



DATA PREPROCESSING
Artificially producing and deleting information for the larger good

⛳️ Extra DATA PREPROCESSING, defined:
· Lacking Worth Imputation
· Categorical Encoding
· Knowledge Scaling
· Discretization
▶ Oversampling & Undersampling
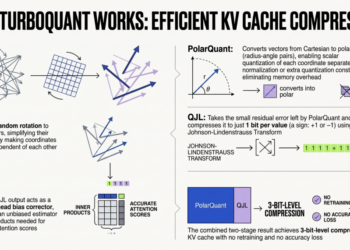
Accumulating a dataset the place every class has precisely the identical variety of class to foretell is usually a problem. In actuality, issues are hardly ever completely balanced, and if you find yourself making a classification mannequin, this may be a difficulty. When a mannequin is skilled on such dataset, the place one class has extra examples than the opposite, it has often grow to be higher at predicting the larger teams and worse at predicting the smaller ones. To assist with this challenge, we are able to use ways like oversampling and undersampling — creating extra examples of the smaller group or eradicating some examples from the larger group.
There are lots of completely different oversampling and undersampling strategies (with intimidating names like SMOTE, ADASYN, and Tomek Hyperlinks) on the market however there doesn’t appear to be many sources that visually examine how they work. So, right here, we are going to use one easy 2D dataset to point out the adjustments that happen within the information after making use of these strategies so we are able to see how completely different the output of every technique is. You will note within the visuals that these numerous approaches give completely different options, and who is aware of, one is likely to be appropriate to your particular machine studying problem!

Oversampling
Oversampling make a dataset extra balanced when one group has so much fewer examples than the opposite. The best way it really works is by making extra copies of the examples from the smaller group. This helps the dataset characterize each teams extra equally.
Undersampling
Alternatively, undersampling works by deleting a few of the examples from the larger group till it’s nearly the identical in dimension to the smaller group. Ultimately, the dataset is smaller, positive, however each teams may have a extra comparable variety of examples.
Hybrid Sampling
Combining oversampling and undersampling could be known as “hybrid sampling”. It will increase the dimensions of the smaller group by making extra copies of its examples and likewise, it removes a few of instance of the larger group by eradicating a few of its examples. It tries to create a dataset that’s extra balanced — not too massive and never too small.

Let’s use a easy synthetic golf dataset to point out each oversampling and undersampling. This dataset reveals what sort of golf exercise an individual do in a selected climate situation.

⚠️ Notice that whereas this small dataset is sweet for understanding the ideas, in actual purposes you’d need a lot bigger datasets earlier than making use of these methods, as sampling with too little information can result in unreliable outcomes.
Random Oversampling
Random Oversampling is a straightforward option to make the smaller group greater. It really works by making duplicates of the examples from the smaller group till all of the lessons are balanced.
👍 Greatest for very small datasets that should be balanced rapidly
👎 Not advisable for classy datasets


SMOTE
SMOTE (Artificial Minority Over-sampling Approach) is an oversampling method that makes new examples by interpolating the smaller group. In contrast to the random oversampling, it doesn’t simply copy what’s there however it makes use of the examples of the smaller group to generate some examples between them.
👍 Greatest when you could have a good quantity of examples to work with and want selection in your information
👎 Not advisable you probably have only a few examples
👎 Not advisable if information factors are too scattered or noisy


ADASYN
ADASYN (Adaptive Artificial) is like SMOTE however focuses on making new examples within the harder-to-learn elements of the smaller group. It finds the examples which are trickiest to categorise and makes extra new factors round these. This helps the mannequin higher perceive the difficult areas.
👍 Greatest when some elements of your information are tougher to categorise than others
👍 Greatest for complicated datasets with difficult areas
👎 Not advisable in case your information is pretty easy and easy


Undersampling shrinks the larger group to make it nearer in dimension to the smaller group. There are some methods of doing this:
Random Undersampling
Random Undersampling removes examples from the larger group at random till it’s the identical dimension because the smaller group. Similar to random oversampling the tactic is fairly easy, however it would possibly eliminate necessary data that actually present how completely different the teams are.
👍 Greatest for very giant datasets with numerous repetitive examples
👍 Greatest whenever you want a fast, easy repair
👎 Not advisable if each instance in your greater group is necessary
👎 Not advisable in the event you can’t afford dropping any info


Tomek Hyperlinks
Tomek Hyperlinks is an undersampling technique that makes the “traces” between teams clearer. It searches for pairs of examples from completely different teams which are actually alike. When it finds a pair the place the examples are one another’s closest neighbors however belong to completely different teams, it eliminates the instance from the larger group.
👍 Greatest when your teams overlap an excessive amount of
👍 Greatest for cleansing up messy or noisy information
👍 Greatest whenever you want clear boundaries between teams
👎 Not advisable in case your teams are already effectively separated


Close to Miss
Close to Miss is a set of undersampling methods that works on completely different guidelines:
- Close to Miss-1: Retains examples from the larger group which are closest to the examples within the smaller group.
- Close to Miss-2: Retains examples from the larger group which have the smallest common distance to their three closest neighbors within the smaller group.
- Close to Miss-3: Retains examples from the larger group which are furthest away from different examples in their very own group.
The principle thought right here is to maintain essentially the most informative examples from the larger group and eliminate those that aren’t as necessary.
👍 Greatest whenever you need management over which examples to maintain
👎 Not advisable in the event you want a easy, fast answer


ENN
Edited Nearest Neighbors (ENN) technique eliminates examples which are in all probability noise or outliers. For every instance within the greater group, it checks whether or not most of its closest neighbors belong to the identical group. In the event that they don’t, it removes that instance. This helps create cleaner boundaries between the teams.
👍 Greatest for cleansing up messy information
👍 Greatest when you’ll want to take away outliers
👍 Greatest for creating cleaner group boundaries
👎 Not advisable in case your information is already clear and well-organized


SMOTETomek
SMOTETomek works by first creating new examples for the smaller group utilizing SMOTE, then cleansing up messy boundaries by eradicating “complicated” examples utilizing Tomek Hyperlinks. This helps making a extra balanced dataset with clearer boundaries and fewer noise.
👍 Greatest for unbalanced information that’s actually extreme
👍 Greatest whenever you want each extra examples and cleaner boundaries
👍 Greatest when coping with noisy, overlapping teams
👎 Not advisable in case your information is already clear and well-organized
👎 Not advisable for small dataset

SMOTEENN
SMOTEENN works by first creating new examples for the smaller group utilizing SMOTE, then cleansing up each teams by eradicating examples that don’t match effectively with their neighbors utilizing ENN. Similar to SMOTETomek, this helps create a cleaner dataset with clearer borders between the teams.
👍 Greatest for cleansing up each teams directly
👍 Greatest whenever you want extra examples however cleaner information
👍 Greatest when coping with numerous outliers
👎 Not advisable in case your information is already clear and well-organized
👎 Not advisable for small dataset
















{kind=link}