


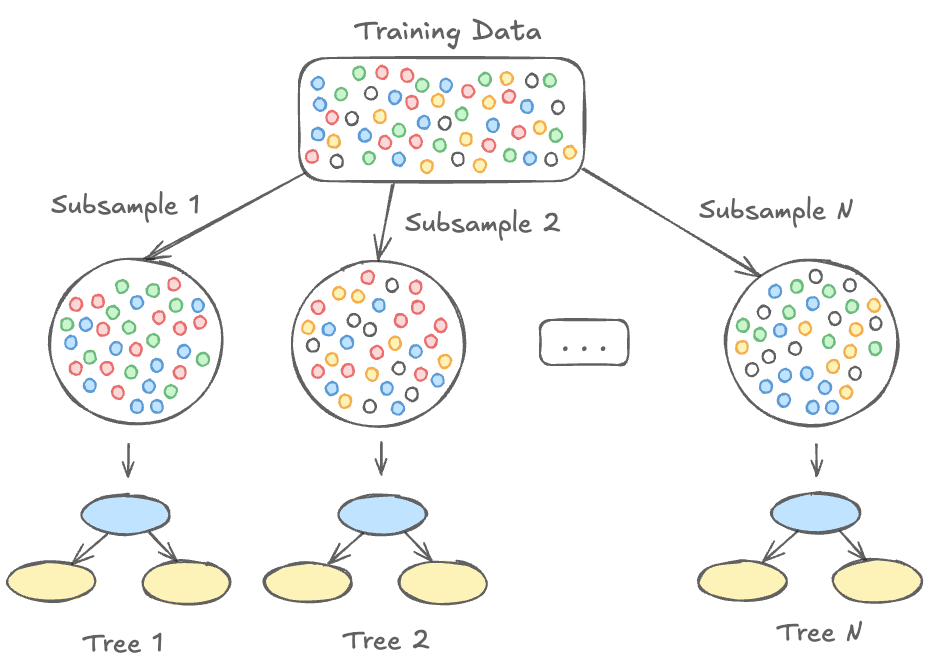
Why understanding parameters is vital for constructing sturdy fashions

After leaving neuroscience behind and commencing on a knowledge science path quite a few years in the past, I’ve had the privilege of engaged on quite a few real-world machine studying initiatives. One factor that stands out throughout industries and use circumstances — whether or not it’s predicting buyer churn, forecasting gross sales, or optimizing provide chains — is how usually XGBoost dominates when working with tabular knowledge.
Its capability to deal with lacking values, apply regularization, and persistently ship robust efficiency has actually solidified its place within the knowledge scientist’s toolkit. Even with the rise of newer algorithms, together with neural networks, XGBoost nonetheless stands out as a go-to selection for manufacturing methods coping with structured datasets.
What I discover most spectacular, although, is the extent of management it provides via its parameters — they’re like the key levers that unlock efficiency, stability complexity, and even make fashions extra interpretable. But, I’ve usually seen that whereas XGBoost is extensively used, its parameters are generally handled like a black field, with their full potential left untapped. Understanding these parameters and the way they’ll contribute to raised…

















{kind=link}