


On this article, you’ll be taught what recursive language fashions are, why they matter for long-input reasoning, and the way they differ from customary long-context prompting, retrieval, and agentic programs.
Subjects we are going to cowl embrace:
- Why lengthy context alone doesn’t remedy reasoning over very giant inputs
- How recursive language fashions use an exterior runtime and recursive sub-calls to course of info
- The primary tradeoffs, limitations, and sensible use instances of this strategy
Let’s get proper to it.
All the things You Must Know About Recursive Language Fashions
Picture by Editor
Introduction
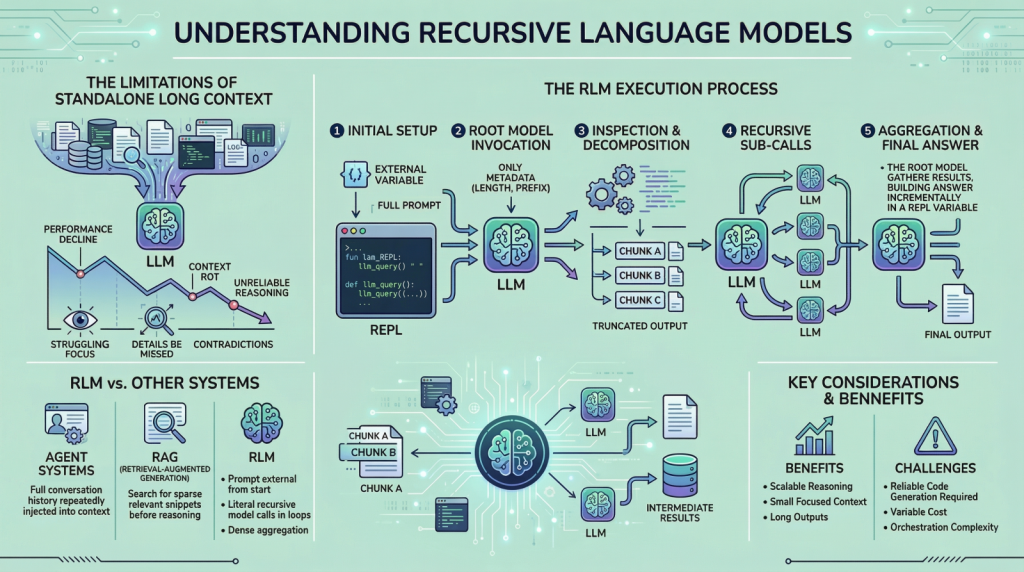
If you’re right here, you’ve gotten in all probability heard about latest work on recursive language fashions. The concept has been trending throughout LinkedIn and X, and it led me to check the subject extra deeply and share what I realized with you. I feel we are able to all agree that enormous language fashions (LLMs) have improved quickly over the previous few years, particularly of their potential to deal with giant inputs. This progress has led many individuals to imagine that lengthy context is essentially a solved drawback, however it isn’t. When you’ve got tried giving fashions very lengthy inputs near, or equal to, their context window, you may need observed that they grow to be much less dependable. They usually miss particulars current within the offered info, contradict earlier statements, or produce shallow solutions as a substitute of doing cautious reasoning. This problem is sometimes called “context rot”, which is kind of an attention-grabbing title.
Recursive language fashions (RLMs) are a response to this drawback. As a substitute of pushing increasingly textual content right into a single ahead move of a language mannequin, RLMs change how the mannequin interacts with lengthy inputs within the first place. On this article, we are going to take a look at what they’re, how they work, and the sorts of issues they’re designed to unravel.
Why Lengthy Context Is Not Sufficient
You may skip this part should you already perceive the motivation from the introduction. However in case you are curious, or if the concept didn’t totally click on the primary time, let me break it down additional.
The best way these LLMs work is pretty easy. All the things we wish the mannequin to think about is given to it as a single immediate, and primarily based on that info, the mannequin generates the output token by token. This works effectively when the immediate is brief. Nonetheless, when it turns into very lengthy, efficiency begins to degrade. This isn’t essentially as a consequence of reminiscence limits. Even when the mannequin can see the whole immediate, it usually fails to make use of it successfully. Listed below are some causes that will contribute to this conduct:
- These LLMs are primarily transformer-based fashions with an consideration mechanism. Because the immediate grows longer, consideration turns into extra diffuse. The mannequin struggles to focus sharply on what issues when it has to take care of tens or a whole bunch of hundreds of tokens.
- Another excuse is the presence of heterogeneous info combined collectively, resembling logs, paperwork, code, chat historical past, and intermediate outputs.
- Lastly, many duties aren’t nearly retrieving or discovering a related snippet in an enormous physique of content material. They usually contain aggregating info throughout your entire enter.
Due to the issues mentioned above, folks proposed concepts resembling summarization and retrieval. These approaches do assist in some instances, however they don’t seem to be common options. Summaries are lossy by design, and retrieval assumes that relevance may be recognized reliably earlier than reasoning begins. Many real-world duties violate these assumptions. Because of this RLMs counsel a special strategy. As a substitute of forcing the mannequin to soak up your entire immediate directly, they let the mannequin actively discover and course of the immediate. Now that now we have the fundamental background, allow us to look extra intently at how this works.
How a Recursive Language Mannequin Works in Observe
In an RLM setup, the immediate is handled as a part of the exterior surroundings. This implies the mannequin doesn’t learn your entire enter instantly. As a substitute, the enter sits exterior the mannequin, usually as a variable, and the mannequin is given solely metadata in regards to the immediate together with directions on the best way to entry it. When the mannequin wants info, it points instructions to look at particular elements of the immediate. This straightforward design retains the mannequin’s inside context small and centered, even when the underlying enter is extraordinarily giant. To grasp RLMs extra concretely, allow us to stroll by way of a typical execution step-by-step.
Step 1: Initializing a Persistent REPL Surroundings
At first of an RLM run, the system initializes a runtime surroundings, usually a Python REPL. This surroundings incorporates:
- A variable holding the complete person immediate, which can be arbitrarily giant
- A perform (for instance,
llm_query(...)orsub_RLM(...)) that enables the system to invoke further language mannequin calls on chosen items of textual content
From the person’s perspective, the interface stays easy, with a textual enter and an output, however internally the REPL acts as scaffolding that permits scalable reasoning.
Step 2: Invoking the Root Mannequin with Immediate Metadata Solely
The basis language mannequin is then invoked, but it surely doesn’t obtain the complete immediate. As a substitute, it’s given:
- Fixed-size metadata in regards to the immediate, resembling its size or a brief prefix
- Directions describing the duty
- Entry directions for interacting with the immediate through the REPL surroundings
By withholding the complete immediate, the system forces the mannequin to work together with the enter deliberately, reasonably than passively absorbing it into the context window. From this level onward, the mannequin interacts with the immediate not directly.
Step 3: Inspecting and Decomposing the Immediate through Code Execution
The mannequin may start by inspecting the construction of the enter. For instance, it could actually print the primary few traces, seek for headings, or cut up the textual content into chunks primarily based on delimiters. These operations are carried out by producing code, which is then executed within the surroundings. The outputs of those operations are truncated earlier than being proven to the mannequin, making certain that the context window isn’t overwhelmed.
Step 4: Issuing Recursive Sub-Calls on Chosen Slices
As soon as the mannequin understands the construction of the immediate, it could actually determine the best way to proceed. If the duty requires semantic understanding of sure sections, the mannequin can problem sub-queries. Every sub-query is a separate language mannequin name on a smaller slice of the immediate. That is the place the “recursive” half truly is available in. The mannequin repeatedly decomposes the issue, processes elements of the enter, and shops intermediate outcomes. These outcomes reside within the surroundings, not within the mannequin’s context.
Step 5: Assembling and Returning the Closing Reply
Lastly, after sufficient info has been gathered and processed, the mannequin constructs the ultimate reply. If the output is lengthy:
- The mannequin incrementally builds it inside a REPL variable, resembling
Closing - As soon as
Closingis about, the RLM loop terminates - The worth of
Closingis returned because the response
This mechanism permits the RLM to supply outputs that exceed the token limits of a single language mannequin name. All through this course of, no single language mannequin name ever must see the complete immediate.
What Makes RLMs Completely different from Brokers and Retrieval Techniques
In the event you spend time within the LLM house, you may confuse this strategy with agentic frameworks or retrieval-augmented technology (RAG). Nonetheless, these are completely different concepts, even when the distinctions can really feel delicate.
In lots of agent programs, the complete dialog historical past or working reminiscence is repeatedly injected into the mannequin’s context. When the context grows too giant, older info is summarized or dropped. RLMs keep away from this sample solely by conserving the immediate exterior from the beginning. Retrieval programs, against this, depend on figuring out a small set of related chunks earlier than reasoning begins. This works effectively when relevance is sparse. RLMs are designed for settings the place relevance is dense and distributed, and the place aggregation throughout many elements of the enter is required. One other key distinction is recursion. In RLMs, recursion isn’t metaphorical. The mannequin actually calls language fashions inside loops generated as code, permitting work to scale with enter measurement in a managed method.
Prices, Tradeoffs, and Limitations
It is usually value highlighting a few of the downsides of this methodology. RLMs don’t eradicate computational value. They shift it. As a substitute of paying for a single very giant mannequin invocation, you pay for a lot of smaller ones, together with the overhead of code execution and orchestration. In lots of instances, the whole value is akin to a normal long-context name, however the variance may be increased. There are additionally sensible challenges. The mannequin should be able to writing dependable code. Poorly constrained fashions could generate too many sub-calls or fail to terminate cleanly. Output protocols should be fastidiously designed to differentiate intermediate steps from closing solutions. These are engineering issues, not conceptual flaws, however they nonetheless matter.
Conclusion and References
A helpful rule of thumb is that this: in case your job turns into more durable just because the enter is longer, and if summarization or retrieval would lose essential info, an RLM is probably going value contemplating. If the enter is brief and the duty is straightforward, a normal language mannequin name will often be quicker and cheaper. If you wish to discover recursive language fashions in additional depth, the next sources are helpful beginning factors:
On this article, you’ll be taught what recursive language fashions are, why they matter for long-input reasoning, and the way they differ from customary long-context prompting, retrieval, and agentic programs.
Subjects we are going to cowl embrace:
- Why lengthy context alone doesn’t remedy reasoning over very giant inputs
- How recursive language fashions use an exterior runtime and recursive sub-calls to course of info
- The primary tradeoffs, limitations, and sensible use instances of this strategy
Let’s get proper to it.
All the things You Must Know About Recursive Language Fashions
Picture by Editor
Introduction
If you’re right here, you’ve gotten in all probability heard about latest work on recursive language fashions. The concept has been trending throughout LinkedIn and X, and it led me to check the subject extra deeply and share what I realized with you. I feel we are able to all agree that enormous language fashions (LLMs) have improved quickly over the previous few years, particularly of their potential to deal with giant inputs. This progress has led many individuals to imagine that lengthy context is essentially a solved drawback, however it isn’t. When you’ve got tried giving fashions very lengthy inputs near, or equal to, their context window, you may need observed that they grow to be much less dependable. They usually miss particulars current within the offered info, contradict earlier statements, or produce shallow solutions as a substitute of doing cautious reasoning. This problem is sometimes called “context rot”, which is kind of an attention-grabbing title.
Recursive language fashions (RLMs) are a response to this drawback. As a substitute of pushing increasingly textual content right into a single ahead move of a language mannequin, RLMs change how the mannequin interacts with lengthy inputs within the first place. On this article, we are going to take a look at what they’re, how they work, and the sorts of issues they’re designed to unravel.
Why Lengthy Context Is Not Sufficient
You may skip this part should you already perceive the motivation from the introduction. However in case you are curious, or if the concept didn’t totally click on the primary time, let me break it down additional.
The best way these LLMs work is pretty easy. All the things we wish the mannequin to think about is given to it as a single immediate, and primarily based on that info, the mannequin generates the output token by token. This works effectively when the immediate is brief. Nonetheless, when it turns into very lengthy, efficiency begins to degrade. This isn’t essentially as a consequence of reminiscence limits. Even when the mannequin can see the whole immediate, it usually fails to make use of it successfully. Listed below are some causes that will contribute to this conduct:
- These LLMs are primarily transformer-based fashions with an consideration mechanism. Because the immediate grows longer, consideration turns into extra diffuse. The mannequin struggles to focus sharply on what issues when it has to take care of tens or a whole bunch of hundreds of tokens.
- Another excuse is the presence of heterogeneous info combined collectively, resembling logs, paperwork, code, chat historical past, and intermediate outputs.
- Lastly, many duties aren’t nearly retrieving or discovering a related snippet in an enormous physique of content material. They usually contain aggregating info throughout your entire enter.
Due to the issues mentioned above, folks proposed concepts resembling summarization and retrieval. These approaches do assist in some instances, however they don’t seem to be common options. Summaries are lossy by design, and retrieval assumes that relevance may be recognized reliably earlier than reasoning begins. Many real-world duties violate these assumptions. Because of this RLMs counsel a special strategy. As a substitute of forcing the mannequin to soak up your entire immediate directly, they let the mannequin actively discover and course of the immediate. Now that now we have the fundamental background, allow us to look extra intently at how this works.
How a Recursive Language Mannequin Works in Observe
In an RLM setup, the immediate is handled as a part of the exterior surroundings. This implies the mannequin doesn’t learn your entire enter instantly. As a substitute, the enter sits exterior the mannequin, usually as a variable, and the mannequin is given solely metadata in regards to the immediate together with directions on the best way to entry it. When the mannequin wants info, it points instructions to look at particular elements of the immediate. This straightforward design retains the mannequin’s inside context small and centered, even when the underlying enter is extraordinarily giant. To grasp RLMs extra concretely, allow us to stroll by way of a typical execution step-by-step.
Step 1: Initializing a Persistent REPL Surroundings
At first of an RLM run, the system initializes a runtime surroundings, usually a Python REPL. This surroundings incorporates:
- A variable holding the complete person immediate, which can be arbitrarily giant
- A perform (for instance,
llm_query(...)orsub_RLM(...)) that enables the system to invoke further language mannequin calls on chosen items of textual content
From the person’s perspective, the interface stays easy, with a textual enter and an output, however internally the REPL acts as scaffolding that permits scalable reasoning.
Step 2: Invoking the Root Mannequin with Immediate Metadata Solely
The basis language mannequin is then invoked, but it surely doesn’t obtain the complete immediate. As a substitute, it’s given:
- Fixed-size metadata in regards to the immediate, resembling its size or a brief prefix
- Directions describing the duty
- Entry directions for interacting with the immediate through the REPL surroundings
By withholding the complete immediate, the system forces the mannequin to work together with the enter deliberately, reasonably than passively absorbing it into the context window. From this level onward, the mannequin interacts with the immediate not directly.
Step 3: Inspecting and Decomposing the Immediate through Code Execution
The mannequin may start by inspecting the construction of the enter. For instance, it could actually print the primary few traces, seek for headings, or cut up the textual content into chunks primarily based on delimiters. These operations are carried out by producing code, which is then executed within the surroundings. The outputs of those operations are truncated earlier than being proven to the mannequin, making certain that the context window isn’t overwhelmed.
Step 4: Issuing Recursive Sub-Calls on Chosen Slices
As soon as the mannequin understands the construction of the immediate, it could actually determine the best way to proceed. If the duty requires semantic understanding of sure sections, the mannequin can problem sub-queries. Every sub-query is a separate language mannequin name on a smaller slice of the immediate. That is the place the “recursive” half truly is available in. The mannequin repeatedly decomposes the issue, processes elements of the enter, and shops intermediate outcomes. These outcomes reside within the surroundings, not within the mannequin’s context.
Step 5: Assembling and Returning the Closing Reply
Lastly, after sufficient info has been gathered and processed, the mannequin constructs the ultimate reply. If the output is lengthy:
- The mannequin incrementally builds it inside a REPL variable, resembling
Closing - As soon as
Closingis about, the RLM loop terminates - The worth of
Closingis returned because the response
This mechanism permits the RLM to supply outputs that exceed the token limits of a single language mannequin name. All through this course of, no single language mannequin name ever must see the complete immediate.
What Makes RLMs Completely different from Brokers and Retrieval Techniques
In the event you spend time within the LLM house, you may confuse this strategy with agentic frameworks or retrieval-augmented technology (RAG). Nonetheless, these are completely different concepts, even when the distinctions can really feel delicate.
In lots of agent programs, the complete dialog historical past or working reminiscence is repeatedly injected into the mannequin’s context. When the context grows too giant, older info is summarized or dropped. RLMs keep away from this sample solely by conserving the immediate exterior from the beginning. Retrieval programs, against this, depend on figuring out a small set of related chunks earlier than reasoning begins. This works effectively when relevance is sparse. RLMs are designed for settings the place relevance is dense and distributed, and the place aggregation throughout many elements of the enter is required. One other key distinction is recursion. In RLMs, recursion isn’t metaphorical. The mannequin actually calls language fashions inside loops generated as code, permitting work to scale with enter measurement in a managed method.
Prices, Tradeoffs, and Limitations
It is usually value highlighting a few of the downsides of this methodology. RLMs don’t eradicate computational value. They shift it. As a substitute of paying for a single very giant mannequin invocation, you pay for a lot of smaller ones, together with the overhead of code execution and orchestration. In lots of instances, the whole value is akin to a normal long-context name, however the variance may be increased. There are additionally sensible challenges. The mannequin should be able to writing dependable code. Poorly constrained fashions could generate too many sub-calls or fail to terminate cleanly. Output protocols should be fastidiously designed to differentiate intermediate steps from closing solutions. These are engineering issues, not conceptual flaws, however they nonetheless matter.
Conclusion and References
A helpful rule of thumb is that this: in case your job turns into more durable just because the enter is longer, and if summarization or retrieval would lose essential info, an RLM is probably going value contemplating. If the enter is brief and the duty is straightforward, a normal language mannequin name will often be quicker and cheaper. If you wish to discover recursive language fashions in additional depth, the next sources are helpful beginning factors:















{kind=link}