Whereas engaged on my Data Distillation drawback for intent classification, I confronted a puzzling roadblock. My setup concerned a instructor mannequin, which is RoBERTa-large (finetuned on my intent classification), and a scholar mannequin, which I used to be making an attempt to coach with out dropping an excessive amount of accuracy in comparison with the instructor.
I experimented with a number of mapping strategies, connecting each 2nd layer to the scholar layer, averaging two instructor layers into one, and even assigning customized weights like giving (0.3 to l1 and 0.7 to l2). However it doesn’t matter what mixture I attempted, the instructor’s accuracy by no means matched the scholar mannequin.
That’s once I began exploring how one can map essentially the most informative layers to my scholar mannequin in order that the scholar can maximize its efficiency. I wished a solution to quantify which layer of the instructor mannequin really issues for distillation.
Curious, I made a decision to adapt the thought to textual content information – and BOOM!!!, it really labored!For the primary time, my scholar mannequin began pondering virtually like its instructor.
Supply: Writer
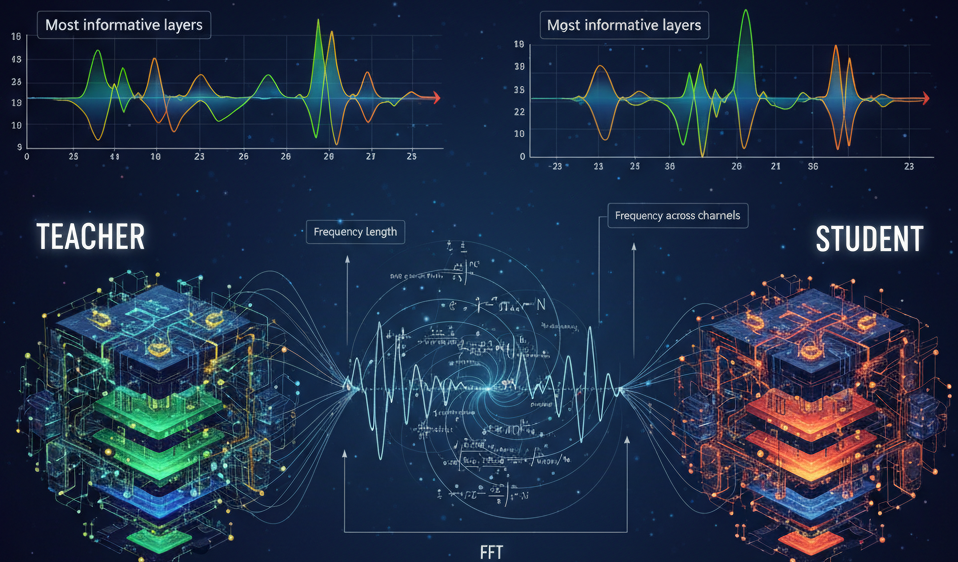
Right here’s the layer depth graph of my fine-tuned RoBERTa-large mannequin. Based mostly on the spectral insights, I chosen layers 1–9 and 21–23 for my scholar mannequin throughout information distillation, those carrying the richest info.
I can’t share my dataset or code for confidentiality causes, however I’ll stroll you thru how the paper’s image-based strategy impressed my text-based adaptation, and how one can take into consideration doing the identical.
Behind the Scenes: How FFT Reveals a Mannequin’s Spectral Soul
So, let’s begin with spectral depth, and slowly dive into the actual magician right here: the Quick Fourier Rework (FFT).
Within the spectralKD paper, the authors introduce a framework that helps us to see Imaginative and prescient Transformer(ViTs), not simply what they’re predicting, but additionally how the knowledge flows within the layers. As an alternative of counting on instinct or visualisation, they use spectral evaluation, a manner to measure the frequency richness of the mannequin’s inner representations.
Think about every Transformer layer because the musician in an orchestra, some layers play excessive notes(tremendous particulars), whereas others play low notes(broad options). The FFT helps us to hear to every participant’s music individually and filter out which one is having the strongest melodies, i.e., essentially the most information-rich indicators.
Supply: Writer
Step 1: Function maps, The uncooked materials
B is batch measurement C is variety of channels and, H,W is the spatial top and width.
Step 2: Making use of the fourier Rework
The authors apply a 1-dimensional FFT alongside the channel dimension to translate these real-valued activations into the frequency area: F(X)=FFT(X)
This implies: For each spatial location (b, h, w), a 1D FFT is computed throughout all channels. The result’s a complex-valued tensor (since FFT outputs actual + imaginary components). F(X) subsequently tells us how a lot of every frequency is current in that layer’s illustration.
And should you’re questioning, “Why FFT although?” — maintain that thought. As a result of later on this weblog, we’re going to uncover precisely why FFT is the proper instrument to measure a mannequin’s internal depth.
Step 3: measuring frequency power
Re(F(X)) is the actual half, Im(F(X)) is the imaginary half.
Step 4: Averaging throughout the map
Now we wish to summarize this depth throughout all positions within the layer:
This step tells us the typical depth of the one channel
After which you possibly can merely do common of every channels. Voilà! Now you have got the spectral depth of the one layer of the Imaginative and prescient Transformer.
Peeking into the Frequency Realm: The Fourier Lens of SpectralKD
Let’s look into the Quick Fourier Rework:
Xₖ is the enter sequence (your sign, characteristic, or activation sample). xₙ is the frequency part on the frequency index. N is the variety of factors within the sequence (i.e., variety of channels or options).
Every time period e⁻ʲ²πᵏⁿ/ᴺ acts as a rotating phasor, a tiny complicated wave spinning via the sign area, and collectively, they kind probably the most stunning concepts in sign processing.
Supply: Writer (Right here, a rotating phasor e⁻ʲ²πᵏⁿ/ᴺ is getting multiplied by g(t) in a fancy airplane)supply: Writer (Common out all of the factors within the complicated airplane, then it will provide you with the middle of mass of the phasor entity, and it will get peaked solely at a selected frequency or Ok (within the above case, it’s 3))
.OMG! What simply occurred right here? Let me break it down.
Whenever you multiply your hidden activations xₙ (say, throughout channels or characteristic dimensions) by this phasor, you’re basically asking:
“Hey, layer, how a lot of the k-th sort of variation do you include in your representations?”
Every frequency okay corresponds to a definite sample scale throughout the characteristic dimensions.
Now right here’s the enjoyable half: if some layer resonates with a specific frequency sample, the multiplication of the Fourier Rework aligns completely, and the sum within the Fourier components produces a robust response for that okay.
If not, the rotations cancel out, that means that frequency doesn’t play a giant function in that layer’s illustration.
So, the Fourier Rework isn’t including something new; it’s simply discovering out how our layer encodes info throughout completely different scales of abstraction.
It’s like zooming out and realizing:
Some layers hum quietly with clean, conceptual meanings (low frequencies),
Others buzz with sharp, detailed interactions between tokens (excessive frequencies).
The FFT mainly turns a layer’s hidden states right into a frequency fingerprint — a map of what varieties of knowledge that layer is specializing in.
And that’s precisely what SpectralKD makes use of to determine which layers are really doing the heavy lifting throughout information distillation.
From Imaginative and prescient to Language: How Spectral Depth Guided My Intent Classifier
Supply: Writer
Let a layer activation tensor be:
the place:
N = variety of samples (batch measurement)
L = sequence size (variety of tokens/time steps)
H = hidden dimension (variety of channels/options produced by the layer)
Every Pattern i has an activation matrix Xᵢ ∈ Rᴸ ˣ ᴴ (sequence positions x hidden options)
Now once more, you possibly can compute the FFT of that Xᵢ after which measure the frequency size utilizing the actual and imaginary elements and common out throughout the channels, after which for every layer.
Frequency size:
Frequency throughout channels:
Frequency throughout a layer:
Right here, Ok is the variety of bins retained.
Conclusion
Their evaluation exhibits two main insights:
Not all layers contribute equally. In uniform transformer architectures, just a few early and remaining layers present robust spectral exercise, the true “hotspots” of knowledge stream.
Totally different transformer sorts, comparable melodies. Regardless of architectural variations, each hierarchical and uniform transformers share surprisingly comparable spectral patterns, hinting at a common manner these fashions be taught and symbolize information.
Constructing on these findings, SpectralKD introduces a easy, parameter-free information distillation (KD) technique. By selectively aligning the spectral habits of early and remaining layers between a instructor and a scholar mannequin, the scholar learns to mimic the instructor’s spectral signature, even in intermediate layers that had been by no means explicitly aligned.
The outcomes are hanging within the paper: the distilled scholar (DeiT-Tiny) doesn’t simply match efficiency on benchmarks like ImageNet-1K, it additionally learns to suppose spectrally just like the instructor, capturing each native and world info with outstanding allegiance.
Finally, SpectralKD bridges interpretability and distillation, providing a recent solution to visualize what occurs inside transformers throughout studying. It opens a brand new line of analysis, the authors name “distillation dynamics”, a journey into how information itself flows, oscillates, and harmonizes between instructor and scholar networks.
































{kind=link}