed from any digicam place are doubtless reconstruction artifacts, and any labels they carry are unreliable. By computing the minimal distance from every level to the closest digicam and stripping labels past a threshold, you take away the long-range errors that will in any other case corrupt downstream voting.
Stage 2: spatial index. Relatively than indexing all 800,000 factors, the algorithm constructs a KD-tree utilizing solely the labeled subset. This reduces the tree measurement by 80% or extra, making each subsequent question sooner.
Stage 3: goal identification. Each level nonetheless carrying a zero label after the noise gate turns into a propagation candidate. In a typical five-view session, roughly 20% of the scene receives direct labels. Which means 80% of factors are ready for the voting step.
Stage 4: democratic vote. For every unlabeled level, a ball question collects all labeled neighbors inside radius max_distance. If fewer than min_neighbors labeled factors fall inside vary, the purpose stays unlabeled (abstention prevents low-confidence guesses). In any other case, the commonest label wins.
🦥 Geeky Word: The
min_neighborsparameter is the quorum threshold. Setting it to 1 would let a single noisy label propagate unchecked. Setting it to three means at the very least three impartial labeled factors should agree earlier than a vote counts. In follow, values between 3 and 5 produce the perfect steadiness between protection and accuracy, as a result of depth noise hardly ever locations three inaccurate labels in the identical native neighborhood.
Why does this work so properly? As a result of errors from monocular depth are typically spatially random whereas appropriate labels cluster collectively. Majority voting naturally filters the noise.
🌱 Rising Word: The three parameters to tune:
max_distance=0.05(propagation radius, 5 cm for dense indoor objects, 0.15 for sparse outside).min_neighbors=3(minimal votes, improve to 5-10 for noisy knowledge).batch_size=100000(secure for 16 GB RAM, drop to 50000 underneath reminiscence stress). These three numbers decide the quality-speed-memory tradeoff to your particular scene.
All the course of runs in underneath ten seconds on 800,000 factors with a client CPU. No GPU, no mannequin inference, no coaching. Pure computational geometry.
And that’s exactly why it generalizes throughout each area I’ve examined it on: indoor scenes, outside objects, industrial elements, archaeological artifacts.
4 levels, ten seconds, zero deep studying. However does the output truly maintain up if you take a look at the numbers?
From 20% to 78% label protection: what 3D geometric fusion truly produces
If you mission semantic predictions from 5 out of fifteen images into 3D, roughly 20% of the purpose cloud receives a direct label. The protection is patchy as a result of every digicam sees solely a portion of the scene.

The outcome seems to be like coloured islands in a seaof grey.
After the fusion pipeline runs, protection jumps to roughly 78%. That 3.5x enlargement comes fully from the geometric reasoning within the ball-query voting step.
Let me be particular about what which means:
- No extra human enter is required
- No mannequin inference occurs
- No new data enters the system
- The algorithm merely propagates present labels to close by unlabeled factors utilizing spatial proximity and democratic consensus
The factors that stay unlabeled fall into two informative classes. Some sit in areas that no digicam noticed properly (occluded areas, tight crevices, the underside of overhanging geometry).
Others sit at class boundaries the place the ball question discovered neighbors from a number of courses however none reached the quorum threshold, so the algorithm appropriately abstained fairly than guessing.
Each failure modes let you know precisely the place so as to add one other viewpoint to shut the gaps.
The geometric fusion layer acts as a label amplifier. Any upstream prediction, whether or not it comes from a human, from SAM, or from a future text-prompted mannequin, will get amplified by the identical issue.
That is the perception that makes the entire stack work.
If SAM replaces the handbook portray step, the pipeline turns into absolutely computerized: basis mannequin predictions in 2D, geometric amplification in 3D, no human within the loop. The fusion layer doesn’t care the place the preliminary labels got here from. It solely cares that they’re spatially constant sufficient for the voting step to provide dependable outcomes.

🌱 Rising Word: I ran this similar pipeline on an industrial pipe rack with 4.2 million factors and 32 digicam positions. The fusion step took 47 seconds and expanded protection from 12% to 61%. The decrease ultimate protection displays the geometric complexity (many occluded surfaces), however the amplification issue (5x) was truly increased than the less complicated scene. Denser digicam networks push the ceiling additional.
A 3.5x amplifier that works with any enter supply is highly effective. However there’s one drawback the fusion layer can’t clear up by itself.
The open drawback in spatial AI: multi-view consistency and the place 3D labeling is heading
Basis fashions produce predictions independently for every picture. SAM doesn’t know what it segmented within the earlier body. Depth-Something-3 doesn’t implement consistency throughout viewpoints.
If you mission these per-image predictions into 3D, they generally disagree.
One digicam would possibly label a area as “wall” whereas one other labels overlapping factors as “ceiling,” not as a result of both prediction is flawed in 2D, however as a result of the category boundary seems to be totally different from totally different angles.
The fusion layer partially resolves these disagreements via majority voting. If seven cameras name some extent “wall” and two name it “ceiling,” the purpose will get labeled “wall,” and that’s normally appropriate.
However at real class boundaries (the place the wall meets the ceiling), the voting turns into a coin flip.
🦥 Geeky Word: I’ve seen boundary artifacts spanning 5 to fifteen centimeters in indoor scenes, which is suitable for many functions however problematic for precision duties like as-built BIM modeling. For progress monitoring, facility administration, or spatial analytics, these boundaries are irrelevant. For millimeter-precision development documentation, they matter.
Truly, let me rephrase that. The boundary artifacts aren’t the true drawback. The actual drawback is that no one’s closed the loop between 3D consensus and 2D prediction.
The following frontier is multi-view consistency: making the upstream fashions conscious of one another’s predictions earlier than they attain the fusion layer. SAM 2 takes a step on this course by propagating masks throughout video frames, nevertheless it operates in 2D and doesn’t implement 3D geometric consistency. A system that feeds the 3D fusion outcomes again into the 2D prediction loop (correcting per-image masks primarily based on the rising 3D consensus) would shut the loop fully.
🦚 Florent’s Word: I’m already seeing this convergence play out in actual initiatives. A shopper just lately introduced me a pipeline the place they ran SAM on 200 drone pictures of a development web site, projected the masks via DA3 depth, and used a model of this fusion algorithm to label a 12-million-point cloud. The annotation step that used to take two full days completed in eleven minutes. The boundary artifacts have been there, however for progress monitoring they didn’t matter. They wanted “which ground is poured” and “the place are the rebar cages,” not millimeter-precision edges. That’s spatial AI proper now: it really works, it’s quick, and the remaining imperfections are irrelevant for 80% of actual use circumstances.
What I anticipate to unfold within the subsequent 12 to 18 months
Right here’s my timeline, primarily based on what I’m seeing throughout analysis labs and the trade initiatives I counsel:
| Timeframe | Milestone | Influence |
| Q2 2026 | On-device depth estimation correct sufficient for spatial AI (already delivery on latest iPhones and Pixels) | Seize turns into a easy video recording, no cloud inference wanted |
| Q3 2026 | SAM 3 or equal ships with native multi-view consciousness | Boundary artifacts shrink by an order of magnitude Mid 2026 |
| This autumn 2026 | Actual-time 3D semantic streaming: stroll via a constructing, labeled level cloud builds itself | The geometric fusion layer from this text is precisely what makes that pipeline work |
The bottleneck shifts from producing labels to quality-controlling them, which is a a lot better drawback to have.
🪐 System Considering Word: The methods I exploit right now for validating fusion output (per-class statistics, earlier than/after protection metrics, boundary inspection) change into the diagnostic layer that sits on high of the absolutely automated stack. In the event you perceive the fusion pipeline now, you’ll be the one who debugs and improves it when it runs at scale. That’s the place the true leverage is.

🌱 Rising Word: If you wish to construct the entire pipeline your self (the handbook model that teaches you each element), I’ve revealed a step-by-step tutorial protecting the total Python implementation with interactive portray, back-projection, and fusion. The free toolkit contains all of the code and a pattern dataset.
Assets for going deeper into spatial AI and 3D knowledge science
If you wish to go deeper into the spatial AI stack, listed below are the references that matter.
The 3D Geodata Academy that I created is an educative platform that provides an open-access course on 3D level cloud processing with Python that covers the geometric foundations (coordinate programs, digicam fashions, spatial indexing) intimately. My O’Reilly e-book, 3D Knowledge Science with Python, supplies a complete therapy of the algorithms mentioned right here, together with KD-tree development, ball queries, and label propagation methods.
For the person layers of the stack:
Florent Poux, Ph.D.
Scientific and Course Director on the 3D Geodata Academy. I analysis and educate 3D spatial knowledge processing, level cloud evaluation, and the intersection of geometric computing with machine studying. You possibly can entry my open programs at learngeodata.eu and discover my e-book 3D Knowledge Science with Python on O’Reilly.
Incessantly requested questions on spatial AI and 3D semantic understanding
What’s the distinction between 2D picture segmentation and 3D spatial understanding?
Picture segmentation assigns labels to pixels in a flat {photograph}, whereas 3D semantic understanding assigns labels to factors in a volumetric coordinate system the place distances, surfaces, and spatial relationships are preserved. The hole between them is the digicam geometry that maps pixels to bodily areas, and bridging that hole is what the spatial AI stack described on this article accomplishes.
Can basis fashions like SAM immediately produce 3D labels from images?
Not but. SAM and related fashions function on particular person 2D pictures and don’t have any native understanding of 3D geometry. Their predictions have to be projected into 3D house utilizing digicam intrinsics, extrinsics, and depth data from fashions like Depth-Something-3, then fused throughout a number of viewpoints utilizing spatial algorithms like KD-tree ball queries with majority voting.
How does geometric label fusion scale to giant 3D level clouds?
The fusion algorithm scales linearly with level rely via batched processing that retains peak reminiscence bounded. On a scene with 800,000 factors, the total pipeline runs in underneath ten seconds on a client CPU. On a 4.2-million-point industrial scene, it completes in underneath a minute. The KD-tree spatial index reduces neighbor queries from brute-force O(N) to O(log N) per level.
What’s the 3.5x label amplification consider geometric fusion?
If you mission semantic labels from 5 digicam viewpoints into 3D, roughly 20% of the purpose cloud receives direct labels. The KD-tree ball-query fusion propagates these sparse labels to close by unlabeled factors via majority voting, increasing protection to roughly 78%. The three.5x ratio (78/20) represents how a lot label protection the geometric fusion provides with zero extra enter.
The place can I study extra about 3D knowledge science and the spatial AI stack?
The 3D Geodata Academy presents hands-on programs protecting level clouds, meshes, voxels, and Gaussian splats. For a complete reference, 3D Knowledge Science with Python on O’Reilly covers 18 chapters from fundamentals to manufacturing programs, together with all of the geometric fusion methods mentioned right here.















{kind=link}