




Picture by Creator
# The Setup
You are about to coach a mannequin once you discover 20% of your values are lacking. Do you drop these rows? Fill them in with averages? Use one thing fancier? The reply issues greater than you’d suppose.
Should you Google it, you will discover dozens of imputation strategies, from the dead-simple (simply use the imply) to the delicate (iterative machine studying fashions). You may suppose that fancy strategies are higher. KNN considers comparable rows. MICE builds predictive fashions. They have to outperform simply slapping on the common, proper?
We thought so too. We have been incorrect.
# The Experiment
We grabbed the Crop Advice dataset from StrataScratch initiatives – 2,200 soil samples throughout 22 crop sorts, with options comparable to nitrogen ranges, temperature, humidity, and rainfall. A Random Forest hits 99.6% accuracy on this factor. It is virtually suspiciously clear.
This evaluation extends our Agricultural Knowledge Evaluation challenge, which explores the identical dataset by means of EDA and statistical testing. Right here, we ask: what occurs when clear information meets a real-world drawback – lacking values?
Good for our experiment.
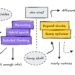
We launched 20% lacking values (utterly at random, simulating sensor failures), then examined 5 imputation strategies:

Our testing was thorough; we used 10-fold cross-validation throughout 5 random seeds (a complete of fifty runs per methodology). To make sure that no data from the take a look at set leaked into the coaching set, our imputation fashions have been educated on the coaching units solely. For our statistical checks, we utilized the Bonferroni correction. We additionally normalized the enter options for each KNN and MICE, as if we didn’t normalize them, an enter with values ranging between 0 and 300 (rainfall) would have a a lot better influence than an enter with a spread of three to 10 (pH) when performing the gap calculation for these strategies. Full code and reproducible outcomes can be found in our pocket book.
Then we ran it and stared on the outcomes.
# The Shock
This is what we anticipated: KNN or MICE would win, as a result of they’re smarter. They think about relationships between options. They use precise machine studying.
This is what we acquired:

The Median and Imply are tied for first place. The subtle strategies got here in third and fourth.
We ran the statistical take a look at. Imply vs. Median: p = 0.7. Not even near important. They’re successfully an identical.
However this is the kicker: each of them considerably outperformed KNN and MICE (p < 0.001 after Bonferroni correction). The straightforward strategies did not simply match the flowery ones. They beat them.
# Wait, What?
Earlier than you throw out your MICE set up, let’s dig into why this occurred.
The duty was prediction. We measured accuracy. Does the mannequin nonetheless classify crops accurately after imputation? For that particular aim, what issues is preserving the predictive sign, not essentially the precise values.
Imply imputation does one thing attention-grabbing: it replaces lacking values with a “impartial” worth that does not push the mannequin towards any explicit class. It is boring, nevertheless it’s protected. The Random Forest can nonetheless discover its choice boundaries.
KNN and MICE strive more durable; they estimate what the precise worth might need been. However in doing so, they’ll introduce noise. If the closest neighbors aren’t that comparable, or if MICE’s iterative modeling picks up spurious patterns, you may be including error reasonably than eradicating it.
The baseline was already excessive. At 99.6% accuracy, this can be a fairly straightforward classification drawback. When the sign is powerful, imputation errors matter much less. The mannequin can afford some noise.
Random Forest is strong. Tree-based fashions deal with imperfect information nicely. A linear mannequin struggled extra with the variance distortion of imply imputation.

Not so quick.
# The Plot Twist
We measured one thing else: correlation preservation.
This is the factor about actual information: options do not exist in isolation. They transfer collectively. In our dataset, when soil has excessive Phosphorus, it often has excessive Potassium as nicely (correlation of 0.74). This is not random; farmers sometimes add these vitamins collectively, and sure soil sorts retain each equally.
While you impute lacking values, you could by accident break these relationships. Imply imputation fills in “common Potassium” no matter what Phosphorus appears to be like like in that row. Do this sufficient occasions, and the connection between P and Okay begins to fade. Your imputed information may look wonderful column-by-column, however the relationships between columns are quietly falling aside.
Why does this matter? If the next move is clustering, PCA, or any evaluation the place characteristic relationships are the purpose, you are working with broken information and do not even understand it.
We checked: after imputation, how a lot of that P↔Okay correlation survived?

Picture by Creator
The rankings utterly flipped.
KNN preserved the correlation virtually completely. Imply and Median destroyed a couple of quarter of it. And Random Pattern (which samples values independently for every column) eradicated the connection.
This is smart. Imply imputation replaces lacking values with the identical quantity no matter what the opposite options appear to be. If a row has excessive Nitrogen, Imply does not care; it nonetheless imputes the common Potassium. KNN appears to be like at comparable rows, so if high-N rows are inclined to have high-Okay, it’s going to impute a high-Okay worth.
# The Commerce-Off
This is the actual discovering: there isn’t any single greatest imputation methodology. As a substitute, choose probably the most acceptable methodology based mostly in your particular aim and context.
The accuracy rankings and correlation rankings are almost reverse:

Picture by Creator
(At the very least the Random Pattern is constant – it is dangerous at all the things.)
This trade-off is not distinctive to our dataset. It is baked into how these strategies work. Imply/Median are univariate, and so they take a look at one column at a time. KNN/MICE are multivariate, and so they think about relationships. Univariate strategies protect marginal distributions however destroy correlation. Multivariate strategies protect construction and may produce some type of predictive error/noise.
# So, What Ought to You Really Do?
After working this experiment and digging by means of the literature, this is our sensible information:
Use Imply or Median when:
- Your aim is prediction (classification, regression)
- You are utilizing a sturdy mannequin (Random Forest, XGBoost, neural nets)
- Lacking fee is underneath 30%
- You want one thing quick
Use KNN when:
- It’s worthwhile to protect characteristic relationships
- Downstream process is clustering, PCA, or visualization
- You need correlations to outlive for exploratory evaluation
Use MICE when:
- You want legitimate normal errors (for statistical inference)
- You are reporting confidence intervals or p-values
- The lacking information mechanism may be MAR (Lacking at Random)
Keep away from Random Pattern:
- It is tempting as a result of it “preserves the distribution”
- Nevertheless it destroys all multivariate construction
- We could not discover a good use case
# The Sincere Caveats
We examined one dataset, one lacking fee (20%), one mechanism (MCAR), and one downstream mannequin (Random Forest). Your setup might fluctuate. The literature reveals that on different datasets, MissForest and MICE typically carry out higher. Our discovering that straightforward strategies compete is actual, nevertheless it’s not common.
# The Backside Line
We went into this experiment anticipating to substantiate that subtle imputation strategies are well worth the complexity. As a substitute, we discovered that for prediction accuracy, the standard imply held its personal, whereas utterly failing at preserving the relationships between options.
The lesson is not “at all times use imply imputation.” It is “know what you are optimizing for.”

Picture by Creator
Should you simply want predictions, begin easy. Check whether or not KNN or MICE really helps in your information. Do not assume they’ll.
Should you want the correlation construction for downstream evaluation, Imply will silently wreck it whereas supplying you with completely cheap accuracy numbers. That is a lure.
And no matter you do, scale your options earlier than utilizing KNN. Belief us on this one.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to information scientists put together for his or her interviews with actual interview questions from prime firms. Nate writes on the newest tendencies within the profession market, offers interview recommendation, shares information science initiatives, and covers all the things SQL.
















{kind=link}