


assumes the supply of absolute labels. For instance, an occasion belongs to a category, a doc receives a rating, an remark is assigned a likelihood, a product is rated on a set scale. In apply, nonetheless, human judgment usually seems in a extra native and comparative type. Folks might not know whether or not a solution deserves 7.4 out of 10, however they will usually say which of two solutions is healthier. They might hesitate to assign an absolute high quality rating to a candidate, however they will say which of two candidates appears stronger. In lots of actual programs, comparability is far simpler than calibration.
That is the setting by which the Bradley-Terry mannequin turns into particularly helpful by providing a mathematically clear method to be taught from pairwise preferences. Fairly than asking for absolute judgments, it begins from easy head-to-head outcomes and makes use of them to deduce a latent ordering over objects to provide a coherent probabilistic rating.

The Core Concept: Every Merchandise Has a Latent Energy
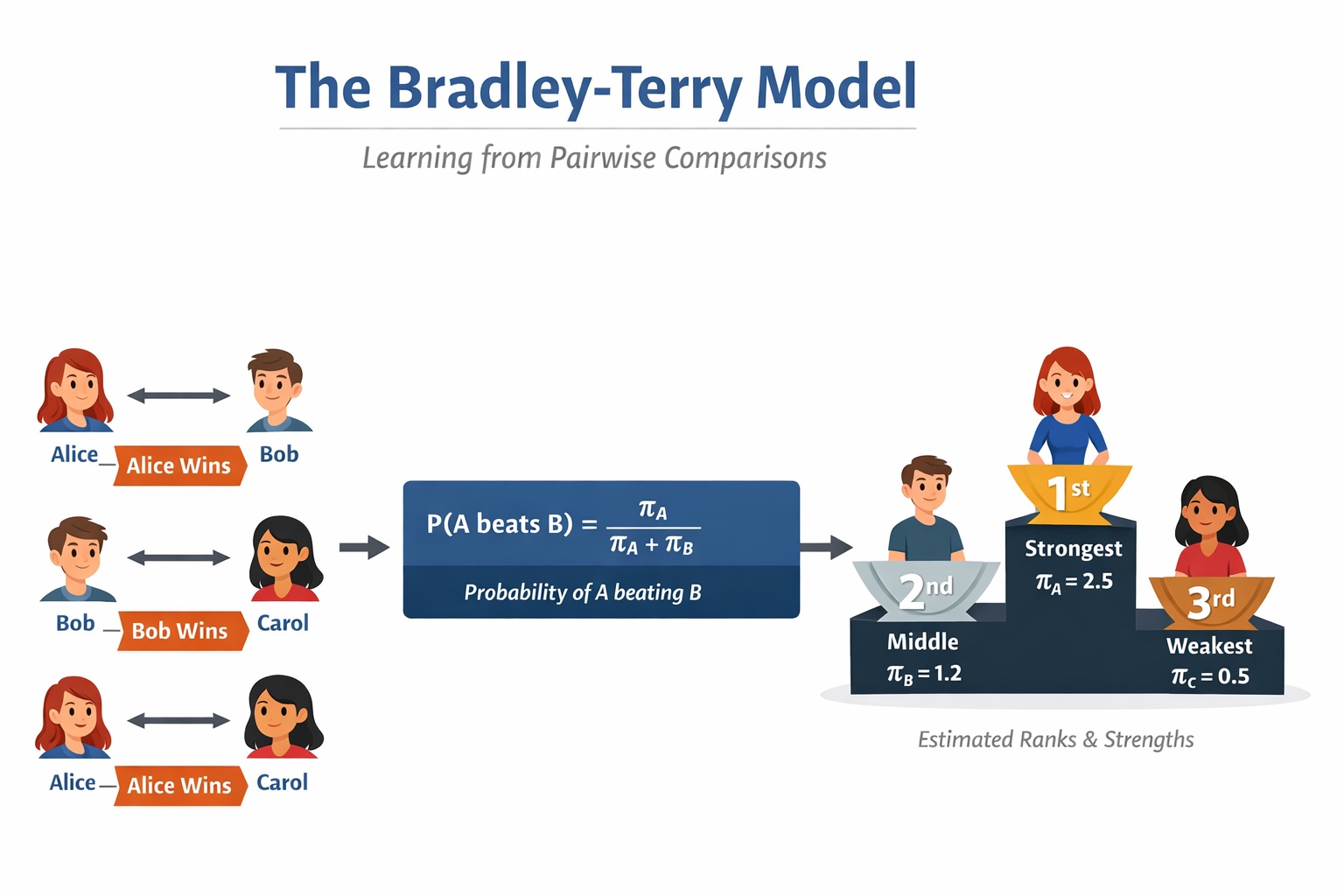
The mannequin begins with a easy assumption. Every merchandise i is related to an unobserved constructive power parameter, written as πᵢ > 0. When merchandise i is in contrast with merchandise j, the likelihood that i is most well-liked to j is outlined as:

and, symmetrically we are able to write:

This manner is kind of engaging as a result of it’s each easy and interpretable. If the 2 objects have equal power, then every has likelihood 1/2 of successful. If πᵢ is far bigger than πⱼ, then i turns into more likely to win. The Bradley Tery mannequin interprets hidden relative strengths into observable pairwise chances.
A second and infrequently extra handy method to write the identical mannequin is to specific every constructive power because the exponential of a real-valued rating:

Substituting this into the likelihood expression yields:

which will also be written as:

This makes an vital reality seen. The likelihood that i beats j relies upon solely on the distinction βᵢ − βⱼ. Bradley-Terry is subsequently carefully associated to logistic modeling. This is identical structural concept that seems in logistic regression. In logistic regression, a binary consequence is modeled by making use of the logistic operate to a linear rating. In Bradley-Terry, the binary consequence is the results of a head-to-head comparability, and the related rating is just the distinction between the 2 latent strengths. Equivalently, the log-odds that i beats j are linear in βᵢ − βⱼ, which makes Bradley-Terry a very pure mannequin for pairwise choice information.
Extra particularly, what issues is just not absolutely the degree of an merchandise’s rating, however its place relative to the opposite merchandise within the comparability.
A Easy Instance
Contemplate three candidate solutions generated by a language mannequin: A, B, and C. Suppose human annotators produce the next preferences:
- A is most well-liked to B
- A is most well-liked to C
- B is most well-liked to C
Even with none numeric scores, a construction is already seen. A seems strongest, B subsequent, and C weakest. The Bradley-Terry mannequin formalizes this instinct by discovering latent strengths that make these noticed outcomes believable underneath the mannequin.
That is the primary conceptual step value noticing. The mannequin doesn’t start with international scores after which derive pairwise outcomes. It does the reverse. It begins with native comparisons and infers the latent scores that finest clarify them.
Becoming the Mannequin From Knowledge
Now suppose that comparisons are repeated many instances throughout a bigger assortment of things. For every ordered pair (i, j), let wᵢⱼ denote the variety of instances that merchandise i beats merchandise j, and let wⱼᵢ denote the variety of instances that j beats i.
The Bradley-Terry mannequin suits the parameters by selecting values of the strengths that make the noticed comparability information as doubtless as attainable. That is performed by most probability estimation.
For a single pair of things i and j, the probability contribution is:

The interpretation is easy. If merchandise i beat merchandise j many instances, then the fitted mannequin ought to assign a excessive likelihood to i beating j. If j additionally gained some comparisons, then the mannequin ought to account for that as properly. The probability rewards parameter settings that place excessive likelihood on the outcomes that have been really noticed.
Throughout all merchandise pairs, the complete chances are obtained by multiplying these phrases collectively. In apply, one works as an alternative with the log-likelihood, as a result of it’s simpler to optimise. The log-likelihood is:

The becoming downside is then to seek out the parameter values that maximise this amount.
A Deeper Take a look at Bradley-Terry Mannequin Becoming
At an intuitive degree, the optimization course of adjusts the latent strengths in order that the mannequin’s predicted chances align with the empirical comparability outcomes.
If an merchandise wins steadily, its power ought to rise. If it loses steadily, its power ought to fall. If two objects cut up their contests roughly evenly, their strengths ought to transfer nearer collectively. These are the casual penalties. The technical mechanism behind them is the gradient of the log-likelihood.
Utilizing the parameterisation πᵢ = exp(βᵢ), the gradient with respect to βᵢ could be written as:

This expression is the central studying sign within the Bradley-Terry mannequin, and it has a really clear interpretation.
- The primary time period, wᵢⱼ, is the variety of wins merchandise i really achieved in opposition to merchandise j.
- The second time period, (wᵢⱼ + wⱼᵢ) P(i ≻ j), is the variety of wins the present mannequin expects merchandise i to realize in opposition to merchandise j.
So the gradient is measuring a discrepancy between two portions: noticed wins and anticipated wins.
Gradient descent adjusts the latent power as follows:
- If merchandise i is successful extra usually than the present mannequin predicts, then the gradient is constructive, and βᵢ ought to improve.
- If merchandise i is successful much less usually than predicted, then the gradient is destructive, and βᵢ ought to lower.
Studying proceeds by repeatedly correcting these discrepancies till the mannequin’s anticipated outcomes are introduced into as shut an alignment as attainable with the noticed information. That is probably the most helpful approach to consider Bradley-Terry becoming. Studying is adjusting the latent strengths till anticipated pairwise behaviour matches empirical pairwise behaviour.
There may be, nonetheless, an vital subtlety of observe with the Bradely Terry mannequin. The mannequin doesn’t establish an absolute scale of high quality. Solely relative strengths matter. If each power parameter is multiplied by the identical constructive fixed c, the pairwise chances don’t change:

This implies the mannequin learns a relative rating construction slightly than an absolute rating in some exterior unit. In apply, one normally fixes the size by imposing a normalisation, resembling setting one β-value to zero or constraining the parameters to sum to a relentless.
From Native Judgments to World Construction
The deeper enchantment of the Bradley-Terry mannequin lies in the best way it converts many native judgments right into a single international illustration. Every particular person comparability says little or no by itself. It tells us solely that, in a single head-to-head contest, one merchandise was most well-liked to a different. But when these native observations are aggregated throughout a dataset, a broader construction begins to emerge. The mannequin reconstructs that construction within the type of latent strengths and pairwise chances.
For this reason Bradley-Terry stays such a helpful mannequin, however continues to be arguably much less well-known within the Knowledge Scientist’s toolkit. It provides a principled bridge between noisy comparative judgments and international probabilistic rating. It respects the truth that human supervision is commonly simpler to acquire in relative slightly than absolute type, and it turns that relative proof into one thing mathematically tractable.
A pure subsequent query is why pairwise comparisons are sometimes extra secure and extra dependable than direct scoring within the first place. That’s the place the sensible enchantment of comparative supervision turns into a lot clearer nonetheless.
Why Pairwise Comparisons Are Usually Higher Than Direct Scores
One of many essential sensible benefits of the Bradley-Terry setting is that pairwise judgments are sometimes simpler for people to make than absolute ones. That is partly a matter of cognitive burden. Asking whether or not reply A is healthier than reply B requires a neighborhood comparability. Asking whether or not reply A deserves a rating of seven.8 out of 10 requires an inside normal, calibration in opposition to prior examples, and a secure interpretation of what the numeric scale is supposed to signify. In lots of domains, persons are significantly better on the former than the latter.
This distinction issues as a result of supervision noise is just not all the similar form. Direct scores usually endure from scale inconsistency. One annotator might use the complete vary from 1 to 10, whereas one other compresses practically all judgments into the interval from 6 to eight. One reviewer might deal with 5 as common, one other as poor. Even the identical individual might rating extra harshly within the morning than within the afternoon. The issue is just not merely disagreement about high quality. It’s disagreement concerning the that means of the size itself.
Pairwise comparisons keep away from a lot of this issue. They don’t require the annotator to anchor a judgment to a world numerical body. They ask just for a relative determination: which of those two objects is healthier? This can be a easier and infrequently extra secure query. In consequence, comparative judgments are steadily much less noisy, simpler to gather persistently, and extra sturdy throughout annotators.
There may be additionally a structural cause that pairwise information is engaging. In lots of actual programs, rating is the true downstream goal. A search engine must order outcomes. A recommender system wants to position higher objects forward of worse ones. A reward mannequin for language era wants to tell apart most well-liked outputs from much less most well-liked ones. In these settings, absolute scores could also be an pointless intermediate abstraction. Pairwise supervision is nearer to the choice downside the system is in the end making an attempt to unravel.
This doesn’t imply pairwise judgments are freed from issue. They are often costly when the variety of objects could be very giant, and so they can include cycles or inconsistencies. One annotator might want A to B, B to C, and but C to A. Totally different annotators might disagree sharply. Even so, pairwise supervision usually stays engaging as a result of it shifts the issue from asking people to offer completely calibrated scores to asking a mannequin to deduce latent construction from native comparative proof.
That’s exactly what Bradley-Terry is designed to do. It takes a group of small, probably noisy, head-to-head outcomes and suits a world probabilistic rating that finest explains them. The mannequin is efficacious not as a result of pairwise judgments are good, however as a result of they’re usually probably the most pure and dependable sign obtainable.
Going Deeper: Identifiability, Curvature, and Optimization
The essential Bradley-Terry mannequin is straightforward to state, however its technical construction turns into extra attention-grabbing as soon as one asks how the parameters are literally estimated and underneath what situations that estimation is properly behaved.
Identifiability
A primary subject is identifiability. Within the parameterization utilizing constructive strengths πᵢ, the chances are unchanged if each parameter is multiplied by the identical constructive fixed. The reason being easy:

relies upon solely on the ratio of the strengths, not on their widespread scale. If each πᵢ is changed by cπᵢ for some c > 0, the chances stay precisely the identical.
The identical subject seems within the log-strength parameterization πᵢ = exp(βᵢ). Including the identical fixed to each βᵢ leaves all pairwise chances unchanged, since solely variations resembling βᵢ − βⱼ matter. The mannequin subsequently has one redundant diploma of freedom.
In apply, that is dealt with by imposing a normalization. Frequent decisions embrace:

or

These constraints don’t change the fitted chances. They merely repair a reference degree in order that the answer turns into distinctive.
There may be additionally a graph-theoretic side to identifiability. If the comparability graph is disconnected, then the relative strengths of things in several linked elements can’t be decided from the information. Extra usually, to estimate a significant international rating, the noticed comparisons should join the objects sufficiently properly. In any other case the information solely identifies separate native rankings inside remoted subsets.
The Log-Probability Once more
Recall the log-likelihood:

That is the target operate we maximize. Its gradient with respect to βᵢ is:

As mentioned earlier, that is noticed wins minus anticipated wins. That provides the gradient a very interesting interpretation. The mannequin will increase an merchandise’s rating when the merchandise wins extra usually than predicted, and reduces it when the merchandise wins much less usually than predicted.
On the optimum, these discrepancies steadiness out in addition to attainable over the complete comparability community.
The Hessian and Curvature
To grasp the geometry of the optimization downside, it helps to look at the second derivatives. For the Bradley-Terry log-likelihood, the diagonal second spinoff takes the shape:

and for i ≠ j, the off-diagonal second spinoff is:

every time objects i and j are in contrast, and 0 in any other case. A number of issues observe from this construction:
- First, the Hessian is destructive semidefinite, which suggests the log-likelihood is concave in β as much as the identifiability subject already mentioned. This is a vital property. It implies that, as soon as the size ambiguity is mounted, the optimization downside has a well-behaved international optimum slightly than many unrelated native maxima.
- Second, the curvature will depend on the time period P(i ≻ j) P(j ≻ i). This amount is largest when the competition is unsure, that’s, when the 2 objects have related power and every has a considerable likelihood of successful. It turns into small when one merchandise is overwhelmingly stronger than the opposite. Intuitively, comparisons which are already nearly deterministic contribute much less native curvature, as a result of the mannequin is already fairly sure about them.
This can be a helpful level to say in a technical article as a result of it connects the arithmetic to the information geometry. Probably the most informative comparisons are sometimes these between objects of roughly related high quality. They’re the contests that present the strongest native sign about relative ordering.
Gradient Ascent
Probably the most direct optimization strategy is gradient ascent. Ranging from an preliminary guess for the parameters, one repeatedly updates:

the place η is the educational price.
As a result of the log-likelihood is concave after normalization, this process is conceptually simple. At every step, the parameters are moved within the path that will increase the match between mannequin expectations and noticed outcomes. In small or medium-sized issues, that is usually completely enough.
That mentioned, plain gradient ascent is just not at all times probably the most environment friendly strategy. Its convergence price will depend on the educational price and on the native curvature of the target. If η is simply too small, studying is sluggish; whether it is too giant, updates might overshoot.
Newton and Second-Order Strategies
As a result of the gradient and Hessian can be found in closed type, Bradley-Terry will also be fitted with Newton or quasi-Newton strategies. A Newton step takes the shape:

the place H is the Hessian matrix and ∇ℓ is the gradient vector.
The benefit of second-order strategies is that they account for curvature instantly. As a substitute of shifting solely in accordance with slope, additionally they use details about how sharply the target bends. This usually yields sooner convergence, particularly close to the optimum.
The downside is computational. Computing and inverting the Hessian could be costly when the variety of objects is giant. For that cause, sensible implementations usually want quasi-Newton strategies or specialised iterative schemes.
MM Updates
One of many traditional becoming procedures for Bradley-Terry is an MM algorithm, the place MM stands for minorization-maximization or majorization-minimization relying on the conference. These strategies substitute the troublesome goal with a less complicated surrogate operate that’s simpler to optimize at every step.
For Bradley-Terry, the MM replace for the constructive strengths could be written in a type resembling:

the place:

is the full variety of wins for merchandise i, and

is the full variety of comparisons between i and j.
This replace has an interesting interpretation. The numerator counts how usually merchandise i really gained. The denominator displays how a lot successful alternative it had underneath the present parameterization. The algorithm repeatedly rescales every power in order that these portions come into higher alignment.
MM strategies are in style for Bradley-Terry as a result of they protect positivity mechanically and infrequently behave stably in apply.
A Statistical Interpretation of the Optimum
The primary-order situation for optimality is very revealing. Setting the gradient to zero offers:

for every merchandise i.
This says that, on the optimum, the full noticed wins of merchandise i equal the full wins anticipated for merchandise i underneath the fitted mannequin. In different phrases, the estimated strengths are these for which the mannequin reproduces the empirical win counts as carefully as attainable in expectation.
That is maybe the cleanest interpretation of Bradley-Terry studying. The mannequin is fitted when its inside probabilistic account of the world is in equilibrium with the comparability information.
Contextual Bradley-Terry: When Energy Will depend on Setting
The usual Bradley-Terry mannequin assigns a single latent power to every merchandise. This can be a helpful simplification, however it is usually an vital limitation. In apply, the power of an merchandise usually will depend on the circumstances of the comparability. A language mannequin might carry out properly on mathematical reasoning however poorly on artistic writing. A chess participant could also be stronger in speedy codecs than in classical time controls. A product could also be most well-liked in a single market section however not in one other.
The contextual Bradley-Terry mannequin addresses this by permitting the latent power to fluctuate as a operate of observable covariates. As a substitute of a set parameter βᵢ for every merchandise, one writes:

the place xᵢ is a vector of options related to merchandise i within the present comparability context, and w is a coefficient vector shared throughout all objects that’s estimated from information. The comparability likelihood turns into:

This formulation reveals a structural equivalence that’s value pausing on. If one defines the design vector for a comparability as dᵢⱼ = xᵢ − xⱼ, then the contextual Bradley-Terry mannequin turns into:

the place σ is the logistic operate. That is merely logistic regression on the distinction of characteristic vectors. Every pairwise comparability is handled as a binary classification downside, and the options are the element-wise variations between the 2 objects’ covariate vectors.
This equivalence has a sensible consequence. Any software program bundle that matches logistic regression can be utilized to suit a contextual Bradley-Terry mannequin. One constructs a coaching set by which every row corresponds to a comparability, the options are dᵢⱼ = xᵢ − xⱼ, and the label is 1 if i used to be most well-liked and 0 in any other case. The estimated coefficient vector w then determines how every characteristic contributes to the likelihood of successful.
What Covariates Seize
The selection of covariates determines what the mannequin can categorical. Within the setting of language mannequin analysis, related covariates may embrace the subject of the immediate (arithmetic, coding, artistic writing), the problem of the immediate (estimated from annotator settlement charges or from embedding-based predictors), the size of the immediate, or the conversational flip at which the comparability was made.
With these covariates, the mannequin not estimates a single international power for every language mannequin. As a substitute, it estimates a power profile throughout the characteristic house. A mannequin might have excessive estimated power on coding prompts however decrease power on open-ended artistic duties. The discovered coefficient vector w quantifies how a lot every contextual characteristic shifts the result likelihood.
This can be a significant departure from the usual mannequin. Within the non-contextual case, the mannequin solutions the query: “Which merchandise is stronger general?” Within the contextual case, it solutions: “Beneath what situations is every merchandise stronger, and by how a lot?”
Software: The Chatbot Area
Probably the most outstanding up to date software of contextual Bradley-Terry modelling is the LMSYS Chatbot Area (Chiang et al., 2024), a platform for crowdsourced analysis of enormous language fashions. Customers submit prompts, obtain responses from two anonymised fashions, and point out which response they like.
The problem dealing with the Area is that naive Bradley-Terry rating treats all comparisons as equally informative. In apply, simple prompts produce practically indistinguishable outputs from most fashions, whereas troublesome prompts reveal significant high quality variations. A comparability on a trivial factual query contributes far much less rating sign than a comparability on a posh multi-step reasoning downside.
The Area addresses this by incorporating prompt-level covariates into the Bradley-Terry framework. Immediate issue, subject class, and different linguistic properties are included as options, permitting the system to estimate context-specific scores for every mannequin. The outcome is just not a single Elo rating per mannequin however a discovered power profile throughout the house of prompts and duties.
Bootstrap confidence intervals are computed by resampling the comparability information and re-estimating the Bradley-Terry coefficients for every bootstrap pattern, offering a measure of uncertainty within the rankings.
Bayesian Extension: TrueSkill
A associated however distinct extension is the Bayesian therapy of merchandise strengths. Microsoft’s TrueSkill system (Herbrich et al., 2006; Minka et al., 2018) replaces level estimates with posterior distributions. Every merchandise’s power is modelled as a Gaussian random variable with imply μᵢ and variance σᵢ². After observing every comparability, the posterior is up to date:

the place τ² is a system noise parameter that accounts for attracts and upsets. The variance σᵢ² shrinks as extra comparisons are noticed, reflecting rising confidence within the estimated power.
The important thing sensible good thing about this strategy is that it offers a pure measure of uncertainty. An merchandise with few comparisons has excessive variance and subsequently a large credible interval. An merchandise with many comparisons has low variance and a extra exact estimate. This uncertainty data can be utilized for adaptive matchmaking: pairing objects with excessive uncertainty in opposition to one another accelerates the convergence of the rating.
TrueSkill doesn’t incorporate covariates in the identical approach because the contextual Bradley-Terry mannequin, however the two concepts are complementary. One might place Bayesian priors on context-dependent strengths, sustaining posterior distributions that adjust throughout the characteristic house. This stays an energetic space of analysis.
Advantages of Contextualisation
The sensible advantages of the contextual extension could be summarised as follows.
- First, interpretability. As a substitute of a single opaque score per merchandise, the mannequin offers a power profile that reveals underneath which situations an merchandise performs properly and underneath which it doesn’t.
- Second, information effectivity. By leveraging the construction of the characteristic house, contextual fashions can extract extra rating sign from fewer comparisons. An merchandise that has been in contrast solely on coding prompts can nonetheless obtain an estimated power on arithmetic prompts if the mannequin has discovered how subject impacts efficiency from different objects.
- Third, generalisation to new objects. In the usual mannequin, a brand new merchandise with no comparability historical past has no estimated power. Within the contextual mannequin, if the brand new merchandise’s characteristic vector is offered, its power could be estimated by way of the discovered coefficient vector w, with none direct comparisons. This can be a type of cold-start prediction that’s notably priceless when the variety of objects is giant relative to the variety of comparisons.
Accounting for Noisy Raters: When Not All Comparisons Are Equal
The Bradley-Terry mannequin, in each its normal and contextual kinds, assumes that each noticed comparability is an equally dependable draw from the mannequin’s likelihood distribution. This assumption is commonly violated. In crowdsourced settings, the place comparisons are collected from many human annotators, the standard of particular person judgments varies considerably.
Some annotators are cautious, constant, and educated concerning the area. Others might rush by comparisons, apply idiosyncratic standards, or produce solutions which are successfully random. A small fraction could also be adversarial or inattentive. If the mannequin treats all comparisons equally, the estimated strengths can be distorted by the noise from unreliable annotators, and the ensuing rankings can be much less reliable than the information warrants.
The Normal Mannequin’s Implicit Assumption
Contemplate the usual Bradley-Terry probability for a single comparability by which annotator okay stories that merchandise i is most well-liked to merchandise j:

This expression doesn’t reference the annotator in any respect. It assumes that the result is a loud remark of the true comparability likelihood, with no variation in noise degree throughout annotators. The implicit mannequin is that each annotator, no matter experience or engagement, has the identical likelihood of appropriately figuring out the higher merchandise.
In apply, that is not often the case. Totally different annotators deliver completely different ranges of talent, consideration, and area data to the duty. Ignoring this heterogeneity results in biased power estimates, overconfident rankings, and an lack of ability to diagnose or appropriate for poor-quality annotations.
CrowdBT: Joint Estimation of Gadgets and Annotators
Chen et al. (2013) proposed CrowdBT, a mannequin that addresses this downside by collectively estimating merchandise strengths and annotator reliabilities. The important thing thought is to introduce a per-annotator reliability parameter ρₖ ∈ [0, 1] that governs the standard of annotator okay’s comparisons.
The comparability likelihood underneath CrowdBT is modelled as a mix:

The interpretation of this combination is intuitive. With likelihood ρₖ, the annotator observes the true Bradley-Terry consequence and stories it appropriately. With likelihood 1 − ρₖ, the annotator produces a uniformly random reply. A wonderfully dependable annotator has ρₖ = 1 and behaves precisely as in the usual mannequin. A totally unreliable annotator has ρₖ = 0 and contributes solely noise.
This formulation captures an vital perception about unreliable annotators. They aren’t assumed to be adversarial (systematically incorrect), however slightly noisy (typically proper, typically random). This can be a extra practical mannequin of human annotation behaviour than both assuming good reliability or treating low-quality annotations as inverted indicators.
Estimation by way of the EM Algorithm
The total log-likelihood underneath CrowdBT is:

the place Cₖ is the set of comparisons made by annotator okay. This goal is optimised by way of the expectation-maximisation (EM) algorithm.
Within the E-step, for every noticed comparability, the algorithm computes the posterior likelihood that the annotator was behaving reliably (versus guessing randomly), given the present estimates of β and ρ. Let zₖᵢⱼ denote this latent indicator. Its posterior is:

Within the M-step, the merchandise strengths β are up to date to maximise the probability of the comparisons which are attributed to dependable behaviour, and the annotator reliabilities ρₖ are up to date based mostly on the fraction of their comparisons that the E-step attributes to real experience slightly than random guessing.
The algorithm alternates between these two steps till convergence. The result’s a set of merchandise strengths which were denoised by downweighting unreliable annotators, along with a set of annotator reliability scores that can be utilized for high quality management and analysis.
Sensible Implications
The CrowdBT mannequin has a number of sensible penalties which are value highlighting.
- First, it offers computerized high quality management. Fairly than requiring a separate step to establish and take away dangerous annotators, the mannequin learns annotator high quality as a byproduct of becoming the rating. Annotators with low estimated ρₖ could be flagged for evaluate, retrained, or excluded from future duties.
- Second, it improves rating accuracy. By downweighting noisy comparisons, the mannequin produces merchandise power estimates which are much less delicate to annotation high quality. That is notably vital when the annotator pool is heterogeneous, as is typical in crowdsourcing platforms.
- Third, it allows a analysis of annotation issue. If many annotators have low reliability on comparisons involving a specific pair of things, this may increasingly point out that the 2 objects are genuinely troublesome to tell apart slightly than that the annotators are poor. The mannequin’s output might help separate annotator noise from item-level ambiguity.
Extensions: Past a Single Reliability Parameter
Subsequent work has prolonged the CrowdBT formulation in a number of instructions.
One pure extension is to decompose annotator behaviour into reliability and bias. The only parameter ρₖ captures noise however not systematic preferences. An annotator who persistently favours a specific merchandise no matter its high quality is just not properly modelled by the reliability parameter alone. Including a per-annotator bias time period permits the mannequin to tell apart between noise (random errors) and systematic distortion (constant favouritism).
A second extension is to permit annotator reliability to fluctuate by area or subject. An annotator who’s an knowledgeable in arithmetic might produce extremely dependable comparisons on mathematical questions however a lot noisier comparisons on artistic writing duties. Modelling domain-specific reliability as ρₖ,c, the place c indexes the comparability class, captures this heterogeneity.
A 3rd extension, developed within the Bayesian setting, locations a previous distribution on the reliability parameters. A pure alternative is a Beta prior:

which encodes a previous perception concerning the distribution of annotator high quality. This Bayesian formulation, typically known as BBQ (Bayesian Bradley-Terry with High quality estimation), offers posterior distributions over each merchandise strengths and annotator reliabilities. It handles the case the place particular person annotators contribute solely a small variety of comparisons, utilizing the previous to regularise the reliability estimates.
Connection to the Broader Crowdsourcing Literature
The issue of aggregating judgments from a number of noisy annotators has a considerable historical past within the statistical and machine studying literature. The foundational mannequin is the Dawid-Skene mannequin (1979), which addresses the identical downside within the setting of categorical labelling. In Dawid-Skene, every annotator is characterised by a confusion matrix that describes their likelihood of reporting every label given the true label. The EM algorithm collectively estimates the true labels and the annotator confusion matrices.
CrowdBT could be understood as an adaptation of this precept to the pairwise comparability setting. As a substitute of a confusion matrix, every annotator is characterised by a reliability parameter. As a substitute of categorical labels, the true sign is a Bradley-Terry comparability likelihood. The conceptual construction is identical: collectively estimate the latent floor fact and the annotator high quality, utilizing every to tell the opposite.
The broader lesson from this literature is that fashions which collectively estimate merchandise parameters and annotator parameters persistently outperform fashions that deal with both dimension as mounted. Treating all annotators as equally dependable discards details about annotation high quality. Treating merchandise high quality as identified discards the sign that annotators are offering. The simplest strategy is to be taught each concurrently, which is exactly what CrowdBT and its extensions are designed to do.
Abstract
The usual Bradley-Terry mannequin offers a clear framework for studying from pairwise comparisons, but it surely assumes that every one comparisons are equally dependable. In apply, annotator high quality varies, and this variation can distort the estimated rankings.
The CrowdBT mannequin addresses this by introducing a per-annotator reliability parameter that governs the likelihood of observing a real comparability versus a random guess. The EM algorithm collectively estimates merchandise strengths and annotator reliabilities, producing denoised rankings and annotator high quality scores as a pure byproduct.
Extensions to domain-specific reliability, Bayesian priors, and bias modelling present further flexibility for purposes the place annotator heterogeneity is especially pronounced. Along with the contextual extensions mentioned within the previous part, these strategies remodel the fundamental Bradley-Terry mannequin from a software for easy rating right into a wealthy framework able to dealing with the complexities of real-world comparative analysis.
Disclaimer: The views and opinions expressed on this article are my very own and don’t signify these of my employer or any affiliated organizations. The content material relies on private expertise and reflection, and shouldn’t be taken as skilled or tutorial recommendation.
📚 Additional Studying
R. A. Bradley and M. E. Terry (1952) — Rank Evaluation of Incomplete Block Designs: I. The Technique of Paired Comparisons — The foundational Bradley–Terry paper. It launched one of many canonical statistical fashions for pairwise comparability information, and it stays the pure place to begin for any dialogue of preference-based rating.
Manuela Cattelan (2012) — Fashions for Paired Comparability Knowledge: A Evaluation with Emphasis on Dependent Knowledge — A transparent evaluate of the paired-comparison literature, particularly helpful for understanding how classical fashions resembling Bradley–Terry and Thurstone are prolonged when comparisons are usually not impartial.
Xi Chen, Paul N. Bennett, Kevyn Collins-Thompson, and Eric Horvitz (2013) — Pairwise Rating Aggregation in a Crowdsourced Setting — A helpful reference for rating underneath noisy human judgments. The paper focuses on methods to combination pairwise comparisons in crowdsourced settings whereas accounting for annotator high quality and label effectivity.
Wei-Lin Chiang et al. (2024) — Chatbot Area: An Open Platform for Evaluating LLMs by Human Choice — The principle reference for Area-style analysis of language fashions by large-scale human pairwise voting. It’s particularly related in case your article connects paired comparability fashions to fashionable LLM benchmarking.
A. P. Dawid and A. M. Skene (1979) — Most Probability Estimation of Observer Error-Charges Utilizing the EM Algorithm — The traditional Dawid–Skene paper on estimating latent fact and annotator reliability from noisy labels. It’s foundational for crowd-label aggregation and for considering fastidiously about decide high quality in analysis pipelines.
Ralf Herbrich, Tom Minka, and Thore Graepel (2006) — TrueSkill: A Bayesian Ability Score System— The unique TrueSkill paper, introducing a Bayesian framework for inferring latent talent from repeated aggressive outcomes. It’s extremely related when pairwise wins and losses are used to construct dynamic rankings over time.
Tom Minka, Ryan Cleven, and Yordan Zaykov (2018) — TrueSkill 2: An Improved Bayesian Ability Score System— A later refinement of TrueSkill that includes richer indicators and improves predictive accuracy. It’s useful if you wish to gesture past easy win/loss aggregation towards extra expressive Bayesian rating programs.

















{kind=link}