


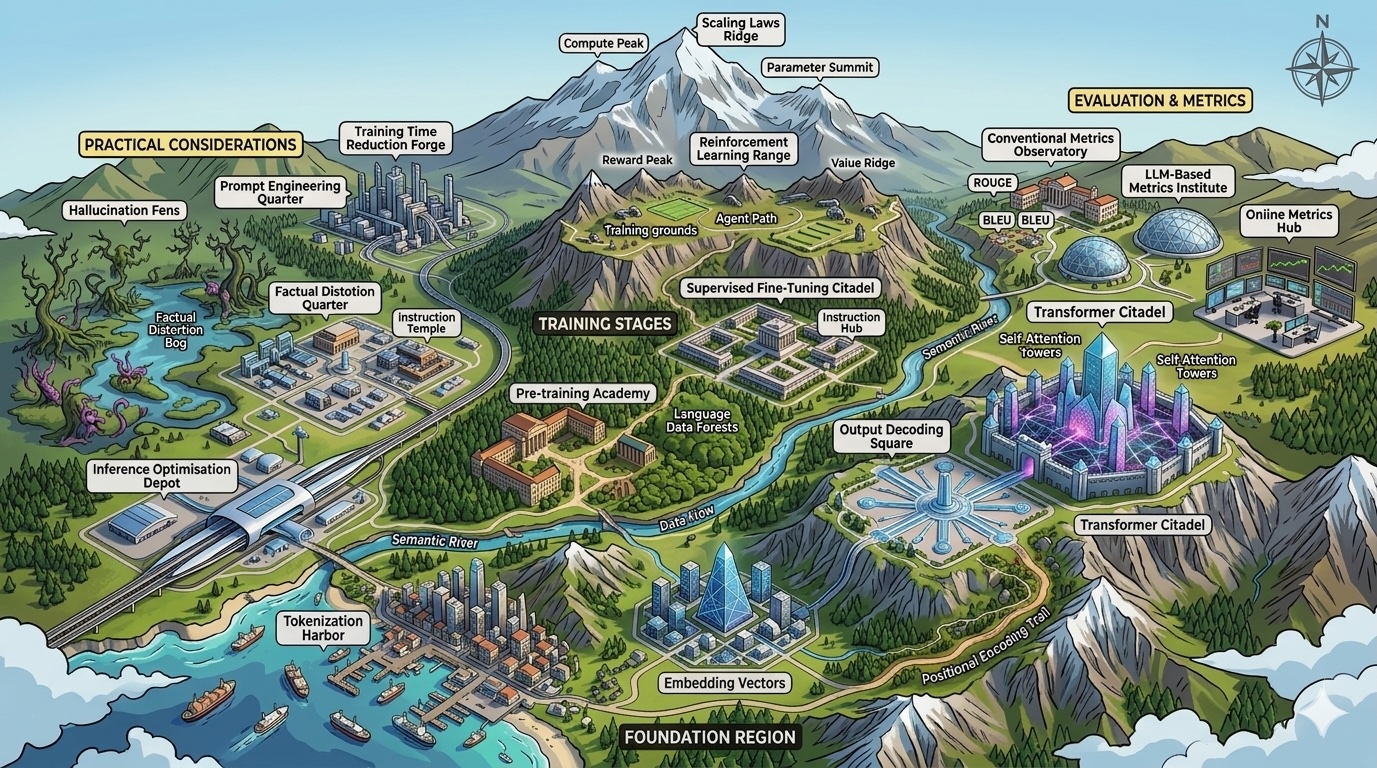
(LLMs) have rapidly turn into the muse of recent AI techniques — from chatbots and copilots to go looking, coding, and automation. However for engineers transitioning into this house, the educational curve can really feel steep and fragmented. Ideas like tokenization, consideration, fine-tuning, and analysis are sometimes defined in isolation, making it onerous to kind a coherent psychological mannequin of how the whole lot suits collectively.
I bumped into this firsthand when transferring from laptop imaginative and prescient to LLMs. In a brief span of time, I needed to perceive not simply the speculation behind transformers, but in addition the sensible realities: coaching trade-offs, inference bottlenecks, alignment challenges, and analysis pitfalls.
This text is designed to bridge that hole.
Slightly than diving deep right into a single part, it supplies a structured map of the LLM engineering panorama — overlaying the important thing constructing blocks it is advisable to perceive to design, prepare, and deploy real-world LLM techniques.
We’ll transfer from the basics of how textual content is represented, by way of mannequin architectures and coaching methods, all the way in which to inference optimization, analysis, and system-level issues and sensible consideration like immediate engineering and decreasing hallucinations.

By the tip, it’s best to have a clear psychological framework for the way fashionable LLM techniques are constructed — and the place every idea suits in observe.
Changing letters to numbers

Tokenisation
When feeding knowledge to a mannequin, we are able to’t simply feed it letters or phrases immediately — we’d like a method to convert textual content into numbers. Intuitively, we would consider assigning every phrase within the language a novel quantity and feeding these numbers to the mannequin. Nevertheless, there are lots of of 1000’s of phrases within the English language, and coaching on such an enormous vocabulary could be infeasible by way of reminiscence and effectivity.
So what could be accomplished as a substitute? Nicely, we may strive encoding letters, since there are solely 26 within the English alphabet. However this might result in issues as nicely — fashions would battle to seize the that means of phrases from particular person letters alone, and sequences would turn into unnecessarily lengthy, making coaching troublesome.
A sensible answer is tokenization. As a substitute of representing language on the phrase or character stage, we cut up textual content into probably the most frequent and helpful subword items. These subwords act because the constructing blocks of the mannequin’s vocabulary: widespread phrases seem as entire tokens, whereas uncommon phrases could be represented as combos of smaller subwords.
A standard algorithm for that’s Byte-Pair-Encoding (BPE). BPE begins with particular person characters as tokens, then repeatedly merges probably the most frequent pairs of tokens into new tokens, step by step increase a vocabulary of subword items till a desired vocabulary dimension is reached.
At this stage every token is assigned a novel quantity — its ID within the vocabulary.
Embeddings
After now we have tokenized the information and assigned token IDs, we have to connect semantic that means to those IDs. That is achieved by way of textual content embeddings — mappings from discrete token IDs into steady vector areas. On this house, phrases or tokens with related meanings are positioned shut collectively, and even algebraic operations can seize semantic relationships (for instance: embedding(queen) — embedding(girl) + embedding(man) ≈ embedding(king)).
Usually, embedding layers are educated to take token IDs as enter and produce dense vectors as output. These vectors are optimized collectively with the mannequin’s coaching goal (e.g., next-token prediction). Over time, the mannequin learns embeddings that encode each syntactic and semantic details about phrases, subwords, or tokens. Standard embedding fashions are: word2vec, glove, BERT.
Positional encoding
Usually, LLMs are usually not inherently conscious of the construction of language. Pure language has a sequential nature — phrase order issues — however on the similar time, tokens which might be far aside in a sentence should be strongly associated. To seize each native order and long-range dependencies, we inject positional info of the tokens into every embedding.
There are a number of widespread to positional approaches:
- Absolute positional encodings — Mounted patterns, corresponding to sine and cosine features at totally different frequencies, are added to token embeddings. That is easy and efficient however could battle to symbolize very lengthy sequences, because it doesn’t explicitly mannequin relative distances.
- Relative positional encodings — These symbolize the distance between tokens as a substitute of their absolute positions. A well-liked methodology is RoPE (Rotary Positional Embeddings), which encodes place as vector rotations. This strategy scales higher to lengthy sequences and captures relationships between distant tokens extra naturally.
- Realized positional encodings — As a substitute of counting on mounted mathematical features, the mannequin immediately learns place embeddings throughout coaching. This enables flexibility however could be much less generalizable to sequence lengths not seen in coaching.
Mannequin Structure

After the information is tokenized, embedded, and enriched with positional encodings, it’s handed by way of the mannequin. The present state-of-the-art structure for processing textual knowledge is the transformer structure, whose core is base on the consideration mechanism. A transformer sometimes consists of a stack of transformer blocks:
- Multi-Head Consideration: Permits the mannequin to concentrate on totally different components of the enter sequence concurrently, capturing numerous context. It calculates Queries (Q), Keys (Okay), and Values (V) to outline phrase relationships.
- Place-wise Feed-Ahead Community (FFN): A completely linked community utilized to every place independently, including non-linearity.
- Residual Connections: Brief-cut connections that assist gradients movement throughout coaching, stopping info loss.
- Layer Normalization: Normalizes the enter to stabilize coaching.
Consideration

Launched within the paper known as Consideration Is All You Want, in consideration, each token is projected into three vectors: a question (what it’s on the lookout for), a key (what it gives), and a worth (the precise info it carries). Consideration works by evaluating queries to keys (through similarity scores) to determine how a lot of every worth to mixture. This lets the mannequin dynamically pull in related context based mostly on content material, not place.
Multi-head consideration runs a number of consideration mechanisms in parallel, every with its personal realized projections. Consider every “head” as specializing in a special relationship (e.g., syntax, coreference, semantics). Combining them provides the mannequin a richer, extra nuanced understanding than a single consideration cross.
There are a number of sorts of consideration mechanism that change based mostly on its objective: self-attention, masked self-attention and cross-attention.
- Self-attention operates inside a single sequence, letting tokens attend to one another (e.g., understanding a sentence). Masked self-attention is just like self-attention with a key distinction in that spotlight solely sees previous tokens, with out observing the long run ones.
- Cross-attention connects two sequences, the place one supplies queries and the opposite supplies keys/values (e.g., a decoder attending to an encoded enter in translation). The important thing distinction is whether or not context comes from the identical supply or an exterior.
Normal consideration compares each token with each different token, resulting in quadratic complexity O(n2). As sequence size grows, computation and reminiscence utilization enhance quickly, making very lengthy contexts costly and sluggish. This is without doubt one of the foremost bottlenecks in scaling LLMs and an energetic subject of analysis —for instance by way of being selective about what tokens attend to what tokens.
Structure varieties
Language modeling duties are constructed utilizing one of many following transformer architectures:
- Encoder-only fashions — Every token can attend to each different token within the sequence (bidirectional consideration). These fashions are sometimes educated with masked language modeling (MLM), the place some tokens within the enter are hidden, and the duty is to foretell them. This setup is well-suited for classification and understanding duties (e.g., BERT).
- Decoder-only fashions — Every token can attend solely to the tokens that come earlier than it within the sequence (causal or unidirectional consideration). These fashions are educated with causal language modeling, i.e., predicting the following token given all earlier ones. This setup is right for textual content technology (e.g., GPT).
- Encoder–Decoder fashions — The enter sequence is first processed by the encoder, and the ensuing representations are then fed into the decoder by way of cross-attention layers. The decoder generates an output sequence one token at a time, conditioned each on the encoder’s representations and its personal earlier outputs. This setup is widespread for sequence-to-sequence duties like machine translation (e.g., T5, BART).
Subsequent token prediction and output decoding
Fashions are educated to foretell the subsequent token — that is accomplished by outputting a chance distribution over all potential tokens within the vocabulary. Output of the mannequin is the logit which is then handed by way of the softmax to foretell the chance of the following token within the vocabulary.
In probably the most simple strategy, we may all the time select the token with the very best chance (that is known as grasping decoding). Nevertheless, this technique is commonly suboptimal, for the reason that regionally more than likely token doesn’t all the time result in the globally most coherent or pure sentence.
To enhance technology, we are able to pattern from the chance distribution. This introduces variety and permits the mannequin to discover totally different continuations. Furthermore, we are able to department the technology course of by contemplating a number of candidate tokens and increasing them in parallel.
A number of in style decoding methods utilized in observe are:
- Beam search: As a substitute of following a single grasping path, beam search retains observe of the high n candidate sequences (beams) at every step, increasing them in parallel and in the end choosing the sequence with the very best total chance.
- High-k sampling: At every step, solely the okay most possible tokens are thought-about, and one is sampled in keeping with their chances. This avoids sampling from the lengthy tail of impossible tokens.
- High-p sampling (nucleus sampling): As a substitute of fixing okay, we choose the smallest set of tokens whose cumulative chance is not less than p(e.g., 0.9). Then we pattern from this set, dynamically adjusting what number of tokens are thought-about relying on the form of the distribution.
To regulate how “flat” or “peaked” the chance distribution is LLMs use a temperature parameter. A low temperature (<1) makes the mannequin extra deterministic, concentrating chance mass on the more than likely tokens. A excessive temperature (>1) makes the distribution extra uniform, rising randomness and variety within the generated output.
Coaching phases

LLM coaching sometimes has two phases: pre-training, the place the mannequin learns basic language patterns corresponding to grammar, syntax, and that means from large-scale knowledge, and fine-tuning, the place it’s tailored to carry out particular duties, corresponding to following directions or answering questions in a desired format and afterward refines outputs to align with human preferences and security constraints.
This development strikes from functionality (what the mannequin can do) to alignment (what the mannequin ought to do).
Pre-training
Pre-training is probably the most computationally costly stage of LLM coaching as a result of the mannequin should be taught from extraordinarily giant and numerous datasets. This sometimes entails lots of of billions to trillions of tokens drawn from sources corresponding to net pages, books, articles, code, and conversations.
To information choices about mannequin dimension, coaching time, and dataset scale, researchers use LLM scaling legal guidelines, which describe how these components relate and assist estimate the optimum setup for attaining robust efficiency.
Knowledge pre-processing is an important step as a result of uncooked textual content can considerably degrade LLM efficiency if used immediately. Coaching knowledge comes from many sources, every with its personal challenges that should be cleaned and filtered.
- Net pages typically comprise boilerplate content material corresponding to adverts, navigation menus, headers, and footers, together with formatting noise from HTML, CSS, and JavaScript. They could additionally embody duplicated pages, spam, low-quality textual content, and even dangerous content material.
- Books can introduce points like metadata (writer particulars, web page numbers, footnotes), OCR errors from digitization, and repetitive or stylistically inconsistent passages. As well as, copyright restrictions require cautious filtering and licensing compliance.
- Code datasets could embody auto-generated information, duplicated repositories, extreme feedback, or boilerplate code. Licensing constraints are additionally vital, and low-quality or buggy code can negatively impression coaching if not eliminated.
To deal with these challenges, datasets are sometimes filtered by language and high quality, and imbalances throughout sources are corrected by way of knowledge augmentation or re-weighting.
Suprevised fine-tuning
In supervised fine-tuning, we sometimes don’t replace all mannequin parameters. As a substitute, a lot of the pretrained weights are saved frozen, and solely a small variety of extra parameters are educated. That is accomplished both by including light-weight adapter modules or by utilizing parameter-efficient strategies corresponding to LoRA, whereas coaching on a small sub-set of filtered and clear set of information.
- Low Rank Adaptation (LoRA) is without doubt one of the most generally used approaches. As a substitute of updating the total weight matrix, LoRA learns two smaller low-rank matrices, A and B, whose product approximates the replace to the unique weights. The pretrained weights stay mounted, and solely A and B are educated. This makes fine-tuning much more environment friendly by way of reminiscence and compute whereas nonetheless preserving efficiency. (See additionally: sensible LoRA coaching methods and finest practices.)
- Past LoRA, different parameter-efficient strategies embody prefix tuning, the place a small set of trainable “digital tokens” is added to the enter and optimized throughout coaching, and adapter layers, that are small trainable modules inserted between present transformer blocks whereas the remainder of the mannequin stays frozen.
At the next stage, supervised fine-tuning itself is the stage the place we educate the mannequin find out how to behave on a particular job utilizing high-quality labeled examples. This sometimes contains:
- Dialogue knowledge: curated human–human or human–AI conversations that educate the mannequin find out how to reply naturally in interactive settings.
- Instruction knowledge: immediate–response pairs that prepare the mannequin to comply with directions, reply questions, and carry out reasoning or task-specific outputs.
Collectively, these methods align a pretrained mannequin with the conduct we truly need at inference time.
Reinforcement studying
After supervised fine-tuning teaches the mannequin what to do, reinforcement studying is used to refine how nicely it does it, particularly in open-ended or subjective duties like dialogue, reasoning, and security.
Not like supervised studying with mounted targets, RL introduces a suggestions loop: mannequin outputs are evaluated, scored, and improved over time. This makes RL a key software for aligning fashions with human preferences. In observe, it helps: encourage useful, innocent, and trustworthy behaviour, scale back poisonous, biased, or unsafe outputs and enhance instruction-following and conversational high quality.
As a result of alignment knowledge is smaller however increased high quality than pre-training knowledge, RL acts as a fine-grained steering mechanism, not a supply of latest data.
A standard paradigm is Reinforcement Studying from Human Suggestions (RLHF), which generally entails three steps:
- Accumulate desire knowledge: Because the gold customary people rank a number of mannequin responses to the identical immediate (e.g., which is extra useful or secure), producing relative preferences somewhat than absolute labels, nevertheless, in some instances, stronger fashions are used to generate desire knowledge or critique weaker fashions, decreasing reliance on costly human labeling. In observe, combining human and automatic suggestions permits scaling whereas sustaining high quality.
- Practice a reward mannequin (RM): A separate mannequin is educated to attain responses in keeping with human preferences. Given a immediate and a candidate response, the reward mannequin assigns a scalar rating representing how good the response is in keeping with human judgment.
- Optimize the coverage (the LLM): The language mannequin, is then educated to maximise the reward sign, i.e., to generate outputs people usually tend to favor.
Optimizing the coverage (LLM) is commonly difficult — RL may destroy learnt data, or the mannequin may collapse to predicting one believable output that may generate most reward with out variety. A number of algorithms are used to carry out this optimization and deal with the problems:
- Proximal Coverage Optimization (PPO): PPO updates the mannequin whereas constraining how far it could transfer from the unique coverage in a single step, stopping instability or degradation of language high quality. A wonderful video explantion of the PPO could be discovered right here.
- Direct Choice Optimization (DPO): bypasses the necessity for an express reward mannequin. It immediately optimizes the mannequin to favor chosen responses over rejected ones utilizing a classification-style goal, simplifying the pipeline and reduces coaching complexity.
- Group Relative Coverage Optimization (GRPO): A variant that compares teams of outputs somewhat than pairs, enhancing stability and pattern effectivity by leveraging richer comparative alerts.
- Kahneman-Tversky Optimization (KTO): KTO incorporates uneven preferences (e.g., penalizing dangerous outputs extra strongly than rewarding good ones), which might higher mirror human judgment in safety-critical eventualities.
RL for language fashions could be broadly categorized into on-line and offline based mostly on how knowledge is collected and used throughout coaching:
- Offline RL (dominant at the moment): The mannequin is educated on a mounted dataset of interactions. There is no such thing as a additional interplay with people or the surroundings throughout optimization: as soon as desire knowledge is collected and the reward mannequin is educated, coverage optimization (e.g., PPO or DPO) is carried out on this static dataset.
- On-line RL: The mannequin repeatedly interacts with the surroundings (e.g., customers or human annotators), producing new outputs and receiving contemporary suggestions that’s included into coaching. This creates a dynamic suggestions loop the place the mannequin can discover and enhance iteratively.
Reasoning-aware RL (e.g., RL by way of Chain-of-Thought)
RL may also be utilized to enhance reasoning. As a substitute of solely rewarding remaining solutions, the mannequin could be rewarded for producing high-quality intermediate reasoning steps (chain-of-thought). This encourages extra structured, interpretable, and dependable problem-solving conduct.
Hallucination in LLMs

Even LLMs educated on factually appropriate knowledge tend to supply non-factual completions, also called hallucinations. This occurs as a result of LLMs are probabilistic fashions which might be predicting the following token conditioned on the coaching knowledge corpus and generated tokens to this point and are usually not assured to supply precise matching with the information educated on. There are, nevertheless, methods to minimise the impact of hallucinations in LLMs:
Retrieval Augmented Era (RAG): Incorporate exterior data sources at inference time so the mannequin can retrieve related, factual info and floor its responses in verified knowledge, decreasing reliance on probably outdated or incomplete inner data. RAG could be pretty complicated from the engineering perspective and sometimes consists of:
- Chunking: splitting paperwork into smaller, manageable items earlier than indexing them for retrieval. Good chunking balances context and precision: chunks which might be too giant dilute relevance, whereas chunks which might be too small lose vital context.
- Embedding: convert chunks of textual content into dense vector representations that seize semantic that means. In RAG, each queries and paperwork are embedded into the identical vector house, permitting similarity search to retrieve related content material even when precise key phrases don’t match.
- Retrieval: Excessive-quality retrieval ensures that related, numerous, and non-redundant chunks are handed to the mannequin, decreasing hallucinations and enhancing factual accuracy. It relies on components like embedding high quality, chunking technique, indexing methodology, and search parameters.
- Reranking: A second-stage filtering step that reorders retrieved chunks utilizing a extra exact (typically dearer) mannequin. Whereas preliminary retrieval is optimized for pace, rerankers concentrate on relevance, serving to prioritize probably the most helpful context for technology.
Coaching to say I don’t know: Explicitly educate the mannequin to acknowledge uncertainty when it lacks ample info, discouraging it from producing plausible-sounding however incorrect statements.
Actual matching and post-evaluation: Use strict matching or verification in opposition to trusted sources or exterior mannequin‑based mostly verifiers and critics throughout completion or post-processing to make sure generated content material aligns with factual references, significantly for delicate or exact info.
Optimization

Coaching LLMs is a problem in itself — coaching the mannequin requires enormous variety of GPUs, as we have to retailer the mannequin, gradients and parameters of the optimizer. Nevertheless, inference can be a problem — think about having to serve tens of millions of requests — person retention is increased if the fashions can infer the textual content quick and with prime quality.
Coaching optimization
Coaching giant fashions is usually accomplished utilizing stochastic gradient descent (SGD) or certainly one of its variants. As a substitute of updating mannequin parameters after each single instance, we compute gradients on batches of information, which makes coaching extra secure and environment friendly. Generally, the bigger the batch dimension, the extra correct the gradient estimate is, although extraordinarily giant batches also can sluggish convergence or require tuning.
For very giant fashions corresponding to LLMs, a single GPU can’t retailer all of the parameters or course of giant batches by itself. To deal with this, coaching is distributed throughout a number of GPUs and even throughout clusters of machines. This requires rigorously deciding find out how to cut up the workload — both by dividing the knowledge, the mannequin parameters, or the computation pipeline.
Whereas distributed coaching has been studied extensively in deep studying, LLMs introduce distinctive challenges resulting from their huge parameter counts and reminiscence necessities. A number of methods have been developed to beat these:
- Knowledge parallelism — Every GPU holds a replica of the mannequin however processes totally different batches of information, with gradients averaged throughout GPUs.
- Mannequin parallelism — The mannequin’s parameters are cut up throughout a number of GPUs, so every GPU is chargeable for part of the mannequin.
- Pipeline parallelism — Totally different layers of the mannequin are assigned to totally different GPUs, and knowledge flows by way of them like phases in a pipeline.
- Tensor parallelism — Particular person tensor operations (e.g., giant matrix multiplications) are themselves cut up throughout a number of GPUs.
- DeepSpeed / ZeRO — A library and set of optimization methods for coaching giant fashions effectively, together with partitioning optimizer states, gradients, and parameters to cut back reminiscence utilization.
Usually in these there are two parameters that we try to optimize — scale back throughout GPU communication (e.g. for gradient change), whereas additionally ensuring that we match significant knowledge on the GPUs. Different techiques to cut back reminiscence throughout coaching and achieve some speedups embody:
- Gradient checkpointing: A memory-saving coaching method that shops solely a subset of intermediate activations through the ahead cross and recomputes the remainder throughout backpropagation. This trades additional compute for considerably decrease GPU reminiscence utilization, enabling coaching of bigger fashions or longer sequences.
- Combined precision coaching: Makes use of lower-precision codecs (e.g., FP16 or BF16) for many computations whereas retaining essential values (like grasp weights or accumulations) in increased precision (FP32). This reduces reminiscence utilization and hurries up coaching, particularly on fashionable GPUs with specialised {hardware}, with minimal impression on accuracy.
Inference Optimization
- Distillation: Massive fashions are sometimes overparameterized, so we are able to prepare a smaller scholar mannequin to imitate a bigger trainer. As a substitute of studying solely the right outputs, the coed matches the trainer’s full chance distribution — together with much less probably tokens — capturing richer relationships. This yields near-teacher efficiency in a a lot smaller, quicker mannequin.
- Flash-attention: An optimized consideration algorithm that computes precise consideration whereas dramatically decreasing reminiscence utilization. It avoids materializing the total consideration matrix by tiling computations and fusing operations right into a single GPU kernel, retaining knowledge in quick on-chip reminiscence. The consequence: considerably quicker coaching and inference, particularly for lengthy sequences, and assist for longer context lengths with out altering the mannequin.
- KV-caching: Throughout autoregressive technology, recomputing consideration over previous tokens is wasteful. KV-caching shops beforehand computed keys and values and reuses them for future tokens. This reduces technology complexity from quadratic to linear in sequence size, drastically rushing up long-form textual content technology.
- Prunning: Neural networks are sometimes overparameterized, so pruning removes redundant weights. This may be structured (eradicating whole neurons, heads, or layers) or unstructured (eradicating particular person weights). In observe, structured pruning is most popular as a result of it aligns higher with {hardware}, making the speedups truly realizable.
- Quantisation: Reduces numerical precision (e.g., from 32-bit floats to 8-bit integers) to shrink fashions and pace up computation. It lowers reminiscence utilization and improves effectivity on specialised {hardware}. Utilized both after coaching or throughout coaching, it might barely impression accuracy, however cautious calibration minimizes this. Efficient quantization additionally requires controlling worth ranges (e.g., small activation magnitudes) to keep away from info loss.
- Speculative decoding: Quickens technology utilizing two fashions: a small, quick draft mannequin and a bigger, correct goal mannequin. The draft proposes a number of tokens forward, and the goal verifies them in parallel — accepting matches and recomputing mismatches. This enables producing a number of tokens per step as a substitute of 1.
- Combination of consultants (MoE): As a substitute of activating all parameters for each token, MoE fashions use many specialised “consultants” and a gating mechanism to pick just a few per enter. This allows large mannequin capability with out proportional compute price. Notable examples embody Change Transformer, GLaM, and Mixtral.
A extra detailed weblog from NVIDIA for inference optimization would definitely be a fantastic learn if you need to make use of some extra superior methods.
Immediate engineering

Immediate engineering is a core a part of working with LLMs as a result of, in observe, the mannequin’s conduct isn’t just decided by its weights however by how it’s conditioned at inference time. The identical mannequin can produce dramatically totally different outcomes relying on how directions, context, and constraints are written.
Immediate engineering shouldn’t be one-shot design — it’s iteration. Small modifications in wording, ordering, or constraints can produce giant conduct shifts. Deal with prompts like code: check, measure, refine, and version-control them as a part of your system.
What makes a powerful immediate
- Be express concerning the job, not simply the subject: A weak immediate asks what you need (“Clarify RAG”). A powerful immediate specifies how you need it (“Clarify RAG in 5 bullet factors, specializing in failure modes, for a technical weblog viewers”).
- Separate instruction, context, and format: Clear prompts distinguish between what the mannequin ought to do, what info it ought to use, and how the output ought to look. For instance: directions (“summarize”), context (retrieved textual content), and format (“JSON with fields X, Y, Z”).
- Use examples (few-shot prompting): Offering 1–3 examples of desired input-output conduct considerably improves reliability for complicated duties. That is particularly helpful for classification or formatting.
- Constrain output construction aggressively: For those who want machine-readable or constant output, outline strict codecs (e.g. JSON, schemas).
- Management context, high quality: Extra context isn’t all the time higher. Irrelevant or noisy inputs degrade efficiency. Prioritize high-signal info, and in RAG techniques, guarantee retrieval is exact and filtered.
Sensible issues
- Observe immediate modifications like code. Know who modified what, when, and why. This makes debugging and rollback potential.
- Use templates the place potential. Break prompts into reusable elements (directions, context slots, formatting guidelines).
- Use routing techniques. Adjusting each the mannequin choice and the immediate relying on the person requests.
- Have structured testing. Run prompts in opposition to a set dataset and evaluate outputs utilizing metrics or structured rubrics (correctness, completeness, type).
- Maintain a human within the loop. For subjective qualities like readability or reasoning, human reviewers are nonetheless probably the most dependable sign — particularly for edge instances.
- Preserve a check suite of essential examples, particularly round security.
- Redteaming — and making an attempt to interrupt the defences that you simply’ve constructed at the moment are an business norm.
Analysis

Massive language fashions are used throughout a variety of duties — from structured query answering to open-ended technology — so no single metric can seize efficiency in each case. In observe, analysis relies upon closely on the issue you’re fixing. That stated, most approaches fall into just a few clear classes, spanning each conventional metrics and LLM-based evaluators.
Whatever the metrics used one of many metrics used an important a part of the analysis is the reference anchor for what could be thought-about good mannequin efficiency — the analysis dataset. It must be numerous, clear, grounded within the actuality and have the set of the goal duties in your mannequin.
Typical
These are sometimes amassing phrase stage statisitics, easy to implement and fast, nevertheless have limitations — they don’t perceive semantics.
- Levenstein distance — measures the minimal variety of single-character edits (insertions, deletions, or substitutions) wanted to remodel one string into one other.
- Perplexity — measures how nicely a language mannequin predicts a sequence, with decrease values indicating the mannequin assigns increased chance to the noticed textual content.
- BLEU — evaluates machine-translated textual content by measuring n-gram overlap between a candidate translation and a number of reference translations, emphasizing precision.
- ROUGE — evaluates textual content summarization (and technology) by measuring n-gram and sequence overlap between a generated textual content and reference texts, emphasizing recall.
- METEOR — evaluates generated textual content by aligning it with reference texts utilizing precise, stemmed, synonym matches, balancing precision-recall.
LLM-based
- BertScore: compares generated textual content to a reference utilizing contextual embeddings from BERT. As a substitute of matching precise phrases, it measures semantic similarity within the embeddings house — how shut the meanings are, making it robust at recognizing paraphrases and refined wording variations. It’s a sensible choice for summarization and translation duties.
- GPTScore: GPTScore makes use of a big language mannequin to guage outputs based mostly on reasoning — scoring issues like correctness, relevance, coherence, and even type, with out counting on reference. Its flexibility makes it ideally suited for subjective duties with out clear floor fact.
- SelfCheckGPT: Prompts the identical mannequin to critique its personal output, surfacing hallucinations, logical inconsistencies, or deceptive claims. Helpful in knowledge-heavy or reasoning duties, the place correctness issues however exterior verification could also be costly or sluggish.
- Bleurt: A BERT-based metric fine-tuned for analysis. It compares textual content utilizing realized semantic representations and outputs a single high quality rating reflecting fluency, that means preservation, and paraphrasing.
- GEval: In GEval you immediate the mannequin with a rubric (e.g., choose factuality or readability), and it returns a rating or detailed suggestions. This makes it particularly helpful for subjective duties the place conventional metrics fail, providing evaluations that really feel nearer to human judgment.
- Directed Acyclic Graph (DAG): strategy breaks analysis right into a sequence of smaller, rule-based checks. Every node is an LLM choose chargeable for one criterion, and the movement between nodes defines how choices are made. This construction reduces ambiguity and improves consistency, particularly when the duty could be checked step-by-step.
LLM-based analysis isn’t foolproof — it comes with its personal quirks:
- Bias: Choose fashions could favor longer solutions, sure writing types, or outputs that resemble their coaching knowledge.
- Variance: As a result of fashions are stochastic, small modifications (like temperature) can result in totally different scores for a similar enter.
- Immediate sensitivity: Even minor tweaks to your analysis immediate or rubric can shift outcomes considerably, making comparisons unreliable.
Deal with LLM analysis as a system that wants calibration. Standardize prompts, check them rigorously, and look ahead to hidden biases.
Trying past conventional duties — a category of metrics seems to be into evaluating RAG pipelines, that cut up the method of knowledge retrieval into retrieval and technology steps — and depend on metrics particular to every step, and a category that appears into summarization metrcis.
If you need to go deeper on LLM mannequin analysis, I might advocate this survey paper overlaying a number of strategies.
When to make use of LLM-as-a-judge vs conventional metrics?
Not each output could be neatly scored with guidelines. For those who’re evaluating issues like summarization high quality, tone, helpfulness, or how nicely directions are adopted, inflexible metrics fall brief. That is the place LLM-as-a-judge shines: as a substitute of checking for precise matches, you ask one other mannequin to grade responses in opposition to a rubric.
That stated, don’t throw out conventional metrics. When there’s a transparent floor fact — like factual accuracy or precise solutions. They’re quick, low-cost, and constant.
One of the best setups mix each: use conventional metrics for goal correctness, and LLM judges for subjective or open-ended high quality.
Analysis loops in manufacturing
Robust analysis doesn’t depend on a single methodology — it’s layered:
- Offline metrics: Begin with labeled datasets and automatic scoring to rapidly filter out weak mannequin variations.
- Human analysis: Usher in annotators or consultants to evaluate nuance — realism, usefulness, security and edge instances that metrics miss.
- On-line A/B testing: Lastly, measure real-world impression — clicks, retention, satisfaction.
As soon as your system is reside, analysis doesn’t cease — it evolves. Consumer interactions must be repeatedly logged, sampled, and reviewed. These real-world examples reveal failure instances and shifts in utilization patterns. The extra knowledge you will have logged from the mannequin the extra instruments you’d have for diagnostics: mannequin embeddings, response, response time and many others.
Even when your mannequin itself stays unchanged, its conduct and efficiency can nonetheless shift over time. This phenomenon — generally known as behaviour drift — sometimes emerges step by step as exterior components evolve, corresponding to modifications in person queries, the introduction of latest slang, shifts in area focus, and even small changes to prompts and templates. The problem is that this degradation is commonly refined and silent, making it simple to overlook till it begins affecting person expertise.
To catch drift early, pay shut consideration to each inputs and outputs.
- Enter: Observe modifications in embedding distributions, question lengths, subject patterns, or the looks of beforehand unseen tokens.
- Output: Observe shifts in tone, verbosity, refusal charges, or safety-related flags. Past these direct alerts, it’s additionally helpful to watch analysis proxies over time — issues like LLM-as-a-judge scores, person suggestions (corresponding to thumbs up or down), and task-specific heuristics on extened intervals of time, taking in account person behaviour seasonality, triggering alerts when statistical variations exceed outlined thresholds.
LLM Criticism
A standard criticism of LLMs is that they behave like “info averages”: as a substitute of storing or retrieving discrete details, they be taught a smoothed statistical distribution over textual content. This implies their outputs typically mirror the more than likely mix of many potential continuations somewhat than a grounded, single “true” assertion. In observe, this could result in overly generic solutions or confident-sounding statements which might be truly simply high-probability linguistic patterns.
On the core of this conduct is the cross-entropy goal, which trains fashions to attenuate the space between predicted token chances and the noticed subsequent token in knowledge. Whereas efficient for studying fluent language, cross-entropy solely rewards chance matching, not fact, causality, or consistency throughout contexts. It doesn’t distinguish between “believable wording” and “appropriate reasoning” — solely whether or not the following token matches the coaching distribution.
The limitation turns into sensible: optimizing for cross-entropy encourages mode-averaging, the place the mannequin prefers secure, central predictions over sharp, verifiable ones. That is why LLMs could be wonderful at fluent synthesis however fragile at duties requiring exact symbolic reasoning, long-horizon consistency, or factual grounding with out exterior techniques like retrieval or verification.
Abstract
Constructing and deploying giant language fashions shouldn’t be about mastering a single breakthrough concept, however about understanding what number of interdependent techniques come collectively to supply coherent intelligence. From tokenization and embeddings, by way of attention-based architectures, to coaching methods like pre-training, fine-tuning, and reinforcement studying, every layer contributes a particular perform in turning uncooked textual content into succesful, controllable fashions.
What makes LLM engineering difficult — and thrilling — is that efficiency isn’t decided by one part in isolation. Effectivity methods like KV-caching, FlashAttention, and quantization matter simply as a lot as high-level decisions like mannequin structure or alignment technique. Equally, success in manufacturing relies upon not solely on coaching high quality, but in addition on inference optimization, analysis rigor, immediate design, and steady monitoring for drift and failure modes.
Seen collectively, LLM techniques are much less like a single mannequin and extra like an evolving stack: knowledge pipelines, coaching targets, retrieval techniques, decoding methods, and suggestions loops all working in live performance. Engineers who develop a psychological map of this stack are capable of transfer past “utilizing fashions” and begin designing techniques which might be dependable, scalable, and aligned with real-world constraints.
As the sector continues to evolve — towards longer context home windows, extra environment friendly architectures, stronger reasoning talents, and tighter human alignment — the core problem stays the identical: bridging statistical studying with sensible intelligence. Mastering that bridge is what shapes the work an LLM engineer.
Notable fashions within the chronological order
BERT (2018), GPT-1 (2018), RoBERTa (2019), SpanBERT (2019), GPT-2 (2019), T5 (2019), GPT-3 (2020), Gopher (2021), Jurassic-1 (2021), Chinchila (2022), LaMDA (2022), LLaMA (2023)
Preferred the creator? Keep linked!
For those who favored this text share it with a pal! To learn extra on machine studying and picture processing matters press subscribe!
Have I missed something? Don’t hesitate to go away a be aware, remark or message me immediately on LinkedIn or Twitter!














{kind=link}