


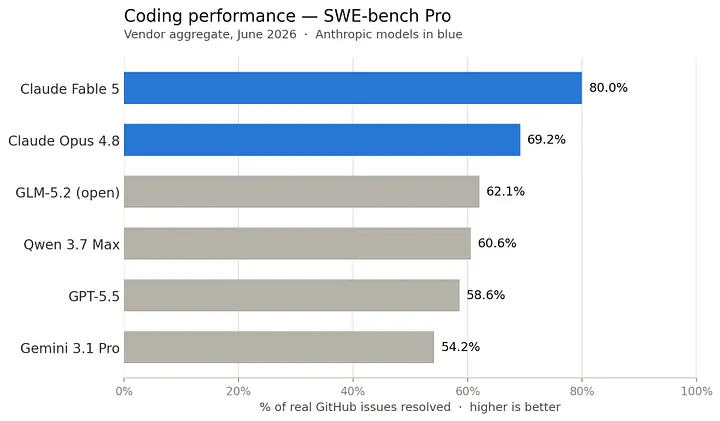
: frontier AI fashions are more and more vulnerable to being locked behind strict export controls or mounting API prices.
As this expertise embeds itself into our each day lives, the open-source motion isn’t only a philosophical choice, it’s a mandatory mechanism to maintain AI within the fingers of on a regular basis customers. We aren’t at parity but; the proprietary fashions from the huge tech labs nonetheless maintain a commanding lead in pure efficiency. However, we will hope that the hole is closing quick. Across the clock, an impartial group of researchers and builders is pushing to make sure this expertise is accessible to anybody with a pc.
At the moment, the inspiration for true democratization is already right here: you may run a extremely succesful mannequin totally by yourself laptop computer. For right this moment’s experiment, I got down to discover a big language mannequin that may run totally on my laptop computer — and use it for the easy duties I’d usually hand off to an enormous lab mannequin.
We’ll set up Qwen 3 8B on my MacBook Air, run it absolutely offline, and eventually have a language mannequin residing alone machine as a substitute of a distant datacenter. The Qwen household of fashions have been skilled by Alibaba (the chinese language firm) and are absolutely open supply, accessible on the web for everybody to obtain. The mannequin has 9 billion weights and takes up round 6gb of your RAM when loaded.
What follows now could be a sensible, start-to-finish information to operating a correct native LLM on an Apple Silicon Mac and it consists of the terminal instructions you want. However earlier than we open the terminal, we have to discuss why that is value doing in any respect.
Why Do This?
More often than not, cloud fashions are higher and simpler. I’m not going to faux an 8-billion parameter mannequin on a laptop computer beats frontier AI. It doesn’t and I’ll maintain utilizing the huge cloud fashions for heavy lifting.
However the fixed pricing and sovereignity wars round AI might make open supply and native fashions very related for a future the place gaining access to the expertise will make an enormous distinction. Each time you employ Claude or ChatGPT, you might be sending your information to some distant servers the place the entry might be blocked at any time.
“Digital sovereignty” is a grand phrase for a really abnormal want: we might wish to personal the factor that reads our most delicate ideas, the identical means you personal a bodily pocket book or maintain some money at house.
An area mannequin solutions that cleanly within the AI world. As soon as it’s downloaded, nothing leaves the machine. No API keys, no shifting phrases of service, no quiet information retention insurance policies. You’ll be able to pull the Wi-Fi card out and it retains working. For the extremely delicate a part of your work, that alone could also be definitely worth the worth of admission.
Individuals like to say native fashions are “democratizing” AI. I would like that to be true, however we aren’t there but. Operating this stack nonetheless assumes you personal a €1,500 laptop computer with large unified reminiscence and also you’re comfy in a command line. That’s a slender, fortunate slice of the world.
However the trajectory is democratizing. Two years in the past, operating a good offline mannequin required a devoted workstation and severe technical ache. This weekend, it took me a few hours and 5 gigabytes of disk house.
So let’s set up the factor.
The Machine and the Specs
I constructed this on a MacBook Air M4 with 24 GB of unified reminiscence and about 235 GB of free storage. This was a contemporary begin: no Homebrew, no Python setting nightmares.
The quantity that really issues right here is the 24 GB. Apple Silicon’s “unified reminiscence” is the magic trick that makes Macs so exceptionally good at this. As a result of the CPU and GPU share the very same reminiscence pool, large neural community weights don’t need to be sluggishly shuttled backwards and forwards.
An 8B mannequin takes up about 5 GB on disk and sits at roughly 6 GB in reminiscence when loaded. On a 24 GB machine, that’s deeply comfy. You may run a 14B mannequin and nonetheless maintain dozens of browser tabs open. (Should you’re on an 8 GB Mac, follow the 1.5B or 3B fashions and shut your different apps).
Why Ollama?
There are a dozen methods to run native AI, and most of them ask you to care about compiler flags and dependency timber. You shouldn’t need to.
Ollama is an open supply framework and power that simply works. It’s a single binary that bundles a extremely optimized mannequin runner (llama.cpp utilizing Apple’s Metallic for GPU acceleration), a Docker-style mannequin registry, and an area HTTP API. You put in it, you pull a mannequin, and also you discuss to it. That’s it!
Step 1: Set up Ollama (No Homebrew Required)
Ollama ships as a regular macOS app in a zipper file. The command-line interface (CLI) lives secretly contained in the app bundle, so we will set it up totally by hand.
# Obtain the Apple Silicon construct
cd ~/Downloads
curl -L -o Ollama-darwin.zip https://ollama.com/obtain/Ollama-darwin.zip
# Unzip and transfer the app into your Purposes folder
unzip -o -q Ollama-darwin.zip
mv Ollama.app /Purposes/Should you don’t know the best way to open the terminal, simply go to your Mac purposes and seek for “terminal”:
Step 2: Put Ollama on Your PATH
I didn’t wish to battle with sudo permissions in /usr/native/bin, so I symlinked the bundled CLI into an area listing I personal — that is only a helpful shortcut to hurry up the set up and spin up the LLM.
# Create an area bin listing and symlink the CLI
mkdir -p ~/.native/bin
ln -sf /Purposes/Ollama.app/Contents/Assets/ollama ~/.native/bin/ollama
# Make it everlasting in your zsh profile
echo 'export PATH="$HOME/.native/bin:$PATH"' >> ~/.zshrc
# Apply it to your present shell
export PATH="$HOME/.native/bin:$PATH"
ollama --versionStep 3: Begin the Server
Ollama runs a light-weight background server to reveal the API and handle your pc’s reminiscence.
# Begin the server and log output
mkdir -p ~/.ollama/logs
nohup ollama serve > ~/.ollama/logs/serve.log 2>&1 &
# Ping it to verify if it is alive
curl -s http://127.0.0.1:11434/api/modelIf the command above returns a “model”, ollama is about up!

Notice: You can even simply double-click the Ollama app in your Purposes folder to run this server by way of your menu bar. I did it by way of terminal to see precisely what was taking place below the hood.
Step 4: Pull the Mannequin
Properly this one is as simple because it will get:
ollama pull qwen3:8b
ollama recordGo make a espresso. The obtain is about 5.2 GB.
After operating ollama record, you’ll see the mannequin accessible for you:

Step 5: Speak to the brand new digital Mind in your Pc
You have got three distinct methods to work together together with your new native mannequin.
1. Interactive Chat (The Best)
ollama run qwen3:8bOperating the next command will launch the interactive chat:

Within the default mode, the mannequin will spill out the “considering tokens”, one thing that’s usually abstracted and hidden in most business instruments.
I’m going to begin by asking my native mannequin what it thinks about open supply fashions:

The sunshine gray textual content represents the mannequin’s inside reasoning course of. These fashions carry out intensive calculation earlier than producing a response, and for native fashions, this considering section accounts for a good portion of the full time till the mannequin spews out a response.
After doing the considering course of, right here is the reply from the mannequin:

Was with most instruments, these fashions additionally retain some context from earlier interactions:

The mannequin is outputting 5.7 tokens per second as a result of I’m in battery saving mode. If I flip it down, we are going to in all probability see a worth of 15–20 tokens per second.
2. One-Shot Terminal Instructions
To work together together with your native mannequin, it’s also possible to present the query exterior of the interactive mode:
ollama run qwen3:8b "write a python script that tells me what number of vowels a phrase has"Right here’s the script that our native massive language mannequin constructed:
```python
# Immediate the person for a phrase
phrase = enter("Enter a phrase: ")
# Outline the set of vowels
vowels = {'a', 'e', 'i', 'o', 'u'}
# Initialize a counter
rely = 0
# Convert the phrase to lowercase and verify every character
for char in phrase.decrease():
if char in vowels:
rely += 1
# Output the outcome
print(f"Variety of vowels: {rely}")3. The HTTP API (For Scripts and Apps)
Are you able to solely use this inside the terminal instructions?
In fact not! In case you are comfy with Python, you may construct any native script utilizing your native mannequin:
import json, urllib.request
req = urllib.request.Request(
"http://127.0.0.1:11434/api/generate",
information=json.dumps({
"mannequin": "qwen3:8b",
"immediate": "Give me three makes use of for an area LLM.",
"stream": False,
"suppose": False,
}).encode(),
headers={"Content material-Sort": "software/json"},
)
print(json.hundreds(urllib.request.urlopen(req).learn())["response"])Right here is the reply from the mannequin after operating this Python script:
Positive! Listed here are three widespread and sensible makes use of for a **native LLM (Giant Language Mannequin)**:
1. **Personalised Help and Productiveness**
An area LLM can act as a personal AI assistant, serving to with duties like e mail drafting, scheduling, note-taking, and even coding. Because it runs domestically, it maintains person privateness and does not depend on web connectivity.
2. **Content material Creation and Language Processing**
You should utilize an area LLM to generate artistic content material reminiscent of weblog posts, tales, scripts, or advertising and marketing copy. It may well additionally help with language translation, grammar checking, and summarizing textual content.
3. **Customized Purposes and Integration**
An area LLM might be built-in into customized purposes or workflows, reminiscent of chatbots, buyer assist methods, or information evaluation instruments. This enables for tailor-made options with out exposing delicate information to exterior servers.
Let me know if you would like examples of the best way to implement these makes use of!Cool! Now you can create your individual purposes with your individual native mannequin fairly simply.
Superb-Tuning the Expertise — Taming the “Considering” Tokens
Qwen 3 is a hybrid reasoning mannequin. By default, it generates a verbose
Right here is the way you bypass the reasoning go:
- Disable it totally:
ollama run qwen3:8b --think=false - Run it, however conceal it from the UI:
ollama run qwen3:8b --hidethinking - In scripts: Cross
"suppose": falsein your JSON payload.
A Warning About Internet Search
Fashions are static up till their coaching information. That signifies that they’ll’t entry information after they had been skilled, and firms have been counting on internet search instruments to reinforce the aptitude of the fashions. For instance for our native mannequin:

However, Ollama lets you hand the mannequin a web-search device. This sounds unbelievable however there’s a catch.
The search itself executes on Ollama’s hosted cloud service. The second you allow it, your prompts are being despatched over the web to fetch search outcomes. The mannequin stays native, however your queries don’t. This will violate the precept of privateness you wish to assure with the setup.
Bonus: VS Code Integration
The last word endgame for me was getting an offline coding assistant. The cleanest, totally free path for that is the Proceed.dev extension.
- Set up VS Code and the Proceed extension.
- Open Proceed’s configuration file at
~/.proceed/config.yaml. - Level it at your native Ollama server:
identify: Native Assistant
model: 1.0.0
fashions:
- identify: Qwen3 8B (native)
supplier: ollama
mannequin: qwen3:8b
roles:
- chat
- edit
- apply
- identify: Qwen3 8B Autocomplete
supplier: ollama
mannequin: qwen3:8b
roles:
- autocompleteProfessional-tip: An 8B mannequin is barely too heavy for the split-second latency you need for inline code autocomplete. I extremely suggest pulling a smaller mannequin particularly for that activity (ollama pull qwen2.5-coder:1.5b-base), mapping it to the autocomplete function, and letting Qwen3 8B deal with the heavier chat duties.
What if I’ve a Home windows Pc?
As I’m not on a home windows for this tutorial, I haven’t tried it extensively. However the excellent news is that the Ollama bundle is obtainable for Home windows computer systems right here.
The set up course of might differ a bit, however the logic behind utilizing Ollama and pulling the fashions shall be precisely the identical.
The place This Leaves Me
My complete footprint for this challenge was 156 MB for the software program and 5.2 GB for the mannequin itself.
I now have a extremely succesful language mannequin residing completely on my arduous drive. For public, advanced work, I’ll nonetheless attain for the cloud. However for the drafts I don’t need ingested into coaching information, the offline flights, and the legally certain consumer paperwork? This intelligence is now on my pc.
This can be a bit too techy for most individuals nonetheless, however issues have gotten extra democratized. And it’s not nearly availability. On the efficiency entrance, open-source fashions are bettering at a staggering tempo, delivering outcomes that make the way forward for native AI look extremely promising. For instance, GLM 5.2 and Qwen 3.7 Max are catching as much as the massive labs’ fashions efficiency:

Because the technical ground retains dropping, “proudly owning your individual AI” goes to cease being a luxurious reserved for builders with costly laptops. That’s the model of AI democratization I really imagine in.
Go give your laptop computer one other mind this weekend and lengthy reside open supply!

















{kind=link}