


and Imaginative and prescient Mannequin?
Pc Imaginative and prescient is a subdomain in synthetic intelligence with a variety of functions specializing in picture processing and understanding. Historically addressed by Convolutional Neural Networks (CNNs), this area has been revolutionized by the emergence of transformer structure. Whereas transformers are well-known for his or her functions in language processing, they are often successfully tailored to kind the spine of many imaginative and prescient fashions. On this article, we are going to discover state-of-the-art imaginative and prescient and multimodal fashions, comparable to ViT (Imaginative and prescient Transformer), DETR (Detection Transformer), BLIP (Boostrapping Language-Picture Pretraining), and ViLT (Imaginative and prescient Language Transformer), focusing on numerous pc imaginative and prescient duties together with picture classification, segmentation, image-to-text conversion, and visible query answering. These duties have quite a lot of real-world functions, from annotating photos at scale, detecting abnormalities in medical photos to extracting textual content from paperwork and producing textual content responses primarily based on visible information.
Comparisons with CNNs
Earlier than the broad adoption of basis fashions, CNNs have been the dominant options for many pc imaginative and prescient duties. In a nutshell, CNNs kind a hierarchical deep studying structure that consists of characteristic maps, pooling, linear layers and totally related layers. In distinction, imaginative and prescient transformers leverage the self-attention mechanism that enables picture patches to attend to one another. Additionally they have much less inductive bias, which means they’re much less constrained by particular mannequin assumptions as CNNs, however consequently require considerably extra coaching information to realize sturdy efficiency on generalized duties.
Comparisons with LLMs
Transformer-based imaginative and prescient fashions adapt the structure utilized by LLMs (Giant Language Fashions), including additional layers that convert picture information into numerical embeddings. In an NLP job, textual content sequences bear the method of tokenization and embedding earlier than they’re consumed by the transformer encoder. Equally, picture/visible information undergo the process of patching, place encoding, picture embedding earlier than feeding into the imaginative and prescient transformer encoder. All through this text, we are going to additional discover how the imaginative and prescient transformer and its variants construct upon the transformer spine and prolong capabilities from language processing to picture understanding and picture technology.
Extensions to Multimodal Fashions
Developments in imaginative and prescient fashions have pushed the curiosity in growing multimodal fashions able to course of each picture and textual content information concurrently. Whereas imaginative and prescient fashions concentrate on uni-directional transformation of picture information to numerical illustration and sometimes produce score-based output for classification or object detection (i.e. image-classification and image-segmentation job), multimodal fashions require bidirectional processing and integration between totally different information varieties. For instance, an image-text multimodal mannequin can generate coherent textual content sequences from picture enter for picture captioning and visible query answering duties.
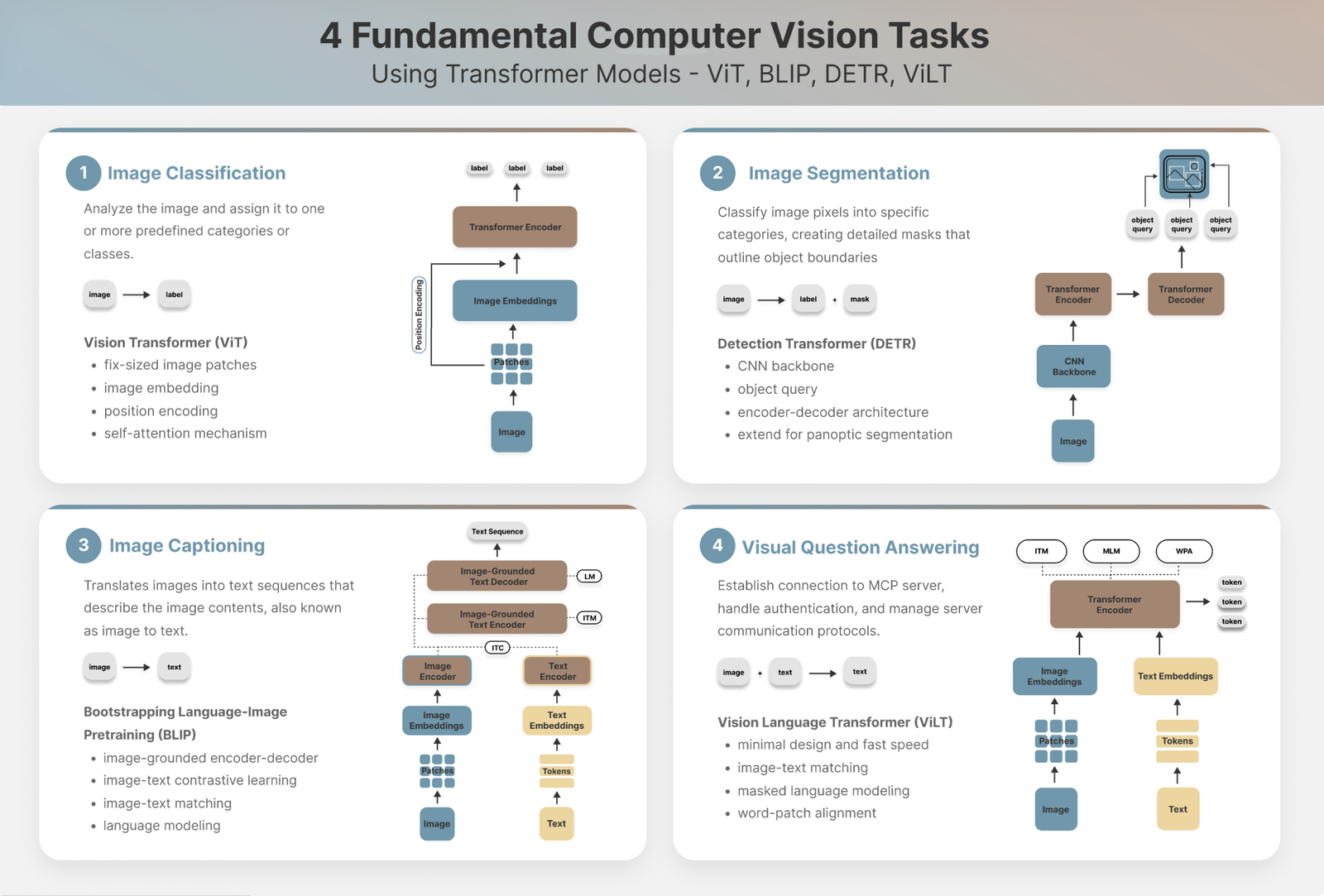
4 Varieties of Elementary Pc Imaginative and prescient Duties
0. Mission Overview
We are going to discover the main points of those 4 basic pc imaginative and prescient duties and the corresponding transformer fashions specialised for every job. These fashions differ primarily of their encoder and decoder architectures, which give them distinct capabilities for deciphering, processing, and translating throughout totally different textual or visible modality.

To make this information extra interactive, I’ve designed a Streamlit internet app as an example and examine outputs of those pc imaginative and prescient duties and fashions. We are going to introduce the tip to finish app improvement on the finish of this text.
Beneath is a sneak peek of output primarily based on the uploaded picture, displaying job title, output, runtime, mannequin title, mannequin kind, by operating the default fashions from Hugging Face pipelines.

1. Picture Classification

Firstly, let’s introduce picture classification — a fundamentals pc imaginative and prescient job that assigns photos to a predefined set of labels, which might be achieved by a fundamental Imaginative and prescient Transformer.
ViT (Imaginative and prescient Transformer)

Imaginative and prescient Transformer (ViT) serves because the cornerstone for a lot of pc imaginative and prescient fashions later launched on this article. It persistently outperforms CNN on picture classification duties by its encoder-only transformer structure. It processes picture inputs and outputs likelihood scores for candidate labels. Since picture classification is solely a picture understanding job with out technology necessities, ViT’s encoder-only structure is well-suited for this objective.
A ViT structure consists of following elements:
- Patching: break down enter photos into small, fastened dimension patches of pixels (sometimes 16×16 pixels per patch) in order that native options are preserved for downstream processing.
- Embedding: convert picture patches into numerical representations, often known as vector embeddings, in order that photos with comparable options are projected as embeddings with nearer proximity within the vector house.
- Classification Token (CLS): extract and combination info from all picture patches into one numeric illustration, making it notably efficient for classification.
- Place Encoding: protect the relative positions of the unique picture pixels. CLS token is all the time at place 0.
- Transformer Encoder: course of the embeddings by layers of multi-headed consideration and feed-forward networks.
The mechanism behind ViT ends in its effectivity in capturing world dependencies, whereas CNN primarily depends on native processing by convolutional kernels. However, ViT has the disadvantage of requiring an enormous quantity of coaching information (often tens of millions of photos) to iteratively modify mannequin parameters in consideration layers to realize sturdy efficiency.
Implementation
Hugging Face pipeline considerably simplifies the implementation of picture classification job by abstracting away the low-level picture processing steps.
from transformers import pipeline
from PIL import Picture
picture = Picture.open(image_url)
pipe = pipeline(job="image-classification", mannequin=model_id)
output = pipe(picture=picture)- enter parameters:
mannequin: you’ll be able to select your personal mannequin or use the default mannequin (i.e. “google/vit-base-patch16-224”) when themannequinparameter is just not specified.job: present a job title (e.g. “image-classification”, “image-segmentation”)picture: present a picture object by an URL or a picture file path.
- output: the mannequin generates scores for the candidate labels.
We in contrast outcomes of the default picture classification mannequin “google/vit-base-patch16-224” by offering two comparable photos with totally different compositions. As we will see, this baseline mannequin is well confused, producing considerably totally different outputs (“espresso” vs. “mircowave”), regardless of each photos containing the identical important object.
“Espresso Mug” Picture Output

[
{ "label": "espresso", "score": 0.40687331557273865 },
{ "label": "cup", "score": 0.2804579734802246 },
{ "label": "coffee mug", "score": 0.17347976565361023 },
{ "label": "desk", "score": 0.01198530849069357 },
{ "label": "eggnog", "score": 0.00782513152807951 }
]“Espresso Mug with Background” Picture Output

[
{ "label": "microwave, microwave oven", "score": 0.20218633115291595 },
{ "label": "dining table, board", "score": 0.14855517446994781 },
{ "label": "stove", "score": 0.1345038264989853 },
{ "label": "sliding door", "score": 0.10262308269739151 },
{ "label": "shoji", "score": 0.07306522130966187 }
]Strive a distinct mannequin your self utilizing our Streamlit internet app and see if it generates higher outcomes.
2. Picture Segmentation

Picture segmentation is one other widespread pc imaginative and prescient job that requires a vision-only mannequin. The target is just like object detection however requires greater precision on the pixel degree, producing masks for object boundaries as an alternative of drawing bounding bins as required for object detection.
There are three important forms of picture segmentation:
- Semantic segmentation: predict a masks for every object class.
- Occasion segmentation: predict a masks for every occasion of the article class.
- Panoptic segmentation: mix occasion segmentation and semantic segmentation by assigning every pixel an object class and an occasion of that class.
DETR (Detection Transformer)

Though DETR is broadly used for object detection, it may be prolonged to carry out panoptic segmentation job by including a segmentation masks head. As proven within the diagram, it makes use of the encoder-decoder transformer structure with a CNN spine for characteristic map extraction. DETR mannequin learns a set of object queries and it’s educated to foretell bounding bins for these queries, adopted by a masks prediction head to carry out exact pixel-level segmentation.
Mask2Former
Mask2Former can also be a typical selection for picture segmentation job. Developed by Fb AI Analysis, Mask2Former typically outperforms DETR fashions with higher precision and computational effectivity. It’s achieved by making use of a masked consideration mechanism as an alternative of world cross-attention to focus particularly on foreground info and important objects in a picture.
Implementation
We use the pipeline implementation similar to picture classification, by merely swapping the duty parameter to “image-segmentation”. To course of the output, we extract the article labels and masks, then show the masked picture utilizing st.picture()
from transformers import pipeline
from PIL import Picture
import streamlit as st
picture = Picture.open(image_url)
pipe = pipeline(job="image-segmentation", mannequin=model_id)
output = pipe(picture=picture)
output_labels = [i['label'] for i in output]
output_masks = [i['mask'] for i in output]
for m in output_masks:
st.picture(m)We in contrast the efficiency of DETR (“fb/detr-resnet-50-panoptic”) and Mask2Former (“fb/mask2former-swin-base-coco-panoptic”) that are each fine-tuned on panoptic segmentation. As displayed within the segmentation outputs, each DETR and Mask2Former efficiently establish and extract the “cup” and the “eating desk”. Mask2Former makes inference at a quicker pace (2.47s in comparison with 6.3s for DETR) and likewise manages to establish “window-other” from the background.
DETR “fb/detr-resnet-50-panoptic” output
[
{
'score': 0.994395,
'label': 'dining table',
'mask':
},
{
'score': 0.999692,
'label': 'cup',
'mask':
}
] 
Mask2Former “fb/mask2former-swin-base-coco-panoptic” output
[
{
'score': 0.999554,
'label': 'cup',
'mask':
},
{
'score': 0.971946,
'label': 'dining table',
'mask':
},
{
'score': 0.983782,
'label': 'window-other',
'mask':
}
] 
3. Picture Captioning

Picture Captioning, often known as picture to textual content, interprets photos into textual content sequences that describe the picture contents. This job requires capabilities of each picture understanding and textual content technology, due to this fact effectively fitted to a multimodal mannequin that may course of picture and textual content information concurrently.
Visible Encoder-Decoder
Visible Encoder-Decoder is a multimodal structure that mixes a imaginative and prescient mannequin for picture understanding with a pretrained language mannequin for textual content technology. A typical instance is ViT-GPT2, which chains collectively the Imaginative and prescient Transformer (launched in part 1. Picture Classification) because the visible encoder and the GPT-2 mannequin because the decoder to carry out autoregressive textual content technology.
BLIP (Boostrapping Language-Picture Pretraining)

BLIP, developed by Salesforce Analysis, leverages 4 core modules – a picture encoder, a textual content encoder, adopted by an image-grounded textual content encoder that fuses visible and textual options by way of consideration mechanisms, in addition to an image-grounded textual content decoder for textual content sequence technology. The pretraining course of includes minimizing image-text contrastive loss, image-text matching loss and language modeling loss, with the goals of aligning the semantic relationship between visible info and textual content sequences. It presents greater flexibility in functions and might be utilized for VQA (visible query answering), however it additionally introduces extra complexity within the architectural design.
Implementation
We use the code snippet beneath to generate output from a picture captioning pipeline.
from transformers import pipeline
from PIL import Picture
picture = Picture.open(image_url)
pipe = pipeline(job="image-to-text", mannequin=model_id)
output = pipe(picture=picture)We tried three totally different fashions beneath and so they all generates moderately correct picture descriptions, with the bigger mannequin performs higher than the bottom one.
Visible Encoder-Decoder “ydshieh/vit-gpt2-coco-en” output
[{'generated_text': 'a cup of coffee sitting on a wooden table'}]BLIP “Salesforce/blip-image-captioning-base” output
[{'generated_text': 'a cup of coffee on a table'}]BLIP “Salesforce/blip-image-captioning-large” output
[{'generated_text': 'there is a cup of coffee on a saucer on a table'}]4. Visible Query Answering

Visible Query Answering (VQA) has gained rising recognition because it permits customers to ask questions on a picture and obtain coherent textual content responses. It additionally requires a multimodal mannequin that may extract key info in visible information whereas additionally able to producing textual content responses. What it differentiates from picture captioning is accepting consumer prompts as enter along with a picture, due to this fact requiring an encoder that interprets each modalities on the identical time.
ViLT (Imaginative and prescient Language Transformer)

ViLT is a computationally environment friendly mannequin structure for executing VQA job. ViLT incorporates picture patch embeddings and textual content embeddings into an unified transformer encoder which is pre-trained for 3 goals:
- image-text matching: be taught the semantic relationship between image-text pairs
- masked language modeling: be taught to foretell the masked phrase/token from the vocabulary primarily based on the textual content and picture enter
- phrase patch alignment: be taught the associations between phrases and picture patches
ViLT adopts an encoder-only structure with job particular heads (e.g. classification head, VQA head), with this minimal design reaching ten instances quicker pace than a VLP (Imaginative and prescient-and-Language Pretraining) mannequin that depends on area supervision for object detection and convolutional structure for characteristic extraction. Nonetheless, this simplified structure ends in suboptimal efficiency on complicated duties and depends on huge coaching information for reaching generalized performance. As demonstrated later, one downside is that ViLT mannequin produces token-based outputs for VQA relatively than coherent sentences, very very similar to a picture classification job with a considerable amount of candidate labels.
BLIP
As launched within the part 3. Picture Captioning, BLIP is a extra in depth mannequin that can be fine-tuned for performing visible query answering job. As the results of it encoder-decoder structure, it generates full textual content sequences as an alternative of tokens.
Implementation
VQA is applied utilizing the code snippet beneath, taking each a picture and a textual content immediate because the mannequin inputs.
from transformers import pipeline
from PIL import Picture
import streamlit as st
picture = Picture.open(image_url)
query='describe this picture'
pipe = pipeline(job="image-to-text", mannequin=model_id, query=query)
output = pipe(picture=picture)When evaluating ViLT and BLIP fashions for the query “describe this picture”, the outputs differ considerably because of their distinct mannequin architectures. ViLT predicts the best scoring tokens from its current vocabulary, whereas BLIP generates extra coherent and wise outcomes.
ViLT “dandelin/vilt-b32-finetuned-vqa” output
[
{ "score": 0.044245753437280655, "answer": "kitchen" },
{ "score": 0.03294338658452034, "answer": "tea" },
{ "score": 0.030773703008890152, "answer": "table" },
{ "score": 0.024886665865778923, "answer": "office" },
{ "score": 0.019653357565402985, "answer": "cup" }
]BLIP “Salesforce/blip-vqa-capfilt-large” output
[{'answer': 'coffee cup on saucer'}]Finish-to-Finish Pc Imaginative and prescient App Improvement
Let’s break down the net app improvement into 6 steps you’ll be able to simply observe to construct your personal interactive Streamlit app or customise it in your wants. Take a look at our GitHub repository for the end-to-end implementation.
1. Initialize the net app and configure the web page format.
def initialize_page():
"""Initialize the Streamlit web page configuration and format"""
st.set_page_config(
page_title="Pc Imaginative and prescient",
page_icon="🤖",
format="centered"
)
st.title("Pc Imaginative and prescient Duties")
content_block = st.columns(1)[0]
return content_block2. Immediate the consumer to add a picture.
def get_uploaded_image():
uploaded_file = st.file_uploader(
"Add your personal picture",
accept_multiple_files=False,
kind=["jpg", "jpeg", "png"]
)
if uploaded_file:
picture = Picture.open(uploaded_file)
st.picture(picture, caption='Preview', use_container_width=False)
else:
picture = None
return picture3. Choose a number of pc imaginative and prescient duties utilizing a multi-select dropdown listing (additionally settle for consumer entered choices e.g. “document-question-answering”). It would immediate consumer to enter the query if ‘visual-question-answering’ or ‘document-question-answering’ is chosen, as a result of these two duties require “query” as a further enter parameter.
def get_selected_task():
choices = st.multiselect(
"Which duties would you prefer to carry out?",
[
"visual-question-answering",
"image-to-text",
"image-classification",
"image-segmentation",
],
max_selections=4,
accept_new_options=True,
)
#immediate for query enter if the duty is 'VQA' and 'DocVQA' - parameter "query"
if 'visual-question-answering' in choices or 'document-question-answering' in choices:
query = st.text_input(
"Please enter your query:"
)
elif "Different (specify job title)" in choices:
job = st.text_input(
"Please enter the duty title:"
)
choices = job
query = ""
else:
query = ""
return choices, query4. Immediate the consumer to decide on between the default mannequin constructed into the cuddling face pipeline or enter their very own mannequin.
def get_selected_model():
choices = ["Use the default model", "Use your selected HuggingFace model"]
selected_option = st.selectbox("Select an choice:", choices)
if selected_option == "Use your chosen HuggingFace mannequin":
mannequin = st.text_input(
"Please enter your chosen HuggingFace mannequin id:"
)
else:
mannequin = None
return mannequin5. Create job pipelines primarily based on the user-entered parameters, then collects the mannequin outputs and processing instances. The result’s displayed in a desk format utilizing st.dataframe() to match the totally different job title, output, runtime, mannequin title, and mannequin kind. For picture segmentation duties, the segmentation masks can also be displayed utilizing st.picture().
def display_results(picture, task_list, user_question, mannequin):
outcomes = []
for job in task_list:
if job in ['visual-question-answering', 'document-question-answering']:
params = {'query': user_question}
else:
params = {}
row = {
'job': job,
}
strive:
mannequin = i['model']
row['model'] = mannequin
pipe = pipeline(job, mannequin=mannequin)
besides Exception as e:
pipe = pipeline(job)
row['model'] = pipe.mannequin.name_or_path
start_time = time.time()
output = pipe(
picture,
**params
)
execution_time = time.time() - start_time
row['model_type'] = pipe.mannequin.config.model_type
row['time'] = execution_time
# show picture segentation visible output
if job == 'image-segmentation':
output_masks = [i['mask'] for i in output]
row['output'] = str(output)
outcomes.append(row)
results_df = pd.DataFrame(outcomes)
st.write('Mannequin Responses')
st.dataframe(results_df)
if 'image-segmentation' in task_list:
st.write('Segmentation Masks Output')
for m in output_masks:
st.picture(m)
return results_df
6. Lastly, chain these capabilities collectively utilizing the primary perform. Use a “Generate Response” button to set off these capabilities and show the ends in the app.
def important():
initialize_page()
picture = get_uploaded_image()
task_list, user_question = get_selected_task()
mannequin = get_selected_model()
# generate reponse spinning wheel
if st.button("Generate Response", key="generate_button"):
display_results(picture, task_list, user_question, mannequin)
# run the app
if __name__ == "__main__":
important()Takeaway Message
We launched the evolution from conventional CNN-based approaches to transformer architectures, evaluating imaginative and prescient fashions with language fashions and multimodal fashions. We additionally explored 4 basic pc imaginative and prescient duties and their corresponding methods, offering a sensible Streamlit implementation information to constructing your personal pc imaginative and prescient internet functions for additional explorations.
The elemental Pc Imaginative and prescient duties and fashions embody:
- Picture Classification: Analyze photos and assign them to a number of predefined classes or lessons, using mannequin architectures like ViT (Imaginative and prescient Transformer).
- Picture Segmentation: Classify picture pixels into particular classes, creating detailed masks that define object boundaries, together with DETR and Mask2Former mannequin architectures.
- Picture Captioning: Generates descriptive textual content for photos, demonstrating fashions like visible encoder-decoder and BLIP that mix visible encoding with language technology capabilities.
- Visible Query Answering (VQA): Course of each picture and textual content queries to reply open-ended questions primarily based on picture content material, evaluating architectures like ViLT (Imaginative and prescient Language Transformer) with its token-based outputs and BLIP with extra coherent responses.
















{kind=link}