


This text was co-authored by Rahul Vir and Reya Vir.
to Token Effectivity
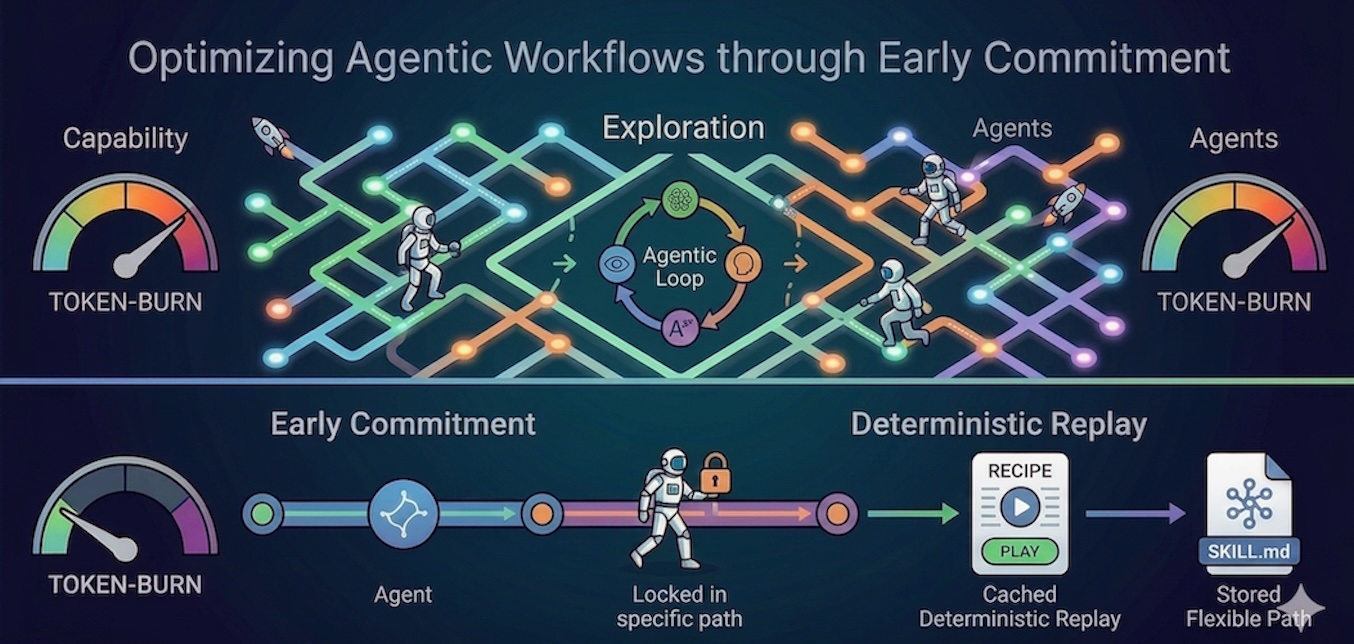
Now we have formally moved previous the AI prototyping section. Constructing on the ideas in Escaping the Prototype Mirage [1], product and engineering groups throughout each business at the moment are transport agentic functions that resolve workflows beforehand dominated by handbook grind. Constructing these autonomous agent prototypes is now a breeze. It is so simple as utilizing key ideas like recursive Agentic Loops (Observe-Suppose-Act) for execution, organising headless gateways to attach brokers by way of chat apps, and counting on saved state that persists throughout reboots (as defined in [1]). However graduating them to dependable merchandise is one other story. The brand new frontier isn’t proving brokers can work, it’s proving they’ll work profitably.
On the identical time, inner metrics at enterprises like “token maxing” (unconstrained token use to realize greatest outcomes) that had been acceptable for the prototyping stage are shifting to measuring the “value-to-token-spent” ratio as agentic merchandise scale. In spite of everything, most merchandise have to be worthwhile and maximize margin as they’re shifting from leveraging low cost conventional compute (TradCompute) to unravel person issues towards utilizing AI intelligence for a similar.
However fashions want reasoning freedom and up to date research have proven that exploratory agentic workflows outperform fastened paths, opening new paths, creating MCP instruments, and constructing infrastructure to unravel the issue extra effectively most often. This brings the query of balancing the mannequin’s want for company with the financial actuality of inference prices.
Why Constrained Brokers Fail to Converge
Agent harnesses retailer your process context and goals in markdown (*.md) recordsdata, which don’t usually characterize tight workflows, however slightly define the intent or the target you need to accomplish.
The Paradox of Goal Failure: In research on brokers fixing complicated issues, researchers discovered that offering strict, highly-constrained pointers the place every of the agent’s motion takes it nearer to the objective, results in getting caught in a neighborhood optima and struggling an goal failure. An instance from Professor Jeff Clune’s analysis on open-ended agent studying illustrates this completely: an agent in a maze, when always rewarded solely for searching for the direct path to the exit, will repeatedly bang into partitions and get trapped in a neighborhood optimum, by no means reaching the tip [2].
The Energy of Unconstrained Harnesses: Up to date agent harnesses like Google Antigravity and Anthropic’s Claude Code have been so efficient as a result of they permit brokers to create, orchestrate, execute complicated duties, and even create their very own instruments with out strict human micro-management. They succeed as a result of they’re given the liberty to discover circuitous paths.
Contemplate an edge case in a routine medical consumption workflow: if we rigidly constrain a healthcare agent to purely comply with a predefined scheduling movement, it breaks in the actual world. If a affected person mentions chest ache halfway by that routine consumption, the agent’s Agentic Loop will need to have the autonomy to immediately acknowledge the urgency, abandon the scheduling movement, and set off a security escalation. It ought to make the most of what we beforehand outlined as a `No-Reply Token` to suppress reserving chatter and route the context on to a human nurse [1]. Rigidly constrained prototypes fail this check spectacularly as a result of they can not adapt to important, out-of-bounds context.
Infinite Purpose Looking is Costly
Whereas offering company is important to find an answer initially, operating a full open-ended seek for each person workflow request can result in large and unsustainable token consumption. At this stage the agent has discovered a legitimate path and this method is inherently permitting it to re-explore or “hallucinate” the workflow construction. Whereas this may be self correcting, such subsequent runs of an analogous request destroy enterprise token economics.
For instance, routing medical consumption workflows and even the sting circumstances that require an escalation might be learnt over a time frame. A clinic or an answer supplier’s workflows will graduate to deterministic paths for probably the most half, leaving some autonomy reserved purely for uncommon outliers and sophisticated edge circumstances.
Architectural Options Via Early Dedication and Deterministic Replay
Early Dedication has proven promise in structured downside fixing and it may be utilized to agentic workflows as properly [3]. It includes classifying the issue first, say by structuring the system immediate to require the mannequin to output a selected classification tag. By forcing an agent to categorise the issue kind and set up constraints earlier than it generates the execution logic, you stop the agent from hallucinating or exploring dead-end paths. This cuts out noise and focuses the agent purely on execution slightly than steady exploration.
For example, in a telehealth triage workflow, we will implement Early Dedication by requiring the agent to definitively classify the encounter as a “routine prescription refill” earlier than taking any motion. As soon as dedicated to this particular constraint, the agent restricts its device calls strictly to the pharmacy database, fully bypassing the costly, open-ended diagnostic reasoning paths it would in any other case wander down making an attempt to diagnose a affected person.
A latest research by Wang, X., et al. introduces the LOOP Talent Engine Framework, which takes early dedication to the infrastructure degree through the use of a one-shot recording and deterministic replay paradigm [4]. The agent can autonomously discover as soon as utilizing full reasoning, and the system then compiles that profitable hint right into a branch-free recipe. For all future runs, the LLM might be bypassed, guaranteeing execution determinism and slashing token utilization by over 93.3% for every day duties, and as much as 99.98% for high-frequency executions. This idea might be prolonged to agentic workflows.
Contemplate the technology of every day clinic compliance reviews or commonplace post-discharge summaries, that are extremely secure, repetitive duties. Ranging from exploratory after which shortly graduating to a deterministic framework, an agent has to cause by the complicated knowledge extraction from the Digital Well being Report precisely as soon as. For the subsequent hundred sufferers discharged with the identical process, the system executes that precise branch-free recipe, reliably swapping within the new affected person’s vitals and dates with out ever invoking the LLM. This ensures zero hallucinated knowledge on repetitive healthcare duties whereas maximizing token effectivity.
ML practitioners have to make the decision between a pure deterministic replay (like LOOP) that maximizes token financial savings, and a hybrid method (storing the explored path in a SKILL.md file). The hybrid method trades a few of these token financial savings again in trade for reasoning by a guided path that’s extremely optimum, but leaves sufficient flexibility to self-adapt to a altering underlying framework. Whether or not this ability file is up to date manually or by an autonomous self-improving mechanism, preserving this reasoning headroom ensures adaptability and long-term robustness. For instance, if the database construction adjustments, the agent is ready to replace the SQL queries and extract the data.
Conclusion: The Discover-Commit-Measure ML Pipeline
ML engineers and Product Managers should adapt their functions to leverage the huge intelligence of autonomous brokers and embrace unconstrained agent harnesses for preliminary downside discovery and sophisticated, one-off edge circumstances. This yields optimum options with out operating an costly reinforcement studying cycle (which is usually blocked by lack of know-how, platform constraints, coaching price or closed fashions).
As soon as now we have discovered a near-optimal path, token economics for structured and repetitive duties demand we implement early dedication in immediate design, using deterministic replay architectures to cache the execution path.
As agentic merchandise scale, we should shift operational metrics away from easy process success charges, shifting as an alternative towards token-efficiency and value-per-token generated.
References
- Vir, R., & Vir, R. (2026, March 4). Escaping the prototype mirage: Why enterprise AI stalls. In the direction of Information Science.
- Clune, J. (2025, February 12). Visitor Lecture 6 CS329A by Prof. Jeff Clune: Open-ended Agent Studying within the Period of Basis Fashions [Video]. YouTube.
- Vir, R. (2026, January 1). Why early dedication helps AI resolve structured issues. In the direction of AI.
- Wang, X., Yu, Ok., Liang, X., Wang, L., & Han, C. (2026). Good to go: The LOOP ability engine that hits 99% success and slashes token utilization by 99% by way of one-shot recording and deterministic replay. arXiv.
















{kind=link}