


# Tremendous-Tuning Language Fashions on Apple Silicon with MLX
Tremendous-tuning a language mannequin used to imply renting cloud GPUs and watching the meter run. In case you personal a Mac with an Apple Silicon chip, now you can adapt an open mannequin to your personal information domestically, at zero cloud price, utilizing a framework constructed particularly for the {hardware} sitting in your laptop computer.
I made the change from Home windows and Dell machines to Mac again in 2014 and by no means seemed again. What began as curiosity a few cleaner working system changed into a deep appreciation for a way tightly Apple integrates {hardware} and software program. Over a decade later, that integration is paying dividends I by no means anticipated, most not too long ago within the skill to fine-tune language fashions totally on-device, with no cloud invoice or a single byte of knowledge leaving my machine.
That functionality is powered by MLX, an open supply array library from Apple’s machine studying analysis crew, and its companion package deal MLX LM, which supplies textual content technology and fine-tuning for hundreds of open fashions by way of a small set of instructions. This tutorial walks by way of the total course of finish to finish: putting in the instruments, making ready a dataset, coaching a LoRA adapter, shrinking reminiscence use with quantization, then testing and serving the end result. By the top, you will have a fine-tuned mannequin operating by yourself machine and a repeatable workflow you possibly can level at any dataset.
# Understanding Why MLX Fits Apple Silicon
Most native inference instruments began life on NVIDIA {hardware} and have been later ported to the Mac. MLX took the alternative route. Apple’s analysis crew designed it from scratch across the unified reminiscence structure of Apple Silicon, the place the CPU and GPU share a single pool of reminiscence.
That design removes the copy step that often shuttles information between system reminiscence and devoted GPU reminiscence. On a 16 GB Mac, the mannequin weights, optimizer state, and coaching batch all coexist in the identical house, which is precisely what makes on-device fine-tuning sensible relatively than aspirational. The API mirrors NumPy intently, provides computerized differentiation for coaching, and makes use of Steel to speed up GPU work whereas conserving that shared view of reminiscence.
Earlier than you begin, you will want an Apple Silicon Mac (M1 or newer), macOS Ventura 13.5 or later, and Python 3.10 or above. Intel Macs will not be supported. Attempting to put in on one returns a “no matching distribution” error.
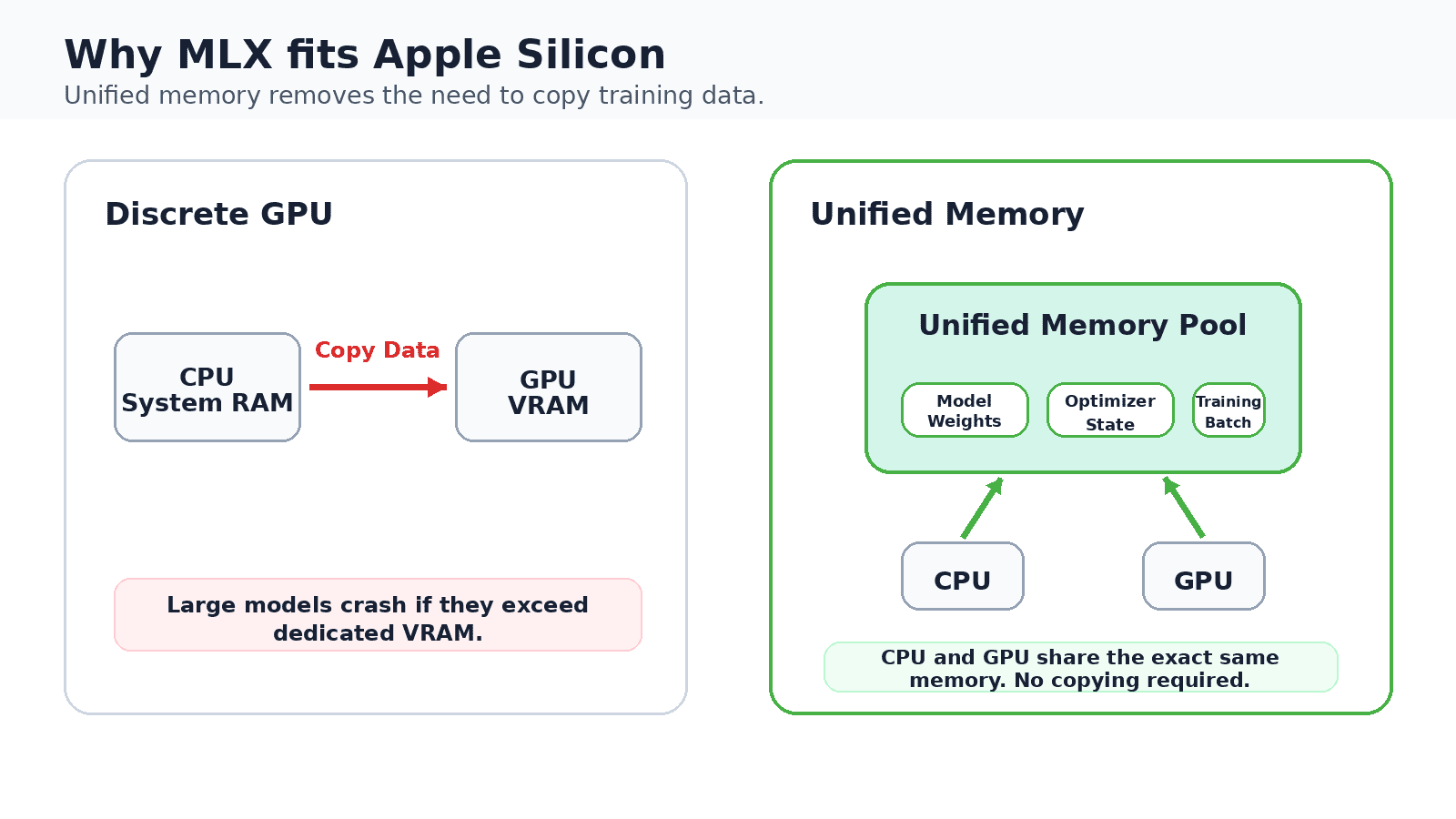
On a discrete GPU, coaching information is copied between system reminiscence and devoted GPU reminiscence. Apple Silicon retains one shared pool, which is what lets a 16 GB Mac fine-tune fashions domestically.
# Setting Up Your Surroundings
With that structure in thoughts, let’s get the instruments put in. Begin with the package deal and its coaching extras, which pull in all the things the fine-tuning instructions want.
pip set up "mlx-lm[train]"
Affirm the set up works with a fast technology take a look at in opposition to a small mannequin.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--prompt "Clarify LoRA in two sentences."
--max-tokens 120
The primary run downloads a 4-bit quantized Mistral mannequin from the MLX Neighborhood group on Hugging Face, caches it domestically, then streams a response. The mlx-community org hosts hundreds of pre-converted fashions, so that you hardly ever must convert weights your self.
One constraint price noting early: MLX fine-tuning requires fashions in Hugging Face safetensors format. GGUF information, frequent in different native instruments, work for inference however not for coaching right here. Supported architectures embody Llama, Mistral, Qwen2, Phi, Gemma, and Mixtral, amongst others, so hottest open fashions can be found out of the field.
# Getting ready Your Dataset
Now that the setting is prepared, the subsequent step is getting your information right into a form the coach can use. MLX LM reads coaching information from a folder containing three information: prepare.jsonl, legitimate.jsonl, and an non-obligatory take a look at.jsonl. Every line holds one JSON instance. The coaching file is required, the validation file lets the coach report validation loss because it runs, and the take a look at file scores the mannequin after coaching finishes.
Three codecs are supported: chat, completions, and textual content. The chat format is probably the most sturdy default. It shops role-tagged messages per line and lets MLX LM apply the mannequin’s personal chat template, so your information matches how the mannequin was skilled to deal with conversations.
{"messages": [{"role": "user", "content": "What is LoRA?"}, {"role": "assistant", "content": "An efficient way to fine-tune a model."}]}
For plain enter and output pairs, the completions format is less complicated and works nicely for instruction-style duties.
{"immediate": "Summarize: The market rose sharply at this time.", "completion": "Markets gained."}
{"immediate": "Translate to French: good morning", "completion": "bonjour"}
By default, the coach computes loss over all the instance, that means the mannequin spends effort studying to breed the immediate in addition to the reply. Passing --mask-prompt tells it to compute loss on the completion alone, so coaching focuses on the response you really care about. This often produces a mannequin that follows directions extra reliably, and it really works with the chat and completions codecs. For chat information, the ultimate message within the listing is handled because the completion.
Preserve every instance on a single line with no inner line breaks, for the reason that reader treats each line as a separate document. Break up your information in order that roughly 80 p.c lands in prepare.jsonl and 10 to twenty p.c in legitimate.jsonl. Round 200 to 500 examples is a wise minimal for altering a mannequin’s conduct (far fewer are likely to overfit and memorize relatively than generalize).
# Coaching Your First LoRA Adapter
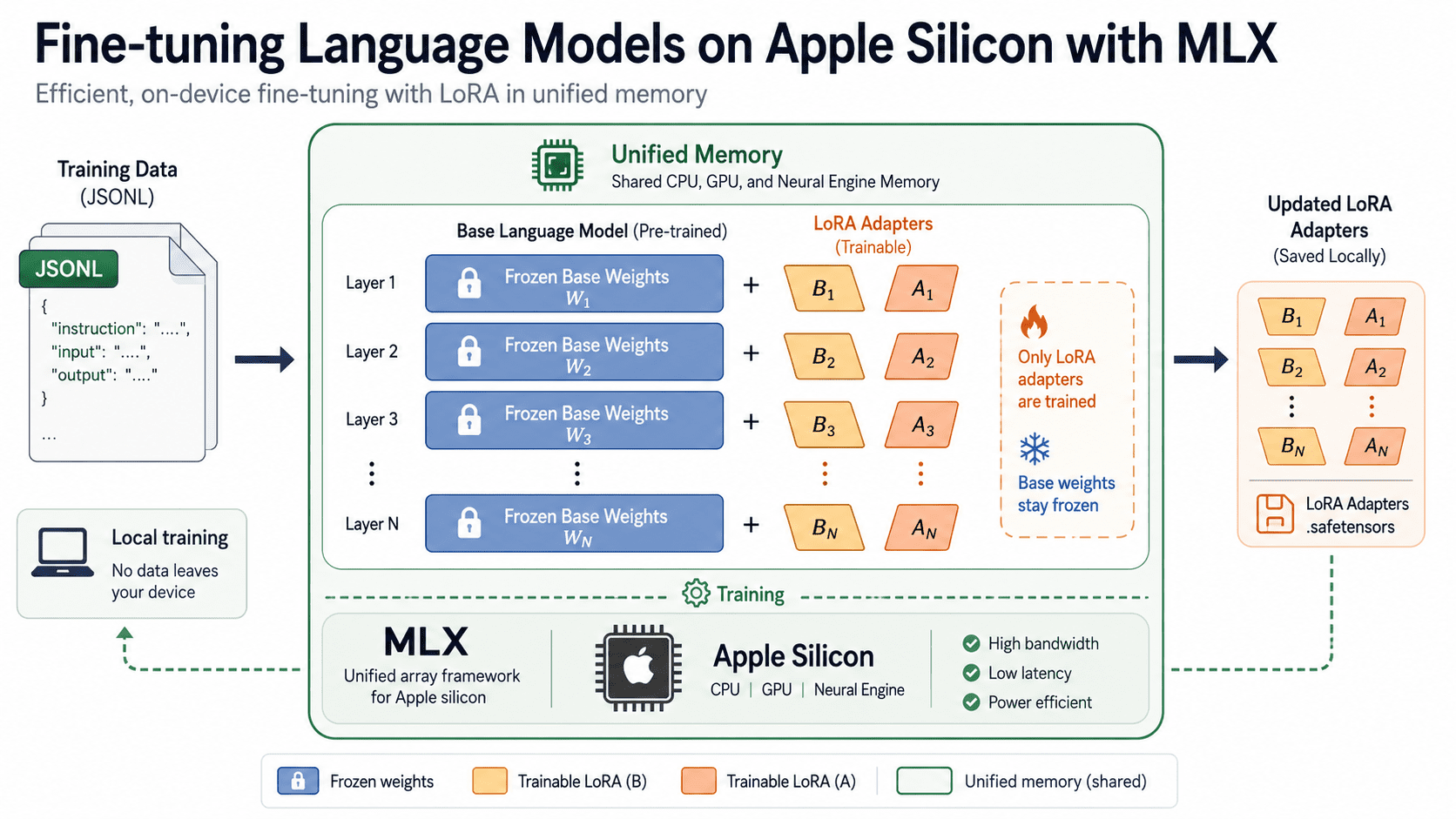
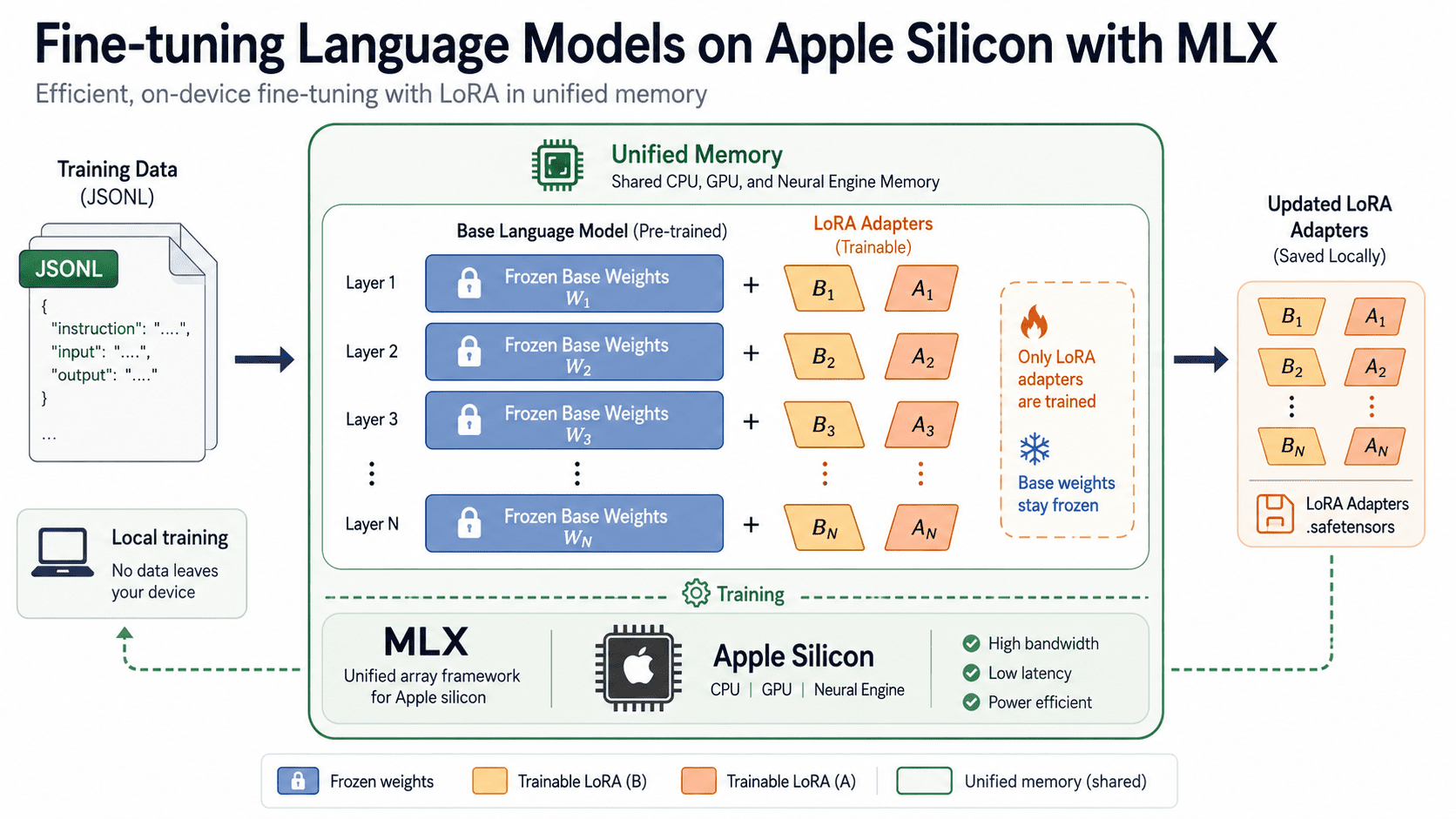
Together with your information in place, here is the place issues get attention-grabbing. Fairly than updating each weight within the mannequin, Low-Rank Adaptation (LoRA) freezes the unique weights and trains small adapter matrices alongside them. This drops reminiscence and storage must a fraction of full fine-tuning whereas conserving a lot of the high quality. The tactic comes from the LoRA paper by Hu and colleagues.

LoRA retains the big pretrained weights frozen and trains solely the small matrices A and B. As a result of simply these two adapters obtain updates, reminiscence and storage keep low.
Launch a coaching run with one command, pointing it at a mannequin and your information folder.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--train
--data ./information
--iters 600
--batch-size 1
Because it runs, MLX LM prints coaching loss, validation loss, tokens processed, and iterations per second. Adapter weights save to an adapters folder by default. Key flags price figuring out: --fine-tune-type accepts lora (the default), dora, or full; --num-layers units what number of transformer layers obtain adapters (default: 16); and --iters controls coaching size.
The instance units --batch-size 1 on goal to maintain reminiscence use as little as attainable. This prevents crashes on 16 GB machines. If in case you have 64 GB or extra, elevating it to 2 or 4 shortens whole coaching time. When reminiscence is tight however you need the smoothing impact of a bigger batch, --grad-accumulation-steps raises the efficient batch dimension with out elevating reminiscence use.
In case you favor dwell graphs over terminal output, add --report-to wandb to log metrics to Weights & Biases. In case you hit reminiscence strain, decrease --num-layers to eight or 4, or add --grad-checkpoint to commerce computation for decrease reminiscence. These two flags are often sufficient to suit a job that will in any other case run out of room.
# Selecting a Base Mannequin and Adapter Settings
Constructing on the coaching mechanics above, two early choices form the remainder of your run: which mannequin to start out from, and the way a lot of it to adapt. For a primary venture, an 8B parameter mannequin in 4-bit type is the candy spot. As soon as the workflow feels comfy, you possibly can transfer as much as 13B or 14B fashions, which want 14 to 18 GB of working reminiscence and sit comfortably on a 32 GB machine.
The variety of skilled layers and the adapter rank collectively management capability. Extra layers and a better rank give the adapter extra room to be taught, at the price of reminiscence and time. A standard place to begin makes use of 16 layers with a reasonable rank, then adjusts based mostly on whether or not validation loss continues to be falling. If coaching loss drops whereas validation loss climbs, the adapter is memorizing your examples.
Studying price issues too. Values within the vary of 1e-5 to 5e-5 work for many LoRA runs. Too excessive and coaching turns into unstable; too low and the mannequin barely strikes. Change one setting at a time so you possibly can attribute any enchancment to a particular selection.
# Decreasing Reminiscence Use with Quantization
Discover that the bottom mannequin above already ends in 4bit. Coaching a LoRA adapter on high of a quantized mannequin is what individuals name QLoRA, described within the QLoRA paper. As a result of quantization is constructed into MLX, the identical mlx_lm.lora command trains adapters instantly on quantized weights with no further setup.
The payoff is concrete. A 4-bit 7B mannequin cuts weight reminiscence by roughly 3.5 instances in contrast with full precision, bringing a 7B fine-tune comfortably into 8 GB of working reminiscence. On a 16 GB MacBook, that leaves ample headroom for the working system and your coaching batch.
In case you favor to quantize a full precision mannequin your self earlier than coaching, the convert command handles it.
mlx_lm.convert
--hf-path mistralai/Mistral-7B-Instruct-v0.3
--mlx-path ./mistral-4bit
-q
This writes a 4-bit model to a neighborhood folder that you just then go to --model.
# Testing and Producing with Your Adapter
With coaching full, it is time to see how nicely the adapter realized. Rating it in opposition to your held-out take a look at set to get a quantity you possibly can monitor throughout experiments.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--data ./information
--test
To see the mannequin reply, go the identical adapter path to the generate command. MLX LM masses the bottom mannequin and applies your adapter on high of it.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--prompt "Summarize: Our quarterly income grew twelve p.c."
Run the identical immediate with out the adapter to match. In case your dataset matched the goal job nicely, the tailored responses ought to monitor your coaching examples extra intently than the bottom mannequin does.
# Fusing and Serving the Mannequin
Adapters are handy throughout experimentation, however for deployment you typically need a single, self-contained mannequin. The fuse command merges the adapter again into the bottom weights.
mlx_lm.fuse
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--save-path ./fused-model
The fused folder behaves like another MLX mannequin. You possibly can serve it by way of an OpenAI-compatible endpoint, which lets current consumer code speak to your native mannequin after solely a base URL change.
mlx_lm.server --model ./fused-model --port 8080
For a graphical different, LM Studio runs MLX fashions with a one-click native server and a chat interface, significantly helpful once you wish to examine your fine-tuned mannequin in opposition to others aspect by aspect.
# Wrapping Up
You now have an entire native fine-tuning workflow: set up MLX LM, format a dataset as JSONL, prepare a LoRA or QLoRA adapter with a single command, take a look at it, then fuse and serve the end result. Every thing runs on the Mac you already personal, with no cloud invoice and no information leaving your machine.
For me, this looks like a pure extension of the journey that started once I switched to Mac in 2014. The tight hardware-software integration that first drew me in has quietly developed into one thing way more highly effective, a machine able to critical machine studying work on the kitchen desk.
Just a few instructions are price exploring subsequent. Strive the dora fine-tune sort and examine its outcomes in opposition to plain LoRA. Modify the variety of skilled layers and iteration rely to stability high quality in opposition to pace. Swap in a unique base structure. Llama, Qwen, Phi, and Gemma all work by way of the identical instructions. Every experiment is cheap when the {hardware} is sitting in your desk, which is the sensible change MLX brings to adapting language fashions.
Vinod Chugani is an AI and information science educator who bridges the hole between rising AI applied sciences and sensible software for working professionals. His focus areas embody agentic AI, machine studying functions, and automation workflows. Via his work as a technical mentor and teacher, Vinod has supported information professionals by way of ability growth and profession transitions. He brings analytical experience from quantitative finance to his hands-on instructing strategy. His content material emphasizes actionable methods and frameworks that professionals can apply instantly.
# Tremendous-Tuning Language Fashions on Apple Silicon with MLX
Tremendous-tuning a language mannequin used to imply renting cloud GPUs and watching the meter run. In case you personal a Mac with an Apple Silicon chip, now you can adapt an open mannequin to your personal information domestically, at zero cloud price, utilizing a framework constructed particularly for the {hardware} sitting in your laptop computer.
I made the change from Home windows and Dell machines to Mac again in 2014 and by no means seemed again. What began as curiosity a few cleaner working system changed into a deep appreciation for a way tightly Apple integrates {hardware} and software program. Over a decade later, that integration is paying dividends I by no means anticipated, most not too long ago within the skill to fine-tune language fashions totally on-device, with no cloud invoice or a single byte of knowledge leaving my machine.
That functionality is powered by MLX, an open supply array library from Apple’s machine studying analysis crew, and its companion package deal MLX LM, which supplies textual content technology and fine-tuning for hundreds of open fashions by way of a small set of instructions. This tutorial walks by way of the total course of finish to finish: putting in the instruments, making ready a dataset, coaching a LoRA adapter, shrinking reminiscence use with quantization, then testing and serving the end result. By the top, you will have a fine-tuned mannequin operating by yourself machine and a repeatable workflow you possibly can level at any dataset.
# Understanding Why MLX Fits Apple Silicon
Most native inference instruments began life on NVIDIA {hardware} and have been later ported to the Mac. MLX took the alternative route. Apple’s analysis crew designed it from scratch across the unified reminiscence structure of Apple Silicon, the place the CPU and GPU share a single pool of reminiscence.
That design removes the copy step that often shuttles information between system reminiscence and devoted GPU reminiscence. On a 16 GB Mac, the mannequin weights, optimizer state, and coaching batch all coexist in the identical house, which is precisely what makes on-device fine-tuning sensible relatively than aspirational. The API mirrors NumPy intently, provides computerized differentiation for coaching, and makes use of Steel to speed up GPU work whereas conserving that shared view of reminiscence.
Earlier than you begin, you will want an Apple Silicon Mac (M1 or newer), macOS Ventura 13.5 or later, and Python 3.10 or above. Intel Macs will not be supported. Attempting to put in on one returns a “no matching distribution” error.
On a discrete GPU, coaching information is copied between system reminiscence and devoted GPU reminiscence. Apple Silicon retains one shared pool, which is what lets a 16 GB Mac fine-tune fashions domestically.
# Setting Up Your Surroundings
With that structure in thoughts, let’s get the instruments put in. Begin with the package deal and its coaching extras, which pull in all the things the fine-tuning instructions want.
pip set up "mlx-lm[train]"
Affirm the set up works with a fast technology take a look at in opposition to a small mannequin.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--prompt "Clarify LoRA in two sentences."
--max-tokens 120
The primary run downloads a 4-bit quantized Mistral mannequin from the MLX Neighborhood group on Hugging Face, caches it domestically, then streams a response. The mlx-community org hosts hundreds of pre-converted fashions, so that you hardly ever must convert weights your self.
One constraint price noting early: MLX fine-tuning requires fashions in Hugging Face safetensors format. GGUF information, frequent in different native instruments, work for inference however not for coaching right here. Supported architectures embody Llama, Mistral, Qwen2, Phi, Gemma, and Mixtral, amongst others, so hottest open fashions can be found out of the field.
# Getting ready Your Dataset
Now that the setting is prepared, the subsequent step is getting your information right into a form the coach can use. MLX LM reads coaching information from a folder containing three information: prepare.jsonl, legitimate.jsonl, and an non-obligatory take a look at.jsonl. Every line holds one JSON instance. The coaching file is required, the validation file lets the coach report validation loss because it runs, and the take a look at file scores the mannequin after coaching finishes.
Three codecs are supported: chat, completions, and textual content. The chat format is probably the most sturdy default. It shops role-tagged messages per line and lets MLX LM apply the mannequin’s personal chat template, so your information matches how the mannequin was skilled to deal with conversations.
{"messages": [{"role": "user", "content": "What is LoRA?"}, {"role": "assistant", "content": "An efficient way to fine-tune a model."}]}
For plain enter and output pairs, the completions format is less complicated and works nicely for instruction-style duties.
{"immediate": "Summarize: The market rose sharply at this time.", "completion": "Markets gained."}
{"immediate": "Translate to French: good morning", "completion": "bonjour"}
By default, the coach computes loss over all the instance, that means the mannequin spends effort studying to breed the immediate in addition to the reply. Passing --mask-prompt tells it to compute loss on the completion alone, so coaching focuses on the response you really care about. This often produces a mannequin that follows directions extra reliably, and it really works with the chat and completions codecs. For chat information, the ultimate message within the listing is handled because the completion.
Preserve every instance on a single line with no inner line breaks, for the reason that reader treats each line as a separate document. Break up your information in order that roughly 80 p.c lands in prepare.jsonl and 10 to twenty p.c in legitimate.jsonl. Round 200 to 500 examples is a wise minimal for altering a mannequin’s conduct (far fewer are likely to overfit and memorize relatively than generalize).
# Coaching Your First LoRA Adapter
Together with your information in place, here is the place issues get attention-grabbing. Fairly than updating each weight within the mannequin, Low-Rank Adaptation (LoRA) freezes the unique weights and trains small adapter matrices alongside them. This drops reminiscence and storage must a fraction of full fine-tuning whereas conserving a lot of the high quality. The tactic comes from the LoRA paper by Hu and colleagues.
LoRA retains the big pretrained weights frozen and trains solely the small matrices A and B. As a result of simply these two adapters obtain updates, reminiscence and storage keep low.
Launch a coaching run with one command, pointing it at a mannequin and your information folder.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--train
--data ./information
--iters 600
--batch-size 1
Because it runs, MLX LM prints coaching loss, validation loss, tokens processed, and iterations per second. Adapter weights save to an adapters folder by default. Key flags price figuring out: --fine-tune-type accepts lora (the default), dora, or full; --num-layers units what number of transformer layers obtain adapters (default: 16); and --iters controls coaching size.
The instance units --batch-size 1 on goal to maintain reminiscence use as little as attainable. This prevents crashes on 16 GB machines. If in case you have 64 GB or extra, elevating it to 2 or 4 shortens whole coaching time. When reminiscence is tight however you need the smoothing impact of a bigger batch, --grad-accumulation-steps raises the efficient batch dimension with out elevating reminiscence use.
In case you favor dwell graphs over terminal output, add --report-to wandb to log metrics to Weights & Biases. In case you hit reminiscence strain, decrease --num-layers to eight or 4, or add --grad-checkpoint to commerce computation for decrease reminiscence. These two flags are often sufficient to suit a job that will in any other case run out of room.
# Selecting a Base Mannequin and Adapter Settings
Constructing on the coaching mechanics above, two early choices form the remainder of your run: which mannequin to start out from, and the way a lot of it to adapt. For a primary venture, an 8B parameter mannequin in 4-bit type is the candy spot. As soon as the workflow feels comfy, you possibly can transfer as much as 13B or 14B fashions, which want 14 to 18 GB of working reminiscence and sit comfortably on a 32 GB machine.
The variety of skilled layers and the adapter rank collectively management capability. Extra layers and a better rank give the adapter extra room to be taught, at the price of reminiscence and time. A standard place to begin makes use of 16 layers with a reasonable rank, then adjusts based mostly on whether or not validation loss continues to be falling. If coaching loss drops whereas validation loss climbs, the adapter is memorizing your examples.
Studying price issues too. Values within the vary of 1e-5 to 5e-5 work for many LoRA runs. Too excessive and coaching turns into unstable; too low and the mannequin barely strikes. Change one setting at a time so you possibly can attribute any enchancment to a particular selection.
# Decreasing Reminiscence Use with Quantization
Discover that the bottom mannequin above already ends in 4bit. Coaching a LoRA adapter on high of a quantized mannequin is what individuals name QLoRA, described within the QLoRA paper. As a result of quantization is constructed into MLX, the identical mlx_lm.lora command trains adapters instantly on quantized weights with no further setup.
The payoff is concrete. A 4-bit 7B mannequin cuts weight reminiscence by roughly 3.5 instances in contrast with full precision, bringing a 7B fine-tune comfortably into 8 GB of working reminiscence. On a 16 GB MacBook, that leaves ample headroom for the working system and your coaching batch.
In case you favor to quantize a full precision mannequin your self earlier than coaching, the convert command handles it.
mlx_lm.convert
--hf-path mistralai/Mistral-7B-Instruct-v0.3
--mlx-path ./mistral-4bit
-q
This writes a 4-bit model to a neighborhood folder that you just then go to --model.
# Testing and Producing with Your Adapter
With coaching full, it is time to see how nicely the adapter realized. Rating it in opposition to your held-out take a look at set to get a quantity you possibly can monitor throughout experiments.
mlx_lm.lora
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--data ./information
--test
To see the mannequin reply, go the identical adapter path to the generate command. MLX LM masses the bottom mannequin and applies your adapter on high of it.
mlx_lm.generate
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--prompt "Summarize: Our quarterly income grew twelve p.c."
Run the identical immediate with out the adapter to match. In case your dataset matched the goal job nicely, the tailored responses ought to monitor your coaching examples extra intently than the bottom mannequin does.
# Fusing and Serving the Mannequin
Adapters are handy throughout experimentation, however for deployment you typically need a single, self-contained mannequin. The fuse command merges the adapter again into the bottom weights.
mlx_lm.fuse
--model mlx-community/Mistral-7B-Instruct-v0.3-4bit
--adapter-path ./adapters
--save-path ./fused-model
The fused folder behaves like another MLX mannequin. You possibly can serve it by way of an OpenAI-compatible endpoint, which lets current consumer code speak to your native mannequin after solely a base URL change.
mlx_lm.server --model ./fused-model --port 8080
For a graphical different, LM Studio runs MLX fashions with a one-click native server and a chat interface, significantly helpful once you wish to examine your fine-tuned mannequin in opposition to others aspect by aspect.
# Wrapping Up
You now have an entire native fine-tuning workflow: set up MLX LM, format a dataset as JSONL, prepare a LoRA or QLoRA adapter with a single command, take a look at it, then fuse and serve the end result. Every thing runs on the Mac you already personal, with no cloud invoice and no information leaving your machine.
For me, this looks like a pure extension of the journey that started once I switched to Mac in 2014. The tight hardware-software integration that first drew me in has quietly developed into one thing way more highly effective, a machine able to critical machine studying work on the kitchen desk.
Just a few instructions are price exploring subsequent. Strive the dora fine-tune sort and examine its outcomes in opposition to plain LoRA. Modify the variety of skilled layers and iteration rely to stability high quality in opposition to pace. Swap in a unique base structure. Llama, Qwen, Phi, and Gemma all work by way of the identical instructions. Every experiment is cheap when the {hardware} is sitting in your desk, which is the sensible change MLX brings to adapting language fashions.
Vinod Chugani is an AI and information science educator who bridges the hole between rising AI applied sciences and sensible software for working professionals. His focus areas embody agentic AI, machine studying functions, and automation workflows. Via his work as a technical mentor and teacher, Vinod has supported information professionals by way of ability growth and profession transitions. He brings analytical experience from quantitative finance to his hands-on instructing strategy. His content material emphasizes actionable methods and frameworks that professionals can apply instantly.
















{kind=link}