


On this article, you’ll study what guardrails are for non-deterministic AI brokers and the way easy statistical strategies can be utilized to implement them successfully.
Matters we’ll cowl embody:
- What guardrails are and why they matter when working with non-deterministic brokers and huge language fashions.
- How semantic drift detection, primarily based on cosine distance z-scores, can flag off-topic or unsafe agent responses.
- How confidence thresholding, primarily based on Shannon entropy, can detect when a mannequin is unsure or seemingly hallucinating.
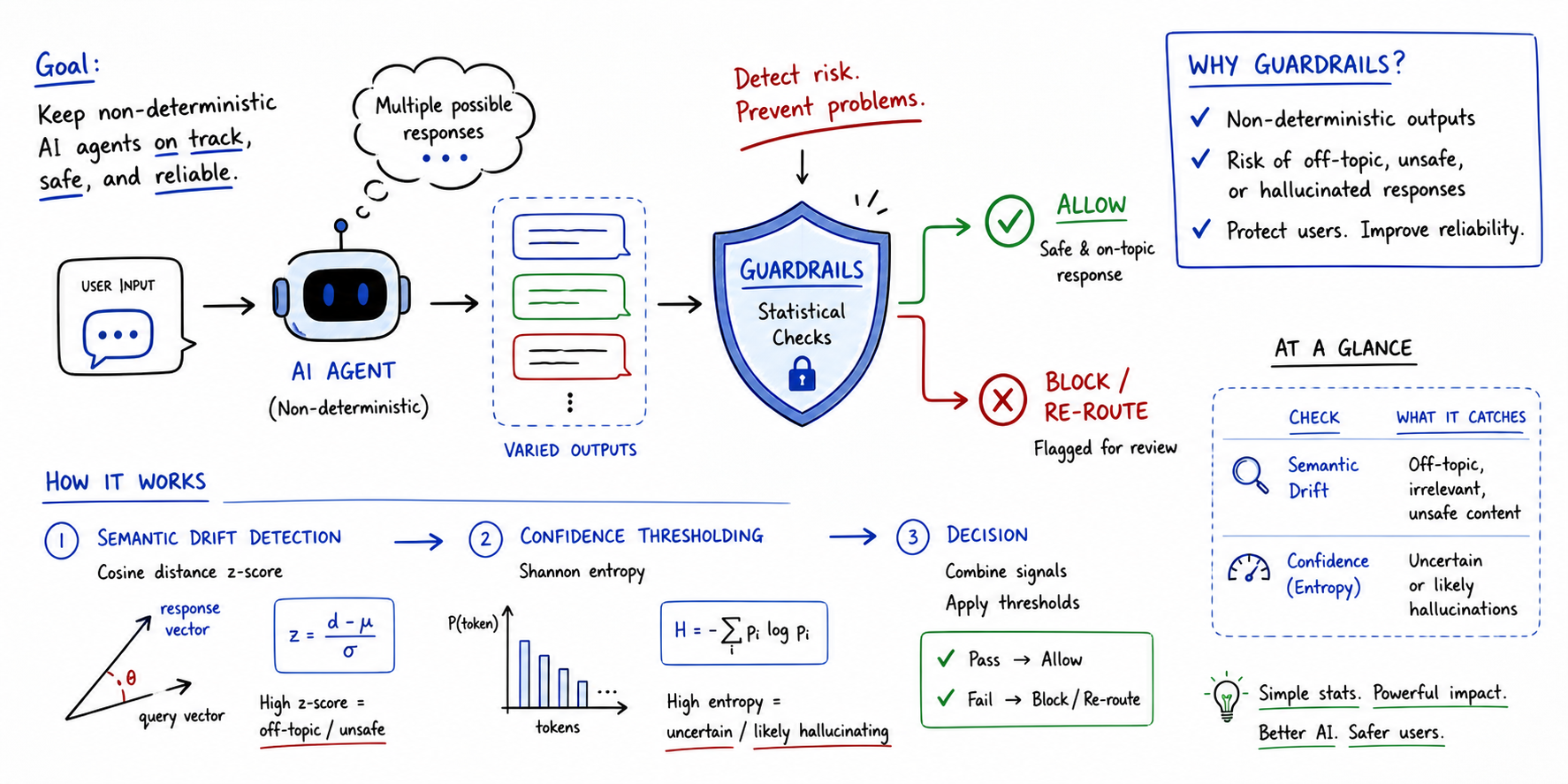
Implementing Statistical Guardrails for Non-Deterministic Brokers (click on to enlarge)
Introduction
Non-deterministic brokers are these the place the identical enter can result in distinct outputs throughout a number of runs. In different phrases, their conduct is probabilistic, making customary analysis strategies like unit testing inconceivable to run. Statistical, threshold-based approaches past precise matching are due to this fact wanted not solely to evaluate these brokers’ efficiency, however most significantly, to make sure protected AI guardrails sit between non-deterministic brokers and finish customers.
This text takes a take a look at guardrails for non-deterministic agent analysis, serving to perceive their significance and illustrating how easy statistical mechanisms can lay the foundations for strong analysis guardrails.
Understanding Guardrails in Agent Analysis
Guardrails are programmatic constraints that act as an automatic security layer sitting between a non-deterministic agent and the tip consumer. These days, the symbiotic use of AI brokers alongside giant language fashions makes them notably necessary, as giant language fashions can yield hallucinations or unpredictable outputs.
In a broad sense, a guardrail assesses the agent’s response in real-time. The evaluation includes checking for points like subject relevance, factual alignment, and potential security violations — all earlier than the output is exhibited to the tip consumer.
Builders can implement them and make brokers extra dependable, even with probabilistic conduct — the secret’s to depend on quantitative statistical thresholds. Let’s see how by a few examples.
Statistical Guardrails for Non-Deterministic Brokers
Statistical guardrails take a major step past summary security considerations. They convert these considerations into automated checks pushed by rigor. Measures broadly utilized in statistics will be utilized, as an example, to establish conditions when the agent turns into erratic or “confused”.
Let’s define two easy but efficient approaches: semantic drift primarily based on cosine distance and confidence thresholding primarily based on log-probability entropy.
Semantic Drift
This guardrail is designed to measure what the agent says, in comparison with a “protected” baseline.
It consists of embedding the output textual content right into a vector house and computing the cosine distance to the recognized baseline knowledge. A z-score of the cosine distance is calculated: if its worth is excessive, this implies the response is a statistical outlier, consequently flagging the response.
This technique is greatest utilized when off-topic drifts ought to be averted, together with hallucinations or poisonous shifts in agent persona and conduct.
Confidence Thresholding
This guardrail measures certainty — extra particularly, how sure the agent is concerning the phrases chosen to construct its response.
To measure it, the log-probabilities of generated tokens are extracted to calculate the Shannon entropy of the underlying distribution:
$$H = -sum p(x) log p(x)$$
When the entropy H is excessive, the agent’s mannequin has been guessing between many low-probability tokens to decide on the following one to generate: a transparent signal of factual failure and low confidence in response technology.
This technique is greatest used for detecting when the mannequin could be inventing details or battling advanced logic workflows.
Statistical Guardrails Implementation
Under, we offer a concise instance of the implementation of those two guardrails in Python, assuming a available agent output textual content.
Begin by importing the mandatory modules and lessons:
|
import numpy as np from sentence_transformers import SentenceTransformer from scipy.spatial.distance import cosine |
The pre-trained sentence transformer we’ll load is used to assemble embeddings for the protected baseline instance responses and the agent’s precise response to guage.
|
# Initialize Mannequin mannequin = SentenceTransformer(‘all-MiniLM-L6-v2’) safe_examples = [“The system is operational.”, “Access is granted to authorized users.”] baseline_embs = mannequin.encode(safe_examples) |
We outline a check_guardrails() operate that evaluates the agent’s output utilizing the 2 strategies described above: a semantic guardrail primarily based on cosine distance z-scores, and a confidence guardrail primarily based on entropy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def check_guardrails(output, token_probs): # 1. Semantic Guardrail (Cosine Distance) output_emb = mannequin.encode([output])[0] distances = np.array([cosine(output_emb, b) for b in baseline_embs]) mean_dist = np.imply(distances) std_dist = np.std(distances) + 1e–9 # keep away from division by zero z_score = (np.min(distances) – mean_dist) / std_dist
# 2. Confidence Guardrail (Entropy) # token_probs is a listing of chances for every generated token entropy = –np.sum(token_probs * np.log(token_probs + 1e–9))
# Choice Logic is_off_topic = z_score > 2.0 # Statistical outlier is_confused = entropy > 3.5 # Excessive uncertainty
if is_off_topic or is_confused: return “REJECT”, {“z_score”: z_score, “entropy”: entropy} return “PASS”, {“z_score”: z_score, “entropy”: entropy}
# Instance utilization with mock token chances print(check_guardrails(“The moon is product of blue cheese.”, np.array([0.1, 0.2, 0.1, 0.5]))) |
To see how the guardrails behave in numerous eventualities, attempt changing the response string within the final line with something of your selection. You may as well tweak the token chances array to extend or lower uncertainty. Within the instance above, the semantic guardrail triggers &emdash; the z-score nicely exceeds the two.0 threshold &emdash; so the response is rejected:
|
(‘REJECT’, {‘z_score’: np.float64(3.847), ‘entropy’: np.float64(1.1289781873656017)}) |
Abstract
Easy, conventional statistical strategies and measures can turn into efficient pillars for implementing security guardrails in AI purposes involving brokers and huge language fashions. They will analyze totally different fascinating properties of responses and assist decision-making, making these techniques extra reliable.
On this article, you’ll study what guardrails are for non-deterministic AI brokers and the way easy statistical strategies can be utilized to implement them successfully.
Matters we’ll cowl embody:
- What guardrails are and why they matter when working with non-deterministic brokers and huge language fashions.
- How semantic drift detection, primarily based on cosine distance z-scores, can flag off-topic or unsafe agent responses.
- How confidence thresholding, primarily based on Shannon entropy, can detect when a mannequin is unsure or seemingly hallucinating.
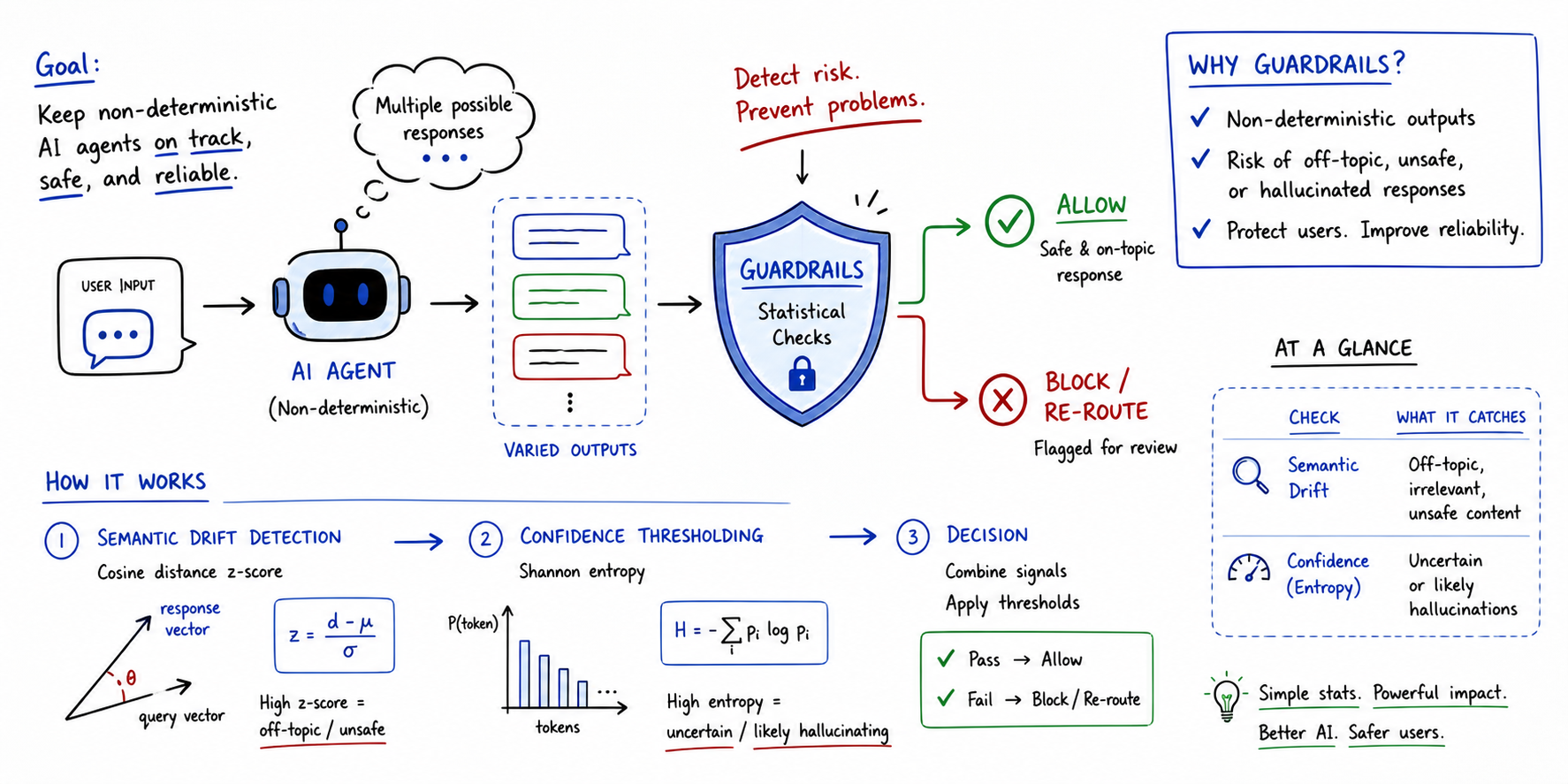
Implementing Statistical Guardrails for Non-Deterministic Brokers (click on to enlarge)
Introduction
Non-deterministic brokers are these the place the identical enter can result in distinct outputs throughout a number of runs. In different phrases, their conduct is probabilistic, making customary analysis strategies like unit testing inconceivable to run. Statistical, threshold-based approaches past precise matching are due to this fact wanted not solely to evaluate these brokers’ efficiency, however most significantly, to make sure protected AI guardrails sit between non-deterministic brokers and finish customers.
This text takes a take a look at guardrails for non-deterministic agent analysis, serving to perceive their significance and illustrating how easy statistical mechanisms can lay the foundations for strong analysis guardrails.
Understanding Guardrails in Agent Analysis
Guardrails are programmatic constraints that act as an automatic security layer sitting between a non-deterministic agent and the tip consumer. These days, the symbiotic use of AI brokers alongside giant language fashions makes them notably necessary, as giant language fashions can yield hallucinations or unpredictable outputs.
In a broad sense, a guardrail assesses the agent’s response in real-time. The evaluation includes checking for points like subject relevance, factual alignment, and potential security violations — all earlier than the output is exhibited to the tip consumer.
Builders can implement them and make brokers extra dependable, even with probabilistic conduct — the secret’s to depend on quantitative statistical thresholds. Let’s see how by a few examples.
Statistical Guardrails for Non-Deterministic Brokers
Statistical guardrails take a major step past summary security considerations. They convert these considerations into automated checks pushed by rigor. Measures broadly utilized in statistics will be utilized, as an example, to establish conditions when the agent turns into erratic or “confused”.
Let’s define two easy but efficient approaches: semantic drift primarily based on cosine distance and confidence thresholding primarily based on log-probability entropy.
Semantic Drift
This guardrail is designed to measure what the agent says, in comparison with a “protected” baseline.
It consists of embedding the output textual content right into a vector house and computing the cosine distance to the recognized baseline knowledge. A z-score of the cosine distance is calculated: if its worth is excessive, this implies the response is a statistical outlier, consequently flagging the response.
This technique is greatest utilized when off-topic drifts ought to be averted, together with hallucinations or poisonous shifts in agent persona and conduct.
Confidence Thresholding
This guardrail measures certainty — extra particularly, how sure the agent is concerning the phrases chosen to construct its response.
To measure it, the log-probabilities of generated tokens are extracted to calculate the Shannon entropy of the underlying distribution:
$$H = -sum p(x) log p(x)$$
When the entropy H is excessive, the agent’s mannequin has been guessing between many low-probability tokens to decide on the following one to generate: a transparent signal of factual failure and low confidence in response technology.
This technique is greatest used for detecting when the mannequin could be inventing details or battling advanced logic workflows.
Statistical Guardrails Implementation
Under, we offer a concise instance of the implementation of those two guardrails in Python, assuming a available agent output textual content.
Begin by importing the mandatory modules and lessons:
|
import numpy as np from sentence_transformers import SentenceTransformer from scipy.spatial.distance import cosine |
The pre-trained sentence transformer we’ll load is used to assemble embeddings for the protected baseline instance responses and the agent’s precise response to guage.
|
# Initialize Mannequin mannequin = SentenceTransformer(‘all-MiniLM-L6-v2’) safe_examples = [“The system is operational.”, “Access is granted to authorized users.”] baseline_embs = mannequin.encode(safe_examples) |
We outline a check_guardrails() operate that evaluates the agent’s output utilizing the 2 strategies described above: a semantic guardrail primarily based on cosine distance z-scores, and a confidence guardrail primarily based on entropy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def check_guardrails(output, token_probs): # 1. Semantic Guardrail (Cosine Distance) output_emb = mannequin.encode([output])[0] distances = np.array([cosine(output_emb, b) for b in baseline_embs]) mean_dist = np.imply(distances) std_dist = np.std(distances) + 1e–9 # keep away from division by zero z_score = (np.min(distances) – mean_dist) / std_dist
# 2. Confidence Guardrail (Entropy) # token_probs is a listing of chances for every generated token entropy = –np.sum(token_probs * np.log(token_probs + 1e–9))
# Choice Logic is_off_topic = z_score > 2.0 # Statistical outlier is_confused = entropy > 3.5 # Excessive uncertainty
if is_off_topic or is_confused: return “REJECT”, {“z_score”: z_score, “entropy”: entropy} return “PASS”, {“z_score”: z_score, “entropy”: entropy}
# Instance utilization with mock token chances print(check_guardrails(“The moon is product of blue cheese.”, np.array([0.1, 0.2, 0.1, 0.5]))) |
To see how the guardrails behave in numerous eventualities, attempt changing the response string within the final line with something of your selection. You may as well tweak the token chances array to extend or lower uncertainty. Within the instance above, the semantic guardrail triggers &emdash; the z-score nicely exceeds the two.0 threshold &emdash; so the response is rejected:
|
(‘REJECT’, {‘z_score’: np.float64(3.847), ‘entropy’: np.float64(1.1289781873656017)}) |
Abstract
Easy, conventional statistical strategies and measures can turn into efficient pillars for implementing security guardrails in AI purposes involving brokers and huge language fashions. They will analyze totally different fascinating properties of responses and assist decision-making, making these techniques extra reliable.















{kind=link}