




Picture by Creator
# Introduction
Internet crawling is the method of mechanically visiting net pages, following hyperlinks, and amassing content material from a web site in a structured approach. It’s generally used to assemble giant quantities of knowledge from documentation websites, articles, data bases, and different net sources.
Crawling a complete web site after which changing that content material right into a format that an AI agent can truly use will not be so simple as it sounds. Documentation websites typically comprise nested pages, repeated navigation hyperlinks, boilerplate content material, and inconsistent web page buildings. On high of that, the extracted content material must be cleaned, organized, and saved in a approach that’s helpful for downstream AI workflows comparable to retrieval, question-answering, or agent-based techniques.
On this information, we’ll study why to make use of Olostep as an alternative of Scrapy or Selenium, arrange every little thing wanted for the online crawling mission, write a easy crawling script to scrape a documentation web site, and at last create a frontend utilizing Gradio in order that anybody can present a hyperlink and different arguments to crawl web site pages.
# Selecting Olostep Over Scrapy or Selenium
Scrapy is highly effective, however it’s constructed as a full scraping framework. That’s helpful once you need deep management, nevertheless it additionally means extra setup and extra engineering work.
Selenium is healthier identified for browser automation. It’s helpful for interacting with JavaScript-heavy pages, however it isn’t actually designed as a documentation crawling workflow by itself.
With Olostep, the pitch is much more direct: search, crawl, scrape, and construction net information by way of one utility programming interface (API), with help for LLM-friendly outputs like Markdown, textual content, HTML, and structured JSON. Which means you should not have to manually sew collectively items for discovery, extraction, formatting, and downstream AI use in the identical approach.
For documentation websites, that can provide you a a lot quicker path from URL to usable content material since you are spending much less time constructing the crawling stack your self and extra time working with the content material you really want.
# Putting in the Packages and Setting the API Key
First, set up the Python packages used on this mission. The official Olostep software program improvement package (SDK) requires Python 3.11 or later.
pip set up olostep python-dotenv tqdm
These packages deal with the primary components of the workflow:
olostepconnects your script to the Olostep APIpython-dotenvmasses your API key from a .env filetqdmprovides a progress bar so you possibly can observe saved pages
Subsequent, create a free Olostep account, open the dashboard, and generate an API key from the API keys web page. Olostep’s official docs and integrations level customers to the dashboard for API key setup.
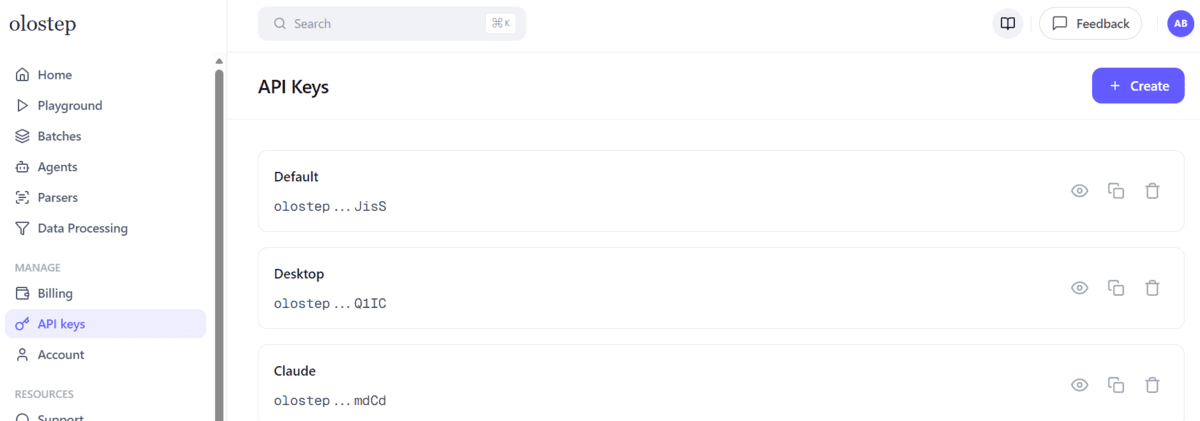
Then create a .env file in your mission folder:
OLOSTEP_API_KEY=your_real_api_key_here
This retains your API key separate out of your Python code, which is a cleaner and safer solution to handle credentials.
# Creating the Crawler Script
On this a part of the mission, we’ll construct the Python script that crawls a documentation web site, extracts every web page in Markdown format, cleans the content material, and saves it domestically as particular person information. We are going to create the mission folder, add a Python file, after which write the code step-by-step so it’s simple to comply with and check.
First, create a mission folder on your crawler. Inside that folder, create a brand new Python file named crawl_docs_with_olostep.py.
Now we’ll add the code to this file one part at a time. This makes it simpler to know what every a part of the script does and the way the total crawler works collectively.
// Defining the Crawl Settings
Begin by importing the required libraries. Then outline the primary crawl settings, such because the beginning URL, crawl depth, web page restrict, embrace and exclude guidelines, and the output folder the place the Markdown information will probably be saved. These values management how a lot of the documentation website will get crawled and the place the outcomes are saved.
import os
import re
from pathlib import Path
from urllib.parse import urlparse
from dotenv import load_dotenv
from tqdm import tqdm
from olostep import Olostep
START_URL = "https://docs.olostep.com/"
MAX_PAGES = 10
MAX_DEPTH = 1
INCLUDE_URLS = [
"/**"
]
EXCLUDE_URLS = []
OUTPUT_DIR = Path("olostep_docs_output")
// Making a Helper Operate to Generate Secure File Names
Every crawled web page must be saved as its personal Markdown file. To do this, we want a helper perform that converts a URL right into a clear and filesystem-safe file title. This avoids issues with slashes, symbols, and different characters that don’t work nicely in file names.
def slugify_url(url: str) -> str:
parsed = urlparse(url)
path = parsed.path.strip("https://www.kdnuggets.com/")
if not path:
path = "index"
filename = re.sub(r"[^a-zA-Z0-9/_-]+", "-", path)
filename = filename.substitute("https://www.kdnuggets.com/", "__").strip("-_")
return f"{filename or 'web page'}.md"
// Making a Helper Operate to Save Markdown Recordsdata
Subsequent, add helper capabilities to course of the extracted content material earlier than saving it.
The primary perform cleans the Markdown by eradicating further interface textual content, repeated clean strains, and undesirable web page components comparable to suggestions prompts. This helps maintain the saved information centered on the precise documentation content material.
def clean_markdown(markdown: str) -> str:
textual content = markdown.substitute("rn", "n").strip()
textual content = re.sub(r"[s*u200b?s*](#.*?)", "", textual content, flags=re.DOTALL)
strains = [line.rstrip() for line in text.splitlines()]
start_index = 0
for index in vary(len(strains) - 1):
title = strains[index].strip()
underline = strains[index + 1].strip()
if title and underline and set(underline) == {"="}:
start_index = index
break
else:
for index, line in enumerate(strains):
if line.lstrip().startswith("# "):
start_index = index
break
strains = strains[start_index:]
for index, line in enumerate(strains):
if line.strip() == "Was this web page useful?":
strains = strains[:index]
break
cleaned_lines: checklist[str] = []
for line in strains:
stripped = line.strip()
if stripped in {"Copy web page", "YesNo", "⌘I"}:
proceed
if not stripped and cleaned_lines and never cleaned_lines[-1]:
proceed
cleaned_lines.append(line)
return "n".be part of(cleaned_lines).strip()
The second perform saves the cleaned Markdown into the output folder and provides the supply URL on the high of the file. There may be additionally a small helper perform to clear outdated Markdown information earlier than saving a brand new crawl end result.
def save_markdown(output_dir: Path, url: str, markdown: str) -> None:
output_dir.mkdir(dad and mom=True, exist_ok=True)
filepath = output_dir / slugify_url(url)
content material = f"""---
source_url: {url}
---
{markdown}
"""
filepath.write_text(content material, encoding="utf-8")
There may be additionally a small helper perform to clear outdated Markdown information earlier than saving a brand new crawl end result.
def clear_output_dir(output_dir: Path) -> None:
if not output_dir.exists():
return
for filepath in output_dir.glob("*.md"):
filepath.unlink()
// Creating the Predominant Crawler Logic
That is the primary a part of the script. It masses the API key from the .env file, creates the Olostep shopper, begins the crawl, waits for it to complete, retrieves every crawled web page as Markdown, cleans the content material, and saves it domestically.
This part ties every little thing collectively and turns the person helper capabilities right into a working documentation crawler.
def principal() -> None:
load_dotenv()
api_key = os.getenv("OLOSTEP_API_KEY")
if not api_key:
elevate RuntimeError("Lacking OLOSTEP_API_KEY in your .env file.")
shopper = Olostep(api_key=api_key)
crawl = shopper.crawls.create(
start_url=START_URL,
max_pages=MAX_PAGES,
max_depth=MAX_DEPTH,
include_urls=INCLUDE_URLS,
exclude_urls=EXCLUDE_URLS,
include_external=False,
include_subdomain=False,
follow_robots_txt=True,
)
print(f"Began crawl: {crawl.id}")
crawl.wait_till_done(check_every_n_secs=5)
pages = checklist(crawl.pages())
clear_output_dir(OUTPUT_DIR)
for web page in tqdm(pages, desc="Saving pages"):
attempt:
content material = web page.retrieve(["markdown"])
markdown = getattr(content material, "markdown_content", None)
if markdown:
save_markdown(OUTPUT_DIR, web page.url, clean_markdown(markdown))
besides Exception as exc:
print(f"Didn't retrieve {web page.url}: {exc}")
print(f"Executed. Recordsdata saved in: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
principal()
Be aware: The complete script is offered right here: kingabzpro/web-crawl-olostep, an online crawler and starter net app constructed with Olostep.
// Testing the Internet Crawling Script
As soon as the script is full, run it out of your terminal:
python crawl_docs_with_olostep.py
Because the script runs, you will note the crawler course of the pages and save them one after the other as Markdown information in your output folder.

After the crawl finishes, open the saved information to examine the extracted content material. It is best to see clear, readable Markdown variations of the documentation pages.
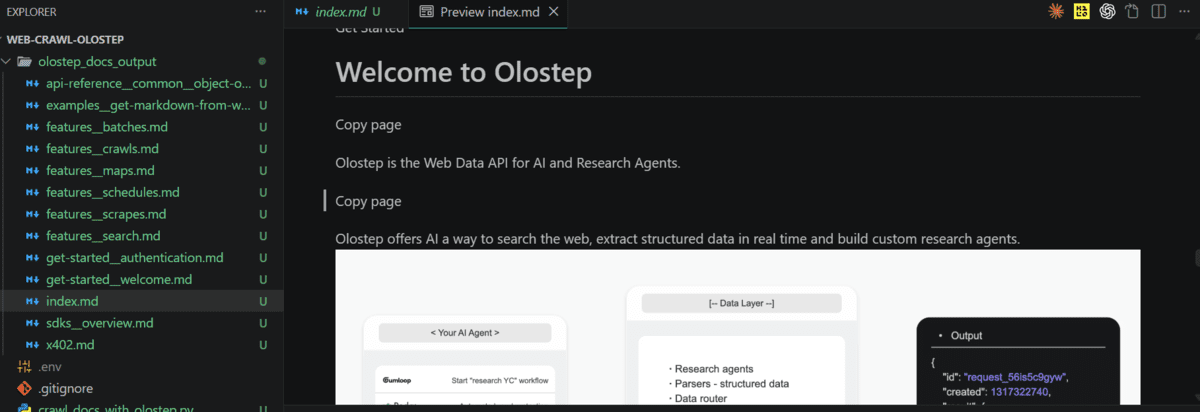
At that time, your documentation content material is able to use in AI workflows comparable to search, retrieval, or agent-based techniques.
# Creating the Olostep Internet Crawling Internet Software
On this a part of the mission, we’ll construct a easy net utility on high of the crawler script. As a substitute of modifying the Python file each time, this utility provides you a better solution to enter a documentation URL, select crawl settings, run the crawl, and preview the saved Markdown information in a single place.
The frontend code for this utility is offered in app.py within the repository: web-crawl-olostep/app.py.
This utility does a number of helpful issues:
- Allows you to enter a beginning URL for the crawl
- Allows you to set the utmost variety of pages to crawl
- Allows you to management crawl depth
- Allows you to add embrace and exclude URL patterns
- Runs the backend crawler immediately from the interface
- Saves the crawled pages right into a folder primarily based on the URL
- Reveals all saved Markdown information in a dropdown
- Previews every Markdown file immediately inside the appliance
- Allows you to clear earlier crawl outcomes with one button
To start out the appliance, run:
After that, Gradio will begin a neighborhood net server and supply a hyperlink like this:
* Operating on native URL: http://127.0.0.1:7860
* To create a public hyperlink, set `share=True` in `launch()`.
As soon as the appliance is operating, open the native URL in your browser. In our instance, we gave the appliance the Claude Code documentation URL and requested it to crawl 50 pages with a depth of 5.
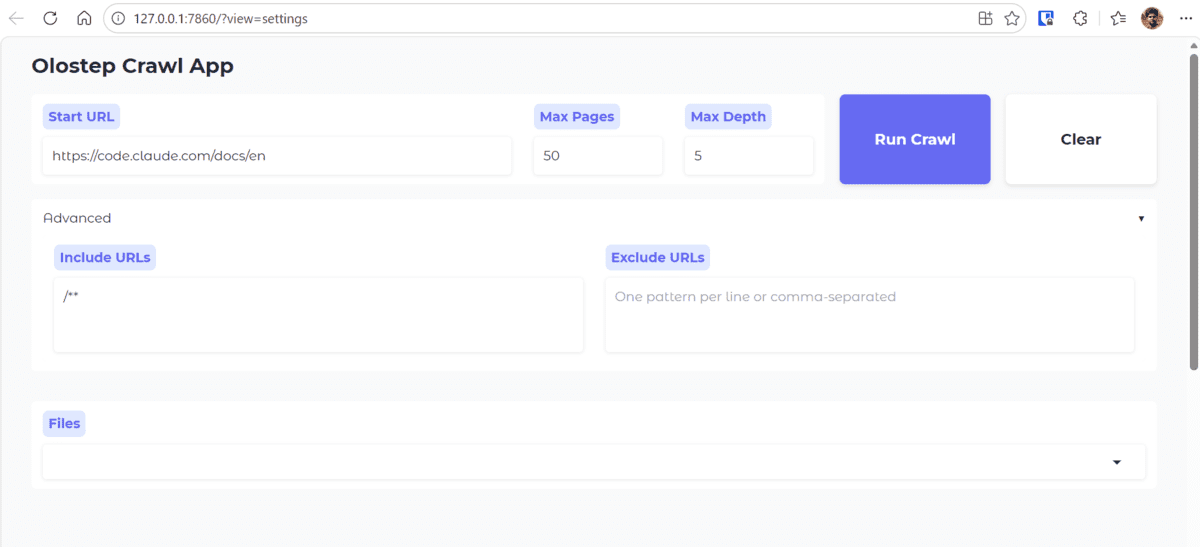
Once you click on Run Crawl, the appliance passes your settings to the backend crawler and begins the crawl. Within the terminal, you possibly can watch the progress as pages are crawled and saved one after the other.

After the crawl finishes, the output folder will comprise the saved Markdown information. On this instance, you’ll see that fifty information have been added.
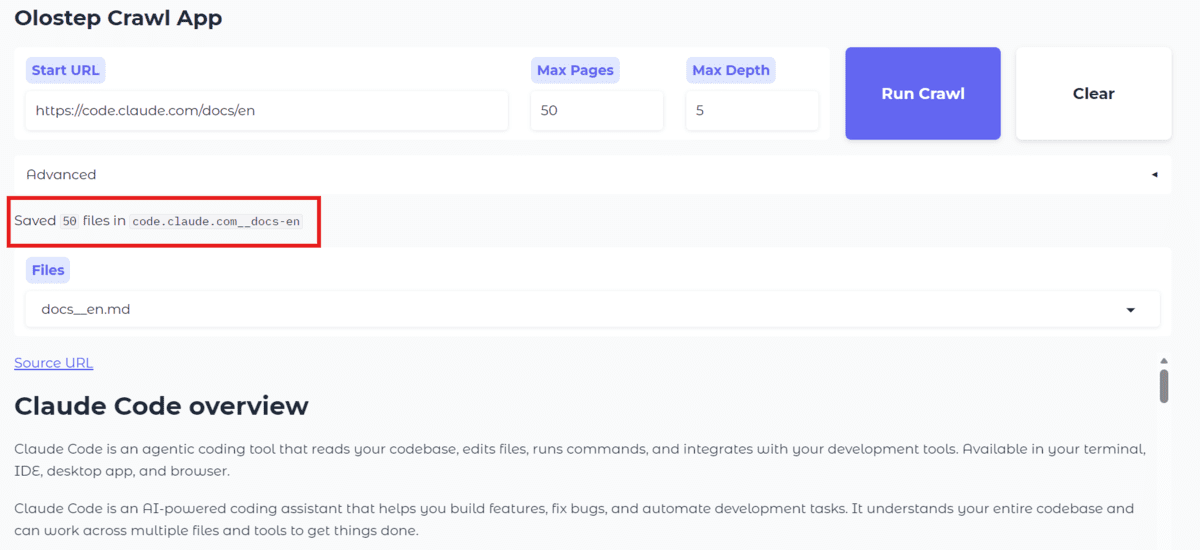
The dropdown within the utility is then up to date mechanically, so you possibly can open any saved file and preview it immediately within the net interface as correctly formatted Markdown.
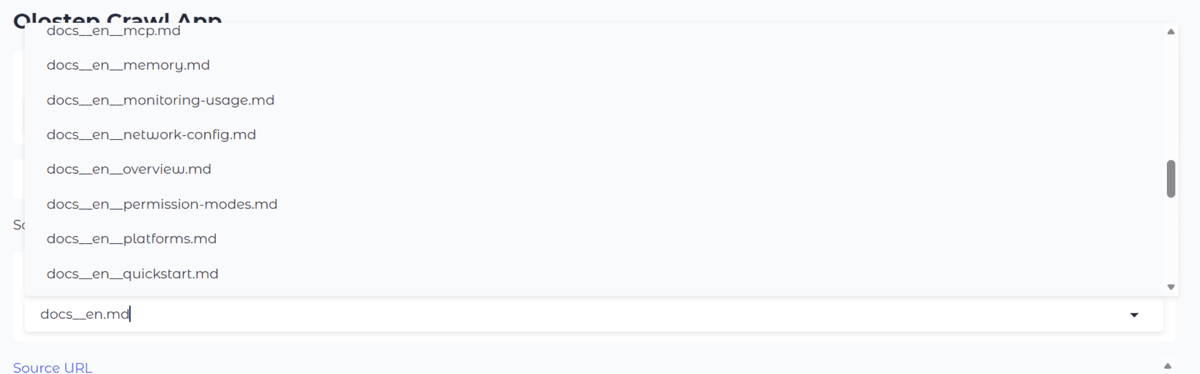
This makes the crawler a lot simpler to make use of. As a substitute of adjusting values in code each time, you possibly can check totally different documentation websites and crawl settings by way of a easy interface. That additionally makes the mission simpler to share with different individuals who might not wish to work immediately in Python.
# Closing Takeaway
Internet crawling will not be solely about amassing pages from a web site. The true problem is popping that content material into clear, structured information that an AI system can truly use. On this mission, we used a easy Python script and a Gradio utility to make that course of a lot simpler.
Simply as importantly, the workflow is quick sufficient for actual use. In our instance, crawling 50 pages with a depth of 5 took solely round 50 seconds, which reveals that you would be able to put together documentation information shortly with out constructing a heavy pipeline.
This setup may transcend a one-time crawl. You’ll be able to schedule it to run every single day with cron or Activity Scheduler, and even replace solely the pages which have modified. That retains your documentation recent whereas utilizing solely a small variety of credit.
For groups that want this type of workflow to make enterprise sense, Olostep is constructed with that in thoughts. It’s considerably extra inexpensive than constructing or sustaining an inner crawling answer, and at the very least 50% cheaper than comparable options in the marketplace.
As your utilization grows, the price per request continues to lower, which makes it a sensible alternative for bigger documentation pipelines. That mixture of reliability, scalability, and robust unit economics is why a few of the fastest-growing AI-native startups depend on Olostep to energy their information infrastructure.
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.
Picture by Creator
# Introduction
Internet crawling is the method of mechanically visiting net pages, following hyperlinks, and amassing content material from a web site in a structured approach. It’s generally used to assemble giant quantities of knowledge from documentation websites, articles, data bases, and different net sources.
Crawling a complete web site after which changing that content material right into a format that an AI agent can truly use will not be so simple as it sounds. Documentation websites typically comprise nested pages, repeated navigation hyperlinks, boilerplate content material, and inconsistent web page buildings. On high of that, the extracted content material must be cleaned, organized, and saved in a approach that’s helpful for downstream AI workflows comparable to retrieval, question-answering, or agent-based techniques.
On this information, we’ll study why to make use of Olostep as an alternative of Scrapy or Selenium, arrange every little thing wanted for the online crawling mission, write a easy crawling script to scrape a documentation web site, and at last create a frontend utilizing Gradio in order that anybody can present a hyperlink and different arguments to crawl web site pages.
# Selecting Olostep Over Scrapy or Selenium
Scrapy is highly effective, however it’s constructed as a full scraping framework. That’s helpful once you need deep management, nevertheless it additionally means extra setup and extra engineering work.
Selenium is healthier identified for browser automation. It’s helpful for interacting with JavaScript-heavy pages, however it isn’t actually designed as a documentation crawling workflow by itself.
With Olostep, the pitch is much more direct: search, crawl, scrape, and construction net information by way of one utility programming interface (API), with help for LLM-friendly outputs like Markdown, textual content, HTML, and structured JSON. Which means you should not have to manually sew collectively items for discovery, extraction, formatting, and downstream AI use in the identical approach.
For documentation websites, that can provide you a a lot quicker path from URL to usable content material since you are spending much less time constructing the crawling stack your self and extra time working with the content material you really want.
# Putting in the Packages and Setting the API Key
First, set up the Python packages used on this mission. The official Olostep software program improvement package (SDK) requires Python 3.11 or later.
pip set up olostep python-dotenv tqdm
These packages deal with the primary components of the workflow:
olostepconnects your script to the Olostep APIpython-dotenvmasses your API key from a .env filetqdmprovides a progress bar so you possibly can observe saved pages
Subsequent, create a free Olostep account, open the dashboard, and generate an API key from the API keys web page. Olostep’s official docs and integrations level customers to the dashboard for API key setup.
Then create a .env file in your mission folder:
OLOSTEP_API_KEY=your_real_api_key_here
This retains your API key separate out of your Python code, which is a cleaner and safer solution to handle credentials.
# Creating the Crawler Script
On this a part of the mission, we’ll construct the Python script that crawls a documentation web site, extracts every web page in Markdown format, cleans the content material, and saves it domestically as particular person information. We are going to create the mission folder, add a Python file, after which write the code step-by-step so it’s simple to comply with and check.
First, create a mission folder on your crawler. Inside that folder, create a brand new Python file named crawl_docs_with_olostep.py.
Now we’ll add the code to this file one part at a time. This makes it simpler to know what every a part of the script does and the way the total crawler works collectively.
// Defining the Crawl Settings
Begin by importing the required libraries. Then outline the primary crawl settings, such because the beginning URL, crawl depth, web page restrict, embrace and exclude guidelines, and the output folder the place the Markdown information will probably be saved. These values management how a lot of the documentation website will get crawled and the place the outcomes are saved.
import os
import re
from pathlib import Path
from urllib.parse import urlparse
from dotenv import load_dotenv
from tqdm import tqdm
from olostep import Olostep
START_URL = "https://docs.olostep.com/"
MAX_PAGES = 10
MAX_DEPTH = 1
INCLUDE_URLS = [
"/**"
]
EXCLUDE_URLS = []
OUTPUT_DIR = Path("olostep_docs_output")
// Making a Helper Operate to Generate Secure File Names
Every crawled web page must be saved as its personal Markdown file. To do this, we want a helper perform that converts a URL right into a clear and filesystem-safe file title. This avoids issues with slashes, symbols, and different characters that don’t work nicely in file names.
def slugify_url(url: str) -> str:
parsed = urlparse(url)
path = parsed.path.strip("https://www.kdnuggets.com/")
if not path:
path = "index"
filename = re.sub(r"[^a-zA-Z0-9/_-]+", "-", path)
filename = filename.substitute("https://www.kdnuggets.com/", "__").strip("-_")
return f"{filename or 'web page'}.md"
// Making a Helper Operate to Save Markdown Recordsdata
Subsequent, add helper capabilities to course of the extracted content material earlier than saving it.
The primary perform cleans the Markdown by eradicating further interface textual content, repeated clean strains, and undesirable web page components comparable to suggestions prompts. This helps maintain the saved information centered on the precise documentation content material.
def clean_markdown(markdown: str) -> str:
textual content = markdown.substitute("rn", "n").strip()
textual content = re.sub(r"[s*u200b?s*](#.*?)", "", textual content, flags=re.DOTALL)
strains = [line.rstrip() for line in text.splitlines()]
start_index = 0
for index in vary(len(strains) - 1):
title = strains[index].strip()
underline = strains[index + 1].strip()
if title and underline and set(underline) == {"="}:
start_index = index
break
else:
for index, line in enumerate(strains):
if line.lstrip().startswith("# "):
start_index = index
break
strains = strains[start_index:]
for index, line in enumerate(strains):
if line.strip() == "Was this web page useful?":
strains = strains[:index]
break
cleaned_lines: checklist[str] = []
for line in strains:
stripped = line.strip()
if stripped in {"Copy web page", "YesNo", "⌘I"}:
proceed
if not stripped and cleaned_lines and never cleaned_lines[-1]:
proceed
cleaned_lines.append(line)
return "n".be part of(cleaned_lines).strip()
The second perform saves the cleaned Markdown into the output folder and provides the supply URL on the high of the file. There may be additionally a small helper perform to clear outdated Markdown information earlier than saving a brand new crawl end result.
def save_markdown(output_dir: Path, url: str, markdown: str) -> None:
output_dir.mkdir(dad and mom=True, exist_ok=True)
filepath = output_dir / slugify_url(url)
content material = f"""---
source_url: {url}
---
{markdown}
"""
filepath.write_text(content material, encoding="utf-8")
There may be additionally a small helper perform to clear outdated Markdown information earlier than saving a brand new crawl end result.
def clear_output_dir(output_dir: Path) -> None:
if not output_dir.exists():
return
for filepath in output_dir.glob("*.md"):
filepath.unlink()
// Creating the Predominant Crawler Logic
That is the primary a part of the script. It masses the API key from the .env file, creates the Olostep shopper, begins the crawl, waits for it to complete, retrieves every crawled web page as Markdown, cleans the content material, and saves it domestically.
This part ties every little thing collectively and turns the person helper capabilities right into a working documentation crawler.
def principal() -> None:
load_dotenv()
api_key = os.getenv("OLOSTEP_API_KEY")
if not api_key:
elevate RuntimeError("Lacking OLOSTEP_API_KEY in your .env file.")
shopper = Olostep(api_key=api_key)
crawl = shopper.crawls.create(
start_url=START_URL,
max_pages=MAX_PAGES,
max_depth=MAX_DEPTH,
include_urls=INCLUDE_URLS,
exclude_urls=EXCLUDE_URLS,
include_external=False,
include_subdomain=False,
follow_robots_txt=True,
)
print(f"Began crawl: {crawl.id}")
crawl.wait_till_done(check_every_n_secs=5)
pages = checklist(crawl.pages())
clear_output_dir(OUTPUT_DIR)
for web page in tqdm(pages, desc="Saving pages"):
attempt:
content material = web page.retrieve(["markdown"])
markdown = getattr(content material, "markdown_content", None)
if markdown:
save_markdown(OUTPUT_DIR, web page.url, clean_markdown(markdown))
besides Exception as exc:
print(f"Didn't retrieve {web page.url}: {exc}")
print(f"Executed. Recordsdata saved in: {OUTPUT_DIR.resolve()}")
if __name__ == "__main__":
principal()
Be aware: The complete script is offered right here: kingabzpro/web-crawl-olostep, an online crawler and starter net app constructed with Olostep.
// Testing the Internet Crawling Script
As soon as the script is full, run it out of your terminal:
python crawl_docs_with_olostep.py
Because the script runs, you will note the crawler course of the pages and save them one after the other as Markdown information in your output folder.
After the crawl finishes, open the saved information to examine the extracted content material. It is best to see clear, readable Markdown variations of the documentation pages.
At that time, your documentation content material is able to use in AI workflows comparable to search, retrieval, or agent-based techniques.
# Creating the Olostep Internet Crawling Internet Software
On this a part of the mission, we’ll construct a easy net utility on high of the crawler script. As a substitute of modifying the Python file each time, this utility provides you a better solution to enter a documentation URL, select crawl settings, run the crawl, and preview the saved Markdown information in a single place.
The frontend code for this utility is offered in app.py within the repository: web-crawl-olostep/app.py.
This utility does a number of helpful issues:
- Allows you to enter a beginning URL for the crawl
- Allows you to set the utmost variety of pages to crawl
- Allows you to management crawl depth
- Allows you to add embrace and exclude URL patterns
- Runs the backend crawler immediately from the interface
- Saves the crawled pages right into a folder primarily based on the URL
- Reveals all saved Markdown information in a dropdown
- Previews every Markdown file immediately inside the appliance
- Allows you to clear earlier crawl outcomes with one button
To start out the appliance, run:
After that, Gradio will begin a neighborhood net server and supply a hyperlink like this:
* Operating on native URL: http://127.0.0.1:7860
* To create a public hyperlink, set `share=True` in `launch()`.
As soon as the appliance is operating, open the native URL in your browser. In our instance, we gave the appliance the Claude Code documentation URL and requested it to crawl 50 pages with a depth of 5.
Once you click on Run Crawl, the appliance passes your settings to the backend crawler and begins the crawl. Within the terminal, you possibly can watch the progress as pages are crawled and saved one after the other.
After the crawl finishes, the output folder will comprise the saved Markdown information. On this instance, you’ll see that fifty information have been added.
The dropdown within the utility is then up to date mechanically, so you possibly can open any saved file and preview it immediately within the net interface as correctly formatted Markdown.
This makes the crawler a lot simpler to make use of. As a substitute of adjusting values in code each time, you possibly can check totally different documentation websites and crawl settings by way of a easy interface. That additionally makes the mission simpler to share with different individuals who might not wish to work immediately in Python.
# Closing Takeaway
Internet crawling will not be solely about amassing pages from a web site. The true problem is popping that content material into clear, structured information that an AI system can truly use. On this mission, we used a easy Python script and a Gradio utility to make that course of a lot simpler.
Simply as importantly, the workflow is quick sufficient for actual use. In our instance, crawling 50 pages with a depth of 5 took solely round 50 seconds, which reveals that you would be able to put together documentation information shortly with out constructing a heavy pipeline.
This setup may transcend a one-time crawl. You’ll be able to schedule it to run every single day with cron or Activity Scheduler, and even replace solely the pages which have modified. That retains your documentation recent whereas utilizing solely a small variety of credit.
For groups that want this type of workflow to make enterprise sense, Olostep is constructed with that in thoughts. It’s considerably extra inexpensive than constructing or sustaining an inner crawling answer, and at the very least 50% cheaper than comparable options in the marketplace.
As your utilization grows, the price per request continues to lower, which makes it a sensible alternative for bigger documentation pipelines. That mixture of reliability, scalability, and robust unit economics is why a few of the fastest-growing AI-native startups depend on Olostep to energy their information infrastructure.
Abid Ali Awan (@1abidaliawan) is an authorized information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students fighting psychological sickness.

















{kind=link}