


I loved studying this paper, not as a result of I’ve met a few of the authors earlier than🫣, however as a result of it felt obligatory. Many of the papers I’ve written about to date have made waves within the broader ML group, which is nice. This one, although, is unapologetically African (i.e. it solves a really African drawback), and I feel each African ML researcher, particularly these fascinated about speech, must learn it.
AccentFold tackles a selected challenge many people can relate to: present Asr methods simply don’t work nicely for African-accented English. And it’s not for lack of attempting.
Most present approaches use methods like multitask studying, area adaptation, or high-quality tuning with restricted information, however all of them hit the identical wall: African accents are underrepresented in datasets, and gathering sufficient information for each accent is dear and unrealistic.
Take Nigeria, for instance. We have now a whole bunch of native languages, and many individuals develop up talking multiple. So once we converse English, the accent is formed by how our native languages work together with it — by means of pronunciation, rhythm, and even switching mid-sentence. Throughout Africa, this solely will get extra advanced.
As a substitute of chasing extra information, this paper affords a wiser workaround: it introduces AccentFold, a way that learns accent Embeddings from over 100 African accents. These embeddings seize deep linguistic relationships (phonological, syntactic, morphological), and assist ASR methods generalize to accents they’ve by no means seen.
That concept alone makes this paper such an necessary contribution.
Associated Work
One factor I discovered attention-grabbing on this part is how the authors positioned their work inside current advances in probing language fashions. Earlier analysis has proven that pre skilled speech fashions like DeepSpeech and XLSR already seize linguistic or accent particular info of their embeddings, even with out being explicitly skilled for it. Researchers have used this to investigate language variation, detect dialects, and enhance ASR methods with restricted labeled information.
AccentFold builds on that concept however takes it additional. Essentially the most intently associated work additionally used mannequin embeddings to assist accented ASR, however AccentFold differs in two necessary methods.
- First, slightly than simply analyzing embeddings, the authors use them to information the collection of coaching subsets. This helps the mannequin generalize to accents it has not seen earlier than.
- Second, they function at a a lot bigger scale, working with 41 African English accents. That is almost twice the dimensions of earlier efforts.
The Dataset

The authors used AfriSpeech 200, a Pan African speech corpus with over 200 hours of audio, 120 accents, and greater than 2,000 distinctive audio system. One of many authors of this paper additionally helped construct the dataset, which I feel is absolutely cool. Based on them, it’s the most numerous dataset of African accented English out there for ASR to date.
What stood out to me was how the dataset is break up. Out of the 120 accents, 41 seem solely within the take a look at set. This makes it best for evaluating zero shot generalization. For the reason that mannequin is rarely skilled on these accents, the take a look at outcomes give a transparent image of how nicely it adapts to unseen accents.
What AccentFold Is
Like I discussed earlier, AccentFold is constructed on the concept of utilizing realized accent embeddings to information adaptation. Earlier than going additional, it helps to clarify what embeddings are. Embeddings are vector representations of advanced information. They seize construction, patterns, and relationships in a means that lets us evaluate completely different inputs — on this case, completely different accents. Every accent is represented as a degree in a excessive dimensional area, and accents which might be linguistically or geographically associated are usually shut collectively.
What makes this convenient is that AccentFold doesn’t want express labels to know which accents are comparable. The mannequin learns that by means of the embeddings, which permits it to generalize even to accents it has not seen throughout coaching.
How AccentFold Works
The best way it really works is pretty easy. AccentFold is constructed on high of a big pre skilled speech mannequin referred to as XLSR. As a substitute of coaching it on only one job, the authors use multitask studying, which suggests the mannequin is skilled to do a number of various things without delay utilizing the identical enter. It has three heads:
- An ASR head for Speech Recognition, changing speech to textual content. That is skilled utilizing CTC loss, which helps match audio to the right phrase sequence.
- An accent classification head for predicting the speaker’s accent, skilled with cross entropy loss.
- A area classification head for figuring out whether or not the audio is medical or basic, additionally skilled with cross entropy however in a binary setting.
Every job helps the mannequin study higher accent representations. For instance, attempting to categorise accents teaches the mannequin to acknowledge how folks converse in a different way, which is crucial for adapting to new accents.
After coaching, the mannequin creates a vector for every accent by averaging the encoder output. That is referred to as imply pooling, and the result’s the accent embedding.
When the mannequin is requested to transcribe speech from a brand new accent it has not seen earlier than, it finds accents with comparable embeddings and makes use of their information to high-quality tune the ASR system. So even with none labeled information from the goal accent, the mannequin can nonetheless adapt. That’s what makes AccentFold work in zero shot settings.
What Data Does AccentFold Seize
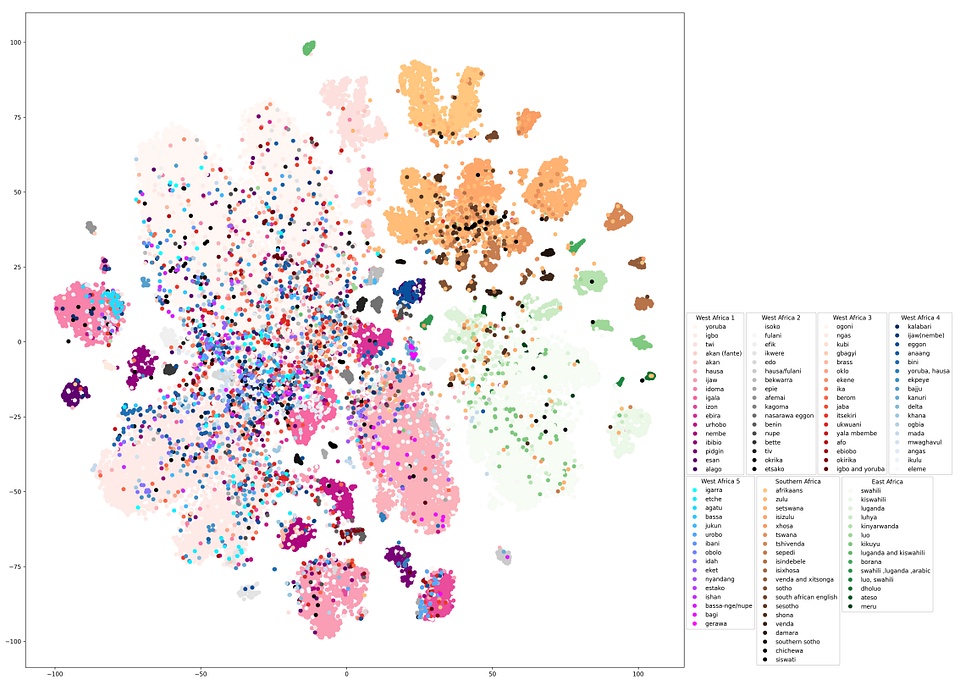
This part of the paper seems at what the accent embeddings are literally studying. Utilizing a collection of tSNE plots, the authors discover whether or not AccentFold captures linguistic, geographical, and sociolinguistic construction. And actually, the visuals converse for themselves.
- Clusters Kind, However Not Randomly

In Determine 2, every level is an accent embedding, coloured by area. You instantly discover that the factors are usually not scattered randomly. Accents from the identical area are likely to cluster. For instance, the pinkish cluster on the left represents West African accents like Yoruba, Igbo, Hausa, and Twi. On the higher proper, the orange cluster represents Southern African accents like Zulu, Xhosa, and Tswana.
What issues isn’t just that clusters kind, however how tightly they do. Some are dense and compact, suggesting inner similarity. Others are extra unfold out. South African Bantu accents are grouped very intently, which suggests sturdy inner consistency. West African clusters are broader, seemingly reflecting the variation in how West African English is spoken, even inside a single nation like Nigeria.
2. Geography Is Not Simply Visible. It Is Spatial

Determine 3 exhibits embeddings labeled by nation. Nigerian accents, proven in orange, kind a dense core. Ghanaian accents in blue are close by, whereas Kenyan and Ugandan accents seem removed from them in vector area.
There’s nuance too. Rwanda, which has each Francophone and Anglophone influences, falls between clusters. It doesn’t totally align with East or West African embeddings. This displays its blended linguistic identification, and exhibits the mannequin is studying one thing actual.
3. Twin Accents Fall Between

Determine 4 exhibits embeddings for audio system who reported twin accents. Audio system who recognized as Igbo and Yoruba fall between the Igbo cluster in blue and the Yoruba cluster in orange. Much more distinct combos like Yoruba and Hausa land in between.
This exhibits that AccentFold isn’t just classifying accents. It’s studying how they relate. The mannequin treats accent as one thing steady and relational, which is what a very good embedding ought to do.
4. Linguistic Households Are Strengthened and Generally Challenged
In Determine 9, the embeddings are coloured by language households. Most Niger Congo languages kind one giant cluster, as anticipated. However in Determine 10, the place accents are grouped by household and area, one thing surprising seems. Ghanaian Kwa accents are positioned close to South African Bantu accents.
This challenges frequent assumptions in classification methods like Ethnologue. AccentFold could also be selecting up on phonological or morphological similarities that aren’t captured by conventional labels.
5. Accent Embeddings Can Assist Repair Labels
The authors additionally present that the embeddings can clear up mislabeled or ambiguous information. For instance:
- Eleven Nigerian audio system labeled their accent as English, however their embeddings clustered with Berom, an area accent.
- Twenty audio system labeled their accent as Pidgin, however had been positioned nearer to Ijaw, Ibibio, and Efik.
This implies AccentFold is just not solely studying which accents exist, but in addition correcting noisy or obscure enter. That’s particularly helpful for actual world datasets the place customers typically self report inconsistently.
Evaluating AccentFold: Which Accents Ought to You Choose
This part is one in every of my favorites as a result of it frames a really sensible drawback. If you wish to construct an ASR system for a brand new accent however don’t have information for that accent, which accents must you use to coach your mannequin?
Let’s say you’re concentrating on the Afante accent. You haven’t any labeled information from Afante audio system, however you do have a pool of speech information from different accents. Let’s name that pool A. Because of useful resource constraints like time, price range, and compute, you’ll be able to solely choose s accents from A to construct your high-quality tuning dataset. Of their experiments, they repair s as 20, that means 20 accents are used to coach every goal accent. So the query turns into: which 20 accents must you select to assist your mannequin carry out nicely on Afante?
Setup: How They Consider
To check this, the authors simulate the setup utilizing 41 goal accents from the Afrispeech 200 dataset. These accents don’t seem within the coaching or improvement units. For every goal accent, they:
- Choose a subset of s accents from A utilizing one in every of three methods
- Tremendous tune the pre skilled XLS R mannequin utilizing solely information from these s accents
- Consider the mannequin on a take a look at set for that concentrate on accent
- Report the Phrase Error Price, or WER, averaged over 10 epochs
The take a look at set is identical throughout all experiments and contains 108 accents from the Afrispeech 200 take a look at break up. This ensures a good comparability of how nicely every technique generalizes to new accents.
The authors take a look at three methods for choosing coaching accents:
- Random Sampling: Choose s accents randomly from A. It’s easy however unguided.
- GeoProx: Choose accents based mostly on geographical proximity. They use geopy to search out nations closest to the goal and select accents from there.
- AccentFold: Use the realized accent embeddings to pick the s accents most much like the goal in illustration area.
Desk 1 exhibits that AccentFold outperforms each GeoProx and Random sampling throughout all 41 goal accents.

This leads to a few 3.5 % absolute enchancment in WER in comparison with random choice, which is significant for low useful resource ASR. AccentFold additionally has decrease variance, that means it performs extra persistently. Random sampling has the very best variance, making it much less dependable.
Does Extra Information Assist
The paper asks a traditional machine studying query: does efficiency maintain bettering as you add extra coaching accents?

Determine 5 exhibits that WER improves as s will increase, however solely up to a degree. After about 20 to 25 accents, the efficiency ranges off.
So extra information helps, however solely to a degree. What issues most is utilizing the precise information.
Key Takeaways
- AccentFold addresses an actual African drawback: ASR methods typically fail on African accented English as a result of restricted and imbalanced datasets.
- The paper introduces accent embeddings that seize linguistic and geographic similarities while not having labeled information from the goal accent.
- It formalizes a subset choice drawback: given a brand new accent with no information, which different accents must you prepare on to get the very best outcomes?
- Three methods are examined: random sampling, geographical proximity, and AccentFold utilizing embedding similarity.
- AccentFold outperforms each baselines, with decrease Phrase Error Charges and extra constant outcomes
- Embedding similarity beats geography. The closest accents in embedding area are usually not at all times geographically shut, however they’re extra useful.
- Extra information helps solely up to a degree. Efficiency improves at first, however ranges off. You do not want all the info, simply the precise accents.
- Embeddings will help clear up noisy or mislabeled information, bettering dataset high quality.
- Limitation: outcomes are based mostly on one pre skilled mannequin. Generalization to different fashions or languages is just not examined.
- Whereas this work focuses on African accents, the core methodology — studying from what fashions already know — may encourage extra basic approaches to adaptation in low-resource settings.
Supply Notice:
This text summarizes findings from the paper AccentFold: A Journey by means of African Accents for Zero Shot ASR Adaptation to Goal Accents by Owodunni et al. (2024). Figures and insights are sourced from the unique paper, out there at https://arxiv.org/abs/2402.01152.

















{kind=link}