



a dependable, low-latency, cost-efficient RAG system on a SQL desk that shops massive paperwork in long-text fields — with out altering the present schema?
This isn’t a theoretical downside.
In most enterprises, essential enterprise information already lives inside conventional relational databases. Proposals, reviews, contracts, articles — all saved in TEXT or LONGTEXT columns — designed for key phrase matching and aggregations, not semantic retrieval.
With the arrival of LLMs, enterprise calls for have advanced to structured computation, deep semantic understanding and contextual insights in a pure, conversational method.
For instance:
- What number of tasks over $1M had been accredited from 2023 to 2025?
- Summarize the main traits seen in know-how during the last 6 months
- What has been the differentiators of successful proposals in 2025?
They require a retrieval technique that may resolve when to compute, when to semantically search, and when to mix each. On this article, I’ll show an Agentic RAG structure that operates straight on high of a conventional SQL database — with out schema adjustments — and focus on the design rules required to make it dependable in manufacturing.
System setup
For this illustration, I’ve used a subset of the Social Animal 10K Articles with NLP dataset, which has numerous information articles and weblog posts together with metadata. The SQL database created has the next columns — url, title, authors, published_date, article_category, word_count and the full_content.
The title could be thought of to be a singular identifier (major key) for the content material. The article classes are know-how, enterprise, sports activities, journey, well being, leisure, politics and style. The articles are distributed roughly evenly throughout the classes. The LLM used is gemini-2.5-flash and FAISS to index and retailer the vector embeddings. The design is relevant for any alternative of LLM or vector database.
Structure
Apart from embedding the uncooked textual content, we mirrored the vector retailer metadata with the identical fields current in SQL (besides the complete content material). This permits for Filtering, as we are going to see within the outcomes. For lengthy paperwork, a sliding window chunking and embedding technique could be adopted with the metadata connected to every embedding.
The metadata code snippet is connected
for idx, row in df_sql.iterrows():
content material = str(row['full_content']).strip()
if not content material:
proceed
metadata = {
"supply": row.get('url', ''),
"title": row.get('title', ''),
"authors": str(row.get('authors', '')),
"article_category": str(row.get('article_category', 'unknown')),
"published_date": str(row.get('published_date', '')),
"word_count": int(row.get('content_word_count', 0))
}
doc = Doc(page_content=content material, metadata=metadata)
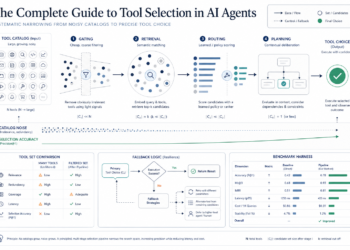
paperwork.append(doc)We constructed two specialised, clever instruments that the ReAct agent can invoke utilizing the next structure. The ReAct (router) agent orchestrates all the question pipeline by intelligently deciding which device to invoke primarily based on the character of the question. It makes use of the metadata and question context to find out whether or not the SQL device, the vector device, or a hybrid method is most acceptable. The next determine depicts the question resolution move:

The instruments are as follows:
- search_database (SQL device): Handles questions that require computation, aggregation or advanced logic. It executes SQL queries
- search_articles (Vector device): Handles questions on content material, subject or particular entities. Accepts a pure language question, and optionally, metadata filters to execute a world semantic search (eg: “articles about youngsters“) or search a subset of the info
As could be seen within the above determine, a question can take the next pathways:
- For computations (eg; what number of articles..), inequalities/vary (eg: Articles revealed between Jan and Apr 2023) or aggregations (eg; What’s the common phrase depend..), use the SQL device solely.
- Semantic search, with or with out filters, use the Vector device as defined above.
- Hybrid question: Hybrid queries are important while you want each structured information (e.g., filtering by date) and unstructured content material (e.g., semantic search on articles). The question has a metadata filter standards (often class or a date vary), for which the SQL device is used to fetch articles. Then the record of titles is handed to the Vector device to carry out a semantic search on solely these articles. An instance can be “between march and should 2023 is there any article about mom’s day in style“
Outcomes
Listed here are the outcomes of some queries of every kind. It could be fascinating to notice the device pathway adopted in every case.
1. “what are the articles by yr and class?” — It is a advanced computation question, so solely the SQL device will likely be used.
The result’s right here
QUERY: what are the articles by yr and class ?
TOOL SELECTION:
- search_database: {'question': "SELECT strftime('%Y', published_date) AS yr, article_category, COUNT(*) FROM articles GROUP BY yr, article_category"}
DOCUMENTS SELECTED:
- Device Output: [('1970', 'business', 1), ('2001', 'politics', 1), ('2013', 'politics', 1), ('2018', 'entertainment', 1), ('2020', 'entertainment', 1), ('2020', 'sports', 1), ('2022', 'fashion', 1), ('2023', 'business', 19), ('2023', 'entertainment', 16), ('2023', 'fashion', 16), ('2023', 'health', 18), ('2023', 'politics', 16), ('2023', 'sports', 16), ('2023', 'technology', 18), ('2023', 'travel', 18)]
RESULT:
Listed here are the variety of articles by yr and class:
* 1970: enterprise (1)
* 2001: politics (1)
* 2013: politics (1)
* 2018: leisure (1)
* 2020: leisure (1), sports activities (1)
* 2022: style (1)
* 2023: enterprise (19), leisure (16), style (16), well being (18), politics (16), sports activities (16), know-how (18), journey (18)2. “what articles about youngsters do you will have?” — This doesn’t match any of metadata classes that the schema consists of, so the agent decides to make use of the Vector device with a world semantic search.
The result’s right here
QUERY: what articles about youngsters do you will have
TOOL SELECTION:
- search_articles: {'question': 'youngsters'}
DOCUMENTS SELECTED:
- Device Output: --- Doc 1 ---
Supply: https://www.filmcompanion.in/options/indepth-stories/streaming/best-childrens-movies-on-amazon-prime-video-netflix-hotstar-klaus-kung-fu-panda-jagga-jasoos-childrens-day-2020
Title: 10 Movies That Youngsters Ought to Watch
Class: leisure
Date: 2020-11-14 02:30:36
Content material: On this youngsters's day, this is a listing of tales designed to assist younger ones perceive the world round them, achieve life classes and be dazzled by vibrant creativeness. It is a good time to be a...
- https://www.filmcompanion.in/options/indepth-stories/streaming/best-childrens-movies-on-amazon-prime-video-netflix-hotstar-klaus-kung-fu-panda-jagga-jasoos-childrens-day-2020
- https://africabusiness.com/2023/04/07/save-the-children-and-thinkmd-expand-partnership-to-improve-the-lives-of-children-globally/
- https://www.tcpalm.com/story/information/training/st-lucie-county-schools/2023/04/11/books-stay-in-st-lucie-county-schools-but-most-move-to-high-school/70098338007/
RESULT:
Listed here are some articles about youngsters:
1. 10 Movies That Youngsters Ought to Watch (leisure)
2. Save the Youngsters and THINKMD Develop Partnership to Enhance the Lives of Youngsters Globally (well being)
3. St. Lucie County Faculty Board decides to maintain challenged books at school libraries (well being)3. “what are the traits in style?” — The agent finds the class = style, and runs the semantic match utilizing the Vector device with this filter standards.
The result’s right here
QUERY: what are the traits in style
TOOL SELECTION:
- search_articles: {'question': 'traits', 'filter_category': 'style'}
DOCUMENTS SELECTED:
- Device Output: --- Doc 1 ---
Supply: https://www.sightunseen.com/2023/04/the-best-thing-we-saw-in-milan-today-india-mahdavi-for-gebruder-thonet-vienna/
Title: The Finest Factor We Noticed in Milan At present: India Mahdavi for Gebrüder Thonet Vienna - Sight Unseen
Class: style
Date: 2023-04-18 12:00:00
Content material: Stay With Objects
The Finest Factor We Noticed in Milan At present: India Mahdavi for Gebrüder Thonet Vienna
Sight Unseen is on the bottom on the Milan Furnishings Honest proper now and we’ll be bringing you load...
- https://www.sightunseen.com/2023/04/the-best-thing-we-saw-in-milan-today-india-mahdavi-for-gebruder-thonet-vienna/
- https://themoderndaygirlfriend.com/clean-make-up-skincare-brand-in-2023/
- https://poprazzi.com/the-80s-inspired-jewelry-trend-im-absolutely-fawning-over/
RESULT:
The search outcomes point out the next traits in style: India Mahdavi for Gebrüder Thonet Vienna, clear make up & skincare, and 80's-inspired jewellery.4. “inform me know-how articles about crypto in 2023” — It is a hybrid question the place the SQL device will likely be used to get the titles in 2023 for class = know-how, then the Vector device will likely be invoked with the question = crypto and the title record. The end result will likely be discovered inside that subset.
The result’s right here
QUERY: inform me know-how articles about crypto in 2023
TOOL SELECTION:
- search_database: {'question': "SELECT title FROM articles WHERE article_category = 'know-how' AND published_date LIKE '2023%'"}
- search_articles: echojobs.io', 'Driving data to deliver net zero with life cycle assessments', 'The Future of Work: Trends and Predictions for the Next Decade', 'Risks of Outsourcing Software Development to Uruguay', 'Kochie Arrest News Addressed, Affected By Scam', 'Paying attention to employee retention
DOCUMENTS SELECTED:
- Device Output: [('NPR quits Twitter, says Musk-led platform is “undermining our credibility”',), ('Crypto.com arena considers rebrand after FTX fallout reignites investor anger',), ("World's Biggest EV Battery Maker Unveils S",), ('What Checks Should You Perform Before Buying a Used Car? - Free Car Mag',), ('Preeclampsia Diagnostics Market 2023-2030 Overall Analysis Report | Fortune Business Insights',), ('Spanish startup on ‘mission to save planet’s beer’ from climate crisis',), ('Best third-party apps for Re...
- Tool Output: --- Document 1 ---
Source: https://www.analyticsinsight.net/crypto-com-arena-considers-rebrand-after-ftx-fallout-reignites-investor-anger/
Title: Crypto.com arena considers rebrand after FTX fallout reignites investor anger
Category: technology
Date: 2023-04-19 01:15:52
Content: The Crypto.com Arena, formerly known as the Staples Center, is reportedly considering a rebrand after the recent controversy surrounding FTX, a cryptocurrency exchange. The FTX fallout reignited anger among investors, wh...
- https://www.analyticsinsight.net/crypto-com-arena-considers-rebrand-after-ftx-fallout-reignites-investor-anger/
- https://theprint.in/ani-press-releases/aave-chainlink-and-binance-are-concentrating-on-enhancing-the-shapella-while-big-eyes-coin-is-aiming-for-a-significant-final-push/1527613/
- https://echojobs.io/job/stripe-software-engineer-service-platform-wndr6
RESULT:
Here are some technology articles from 2023 that mention crypto:
1. **Crypto.com arena considers rebrand after FTX fallout reignites investor anger**: This article discusses the possibility of the Crypto.com Arena rebranding due to the controversy surrounding the FTX cryptocurrency exchange.
2. **Aave, Chainlink, and Binance are concentrating on enhancing the Shapella, while Big Eyes Coin is aiming for a significant final push**: This article mentions the Shapella upgrade and its implications for cryptocurrencies on the Ethereum network, including Binance, Aave, and Chainlink.
3. **Software Engineer, Service Platform at Stripe | echojobs.io**: This article mentions Stripe, a financial infrastructure platform that allows businesses to accept payments.Key Considerations
As with any architecture, there are design principles to be considered for a robust application. Here are a few of them:
- Tool docstrings vs system prompt: These are two types of instructions that guide the agent behavior in different ways. It is important to use them for the intended purposes without any overlap or conflict for a reliable agent performance. Tool docstring, located inside the
@tooldecorator, describes what the tool does and how to use it. Besides the tool name, it defines the parameters, types and descriptions.
Here is the example of the search_articles tool docstring.
@tool
def search_articles(query: str, filter_category: Optional[str] = None, ...):
"""Helpful for locating details about particular matters, summaries, or particulars inside articles.
You'll be able to filter by metadata for precision:
- `filter_category`: 'well being', 'tech', and many others.
- `filter_titles`: Checklist of tangible titles to retrieve (BATCH MODE).
- `filter_date`: Revealed date (YYYY-MM-DD) for EXACT or PARTIAL match solely.
...
"""- However, the system immediate intelligently guides the routing technique for the agent, enabling it to resolve when to make use of the SQL device, Vector device or a mix. It is usually essentially the most advanced and fragile part of the applying. It defines how instruments are mixed in hybrid workflows, offers examples of appropriate device utilization, and specifies necessary guidelines and constraints. To adequately design the system immediate, It’s essential to start with a take a look at case repository of anticipated person queries, present examples within the system immediate, and proceed enriching it for deviations that come up for edge instances throughout operations.
Here’s a pattern of the system immediate
system_prompt = (
"1. **LISTING/BROWSING QUERIES** (e.g., 'what articles are in politics'):n"
" - **ALWAYS use [search_database] to record titlesn"
" - DO NOT use [search_articles] with no semantic queryn"
...
"### MANDATORY RULESn"
"1. **DATE RANGES & INEQUALITIES**: Use SQL first, then cross titles to vector tooln"
...
)- Pre and Submit filtering vector databases: It is a refined level that may have unintended and hard-to-explain outcomes for particular queries. Think about the next two queries the place the one distinction is the mis-spelt identify: “summarize articles about Doo ley in politics on seventeenth apr 2023” and “summarize articles about Dooley in politics on seventeenth apr 2023“. Each the queries comply with an identical paths, whereby the SQL device efficiently selects the titles for this class and date (there may be just one article mentioning Choose Dooley), then the Vector device is known as on this title record with the question. Surprisingly, for the primary question, the Vector device returns
"Device Output: No paperwork discovered matching the standards."for this minor spelling error even when the record has just one article to pick from, whereas for the second question it returns the right article.
Right here is the results of the primary question
QUERY: QUERY: summarize articles about Doo ley in politics on seventeenth apr 2023
TOOL SELECTION:
- search_database: {'question': "SELECT title FROM articles WHERE published_date LIKE '2023-04-17%' AND article_category = 'politics'"}
- search_articles: {'question': 'Doo ley', 'filter_category': 'politics', 'filter_titles': ['Judge Dooley Ends Hartford Police Consent Decree Despite Concerns']}
DOCUMENTS SELECTED:
- Device Output: [('Judge Dooley Ends Hartford Police Consent Decree Despite Concerns',)]
- Device Output: No paperwork discovered matching the standards.And the second question
QUERY: summarize articles about Dooley in politics on seventeenth apr 2023
TOOL SELECTION:
- search_database: {'question': "SELECT title FROM articles WHERE published_date LIKE '2023-04-17%' AND article_category = 'politics'"}
- search_articles: {'question': 'Dooley', 'filter_category': 'politics', 'filter_titles': ['Judge Dooley Ends Hartford Police Consent Decree Despite Concerns']}
DOCUMENTS SELECTED:
- Device Output: [('Judge Dooley Ends Hartford Police Consent Decree Despite Concerns',)]
- Device Output: --- Doc 1 ---
Supply: https://www.nbcconnecticut.com/information/native/judge-ends-hartford-police-consent-decree-despite-concerns/3015203/
Title: Choose Dooley Ends Hartford Police Consent Decree Regardless of Considerations
Class: politics
Date: 2023-04-17 05:36:24
Content material: Choose Dooley has ended the practically 50 years of federal oversight of police in Hartford, regardless of continued considerations the division nonetheless has not employed sufficient minority officers to mirror the town's massive Black and Hispanic populations.And the reason being not only a weaker embedding as a result of incorrect spelling. It’s as a result of FAISS (and Chroma and many others) carry out post-filtering — first do a world seek for the question, after which filter the outcomes for the metadata (= the title record). On this case, the right article doesn’t characteristic within the top_k = 3 articles after semantic search. A pre-filtering database, then again, would have completed the semantic search solely on the articles within the title record and located the right article even with the inaccurate spelling.
- Can all metadata filters be faraway from the Vector Device?: Sure, it’s attainable, however its a increased value possibility, as easy semantic queries with a metadata filter (similar to class or writer), will grow to be a hybrid question, requiring two device calls, including to token utilization and latency. A realistic center floor can be to maintain dates (and presumably different numeric metadata similar to phrase counts on this case) within the SQL solely, and mirror all textual content and categorical metadata within the vector database.
Conclusion
Constructing RAG on high of SQL isn’t about including embeddings. It’s about designing the correct retrieval technique.
When structured metadata and long-form content material dwell in the identical desk, the true problem is orchestration — deciding when to compute with SQL, when to semantically search, and when to mix each. Delicate particulars like metadata filtering and gear routing could make the distinction between a dependable system and one which silently fails.
With a well-designed Agentic RAG layer, legacy SQL databases can energy semantic purposes with out schema adjustments, pricey migrations, or efficiency trade-offs.
Join with me and share your feedback at www.linkedin.com/in/partha-sarkar-lets-talk-AI
Reference
Social Animal 10K Articles with NLP — Dataset by Alex P (Proprietor) (CC BY-SA 4.0)
Pictures used on this article are generated utilizing Google Gemini. Dataset used below CC-BY-SA 4.0 license. Figures and underlying code created by me.
















{kind=link}