




# Introduction
A mannequin that claims it’s 90% assured must be proper 90% of the time. When that relationship breaks down, you get a miscalibration downside. The mannequin’s scores cease telling you something helpful about reliability.
For massive language fashions (LLMs), miscalibration is widespread. A 2024 NAACL survey discovered that confidence scores diverge from precise correctness charges throughout factual QA, code era, and reasoning duties.
One other examine on biomedical fashions discovered imply calibration scores starting from solely 23.9% to 46.6% throughout all examined fashions. The hole is constant.
The usual answer in classical machine studying is post-hoc recalibration: match a easy perform on a held-out validation set to map uncooked confidence scores to better-calibrated possibilities.
Three strategies dominate: temperature scaling, Platt scaling, and isotonic regression. All three had been designed for discriminative classifiers, and making use of them to LLMs requires care.
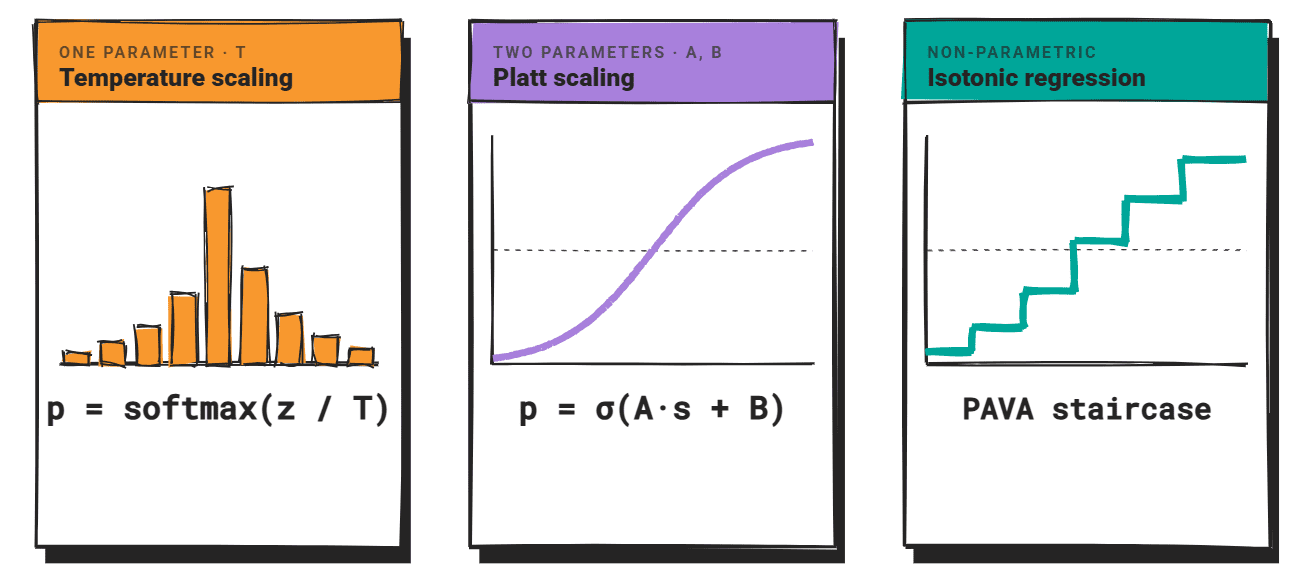
# Measuring Calibration
The dominant metric is Anticipated Calibration Error (ECE). It teams predictions into confidence bins, computes the hole between imply confidence and the noticed accuracy in every bin, and averages throughout bins weighted by measurement. ECE = 0 is ideal calibration.
A reliability diagram plots confidence in opposition to accuracy. A wonderfully calibrated mannequin sits on the diagonal. An overconfident mannequin sits beneath it: the curve reveals excessive confidence, however accuracy would not sustain.
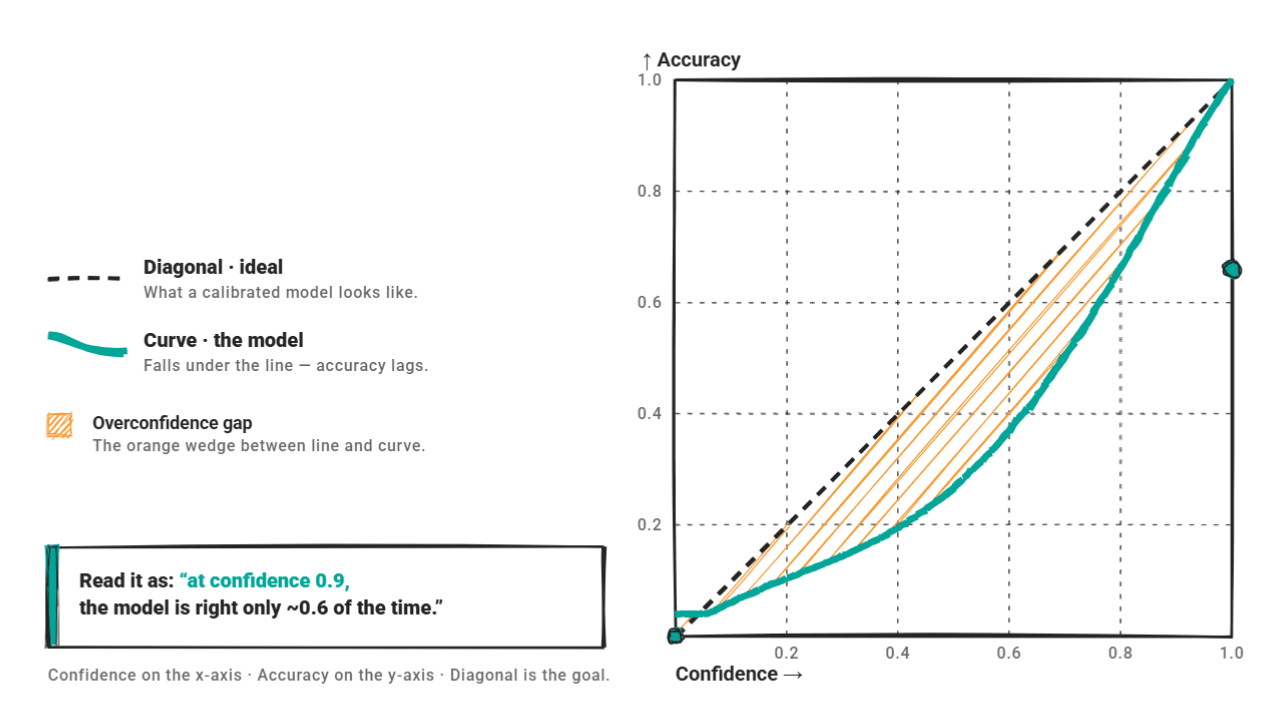
A 2025 analysis of GPT-4o-mini as a textual content classifier discovered that 66.7% of its errors occurred at over 80% confidence — the canonical overconfidence sample.
ECE alone is more and more considered as inadequate. A analysis paper recommends pairing ECE with the Brier rating, overconfidence charges, and reliability diagrams collectively. A single quantity obscures significant variation in the place and the way a mannequin misbehaves.
# Why LLMs Complicate the Normal Setup
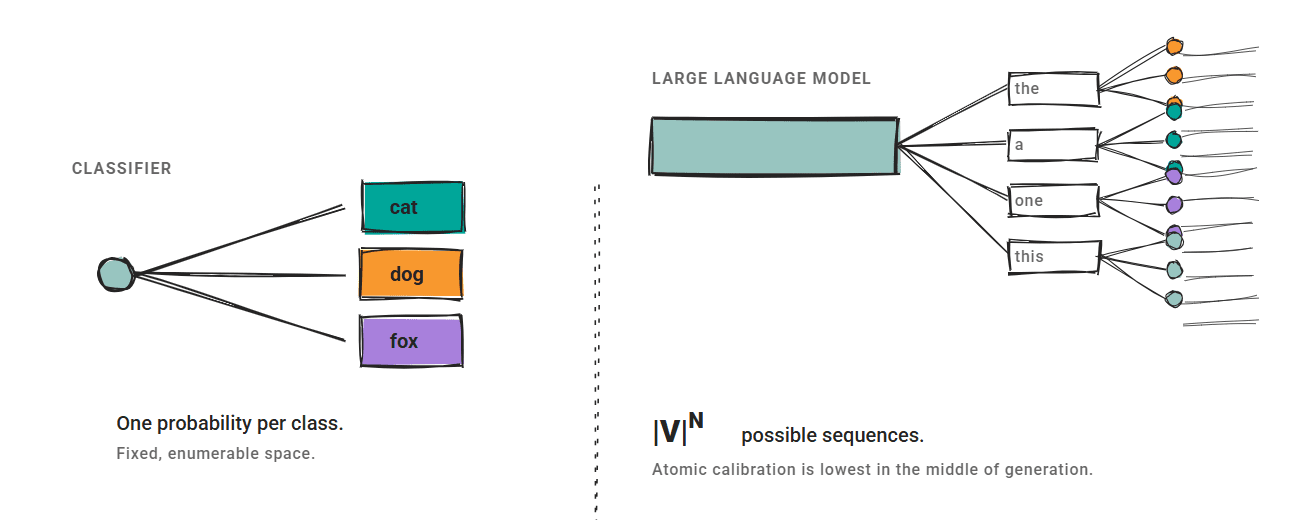
The three strategies we cowl assume a set output house. A classifier produces one chance per class, and calibration maps them to raised estimates.
LLMs do not work this fashion.
4 problems matter right here.
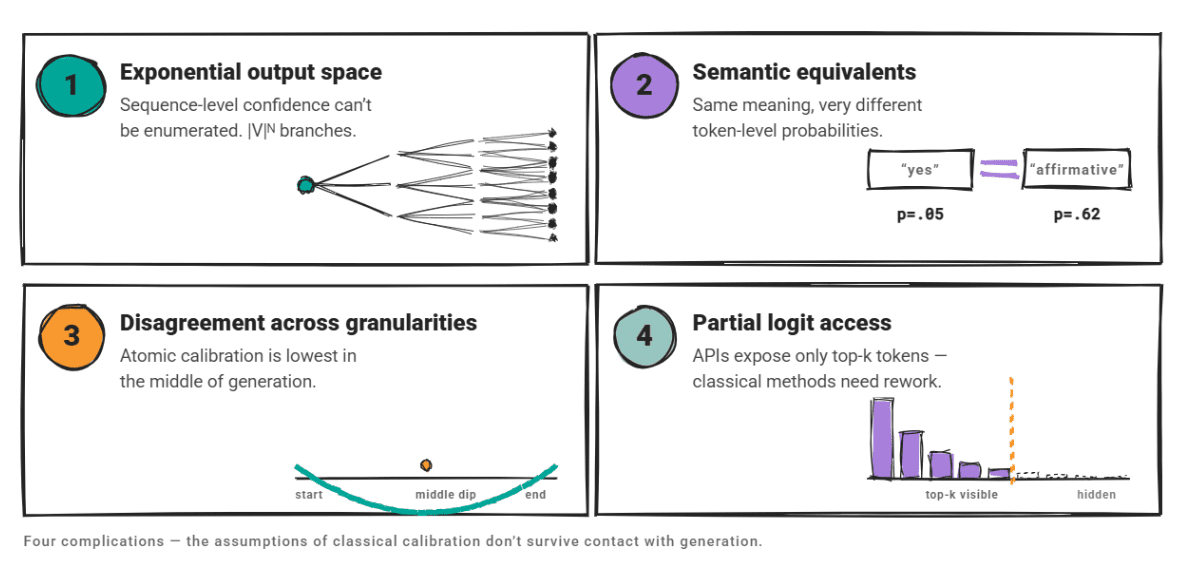
The output house is exponentially massive: sequence-level confidence cannot be enumerated. Semantically equal outputs could have very completely different token-level possibilities. Confidence disagrees throughout granularities; a analysis paper on atomic calibration confirmed that generative fashions exhibit their lowest common confidence in the course of era, not in the beginning or finish.
And plenty of LLMs solely expose top-k token possibilities by their API, so classical calibration approaches that depend on full logit entry want modification.
# Making use of Temperature Scaling
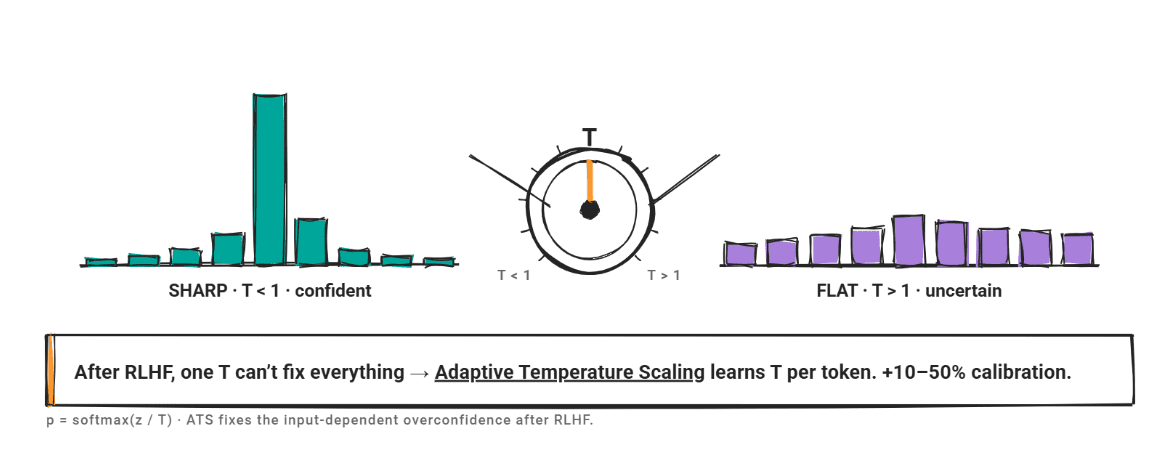
Temperature scaling divides the logit vector by a scalar T earlier than making use of softmax. When T > 1, the distribution flattens and confidence drops. When T < 1, the distribution sharpens and confidence rises.
T is match on a held-out validation set by minimizing unfavourable log-likelihood. The tactic provides one parameter, preserves prediction rankings, and is reasonable to compute.
The unique formulation focused DenseNet picture classifiers. For LLMs, temperature controls the chance distribution over the vocabulary at every decoding step, so the identical logic applies.
The issue is Reinforcement Studying from Human Suggestions (RLHF). Submit-RLHF fashions develop input-dependent overconfidence: the diploma of miscalibration varies throughout inputs, and a single T cannot account for that variation.
Common ECE scores above 0.377 have been documented for fashions like GPT-3 in verbalized confidence duties, and a 2025 survey confirms that RLHF-tuned fashions persistently overestimate confidence throughout the board.
Adaptive Temperature Scaling (ATS) addresses this immediately. ATS predicts a per-token temperature from token-level hidden options, match on a supervised fine-tuning dataset, as a substitute of utilizing a single mounted T. Researchers confirmed that ATS improved calibration by 10–50% with out hurting activity efficiency. For any RLHF-tuned mannequin, ATS is a stronger baseline than normal temperature scaling.
Normal temperature scaling nonetheless works effectively for base fashions earlier than RLHF. When miscalibration is roughly uniform throughout inputs, a single T is usually sufficient to appropriate systematic over- or underconfidence.
The issue is restricted to post-RLHF fashions, the place input-dependent overconfidence means a single T cannot appropriate all inputs.
# Making use of Platt Scaling
Platt scaling suits a logistic perform over the uncalibrated scores: p = σ(A·s + B), the place A and B are discovered from a held-out validation set with binary correctness labels.
The sigmoid form offers a parametric mapping with two free parameters.
Platt scaling was initially developed for SVMs however generalizes to any system that produces a scalar confidence rating.
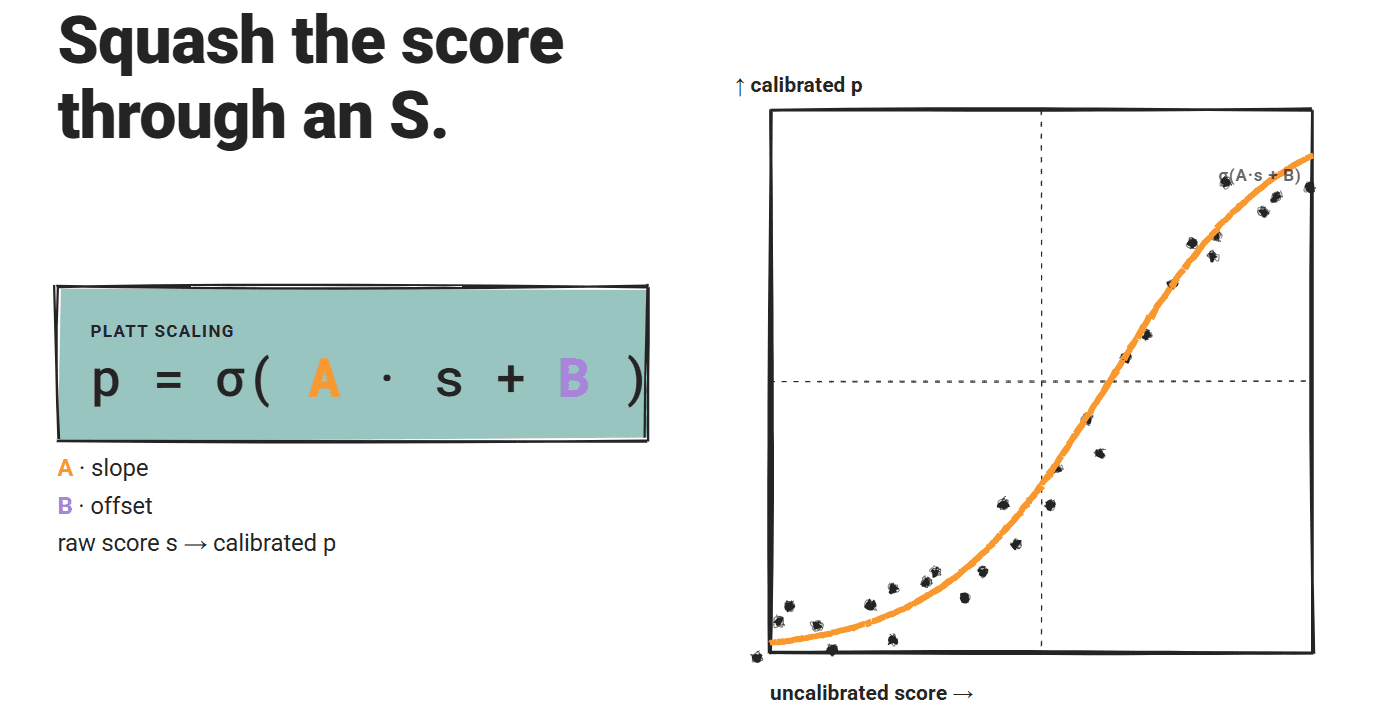
The 2-parameter match can also be data-efficient in comparison with isotonic regression: it might probably produce usable estimates from a smaller calibration set, which issues in deployment contexts the place labeled correctness knowledge is proscribed.
In LLM contexts, Platt scaling operates over sequence-level or token-level confidence scores.
A paper on LLM-generated code confidence discovered that Platt scaling produced better-calibrated outputs than uncalibrated scores. One other examine on LLMs for text-to-SQL launched Multivariate Platt Scaling (MPS), extending single-variable Platt scaling to mix sub-clause frequency scores throughout a number of generated samples — persistently outperforming single-score baselines.
Two limitations are documented. First, world sequence-level Platt scaling is just too coarse for duties the place correctness relies on native edit choices: a single sigmoid mapping cannot seize sample-dependent miscalibration patterns.
In addition to, Platt scaling can degrade correct scoring efficiency for sturdy fashions.
# Making use of Isotonic Regression
Isotonic regression takes the non-parametric route.
It learns a piecewise-constant, monotonically non-decreasing mapping from uncalibrated scores to calibrated possibilities utilizing the Pool Adjoining Violators Algorithm (PAVA). There isn’t any assumed form for the calibration perform, which makes it extra versatile than Platt scaling when the confidence-accuracy relationship is not sigmoid-shaped.
The piecewise-constant output adapts to any monotone form: linear, stepped, or concave. That adaptability is the primary purpose isotonic regression tends to outperform Platt scaling in empirical comparisons.
The associated fee is overfitting threat on small calibration units. The mapping solely generalizes effectively when there’s sufficient knowledge to constrain it.
Empirically, isotonic regression outperforms Platt scaling.
A rigorous comparability throughout a number of datasets and architectures discovered that isotonic regression beat Platt scaling on ECE and Brier rating with statistical significance, utilizing paired t-tests with Bonferroni correction at α = 0.003.
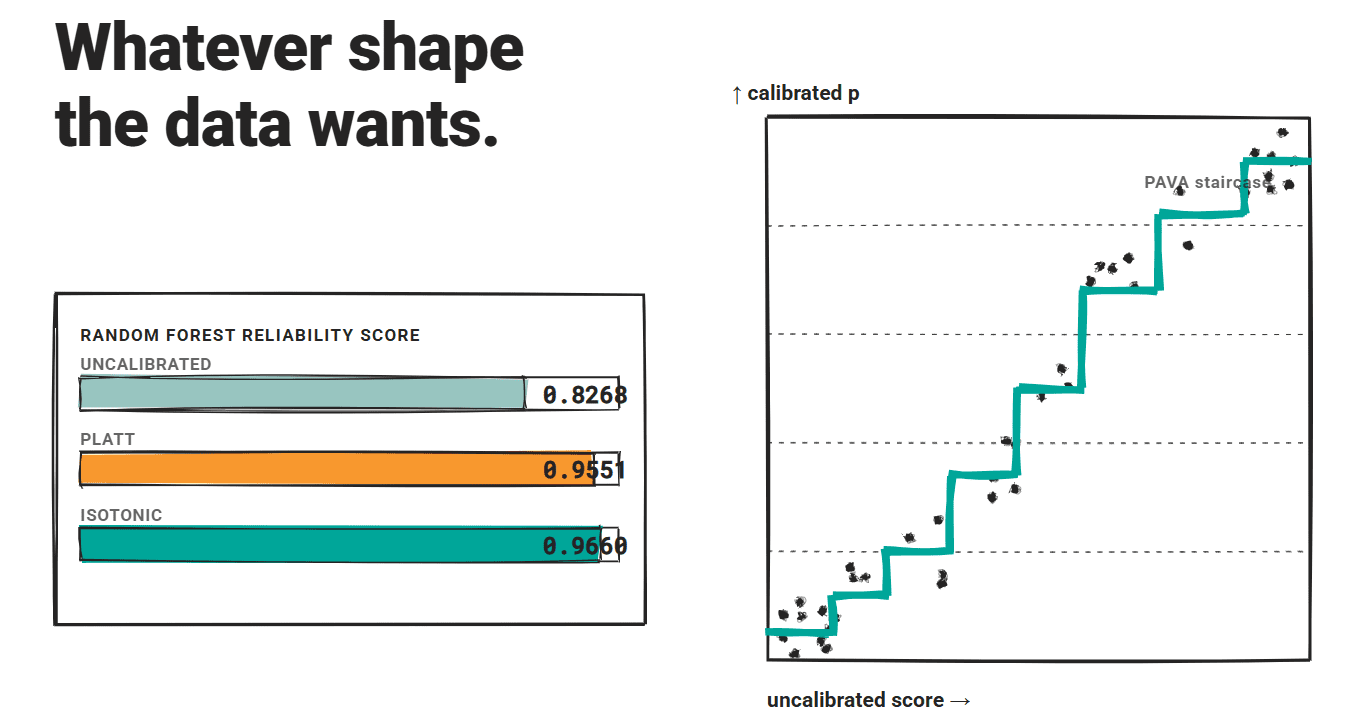
In that examine, a Random Forest baseline improved from a reliability rating of 0.8268 uncalibrated, to 0.9551 with Platt scaling, to 0.9660 with isotonic regression. Each strategies may degrade correct scoring efficiency for sturdy fashions, however the isotonic edge held persistently.
For LLM multiclass settings, it has been proven that normal isotonic regression might be improved additional with normalization-aware extensions, persistently outperforming each OvR isotonic regression and normal parametric strategies on NLL and ECE.
The information requirement is the binding constraint. Isotonic regression’s benefit is actual, but it surely would not switch to low-data deployment situations.
# What the Literature Leaves Open
Three gaps are value flagging earlier than deploying any of those strategies.
The RLHF interplay has been studied just for temperature scaling. How Platt scaling and isotonic regression carry out on post-RLHF fashions hasn’t been systematically examined. ATS exists as a result of normal temperature scaling wanted an express repair for this case. Whether or not the opposite two strategies want comparable extensions is an open query.
Most direct comparisons of all three strategies come from the overall machine studying calibration literature. LLM-specific benchmarks that take a look at all three head-to-head are uncommon. The ICSE 2025 code calibration paper is without doubt one of the few, and its scope is proscribed to code era.
Calibration set measurement is an actual deployment constraint. Isotonic regression outcomes from papers assume datasets massive sufficient to constrain the mapping. In manufacturing with restricted labeled examples, the hole between isotonic regression and Platt scaling could shut or reverse.
# Conclusion
Temperature scaling is the suitable start line for many groups. For base fashions with out RLHF, a single T usually does sufficient.
For RLHF-tuned fashions, change to ATS: the per-token temperature handles the input-dependent overconfidence {that a} world scalar misses.
Platt scaling is the sensible selection when the calibration set is small or when calibration wants to fit into a bigger pipeline. It is data-efficient and simple to implement. The limitation is scope: it might probably’t seize miscalibration that varies throughout samples, and it tends to degrade efficiency for sturdy fashions.
Isotonic regression has the strongest empirical observe file of the three. Use it when the calibration set is massive sufficient to constrain the mapping with out overfitting, and pair it with normalization-aware extensions in multiclass settings.
The choice that comes earlier than all of those is what “confidence” means for the duty. Token chance, sequence chance, verbalized confidence, and consistency throughout samples may give completely different values for a similar output. A calibration methodology utilized to the improper sign would not enhance reliability. Getting that definition proper is the prerequisite for any of the strategies above to work.
Nate Rosidi is a knowledge scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the newest developments within the profession market, offers interview recommendation, shares knowledge science tasks, and covers every little thing SQL.

















{kind=link}