



article. Two conditions.
Scene 1. A staff constructing a RAG system over just a few hundred contracts has learn Article 2. Embeddings break on negation, on actual identifiers, on the hole between a query and its reply. The staff’s first reflex is the one the literature suggests: add a reranker. Cross-encoder, smaller than an LLM, smarter than cosine, slot it between embeddings and the LLM. They wire in bge-reranker-base, ship it the top-100 from the embedding stage, preserve the top-10. A number of queries that had been damaged yesterday appear to work at this time. The staff is inspired.
Scene 2. Two weeks in, the identical operational sample from Article 2 returns. The person asks “checklist each clause that mentions termination” and the system returns the three “most related” ones, precisely three, ranked. The contract has eleven. The person asks “what’s the cancellation rule for non-employees?” The reranker has by no means seen the corporate’s time period non-employee labor, and ranks an unrelated paragraph on prime. The person asks “is there a clause that does NOT point out indemnification?” Identical negation failure as earlier than; the cross-encoder doesn’t see logical complementation any greater than the embedding did. Latency, in the meantime, is now within the a whole bunch of milliseconds. The cross-encoder runs at question time on each candidate, and there’s no technique to precompute it. Worse: after they run side-by-side comparisons towards text-embedding-3-large with out the reranker, the embedding alone typically matches or beats ada-002 + bge-reranker-base.
The classical retrieval funnel appears to be like the identical approach it did in Article 2. Low cost embedding similarity on the backside narrows tens of millions of candidates to hundreds. An elective cross-encoder reranker between narrows the hundreds to dozens. The chat-completion LLM on prime reads the handfuls. The reranker is the layer that sits between two massive constants on the cost-and-quality ladder. Realizing what every stage actually does is what makes the funnel work; anticipating magic from any single stage is how groups lose six months. This text assessments the cost-perf gradient empirically: 4 embedding fashions from 2014 to 2024, plus three off-the-shelf cross-encoder rerankers, scored aspect by aspect on the circumstances Article 2 catalogued. The result’s extra stunning than the funnel suggests.
This text assessments the cost-perf gradient empirically: 4 embedding fashions from 2014 to 2024, plus three off-the-shelf cross-encoder rerankers, scored aspect by aspect on the circumstances Article 2 catalogued. The result’s extra stunning than the funnel suggests.
The seven fashions examined, with their license attestation URLs (the URL of the web page on which the mannequin creator themselves declares the license):
- GloVe-avg (2014, 300-dim phrase vectors): Apache 2.0, declared on the HuggingFace mannequin card.
- all-MiniLM-L6-v2 (2021, 22M params, 384-dim): Apache 2.0, declared on the HuggingFace mannequin card.
- text-embedding-ada-002 (OpenAI 2022, 1536-dim): proprietary; OpenAI Phrases of Use.
- text-embedding-3-large (OpenAI 2024, 3072-dim): proprietary; OpenAI Phrases of Use.
- bge-reranker-base (BAAI 2023, 278M params): MIT license, declared on the HuggingFace mannequin card.
- bge-reranker-large (BAAI 2023, 560M params): MIT license, declared on the HuggingFace mannequin card.
- cross-encoder/ms-marco-MiniLM-L-12-v2 (historic baseline): Apache 2.0, declared on the HuggingFace mannequin card.
from sentence_transformers import CrossEncoder
from openai import OpenAI
# Bi-encoder (the embedding stage from Article 2).
# Every textual content turns into a vector INDEPENDENTLY. Cosine in vector area.
shopper = OpenAI()
def cosine_score(question, passage):
v_q = shopper.embeddings.create(enter=question, mannequin="text-embedding-ada-002").knowledge[0].embedding
v_p = shopper.embeddings.create(enter=passage, mannequin="text-embedding-ada-002").knowledge[0].embedding
return dot(v_q, v_p) / (norm(v_q) * norm(v_p))
# Cross-encoder reranker.
# Question and passage are TOKENIZED TOGETHER and attended over collectively.
# One ahead move per (question, passage) pair. Returns a single relevance rating.
reranker = CrossEncoder("BAAI/bge-reranker-base")
def rerank_score(question, passage):
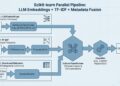
return reranker.predict([(query, passage)])[0]This text is one piece of the broader Entreprise Doc Intelligence Vol. 1 collection, which builds enterprise RAG brick by brick from a baseline pipeline to corpus-scale structure.
1. What a reranker really is
Earlier than the empirical assessments, the architectural image. Two causes it issues: the reranker is an actual engineering object with actual prices, and the editorial place the collection defends solely is smart as soon as the classical position is on the desk.
1.1 The associated fee/precision gradient
Three phases, ordered by price per question:
- Bi-encoder embedding similarity. A precomputed vector per doc. At question time the mannequin encodes the question as soon as and runs cosine similarity towards the index. Milliseconds for tens of millions of candidates. Low cost and approximate.
- Cross-encoder reranker. Question and passage are tokenised collectively and handed by a transformer that attends throughout each. The output is a single relevance rating per pair. Can’t be precomputed as a result of the question is a part of the enter. Tens of milliseconds per pair. Mid-cost, mid-precision.
- Chat-completion LLM. Reads a small candidate set and produces a structured reply. Lots of of milliseconds, {dollars} per million tokens. Costliest, most correct.
Every stage is justified by what it may do cheaper than the following stage above. Embeddings can’t do the whole lot an LLM can, however they will rating 1,000,000 candidates within the time the LLM reads ten. Rerankers can’t do the whole lot an LLM can, however they will rank a thousand candidates within the time the LLM reads twenty. That’s the textbook story. Part 2 assessments it on actual question shapes. The gradient seems to be flatter, and generally inverted, in comparison with what the funnel suggests.
1.2 The funnel
The architectural image is a funnel. The corpus has, say, 200,000 pages. The embedding stage scores all of them and returns the highest 100. The reranker scores the 100 and returns the highest 10. The LLM reads the ten and produces a solution. Every arrow narrows the candidate pool by an order of magnitude or extra, and every stage is justified by the cost-versus-quality commerce with its neighbours.

This funnel logic is what makes the reranker fascinating solely when the upstream stage produces a big pool. If you happen to already retrieve top-5 from a well-scoped pipeline, there isn’t a funnel to slim. The reranker re-orders 5 candidates the LLM will learn anyway. The reranker’s worth is proportional to the scale of the candidate pool it inherits.
On paper, the funnel is elegant: three mathematically distinct scorers, every tuned to its rung of the cost-versus-quality ladder, every justified by the commerce with its neighbours. In apply, the class doesn’t switch to the folks the system is constructed for. A enterprise professional who opens an audit log sees three completely different scores per web page, every on a distinct scale, every produced by a mannequin they don’t perceive and can’t reproduce. The system turns into more durable to clarify than the paperwork it’s purported to reply questions on. The editorial place the collection defends (developed in part 4) will not be that the funnel is unsuitable on paper. It’s that the architectural strikes the consultants can audit (professional vocabulary, structure-aware retrieval, classify-before-retrieve, particular pipelines per query sort) purchase extra belief per greenback than stacking statistically distinct scorers does.
1.3 Bi-encoder vs cross-encoder mechanically
The mechanical distinction issues for what every can mannequin. A bi-encoder (the embedding mannequin from Article 2) encodes the question and the passage independently, then compares vectors. The 2 by no means see one another contained in the mannequin. No matter interplay issues between them (does this passage reply this query) has to outlive the projection right into a fixed-dimensional vector for both sides.
A cross-encoder tokenises question and passage collectively, separated by a particular token, and runs them by a transformer that attends throughout either side. Each token within the passage can attend to each token within the question. The mannequin can instantly rating “the second token of the question is a negation; the third token of the passage means the alternative”. In precept this provides a cross-encoder entry to fine-grained interactions a bi-encoder can’t signify.
In precept. The coaching knowledge and goal resolve what it really learns to attain.
2. The associated fee-perf gradient, examined on the identical circumstances
The textbook funnel sells a clear cost-perf gradient: weak embeddings on the backside, robust embeddings within the center, cross-encoder rerankers on prime. Every step prices extra, every step is meant to attain extra precisely. The sincere take a look at is to take the circumstances Article 2 catalogued and run them throughout the entire gradient: 4 embedding fashions from GloVe-avg (2014) to text-embedding-3-large (2024), plus three off-the-shelf cross-encoder rerankers (bge-base, bge-large, ms-marco-MiniLM-L-12-v2). Seven columns per determine. Learn every row horizontally and the gradient both holds, breaks, or generally inverts.
Three issues to observe as you scan every determine: – Does the TARGET row’s #1 win migrate from left to proper (the gradient holds, greater mannequin = higher)? Does the TARGET get caught at #2-#3 throughout all seven columns (no realized scorer catches the form)? Or does a smaller, cheaper mannequin rank the TARGET increased than the large rerankers (the gradient inverts)?
All three patterns seem under.
2.1 Literal-token entice (Article 2, part 1.6)
Question sizzling canine, candidates: a meals paraphrase (TARGET, zero shared tokens), the lexical entice the canine basked within the sizzling solar, and an unrelated decoy. In Article 2, ada-002 fell for the entice; solely text-embedding-3-large recovered.
The outcome on the seven-column grid is hanging: 3-large continues to be the one mannequin that flips the entice to #2 and lifts the paraphrase to #1. Not one of the three rerankers do. Stacking bge-large on prime of ada-002 doesn’t purchase you what 3-large already provides you without cost on the embedding stage. If the finances is “both improve the embedding or add a reranker,” this case argues for upgrading the embedding.

sizzling canine. Every column’s #1 row exhibits whether or not the scorer picked paraphrase or entice – Picture by creator2.2 Synonym restoration with a tough lexical distractor (Article 2, part 1.2)
Question is inexperienced card wanted. The precise reply (Everlasting resident card is required for this course of.) shares zero tokens with the question however is the strict synonym. The entice (Inexperienced coloured playing cards are well-liked in stationery shops.) shares THREE tokens (inexperienced, card, playing cards) and is semantically unrelated. That is the canonical “synonym vs lexical overlap” take a look at.
The grid surfaces an inversion of the cost-perf declare. MiniLM, ada-002, 3-large and bge-base all rank the synonym TARGET #1. Then bge-large and ms-marco-MiniLM-L-12-v2 fall again to the lexical entice at #1, as if the larger / MS-MARCO-trained fashions have a stronger lexical bias. Two of the three rerankers actively make this worse than bge-base does. A staff that auto-stacks the largest accessible reranker on each question loses floor right here that they’d have stored by sticking with the small one, or by skipping the reranker solely.

2.3 Topical proximity vs reply relevance (Article 2, part 2.3)
Consumer query: “Who signed the contract?” The corpus has one passage describing how contracts have to be signed (procedural, dense in signed/signature/consultant), and one passage that is the precise signature (Signed: John Smith, Advertising and marketing Director, dated 2025-03-15). On each embedding mannequin in Article 2, the procedural passage outranked the precise signature. That is the form of question-answer mismatch cross-encoders are skilled on (MS-MARCO is roughly this form repeated tens of millions of instances).
The grid says one thing the textbook doesn’t predict. MiniLM is the one mannequin, embedding or reranker, that promotes the precise signature line to #1. Each different column, together with the three cross-encoder rerankers explicitly skilled on this type of pair, leaves the procedural passage at #1 and the signature at #2. A 22M-parameter free embedding beats six different layers on the canonical reranker take a look at. The associated fee-perf gradient doesn’t simply flatten right here; it inverts.

2.4 Sign dilution in lengthy context (Article 2, part 2.4)
The identical reply sentence, offered twice: as soon as alone, as soon as buried inside a 70-word coverage paragraph. A topical decoy (speaking densely about deductibles, by no means giving the reply) and an unrelated paragraph spherical out the candidates. In Article 2 each embedding mannequin picked the quick reply alone, however misplaced the buried-answer paragraph to the topical decoy: the encompassing noise diluted the sign of the reply sentence.
That is the one form the place the rerankers earn their price. bge-large, bge-base-saturated and ms-marco-MiniLM all rank the quick reply #1 with the buried-answer paragraph #2. They get well the buried reply to second place, the place ada-002 and MiniLM had it third or worse. 3-large already will get there on the embedding stage. So the image is: on sign dilution, both pay for 3-large on the embedding stage, or stack a free reranker on prime of a less expensive embedding. Each paths work. That is the cleanest case within the article for the cross-encoder layer.

2.5 The sure/no query (Article 2, part 2.6)
Article 2’s deepest case: the precise reply (Sure, it's wanted.) to a sure/no query, towards a literal copy of the question key phrases (Everlasting resident card) and an extended combine. On each embedding mannequin, the literal-keyword copy beat the reply. The entire motive cross-encoders exist as a layer is that they’re skilled on query-answer pairs the place the reply hardly ever repeats the question.
The grid largely confirms: the literal copy Everlasting resident card is #1 on each column. The TARGET (Sure, it's wanted.) is #3 or #4 throughout all of the embeddings and the BGE rerankers. The one column that promotes the precise reply is ms-marco-MiniLM-L-12-v2. It places Sure, it's wanted. at #2, forward of A inexperienced card could also be required. and the No reply. A small win, on a sure/no form that nothing else handles. Price understanding the MS-MARCO-trained reranker has this particular habits; not sufficient to design a pipeline round.

Learn the columns horizontally and the cost-perf gradient is generally flat. On 2.1 the one winner is 3-large (a 2024 embedding, no reranker required). On 2.3 the one winner is MiniLM (a 22M-param free embedding from 2021). On 2.2 two of the three rerankers are worse than the smaller fashions. Solely 2.4 (sign dilution) exhibits a clear reranker win. Stacking a free off-the-shelf reranker on prime of a less expensive embedding doesn’t purchase dependable carry over swapping the embedding for a stronger one; on some shapes it actively hurts.
This matches a sample engineering groups uncover the arduous approach: the marginal greenback is best spent on the embedding stage (or, as the remainder of the collection argues, on upstream structure: professional key phrases, classify-before-retrieve) than on a reranker. The classical funnel sells “embeddings low cost, rerankers extra correct” as a clear ladder. On these question shapes there isn’t a ladder. Part 3 is the more durable aspect: circumstances that don’t transfer no matter which scorer you employ.
3. The place the cross-encoder nonetheless breaks
4 failure modes that survive the cross-encoder layer no matter measurement or household. The architectural job, which the remainder of the collection is about, is to recognise these circumstances on the question-parsing stage and route them by pipelines that don’t depend on similarity scoring in any respect.
3.1 Negation, nonetheless invisible
Article 2 ran the negation take a look at on 4 embedding fashions: question “What’s NOT a metropolis?”, candidates Paris, New York, Metropolis, Desk. Each mannequin ranked Desk (the one right reply) on the backside. The negation token carried no sign. Does any cross-encoder choose up the inversion?

Desk is the right reply for negation. Does every scorer choose it or a metropolis – Picture by creatorCross-encoders are skilled on (question, relevant_passage) pairs from net search and MS-MARCO. Virtually no coaching pair has the form “the related passage is the complement of the question’s matter”. The mannequin realized to attain topical alignment, and a NOT within the question barely shifts that. The repair is at question-parsing time: detect the negation, invert the retrieval (Article 6).
3.2 Precise identifiers and inner acronyms
Contract reference numbers, inner product codes, acronyms that exist solely inside the corporate. The instinct is that realized similarity will confuse ZRX-2025-A with the close-by ZRX-2024-B. Let’s see.

The determine is a helpful lesson in take a look at design as a lot as in retrieval. With solely three candidates and the correct contract showing verbatim within the candidate textual content, each fashionable scorer disambiguates appropriately. MiniLM, each OpenAI embeddings, and all three rerankers put ZRX-2025-A at #1. Solely GloVe will get confused. The true failure mode for identifiers is at scale: a corpus with a whole bunch of contracts whose surrounding textual content follows a templated sample (Contract ), the place the identifier is the solely discriminating characteristic. There the embedding’s literal-token sign turns into a tiny fraction of the cosine, and the close-by IDs blur. Manufacturing-scale identifier disambiguation belongs in BM25 or an exact-match index (Article 6, part 2.2 through concept_keywords_df), not in similarity. The three-candidate take a look at right here simply exhibits that embeddings will not be blind to identifiers when the sphere is small.
3.3 Itemizing, the canonical failure mode
The reranker’s job is to rank candidates. A list query desires all of them. Each scorer will dutifully order the eleven termination clauses from most to least related; the top-k lower discards those it ranked lowest, and the person, who requested for the whole set, will get a partial reply.

The repair is itemizing aggregation (Article 12), not a reranker. A list query is parsed as a list_all intent on the question-parsing stage and routed to a pipeline that returns each matching merchandise, not the top-k by rating.
3.4 Out-of-domain vocabulary
Each mannequin on the grid carries the inductive bias of its coaching corpus. The OpenAI embeddings and the BGE rerankers are skilled on broad net/retrieval knowledge; ms-marco-MiniLM-L-12-v2 on MS-MARCO. Specialised vocabularies (medical, authorized, monetary, regulatory) sit outdoors these distributions. Tremendous-tuning the reranker on area knowledge fixes a lot of this. However fine-tuning is a venture, not a free improve. Off-the-shelf, no scorer on the grid bridges to the corporate time period.

contractor time beyond regulation vs firm time period non-employee labor. Each scorer ranks TARGET at #3 – Picture by creatorCommon failure throughout the seven columns. The TARGET sits at #3 on each mannequin; Contractors are paid on a per-project foundation (the floor lexical match) wins at #1. Neither the most important embedding nor the most important reranker bridges contractor → non-employee labor. That is precisely the issue the collection’s concept_keywords_df is constructed to resolve. The professional curates the mapping contractor → non-employee labor, time beyond regulation → past 40h/week, and the retrieval stage makes use of these key phrases instantly. The reranker would wish fine-tuning on the corporate’s contracts to study the identical mapping the professional simply typed.
4. The place rerankers really justify their price
The place of the collection, acknowledged plainly:
Cross-encoder rerankers are a fallback for slim circumstances, not the first stage of an enterprise pipeline. They’re value their price when the candidate pool is massive (top-100,000 from a vector retailer), the upstream is generic cosine, and there’s no time to construct a curated pipeline. They add little when the upstream is already small, already-scoped, and already structured.
In manufacturing enterprise RAG, three architectural strikes make the reranker’s worth smaller than the literature suggests.
Query parsing routes the question to a selected pipeline. A list query runs by list_all aggregation (Article 12), not by ranked retrieval. A filtering query runs by metadata filters (Article 18), not by similarity scoring. A negation query is detected and inverted at question-parsing time (Article 6). The reranker’s enter is subsequently a small, already-scoped candidate set produced by a structurally applicable pipeline, not a top-100 dump from a generic vector retailer.
Classify-before-retrieve shrinks the candidate pool. Article 15 develops the classification step that tags every doc with matter, sort, and date metadata. At question time, metadata filters cut back the candidate corpus from 200,000 paperwork to perhaps 800. The reranker (if it runs in any respect) runs on a pool sufficiently small {that a} area professional might overview it in fifteen minutes. There isn’t a top-100,000 funnel left to handle.
Professional key phrases exchange probabilistic rating on the circumstances that matter. Article 6 builds the concept_keywords_df desk that maps person vocabulary to doc vocabulary. The mapping is curated; it’s auditable; it’s precisely the work {that a} reranker is meant to do probabilistically. The place the key phrase dictionary covers the case, rating is changed by structured retrieval and the reranker’s worth drops additional.
The professional large-corpus case (hundreds to a whole bunch of hundreds of paperwork in a vector retailer, single ad-hoc query, no time to construct a curated pipeline) is actual, and the collection acknowledges it in Articles 15-20 (corpus scale). Even there, the popular transfer is classify-and-filter first; the reranker is available in to disambiguate the residual pool.
The underside line for the reader: rerankers are helpful. They’ve an actual place within the literature. The associated fee/precision gradient is actual, and the funnel is the engineering actuality of any manufacturing retrieval structure. The collection explains them and makes use of them the place they earn their price. However the architectural selections the collection defends (professional vocabulary, structure-aware retrieval, classify-before-retrieve, particular pipelines for particular question-types) push the reranker right into a slim nook somewhat than the default. Article 9 returns to methodology mixture on the retrieval layer; Articles 15-20 develop the corpus-scale case.
5. Conclusion
The rerankers query is one slice of a bigger framing: Enterprise Doc Intelligence Quantity 1 builds enterprise RAG brick by brick, with the upstream bricks (query parsing, classify-before-retrieve, professional key phrases) doing the work the reranker is often requested to do.

The textbook funnel sells a clear cost-perf gradient: low cost embeddings on the backside, a extra expressive cross-encoder reranker above, then the LLM. Stacking the reranker on prime of weak retrieval is meant to repair what the embedding misses.
The seven-column grid says in any other case. On 4 of the 5 “anticipated reranker wins” from Article 2, the cross-encoder columns both match the embedding or do worse. Solely sign dilution (a buried reply in an extended paragraph) is a clear reranker win. On the literal-token entice, the canonical answer-vs-procedural take a look at, and the synonym-vs-distractor case, a robust embedding (text-embedding-3-large) or perhaps a small free one (MiniLM) typically beats off-the-shelf rerankers. Negation, actual identifiers (at small candidate rely), out-of-domain vocabulary, itemizing: none of them transfer no matter which scorer you employ.
The collection’s editorial place survives the info, and is bolstered by it: rerankers are a fallback for one particular form (sign dilution in lengthy context), not the first stage. The marginal greenback buys extra carry on the embedding stage than the reranker stage on these question shapes. The architectural strikes that make rerankers largely redundant (query parsing, classify-before-retrieve, professional key phrases, particular pipelines for particular intents) are what the remainder of the collection builds. Article 3 makes the broader case (RAG will not be machine studying). Articles 6 and seven construct the upstream bricks. Article 9 returns to methodology mixture on the retrieval layer. Articles 15-20 develop the corpus-scale case the place rerankers may genuinely justify their place.
6. Additional studying
- Nogueira & Cho, Passage Re-ranking with BERT, 2019 (arXiv:1901.04085). The seminal cross-encoder reranker paper; units up the structure the bge-reranker household inherits.
- Khattab & Zaharia, ColBERT: Environment friendly and Efficient Passage Search through Contextualized Late Interplay over BERT, SIGIR 2020 (arXiv:2004.12832). The late-interaction different — retains token-level cross-attention however at bi-encoder price.
- Xiao et al., C-Pack / BGE Reranker household, 2023 (arXiv:2309.07597). The BAAI launch notes for the rerankers used on this article (
bge-reranker-base,bge-reranker-large). - Pradeep et al., RankZephyr: Efficient and Sturdy Zero-Shot Listwise Reranking is a Breeze!, 2023 (arXiv:2312.02724). LLM-as-reranker different; related as soon as frontier mannequin prices drop additional.















{kind=link}