




# Introduction
Everybody focuses on writing SQL that “works,” however only a few check whether or not it retains working tomorrow. A single new row, a modified assumption, or a refactor can break a question silently. This text walks by means of an entire workflow, displaying the way to deal with SQL like software program: versioned, examined, and automatic. We’ll use an actual Amazon interview query about figuring out prospects with the best day by day spending. Then we are going to convert the SQL right into a testable part, outline anticipated outputs, and automate testing with steady integration and steady deployment (CI/CD).
# Step 1: Fixing an Interview-Type SQL Query
// Understanding the Downside

On this interview query from Amazon, you’re requested to seek out the purchasers with the best day by day complete order value between a sure date vary.
// Understanding the Dataset
There are two knowledge tables on this challenge: prospects and orders.
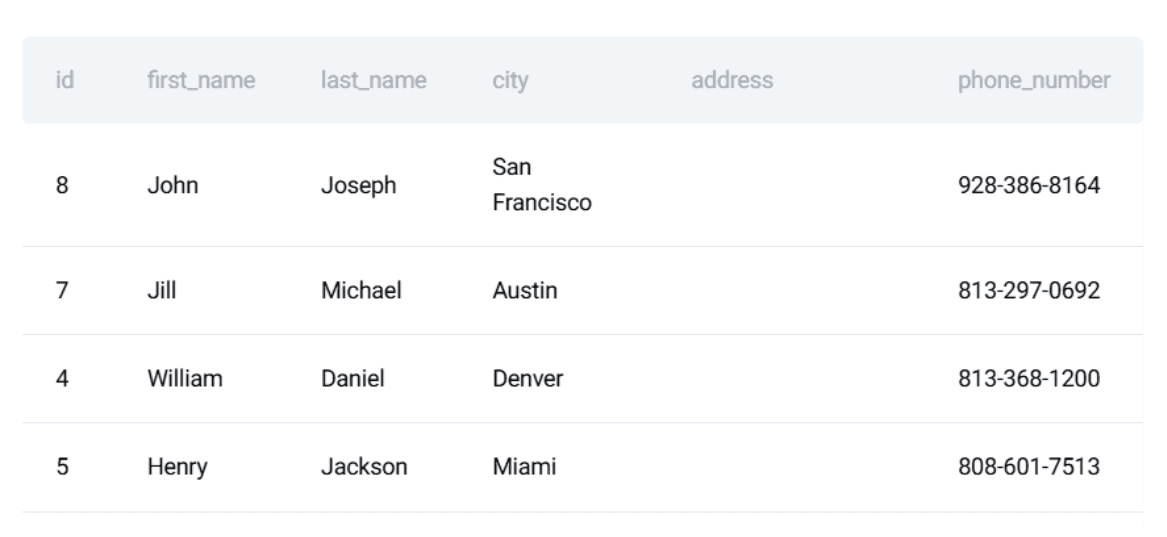
The prospects desk:

Here’s a preview of the dataset:
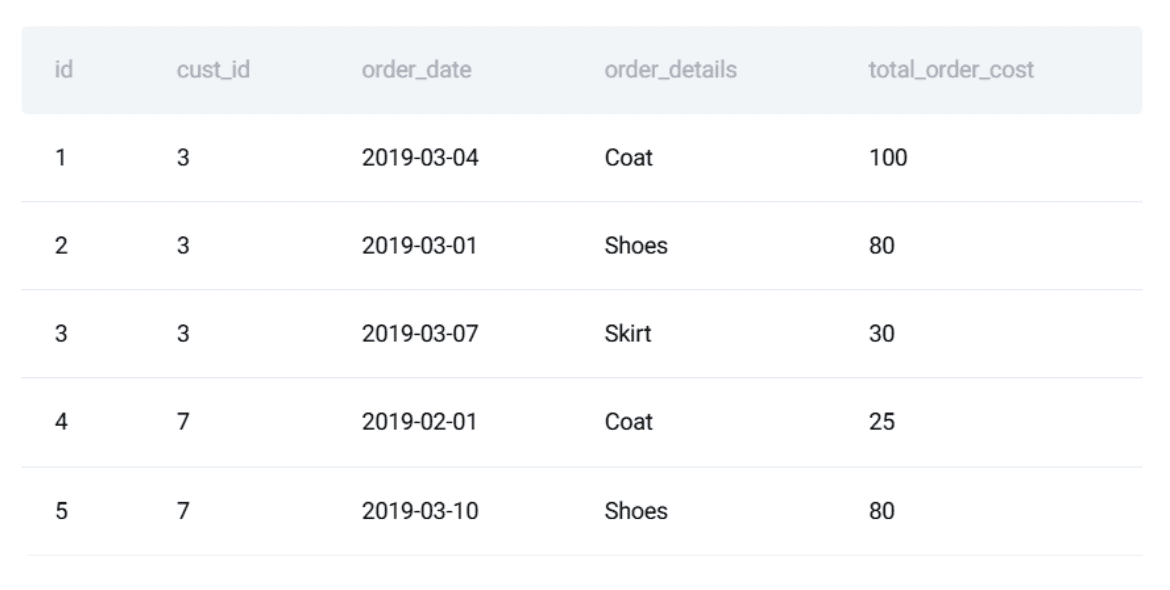
The orders desk:

Here’s a preview of the dataset:
This drawback is ideal for illustrating how SQL will be handled like software program: the question have to be right, secure, and proof against regressions.
// Writing the SQL Resolution
The logic breaks down into three elements:
- Mixture every buyer’s complete spending per day
- Rank prospects by complete spending for every date
- Return solely the day by day high spenders
Right here is the ultimate PostgreSQL answer:
WITH customer_daily_totals AS (
SELECT
o.cust_id,
o.order_date,
SUM(o.total_order_cost) AS total_daily_cost
FROM orders o
WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01'
GROUP BY o.cust_id, o.order_date
),
ranked_daily_totals AS (
SELECT
cust_id,
order_date,
total_daily_cost,
RANK() OVER (
PARTITION BY order_date
ORDER BY total_daily_cost DESC
) AS rnk
FROM customer_daily_totals
)
SELECT
c.first_name,
rdt.order_date,
rdt.total_daily_cost AS max_cost
FROM ranked_daily_totals rdt
JOIN prospects c ON rdt.cust_id = c.id
WHERE rdt.rnk = 1
ORDER BY rdt.order_date;
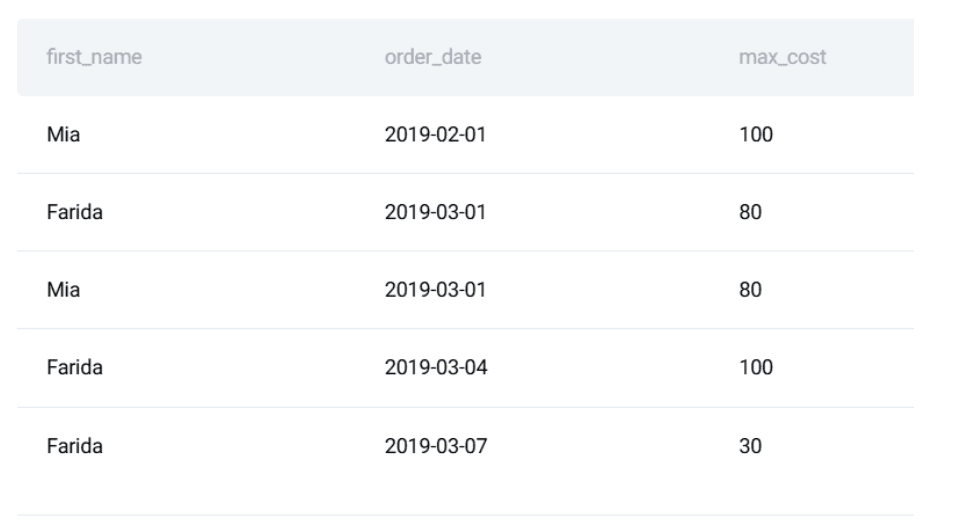
// Defining the Anticipated Output
Right here is the anticipated output:
At this stage, most individuals cease.
# Step 2: Making the SQL Logic Dependable with Unit Assessments
SQL breaks extra simply than most assume. A modified default, a renamed column, or a brand new knowledge supply can introduce silent errors. Testing protects you from these points. There are three testing steps we are going to cowl: changing the logic right into a perform, defining anticipated output, and writing a unit check suite.
// Turning the Question right into a Reusable Part
To check the SQL code, we start by wrapping it in a Python perform utilizing a light-weight testing framework like unittest. First, we outline the question that we need to check:
question = """
WITH customer_daily_totals AS (
SELECT
o.cust_id,
o.order_date,
SUM(o.total_order_cost) AS total_daily_cost
FROM orders o
WHERE o.order_date BETWEEN '2019-02-01' AND '2019-05-01'
GROUP BY o.cust_id, o.order_date
),
ranked_daily_totals AS (
SELECT
cust_id,
order_date,
total_daily_cost,
RANK() OVER (
PARTITION BY order_date
ORDER BY total_daily_cost DESC
) AS rnk
FROM customer_daily_totals
)
SELECT
c.first_name,
rdt.order_date,
rdt.total_daily_cost AS max_cost
FROM ranked_daily_totals rdt
JOIN prospects c ON rdt.cust_id = c.id
WHERE rdt.rnk = 1
ORDER BY rdt.order_date;
"""
// Defining Take a look at Enter and Anticipated Output
Subsequent, we should create a managed pattern dataset to check towards.
test_customers = [
(15, "Mia"),
(7, "Jill"),
(3, "Farida")
]
test_orders = [
(1, 3, "2019-03-04", 100),
(2, 3, "2019-03-01", 80),
(4, 7, "2019-02-01", 25),
(6, 15, "2019-02-01", 100)
]
We additionally create the anticipated output:
anticipated = [
("Mia", "2019-02-01", 100),
("Farida", "2019-03-01", 80),
("Farida", "2019-03-04", 100)
]
Why? As a result of defining anticipated outputs creates a benchmark.
// Writing SQL Unit Assessments
Now we’ve got the question outlined, the check inputs, and the anticipated outputs. We will write an precise unit check. The concept is straightforward:
- Create an remoted, in-memory database
- Load managed check knowledge
- Execute the SQL question
- Assert that the consequence obtained matches the anticipated output

Python’s built-in unittest framework is extremely efficient as a result of it permits us to maintain dependencies minimal whereas offering construction and repeatability. We begin by creating an in-memory SQLite database:
conn = sqlite3.join(":reminiscence:")
cursor = conn.cursor()
Utilizing :reminiscence: ensures that:
- the check database is totally remoted
- no exterior state can have an effect on the consequence
- the database is discarded routinely as soon as the check finishes
Subsequent, we recreate solely the tables required by the question:
CREATE TABLE prospects (...)
CREATE TABLE orders (...)
Although the question solely makes use of a subset of columns, the schema mirrors a practical manufacturing desk. This reduces the danger of false confidence brought on by oversimplified schemas. We then insert the managed check knowledge outlined earlier:
cursor.executemany("INSERT INTO prospects VALUES (?, ?, ?, ?, ?, ?)", test_customers)
cursor.executemany("INSERT INTO orders VALUES (?, ?, ?, ?, ?)", test_orders)
conn.commit()
At this level, the database comprises a recognized, deterministic state, which is important for significant exams. Earlier than executing the question, we load and print the check tables utilizing Pandas:
customers_df = pd.read_sql("SELECT id, first_name, last_name, metropolis FROM prospects", conn)
orders_df = pd.read_sql("SELECT * FROM orders", conn)
Whereas this step isn’t strictly required for automation, it’s extremely helpful throughout growth and debugging. When a check fails, with the ability to instantly examine the enter knowledge saves considerably extra time than checking the SQL logic, as a result of it permits you to perceive step-by-step what the code is computing. Now we run the question below check:
consequence = pd.read_sql(question, conn)
The result’s loaded right into a DataFrame, which gives:
- structured entry to rows and columns
- straightforward comparability with anticipated outputs
- readable printing for debugging
Subsequent, we should confirm the outcomes row by row. The verification logic makes a handbook assertion between the question output and the anticipated consequence:
all_correct = True
if len(consequence) != len(anticipated):
all_correct = False
The primary test confirms whether or not the variety of rows returned by the question matches what we count on. A mismatch right here instantly signifies lacking or additional data. Subsequent, we iterate by means of the anticipated output and evaluate it to the precise question consequence row by row:
for i, (fname, lname, date, value) in enumerate(anticipated):
if i < len(consequence):
precise = consequence.iloc[i]
if not (
precise["first_name"] == fname
and precise["last_name"] == lname
and precise["order_date"] == date
and precise["max_cost"] == value
):
all_correct = False
Every row is checked on all related dimensions:
- buyer title
- order date
- aggregated day by day value
If any worth differs from the anticipated, the check is marked as failed. Lastly, the check result’s summarized in a transparent cross/fail message:
if all_correct and len(consequence) == len(anticipated):
print("ALL TESTS PASSED")
else:
print("SOME TESTS FAILED")
The database connection is then closed:
If the exams cross, the anticipated output is:

This check carries some assumptions value noting:
- a secure row order (
ORDER BY order_date) - precise matches on all values
- no tolerance for ties or duplicate winners per day
The complete script, prepared for use, will be seen right here.
# Step 3: Automating SQL Assessments with Steady Integration and Steady Deployment
A check suite is simply helpful if it runs persistently at any time when wanted. We make the most of CI/CD to automate testing at any time when a code change is made.
// Organizing the Mission
A minimal repository construction can appear like this:

// Creating the GitHub Actions Workflow
The subsequent step is to make sure these exams run routinely at any time when the code adjustments. For this, we use GitHub Actions. This device permits us to outline a CI workflow that runs the SQL exams each time code is pushed or a pull request is opened.
Create the workflow file: In your repository, create the next folder construction if it does not exist already: .github/workflows/. Inside this folder, create a brand new file referred to as test_sql.yml. The title isn’t particular; GitHub solely cares that the file lives contained in the .github/workflows/ listing. You may title it something, however test_sql.yml retains issues clear and easy.
Outline when the workflow ought to run: Right here is the complete workflow file:
title: Run SQL Assessments
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
This part defines when the workflow runs:
- on each push to the primary department
- on each pull request focusing on foremost
In follow, this implies:
- pushing on to foremost will set off the exams
- opening or updating a pull request can even set off the exams
This helps catch SQL regressions earlier than they get merged.
Outline the check job: Subsequent, we outline a job referred to as check:
jobs:
check:
runs-on: ubuntu-latest
This tells GitHub to:
- create a recent Linux machine
- run all check steps inside it
Every workflow run begins from a clear atmosphere, which prevents “it really works on my machine” issues.
// Including the Workflow Steps
Now we outline the steps the machine ought to execute:
- title: Checkout repository
makes use of: actions/checkout@v4
This step downloads your repository’s code into the runner so it may well entry your SQL information and exams.
- title: Arrange Python
makes use of: actions/setup-python@v5
with:
python-version: "3.10"
This installs Python 3.10, making certain a constant runtime throughout all runs.
- title: Set up dependencies
run: |
python -m pip set up --upgrade pip
pip set up -r necessities.txt
This installs all required Python libraries (akin to Pandas) outlined in necessities.txt.
- title: Run unit exams
run: python -m unittest uncover
Lastly, this command:
- routinely discovers check information
- runs all SQL exams outlined within the
exams/folder - fails the workflow if any check fails
The complete workflow will be discovered right here.
Operating the workflow: You needn’t run this file manually. As soon as dedicated:
- pushing to foremost will set off the workflow
- opening a pull request will set off the workflow
You may view the outcomes straight in GitHub by navigating to your repository’s Actions tab.

Every run will present whether or not your SQL exams handed or failed.
# Step 4: Automating Information High quality
Unit exams verify whether or not the logic nonetheless returns the anticipated output, and CI ensures these exams run routinely. However in actual knowledge environments, the enter knowledge itself may cause failures: late-arriving rows, malformed dates, lacking keys, and sudden duplicates can break queries lengthy earlier than the SQL logic does. That is the place knowledge high quality automation is available in. Testing and versioning kind a security internet for code adjustments; knowledge high quality automation extends that security internet to the information itself, stopping downstream points earlier than they affect outcomes.
// Understanding Why Information High quality Checks Matter for SQL Workflows
In our interview drawback, the next points might make the question return incorrect outcomes:
- A buyer’s first title is not distinctive.
- An order arrives with a adverse value.
- Dates fall exterior the anticipated vary.
- Day by day aggregates comprise duplicate rows for a similar buyer and date.
- A buyer exists in orders however not in prospects.

With out automated checks, these points could silently distort outcomes. As a result of SQL does not elevate apparent exceptions in lots of of those situations, errors unfold unnoticed. Automated knowledge high quality checks detect these points early and stop the pipeline from operating with corrupted or incomplete knowledge.
// Turning Information Assumptions into Automated Guidelines
Each SQL question depends on assumptions in regards to the knowledge. The issue is that these assumptions are not often written down and nearly by no means enforced. In our day by day spenders question, correctness relies upon not solely on SQL logic, but additionally on the form and validity of the enter knowledge. As a substitute of trusting these assumptions implicitly, we are able to flip them into automated knowledge high quality guidelines. The concept is straightforward:
- categorical every assumption as a SQL test
- run these checks routinely
- fail quick if any assumption is violated
First names have to be distinctive: Our question joins prospects by ID, however returns first_name as an identifier. If first names are not distinctive, the output turns into ambiguous.
SELECT first_name, COUNT(*)
FROM prospects
GROUP BY first_name
HAVING COUNT(*) > 1;
If this question returns any rows, the belief is damaged.
Order prices have to be non-negative: Adverse order values often point out ingestion or upstream transformation points.
SELECT *
FROM orders
WHERE total_order_cost < 0;
Even a single row right here invalidates monetary aggregates.
Order dates have to be legitimate and inside expectations: Dates which are lacking or wildly out of vary typically reveal synchronization or parsing errors.
SELECT *
FROM orders
WHERE order_date IS NULL
OR order_date < '2010-01-01'
OR order_date > CURRENT_DATE;
This protects the question from silently together with dangerous temporal knowledge.
Each order should reference a sound buyer: If an order refers to a non-existent buyer, joins will silently drop rows.
SELECT o.*
FROM orders o
LEFT JOIN prospects c ON c.id = o.cust_id
WHERE c.id IS NULL;
This rule ensures referential integrity earlier than analytics logic runs.
// Changing Guidelines into an Automated Verify
As a substitute of operating these checks manually, we are able to wrap them right into a single Python perform that fails instantly if any rule is violated.
import pandas as pd
def run_data_quality_checks(conn):
checks = {
"Duplicate first names": """
SELECT first_name
FROM prospects
GROUP BY first_name
HAVING COUNT(*) > 1;
""",
"Adverse order prices": """
SELECT *
FROM orders
WHERE total_order_cost < 0;
""",
"Invalid order dates": """
SELECT *
FROM orders
WHERE order_date IS NULL
OR order_date < '2010-01-01'
OR order_date > CURRENT_DATE;
""",
"Orders with out prospects": """
SELECT o.*
FROM orders o
LEFT JOIN prospects c ON c.id = o.cust_id
WHERE c.id IS NULL;
"""
}
for rule_name, question in checks.objects():
consequence = pd.read_sql(question, conn)
if not consequence.empty:
elevate ValueError(f"Information high quality test failed: {rule_name}")
print("All knowledge high quality checks handed.")
This perform:
- executes every rule
- checks whether or not any rows are returned
- raises an error instantly if a violation is discovered
At this level, knowledge high quality guidelines behave similar to unit exams: cross or fail. If exams cross, you will note one thing like:
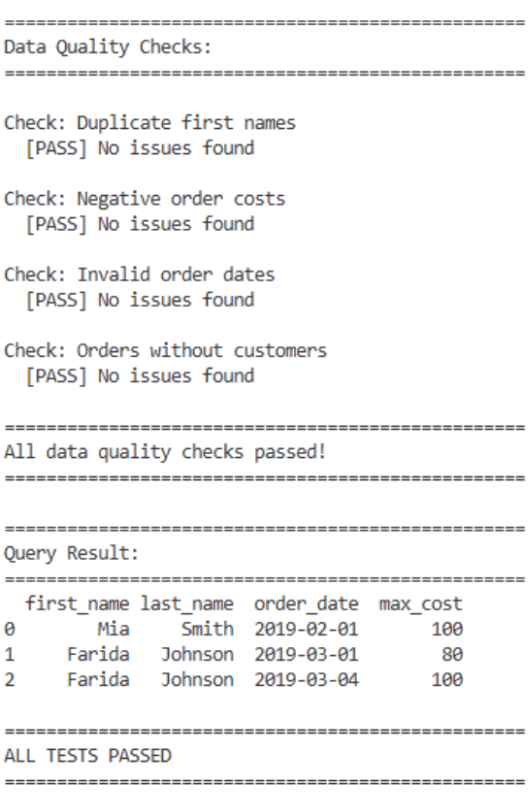
As a result of the information high quality checks run inside Python, they’re routinely picked up by the prevailing GitHub Actions workflow:
- title: Run unit exams
run: python -m unittest uncover
The CI pipeline will cease instantly so long as:
- the perform is imported or executed by your check file
- a failure raises an exception
# Concluding Remarks
Most individuals cease as soon as the SQL question produces an accurate reply. However actual knowledge environments reward those that make their queries secure, testable, and version-controlled.
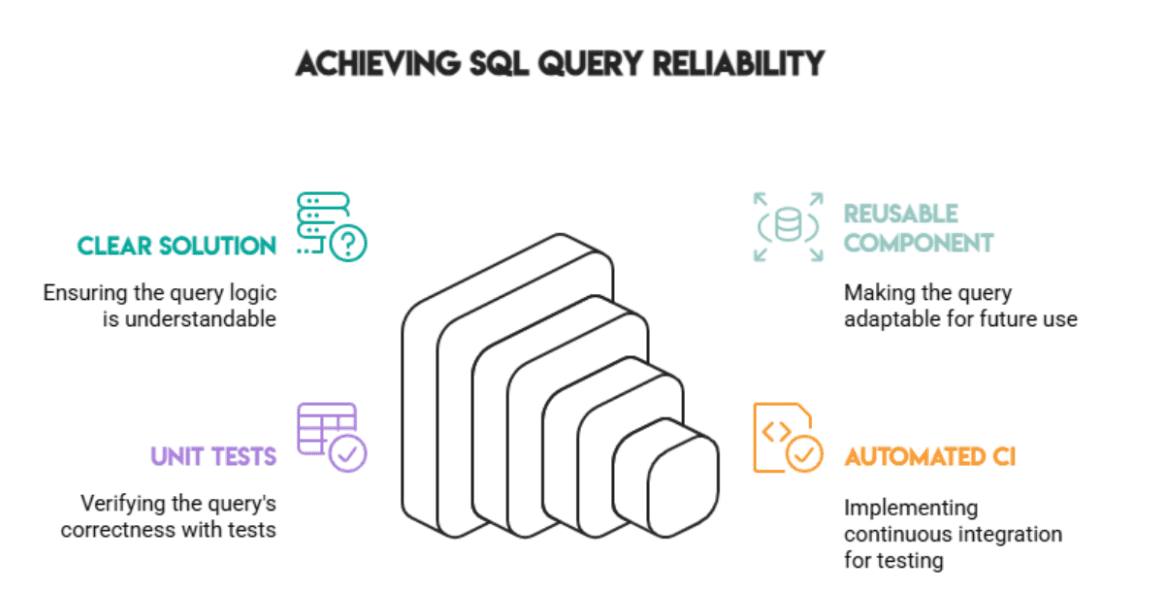
Combining the next practices ensures the question continues to ship dependable outcomes, whilst knowledge adjustments over time:
- a transparent answer
- a reusable part
- unit exams
- automated CI
Correctness is sweet, however reliability is important.
Nate Rosidi is an information scientist and in product technique. He is additionally an adjunct professor instructing analytics, and is the founding father of StrataScratch, a platform serving to knowledge scientists put together for his or her interviews with actual interview questions from high corporations. Nate writes on the most recent developments within the profession market, offers interview recommendation, shares knowledge science initiatives, and covers every little thing SQL.
















{kind=link}