


Synthetic Intelligence (AI) dominates in the present day’s headlines—hailed as a breakthrough someday, warned towards as a risk the following. But a lot of this debate occurs in a bubble, centered on summary hopes and fears moderately than concrete options. In the meantime, one pressing problem usually neglected is the rise of psychological well being points in on-line communities, the place biased or hostile exchanges erode belief and psychological security.
This text introduces a sensible software of AI geared toward that downside: a machine studying pipeline designed to detect and mitigate bias in user-generated content material. The system combines deep studying fashions for classification with generative giant language fashions (LLMs) for crafting context-sensitive responses. Educated on greater than two million Reddit and Twitter feedback, it achieved excessive accuracy (F1 = 0.99) and generated tailor-made moderation messages by way of a digital moderator persona.
In contrast to a lot of the hype surrounding AI, this work demonstrates a tangible, deployable device that helps digital well-being. It reveals how AI can serve not simply enterprise effectivity or revenue, however the creation of fairer, extra inclusive areas the place individuals join on-line. In what follows, I define the pipeline, its efficiency, and its broader implications for on-line communities and digital well-being. For readers concerned about exploring the analysis in additional depth, together with a poster presentation video explaining the code areas and the full-length analysis report, assets can be found on Github. [1]
A machine studying pipeline that employs generative synthetic intelligence to deal with bias in social networks has worth to society’s psychological nicely being. An increasing number of, the human interplay with computer systems is trusting of solutions that enormous language fashions present in reasoning dialogue.
Methodology
The system was designed as a three-phase pipeline: acquire, detect, and mitigate. Every section mixed established pure language processing (NLP) methods with trendy transformer fashions to seize each the size and subtlety of biased language on-line.
Step 1. Information Assortment and Preparation
I sourced 1 million Twitter posts from the Sentiment140 dataset [2] and 1 million Reddit feedback from a curated Pushshift corpus (2007–2014) [3]. Feedback have been cleaned, anonymized, and deduplicated. Preprocessing included tokenization, lemmatization, stopword removing, and phrase matching utilizing NLTK and spaCy.
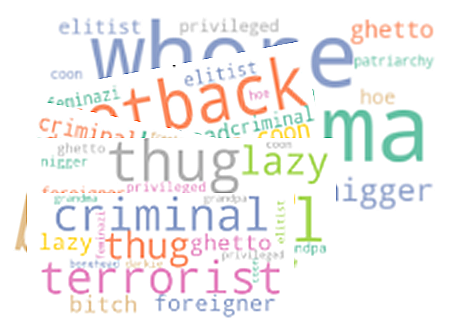
To coach the fashions successfully, I engineered metadata options—comparable to bias_terms, has_bias, and bias_type—that allowed stratification throughout biased and impartial subsets. Desk 1 summarizes these options, whereas Determine 1 reveals the frequency of bias phrases throughout the datasets.

Addressing knowledge leakage and mannequin overfitting points are essential in early knowledge preparation levels.

Supervised studying methods are used to label bias phrases and classify them as implicit or specific types.
Step 2. Bias Annotation and Labeling
Bias was annotated on two axes: presence (biased vs. non-biased) and kind (implicit, specific, or none). Implicit bias was outlined as delicate or coded language (e.g., stereotypes), whereas specific bias was overt slurs or threats. For instance, “Grandpa Biden fell up the steps” was coded as ageist, whereas “Biden is a grandpa who loves his household” was not. This contextual coding decreased false positives.
Step 3. Sentiment and Classification Fashions
Two transformer fashions powered the detection stage:
– RoBERTa [4] was fine-tuned for sentiment classification. Its outputs (constructive, impartial, unfavourable) helped infer the tone of biased feedback.
– DistilBERT [5] was educated on the enriched dataset with implicit/specific labels, enabling exact classification of delicate cues.
With the detection mannequin educated on the highest accuracy, feedback are evaluated by a big language mannequin and a response is produced.
Step 4. Mitigation Technique
Bias detection was adopted by real-time mitigation. As soon as a biased remark was recognized, the system generated a response tailor-made to the bias kind:
– Express bias: direct, assertive corrections.
– Implicit bias: softer rephrasings or academic options.
Responses have been generated by ChatGPT [6], chosen for its flexibility and context sensitivity. All responses have been framed by way of a fictional moderator persona, JenAI-Moderator™, which maintained a constant voice and tone (Determine 3).

Step 5. System Structure
The total pipeline is illustrated in Determine 4. It integrates preprocessing, bias detection, and generative mitigation. Information and mannequin outputs have been saved in a PostgreSQL relational schema, enabling logging, auditing, and future integration with human-in-the-loop programs.

Outcomes
The system was evaluated on a dataset of over two million Reddit and Twitter feedback, specializing in accuracy, nuance, and real-world applicability.
Characteristic Extraction
As proven in Determine 1, phrases associated to race, gender, and age appeared disproportionately in consumer feedback. Within the first move of information exploration, your entire datasets have been explored, and there was a 4 p.c prevalence of bias recognized in feedback. Stratification was used to deal with the imbalance of not bias-to-bias occurrences. Bias phrases like model and bullying appeared occasionally, whereas political bias confirmed up as prominently as different fairness associated biases.
Mannequin Efficiency
– RoBERTa achieved 98.6% validation accuracy by the second epoch. Its loss curves (Determine 5) converged shortly, with a confusion matrix (Determine 6) exhibiting sturdy class separation.
– DistilBERT, educated on implicit/specific labels, reached a 99% F1 rating (Determine 7). In contrast to uncooked accuracy, F1 higher displays the stability of precision and recall in imbalanced datasets[7].



Bias Kind Distribution
Determine 8 reveals boxplots of bias sorts distributed over predicted sentiment file counts. The size of the field plots for unfavourable feedback the place about 20,000 data of the stratified database that included very unfavourable and unfavourable feedback mixed. For constructive feedback, that’s, feedback reflecting affectionate or non-bias sentiment, the field plots span about 10,000 data. Impartial feedback have been in about 10,000 data. The bias and predicted sentiment breakdown validates the sentiment-informed classification logic.

Mitigation Effectiveness
Generated responses from JenAI-Moderator depicted in Determine 3 have been evaluated by human reviewers. Responses have been judged linguistically correct and contextually acceptable, particularly for implicit bias. Desk 2 gives examples of system predictions with authentic feedback, exhibiting sensitivity to delicate instances.

Dialogue
Moderation is commonly framed as a technical filtering downside: detect a banned phrase, delete the remark, and transfer on. However moderation can also be an interplay between customers and programs. In HCI analysis, equity just isn’t solely technical however experiential [8]. This method embraces this attitude, framing mitigation as dialogue by way of a persona-driven moderator: JenAI-Moderator.
Moderation as Interplay
Express bias usually requires agency correction, whereas implicit bias advantages from constructive suggestions. By reframing moderately than deleting, the system fosters reflection and studying [9].
Equity, Tone, and Design
Tone issues. Overly harsh corrections threat alienating customers; overly well mannered warnings threat being ignored. This method varies tone: assertive for specific bias, academic for implicit bias (Determine 4, Desk 2). This aligns with analysis exhibiting equity will depend on context [10].
Scalability and Integration
The modular design helps API-based integration with platforms. Constructed-in logging allows transparency and evaluate, whereas human-in-the-loop choices guarantee safeguards towards overreach.
Moral and Sociotechnical Issues
Bias detection dangers false positives or over-policing marginalized teams. Our method mitigates this by stripping private data knowledge, avoiding demographic labels, and storing reviewable logs. Nonetheless, oversight is crucial. As Mehrabi et al. [7] argue, bias is rarely totally eradicated however should be frequently managed.
Conclusion
This mission demonstrates that AI could be deployed constructively in on-line communities—not simply to detect bias, however to mitigate it in ways in which protect consumer dignity and promote digital well-being.
Key contributions:
– Twin-pipeline structure (RoBERTa + DistilBERT).
– Tone-adaptive mitigation engine (ChatGPT).
– Persona-based moderation (JenAI-Moderator).
The fashions achieved near-perfect F1 scores (0.99). Extra importantly, mitigation responses have been correct and context-sensitive, making them sensible for deployment.
Future instructions:
– Person research to judge reception.
– Pilot deployments to check belief and engagement.
– Strengthening robustness towards evasion (e.g., coded language).
– Increasing to multilingual datasets for world equity.
At a time when AI is commonly solid as hype or hazard, this mission reveals how it may be socially useful AI. By embedding equity and transparency it promotes more healthy on-line areas the place individuals really feel safer and revered.
Photographs, tables, and figures illustrated on this report have been created solely by the creator.
Acknowledgements
This mission fulfilled the Milestone II and Capstone necessities for the Grasp of Utilized Information Science (MADS) program on the College of Michigan Faculty of Data (UMSI). The mission’s poster acquired a MADS Award on the UMSI Exposition 2025 Poster Session. Dr. Laura Stagnaro served because the Capstone mission mentor, and Dr. Jinseok Kim served because the Milestone II mission mentor.
Concerning the Creator
Celia B. Banks is a social and knowledge scientist whose work bridges human programs and utilized knowledge science. Her doctoral analysis in Human and Group Programs explored how organizations evolve into digital environments, reflecting her broader curiosity within the intersection of individuals, know-how, and buildings. Dr. Banks is a lifelong learner, and her present focus builds on this basis by way of utilized analysis in knowledge science and analytics.
References
[1] C. Banks, Celia Banks Portfolio Repository: College of Michigan Faculty of Data Poster Session (2025) [Online]. Accessible: https://celiabbanks.github.io/ [Accessed 10 May 2025]
[2] A. Go, Twitter sentiment evaluation (2009), Entropy, p. 252
[3] Watchful1, 1 billion Reddit feedback from 2005-2019 [Data set] (2019), Pushshift by way of The Eye. Accessible: https://github.com/Watchful1/PushshiftDumps [Accessed 1 September 2024]
[4] Y. Liu, Roberta: A robustly optimized BERT pretraining method (2019), arXiv preprint arXiv, p. 1907.116892
[5] V. Sanh, DistilBERT, a distilled model of BERT: smaller, sooner, cheaper and lighter (2019), arXiv preprint arXiv, p. 1910.01108
[6] B. Zhang, Mitigating undesirable biases with adversarial studying (2018), in AAAI/ACM Convention on AI, Ethics, and Society, pp. 335-340
[7] A. Mehrabi, A survey on bias and equity in machine studying (2021), in ACM Computing Surveys, vol. 54, no. 6, pp. 1-35
[8] R. Binns, Equity in machine studying: Classes from political philosophy (2018), in PMLR Convention on Equity, Accountability and Transparency, pp. 149-159
[9] S. Jhaver, A. Bruckman, and E. Gilbert, Human-machine collaboration for content material regulation: The case of reddit automoderator (2019), ACM Transactions on Pc-Human Interplay (TOCHI), vol. 26, no. 5, pp. 1-35, 2019
[10] N. Lee, P. Resnick, and G. Barton, Algorithmic bias detection and mitigation: Finest practices and insurance policies to cut back client harms (2019), in Brookings Institute, Washington, DC














{kind=link}