


NED-SERIES
How one can distill data from biomedical textual content combining pre-trained language fashions with graph machine studying
This text synthesizes a paper accepted for the IEEE Utility of Data and Communication Applied sciences (AICT2024) convention. Along with the undersigned, Felice Paolo Colliani (first writer), Giovanni Garifo, Antonio Vetrò, and Juan Carlos De Martin are the co-authors of this paper.
The biomedical area has seen a steadily rising publication charge through the years because of the development of scientific analysis, advances in expertise, and the worldwide emphasis on healthcare and medical analysis.
The applying of Pure Language Processing (NLP) methods within the biomedical area represents a shift within the evaluation and interpretation of the huge corpus of biomedical data, enhancing our means to derive significant insights from textual knowledge.
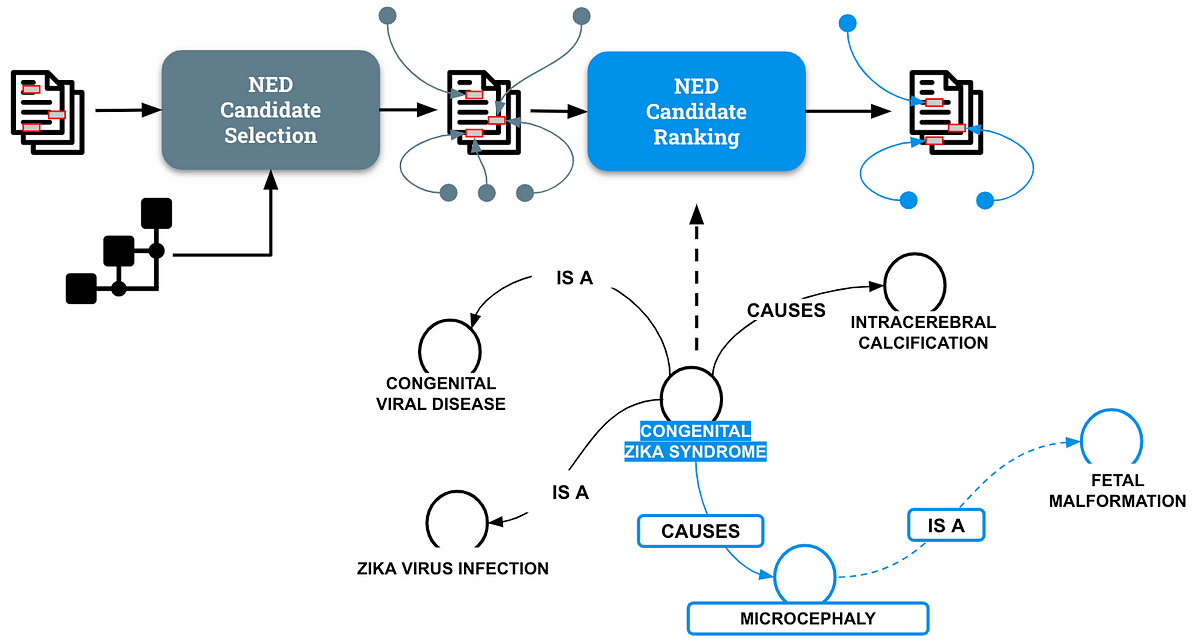
Named Entity Disambiguation (NED) is a crucial NLP process that includes resolving ambiguities in entity mentions by linking them to the proper entries in a data base. To grasp the significance and complexity of such a process, think about the next instance:
Zika belongs to the Flaviviridae household and it’s unfold by Aedes mosquitoes.
People affected by Zika an infection typically…

















{kind=link}