


and requested if I may assist extract revision numbers from over 4,700 engineering drawing PDFs. They had been migrating to a brand new asset-management system and wanted each drawing’s present REV worth, a small discipline buried within the title block of every doc. The choice was a staff of engineers opening every PDF one after the other, finding the title block, and manually keying the worth right into a spreadsheet. At two minutes per drawing, that’s roughly 160 person-hours. 4 weeks of an engineer’s time. At absolutely loaded charges of roughly £50 per hour, that’s over £8,000 in labour prices for a process that produces no engineering worth past populating a spreadsheet column.
This was not an AI downside. It was a methods design downside with actual constraints: price range, accuracy necessities, blended file codecs, and a staff that wanted outcomes they might belief. The AI was one element of the answer. The engineering selections round it had been what truly made the system work.
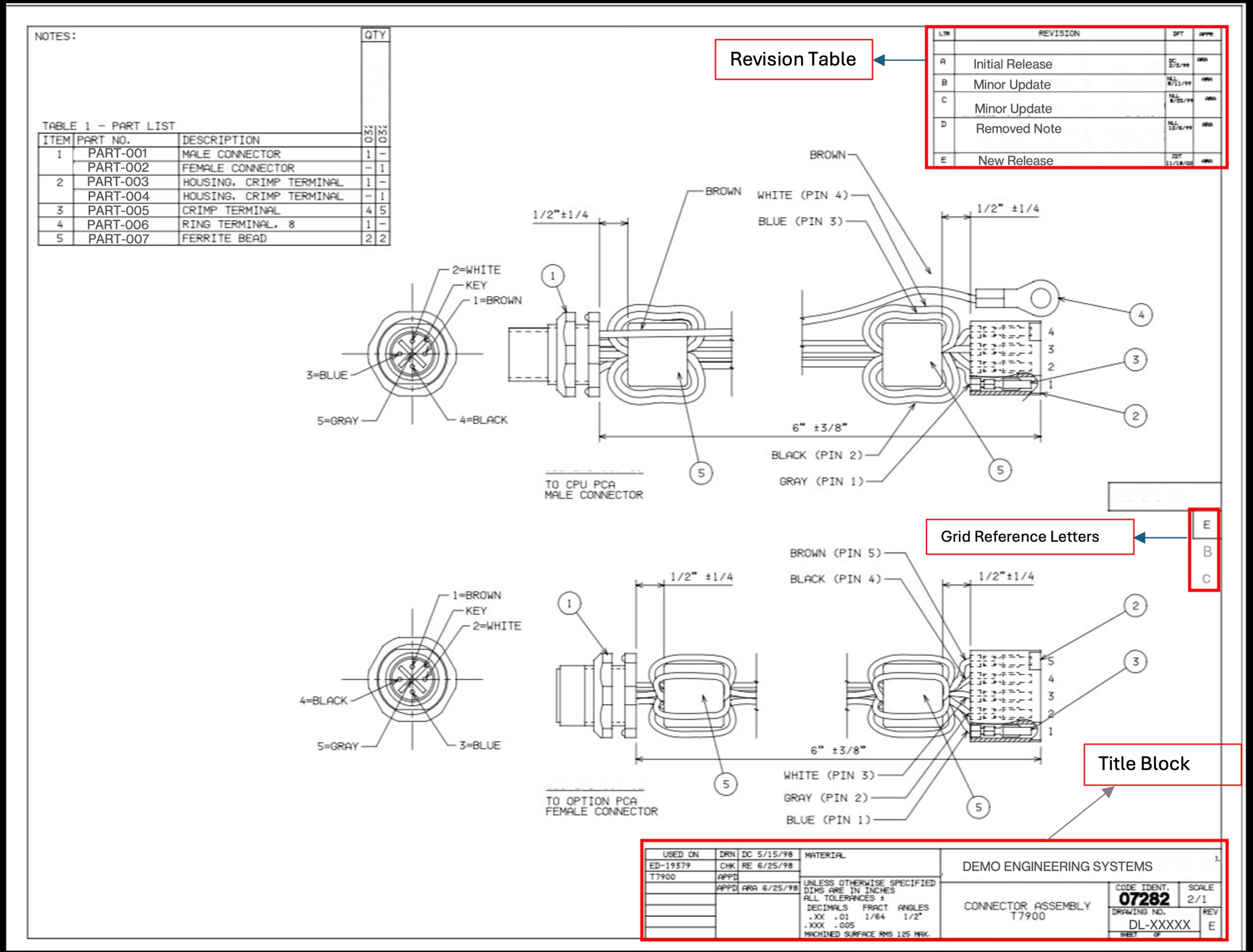
The Hidden Complexity of “Easy” PDFs
Engineering drawings are usually not extraordinary PDFs. Some had been created in CAD software program and exported as text-based PDFs the place you possibly can programmatically extract textual content. Others, significantly legacy drawings from the Nineteen Nineties and early 2000s, had been scanned from paper originals and saved as image-based PDFs. The whole web page is a flat raster picture with no textual content layer in any respect.

Our corpus was roughly 70-80% text-based and 20-30% image-based. However even the text-based subset was treacherous. REV values appeared in no less than 4 codecs: hyphenated numeric variations like 1-0, 2-0, or 5-1; single letters like A, B, C; double letters like AA or AB; and sometimes empty or lacking fields. Some drawings had been rotated 90 or 270 levels. Many had revision historical past tables (multi-row change logs) sitting proper alongside the present REV discipline, which is an apparent false constructive entice. Grid reference letters alongside the drawing border may simply be mistaken for single-letter revisions.
Why a Totally AI Strategy Was the Mistaken Alternative
You would throw each doc at GPT-4 Imaginative and prescient and name it a day, however at roughly $0.01 per picture and 10 seconds per name, that’s $47 and practically 100 minutes of API time. Extra importantly, you’d be paying for costly inference on paperwork the place a number of traces of Python may extract the reply in milliseconds.
The logic was easy: if a doc has extractable textual content and the REV worth follows predictable patterns, there is no such thing as a cause to contain an LLM. Save the mannequin for the instances the place deterministic strategies fail.
The Hybrid Structure That Labored

Stage 1: PyMuPDF extraction (deterministic, zero value). For each PDF, we try rule-based extraction utilizing PyMuPDF. The logic focuses on the bottom-right quadrant of the web page, the place title blocks dwell, and searches for textual content close to identified anchors like “REV”, “DWG NO”, “SHEET”, and “SCALE”. A scoring operate ranks candidates by proximity to those anchors and conformance to identified REV codecs.
def extract_native_pymupdf(pdf_path: Path) -> Non-compulsory[RevResult]:
"""Attempt native PyMuPDF textual content extraction with spatial filtering."""
strive:
finest = process_pdf_native(
pdf_path,
brx=DEFAULT_BR_X, # bottom-right X threshold
bry=DEFAULT_BR_Y, # bottom-right Y threshold
blocklist=DEFAULT_REV_2L_BLOCKLIST,
edge_margin=DEFAULT_EDGE_MARGIN
)
if finest and finest.worth:
worth = _normalize_output_value(finest.worth)
return RevResult(
file=pdf_path.title,
worth=worth,
engine=f"pymupdf_{finest.engine}",
confidence="excessive" if finest.rating > 100 else "medium",
notes=finest.context_snippet
)
return None
besides Exception:
return None
The blocklist filters out frequent false positives: part markers, grid references, web page indicators. Constraining the search to the title block area minimize false matches to close zero.
Stage 2: GPT-4 Imaginative and prescient (for every thing Stage 1 misses). When native extraction comes again empty, both as a result of the PDF is image-based or the textual content format is just too ambiguous, we render the primary web page as a PNG and ship it to GPT-4 Imaginative and prescient by way of Azure OpenAI.
def pdf_to_base64_image(self, pdf_path: Path, page_idx: int = 0,
dpi: int = 150) -> Tuple[str, int, bool]:
"""Convert PDF web page to base64 PNG with good rotation dealing with."""
rotation, should_correct = detect_and_validate_rotation(pdf_path)
with fitz.open(pdf_path) as doc:
web page = doc[page_idx]
pix = web page.get_pixmap(matrix=fitz.Matrix(dpi/72, dpi/72), alpha=False)
if rotation != 0 and should_correct:
img_bytes = correct_rotation(pix, rotation)
return base64.b64encode(img_bytes).decode(), rotation, True
else:
return base64.b64encode(pix.tobytes("png")).decode(), rotation, False
We settled on 150 DPI after testing. Greater resolutions bloated the payload and slowed API calls with out enhancing accuracy. Decrease resolutions misplaced element on marginal scans.
What Broke in Manufacturing
Two lessons of issues solely confirmed up once we ran throughout the total 4,700-document corpus.
Rotation ambiguity. Engineering drawings are continuously saved in panorama orientation, however the PDF metadata encoding that orientation varies wildly. Some information set /Rotate accurately. Others bodily rotate the content material however depart the metadata at zero. We solved this with a heuristic: if PyMuPDF can extract greater than ten textual content blocks from the uncorrected web page, the orientation might be effective no matter what the metadata says. In any other case, we apply the correction earlier than sending to GPT-4 Imaginative and prescient.
Immediate hallucination. The mannequin would generally latch onto values from the immediate’s personal examples as a substitute of studying the precise drawing. If each instance confirmed REV “2-0”, the mannequin developed a bias towards outputting “2-0” even when the drawing clearly confirmed “A” or “3-0”. We mounted this in two methods: we diversified the examples throughout all legitimate codecs with express anti-memorization warnings, and we added clear directions distinguishing the revision historical past desk (multi-row change log) from the present REV discipline (single worth within the title block).
CRITICAL RULES - AVOID THESE:
✗ DO NOT extract from REVISION HISTORY TABLES
(columns: REV | DESCRIPTION | DATE)
- We would like the CURRENT REV from title block (single worth)
✗ DO NOT extract grid reference letters (A, B, C alongside edges)
✗ DO NOT extract part markers ("SECTION C-C", "SECTION B-B")
Outcomes and Commerce-offs
We validated in opposition to a 400-file pattern with manually verified floor fact.
| Metric | Hybrid (PyMuPDF + GPT-4) | GPT-4 Solely |
| Accuracy (n=400) | 96% | 98% |
| Processing time (n=4,730) | ~45 minutes | ~100 minutes |
| API value | ~$10-15 | ~$47 (all information) |
| Human evaluate price | ~5% | ~1% |
The two% accuracy hole was the worth of a 55-minute runtime discount and bounded prices. For an information migration the place engineers would spot-check a share of values anyway, 96% with a 5% flagged-for-review price was acceptable. If the use case had been regulatory compliance, we might have run GPT-4 on each file.
We later benchmarked newer fashions, together with GPT-5+, in opposition to the identical 400-file validation set. Accuracy was akin to GPT-4.1 at 98%. The newer fashions supplied no significant raise for this extraction process, at increased value per name and slower inference. We shipped GPT-4.1. When the duty is spatially constrained sample matching in a well-defined doc area, the ceiling is the immediate and the preprocessing, not the mannequin’s reasoning functionality.
In manufacturing work, the “proper” accuracy goal isn’t at all times the very best one you possibly can hit. It’s the one which balances value, latency, and the downstream workflow that will depend on your output.
From Script to System
The preliminary deliverable was a command-line instrument: feed it a folder of PDFs, get a CSV of outcomes. It ran inside our Microsoft Azure surroundings, utilizing Azure OpenAI endpoints for the GPT-4 Imaginative and prescient calls.
After the preliminary migration succeeded, stakeholders requested if different groups may use it. We wrapped the pipeline in a light-weight inside net software with a file add interface, so non-technical customers may run extractions on demand with out touching a terminal. The system has since been adopted by engineering groups at a number of websites throughout the organisation, every working their very own drawing archives by it for migration and audit duties. I can’t share screenshots for confidentiality causes, however the core extraction logic is an identical to what I’ve described right here.
Classes for Practitioners
Begin with the most cost effective viable technique. The intuition when working with LLMs is to make use of them for every thing. Resist it. Deterministic extraction dealt with 70-80% of our corpus at zero value. The LLM solely added worth as a result of we saved it targeted on the instances the place guidelines fell brief.
Validate at scale, not on cherry-picked samples. The rotation ambiguity, the revision historical past desk confusion, the grid reference false positives. None of those appeared in our preliminary 20-file check set. Your validation set must characterize the precise distribution of edge instances you’ll see in manufacturing.
Immediate engineering is software program engineering. The system immediate went by a number of iterations with structured examples, express detrimental instances, and a self-verification guidelines. Treating it as throwaway textual content as a substitute of a rigorously versioned element is how you find yourself with unpredictable outputs.
Measure what issues to the stakeholder. Engineers didn’t care whether or not the pipeline used PyMuPDF, GPT-4, or provider pigeons. They cared that 4,700 drawings had been processed in 45 minutes as a substitute of 4 weeks, at $50-70 in API calls as a substitute of £8,000+ in engineering time, and that the outcomes had been correct sufficient to proceed with confidence.
The total pipeline is roughly 600 traces of Python. It saved 4 weeks of engineering time, value lower than a staff lunch in API charges, and has since been deployed as a manufacturing instrument throughout a number of websites. We examined the newest fashions. They weren’t higher for this job. Generally the highest-impact AI work isn’t about utilizing probably the most highly effective mannequin accessible. It’s about understanding the place a mannequin belongs within the system, and retaining it there.
Obinna is a Senior AI/Information Engineer primarily based in Leeds, UK, specialising in doc intelligence and manufacturing AI methods. He creates content material round sensible AI engineering at @DataSenseiObi on X and Wisabi Analytics on YouTube.

















{kind=link}