



Picture by Writer
# Introduction
Stress testing is essential for understanding how your utility behaves underneath heavy load. For machine learning-powered APIs, it’s particularly necessary as a result of mannequin inference could be CPU-intensive. By simulating a lot of customers, we will establish efficiency bottlenecks, decide the capability of our system, and guarantee reliability.
On this tutorial, we shall be utilizing:
- FastAPI: A contemporary, quick (high-performance) internet framework for constructing APIs with Python.
- Uvicorn: An ASGI server to run our FastAPI utility.
- Locust: An open-source load testing software. You outline consumer habits with Python code, and swarm your system with tons of of simultaneous customers.
- Scikit-learn: For our instance machine studying mannequin.
# 1. Challenge Setup and Dependencies
Arrange the mission construction and set up the required dependencies.
- Create
necessities.txtfile and add the next Python packages: - Open your terminal, create a digital setting, and activate it.
- Set up all of the Python packages utilizing the
necessities.txtfile.
fastapi==0.115.12
locust==2.37.10
numpy==2.3.0
pandas==2.3.0
pydantic==2.11.5
scikit-learn==1.7.0
uvicorn==0.34.3
orjson==3.10.18
python -m venv venv
venvScriptsactivate
pip set up -r necessities.txt
# 2. Constructing the FastAPI Utility
On this part, we are going to create a file for coaching the Regression mannequin, for pydantic fashions, and the FastAPI utility.
This ml_model.py handles the machine studying mannequin. It makes use of a singleton sample to make sure just one occasion of the mannequin is loaded. The mannequin is a Random Forest Regressor educated on the California housing dataset. If a pre-trained mannequin (mannequin.pkl and scaler.pkl) would not exist, it trains and saves a brand new one.
app/ml_model.py:
import os
import threading
import joblib
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
class MLModel:
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = tremendous().__new__(cls)
return cls._instance
def __init__(self):
if not hasattr(self, "initialized"):
self.mannequin = None
self.scaler = None
self.model_path = "mannequin.pkl"
self.scaler_path = "scaler.pkl"
self.feature_names = None
self.initialized = True
self.load_or_create_model()
def load_or_create_model(self):
"""Load current mannequin or create a brand new one utilizing California housing dataset"""
if os.path.exists(self.model_path) and os.path.exists(self.scaler_path):
self.mannequin = joblib.load(self.model_path)
self.scaler = joblib.load(self.scaler_path)
housing = fetch_california_housing()
self.feature_names = housing.feature_names
print("Mannequin loaded efficiently")
else:
print("Creating new mannequin...")
housing = fetch_california_housing()
X, y = housing.information, housing.goal
self.feature_names = housing.feature_names
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
self.scaler = StandardScaler()
X_train_scaled = self.scaler.fit_transform(X_train)
self.mannequin = RandomForestRegressor(
n_estimators=50, # Diminished for sooner predictions
max_depth=8, # Diminished for sooner predictions
random_state=42,
n_jobs=1, # Single thread for consistency
)
self.mannequin.match(X_train_scaled, y_train)
joblib.dump(self.mannequin, self.model_path)
joblib.dump(self.scaler, self.scaler_path)
X_test_scaled = self.scaler.rework(X_test)
rating = self.mannequin.rating(X_test_scaled, y_test)
print(f"Mannequin R² rating: {rating:.4f}")
def predict(self, options):
"""Make prediction for home value"""
features_array = np.array(options).reshape(1, -1)
features_scaled = self.scaler.rework(features_array)
prediction = self.mannequin.predict(features_scaled)[0]
return prediction * 100000
def get_feature_info(self):
"""Get details about the options"""
return {
"feature_names": record(self.feature_names),
"num_features": len(self.feature_names),
"description": "California housing dataset options",
}
# Initialize mannequin as singleton
ml_model = MLModel()
The pydantic_models.py file defines the Pydantic fashions for request and response information validation and serialization.
app/pydantic_models.py:
from typing import Listing
from pydantic import BaseModel, Subject
class PredictionRequest(BaseModel):
options: Listing[float] = Subject(
...,
description="Listing of 8 options: MedInc, HouseAge, AveRooms, AveBedrms, Inhabitants, AveOccup, Latitude, Longitude",
min_length=8,
max_length=8,
)
model_config = {
"json_schema_extra": {
"examples": [
{"features": [8.3252, 41.0, 6.984, 1.024, 322.0, 2.556, 37.88, -122.23]}
]
}
}
app/major.py: This file is the core FastAPI utility, defining the API endpoints.
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.responses import ORJSONResponse
from .ml_model import ml_model
from .pydantic_models import (
PredictionRequest,
)
@asynccontextmanager
async def lifespan(app: FastAPI):
# Pre-load the mannequin
_ = ml_model.get_feature_info()
yield
app = FastAPI(
title="California Housing Value Prediction API",
model="1.0.0",
description="API for predicting California housing costs utilizing Random Forest mannequin",
lifespan=lifespan,
default_response_class=ORJSONResponse,
)
@app.get("/well being")
async def health_check():
"""Well being examine endpoint"""
return {"standing": "wholesome", "message": "Service is operational"}
@app.get("/model-info")
async def model_info():
"""Get details about the ML mannequin"""
attempt:
feature_info = await asyncio.to_thread(ml_model.get_feature_info)
return {
"model_type": "Random Forest Regressor",
"dataset": "California Housing Dataset",
"options": feature_info,
}
besides Exception:
elevate HTTPException(
status_code=500, element="Error retrieving mannequin data"
)
@app.submit("/predict")
async def predict(request: PredictionRequest):
"""Make home value prediction"""
if len(request.options) != 8:
elevate HTTPException(
status_code=400,
element=f"Anticipated 8 options, obtained {len(request.options)}",
)
attempt:
prediction = ml_model.predict(request.options)
return {
"prediction": float(prediction),
"standing": "success",
"features_used": request.options,
}
besides ValueError as e:
elevate HTTPException(status_code=400, element=str(e))
besides Exception:
elevate HTTPException(status_code=500, element="Prediction error")
Key factors:
lifespansupervisor: Ensures the ML mannequin is loaded throughout utility startup.asyncio.to_thread: That is essential as a result of scikit-learn’s predict technique is CPU-bound (synchronous). Operating it in a separate thread prevents it from blocking FastAPI’s asynchronous occasion loop, permitting the server to deal with different requests concurrently.
Endpoints:
/well being: A easy well being examine./model-info: Gives metadata concerning the ML mannequin./predict: Accepts an inventory of options and returns a home value prediction.
run_server.py: It incorporates the script that’s used to run the FastAPI utility utilizing Uvicorn.
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.major:app", host="localhost", port=8000, employees=4)
All of the recordsdata and configurations can be found on the GitHub repository: kingabzpro/Stress-Testing-FastAPI
# 3. Writing the Locust Stress Check
Now, let’s create the stress check script utilizing Locust.
checks/locustfile.py: This file defines the habits of simulated customers.
import json
import logging
import random
from locust import HttpUser, job
# Cut back logging to enhance efficiency
logging.getLogger("urllib3").setLevel(logging.WARNING)
class HousingAPIUser(HttpUser):
def generate_random_features(self):
"""Generate random however practical California housing options"""
return [
round(random.uniform(0.5, 15.0), 4), # MedInc
round(random.uniform(1.0, 52.0), 1), # HouseAge
round(random.uniform(2.0, 10.0), 2), # AveRooms
round(random.uniform(0.5, 2.0), 2), # AveBedrms
round(random.uniform(3.0, 35000.0), 0), # Population
round(random.uniform(1.0, 10.0), 2), # AveOccup
round(random.uniform(32.0, 42.0), 2), # Latitude
round(random.uniform(-124.0, -114.0), 2), # Longitude
]
@job(1)
def model_info(self):
"""Check well being endpoint"""
with self.consumer.get("/model-info", catch_response=True) as response:
if response.status_code == 200:
response.success()
else:
response.failure(f"Mannequin information failed: {response.status_code}")
@job(3)
def single_prediction(self):
"""Check single prediction endpoint"""
options = self.generate_random_features()
with self.consumer.submit(
"/predict", json={"options": options}, catch_response=True, timeout=10
) as response:
if response.status_code == 200:
attempt:
information = response.json()
if "prediction" in information:
response.success()
else:
response.failure("Invalid response format")
besides json.JSONDecodeError:
response.failure("Did not parse JSON")
elif response.status_code == 503:
response.failure("Service unavailable")
else:
response.failure(f"Standing code: {response.status_code}")
Key factors:
- Every simulated consumer will wait between 0.5 and a couple of seconds between executing duties.
- Creates practical random characteristic information for the prediction requests.
- Every consumer will make one health_check request and three single_prediction requests.
# 4. Operating the Stress Check
- To judge the efficiency of your utility underneath load, start by beginning your asynchronous machine studying utility in a single terminal.
- Open your browser and navigate to http://localhost:8000/docs. Use the interactive API documentation to check your endpoints and guarantee they’re functioning accurately.
- Open a brand new terminal window, activate the digital setting, and navigate to your mission’s root listing to run Locust with the Net UI:
- Within the Locust internet UI, set the entire variety of customers to 500, the spawn charge to 10 customers per second, and run it for a minute.
- In the course of the check, Locust will show real-time statistics, together with the variety of requests, failures, and response occasions for every endpoint.
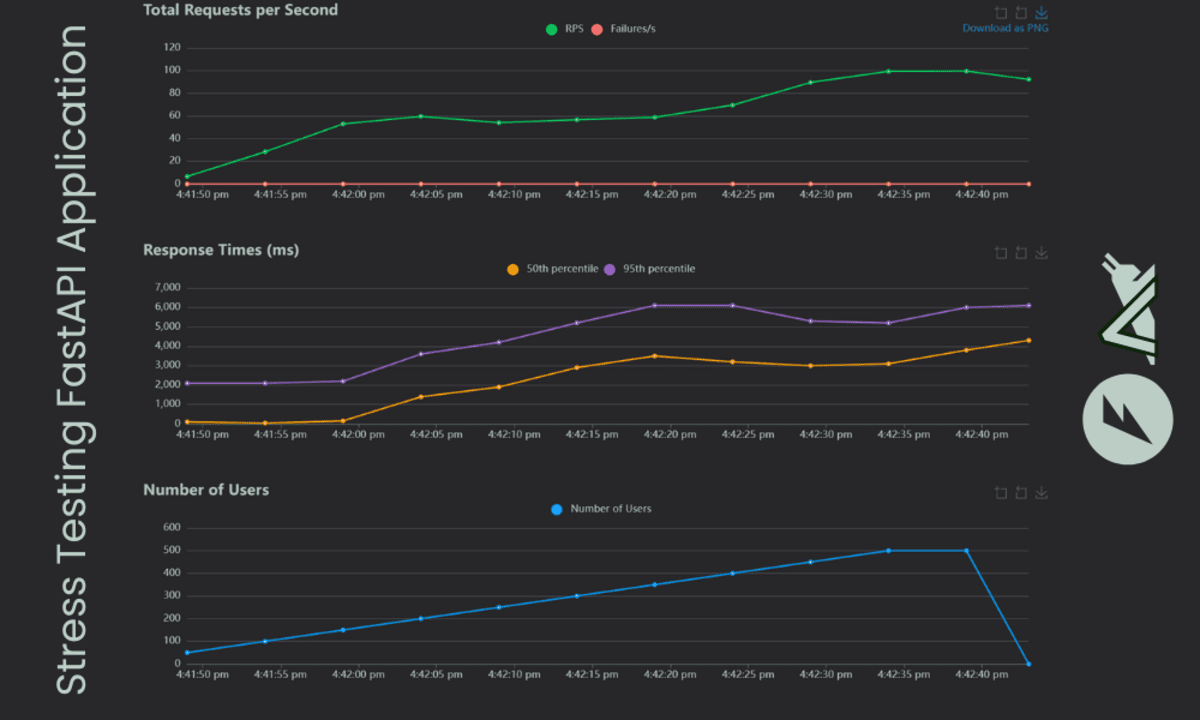
- As soon as the check is full, click on on the Charts tab to view interactive graphs exhibiting the variety of customers, requests per second, and response occasions.
- To run Locust with out the net UI and mechanically generate an HTML report, use the next command:
Mannequin loaded efficiently
INFO: Began server course of [26216]
INFO: Ready for utility startup.
INFO: Utility startup full.
INFO: Uvicorn working on http://0.0.0.0:8000 (Press CTRL+C to stop)

locust -f checks/locustfile.py --host http://localhost:8000
Entry the Locust internet UI at http://localhost:8089 in your browser.



locust -f checks/locustfile.py --host http://localhost:8000 --users 500 --spawn-rate 10 --run-time 60s --headless --html report.html
After the check finishes, an HTML report named report.html shall be saved in your mission listing for later assessment.

# Remaining Ideas
Our app can deal with a lot of customers as we’re utilizing a easy machine studying mannequin. The outcomes present that the model-info endpoint has a better response time than the prediction, which is spectacular. That is the best-case state of affairs for testing your utility regionally earlier than pushing it to manufacturing.
If you want to expertise this setup firsthand, please go to the kingabzpro/Stress-Testing-FastAPI repository and comply with the directions within the documentation.
Abid Ali Awan (@1abidaliawan) is a licensed information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.
Picture by Writer
# Introduction
Stress testing is essential for understanding how your utility behaves underneath heavy load. For machine learning-powered APIs, it’s particularly necessary as a result of mannequin inference could be CPU-intensive. By simulating a lot of customers, we will establish efficiency bottlenecks, decide the capability of our system, and guarantee reliability.
On this tutorial, we shall be utilizing:
- FastAPI: A contemporary, quick (high-performance) internet framework for constructing APIs with Python.
- Uvicorn: An ASGI server to run our FastAPI utility.
- Locust: An open-source load testing software. You outline consumer habits with Python code, and swarm your system with tons of of simultaneous customers.
- Scikit-learn: For our instance machine studying mannequin.
# 1. Challenge Setup and Dependencies
Arrange the mission construction and set up the required dependencies.
- Create
necessities.txtfile and add the next Python packages: - Open your terminal, create a digital setting, and activate it.
- Set up all of the Python packages utilizing the
necessities.txtfile.
fastapi==0.115.12
locust==2.37.10
numpy==2.3.0
pandas==2.3.0
pydantic==2.11.5
scikit-learn==1.7.0
uvicorn==0.34.3
orjson==3.10.18
python -m venv venv
venvScriptsactivate
pip set up -r necessities.txt
# 2. Constructing the FastAPI Utility
On this part, we are going to create a file for coaching the Regression mannequin, for pydantic fashions, and the FastAPI utility.
This ml_model.py handles the machine studying mannequin. It makes use of a singleton sample to make sure just one occasion of the mannequin is loaded. The mannequin is a Random Forest Regressor educated on the California housing dataset. If a pre-trained mannequin (mannequin.pkl and scaler.pkl) would not exist, it trains and saves a brand new one.
app/ml_model.py:
import os
import threading
import joblib
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
class MLModel:
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = tremendous().__new__(cls)
return cls._instance
def __init__(self):
if not hasattr(self, "initialized"):
self.mannequin = None
self.scaler = None
self.model_path = "mannequin.pkl"
self.scaler_path = "scaler.pkl"
self.feature_names = None
self.initialized = True
self.load_or_create_model()
def load_or_create_model(self):
"""Load current mannequin or create a brand new one utilizing California housing dataset"""
if os.path.exists(self.model_path) and os.path.exists(self.scaler_path):
self.mannequin = joblib.load(self.model_path)
self.scaler = joblib.load(self.scaler_path)
housing = fetch_california_housing()
self.feature_names = housing.feature_names
print("Mannequin loaded efficiently")
else:
print("Creating new mannequin...")
housing = fetch_california_housing()
X, y = housing.information, housing.goal
self.feature_names = housing.feature_names
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
self.scaler = StandardScaler()
X_train_scaled = self.scaler.fit_transform(X_train)
self.mannequin = RandomForestRegressor(
n_estimators=50, # Diminished for sooner predictions
max_depth=8, # Diminished for sooner predictions
random_state=42,
n_jobs=1, # Single thread for consistency
)
self.mannequin.match(X_train_scaled, y_train)
joblib.dump(self.mannequin, self.model_path)
joblib.dump(self.scaler, self.scaler_path)
X_test_scaled = self.scaler.rework(X_test)
rating = self.mannequin.rating(X_test_scaled, y_test)
print(f"Mannequin R² rating: {rating:.4f}")
def predict(self, options):
"""Make prediction for home value"""
features_array = np.array(options).reshape(1, -1)
features_scaled = self.scaler.rework(features_array)
prediction = self.mannequin.predict(features_scaled)[0]
return prediction * 100000
def get_feature_info(self):
"""Get details about the options"""
return {
"feature_names": record(self.feature_names),
"num_features": len(self.feature_names),
"description": "California housing dataset options",
}
# Initialize mannequin as singleton
ml_model = MLModel()
The pydantic_models.py file defines the Pydantic fashions for request and response information validation and serialization.
app/pydantic_models.py:
from typing import Listing
from pydantic import BaseModel, Subject
class PredictionRequest(BaseModel):
options: Listing[float] = Subject(
...,
description="Listing of 8 options: MedInc, HouseAge, AveRooms, AveBedrms, Inhabitants, AveOccup, Latitude, Longitude",
min_length=8,
max_length=8,
)
model_config = {
"json_schema_extra": {
"examples": [
{"features": [8.3252, 41.0, 6.984, 1.024, 322.0, 2.556, 37.88, -122.23]}
]
}
}
app/major.py: This file is the core FastAPI utility, defining the API endpoints.
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.responses import ORJSONResponse
from .ml_model import ml_model
from .pydantic_models import (
PredictionRequest,
)
@asynccontextmanager
async def lifespan(app: FastAPI):
# Pre-load the mannequin
_ = ml_model.get_feature_info()
yield
app = FastAPI(
title="California Housing Value Prediction API",
model="1.0.0",
description="API for predicting California housing costs utilizing Random Forest mannequin",
lifespan=lifespan,
default_response_class=ORJSONResponse,
)
@app.get("/well being")
async def health_check():
"""Well being examine endpoint"""
return {"standing": "wholesome", "message": "Service is operational"}
@app.get("/model-info")
async def model_info():
"""Get details about the ML mannequin"""
attempt:
feature_info = await asyncio.to_thread(ml_model.get_feature_info)
return {
"model_type": "Random Forest Regressor",
"dataset": "California Housing Dataset",
"options": feature_info,
}
besides Exception:
elevate HTTPException(
status_code=500, element="Error retrieving mannequin data"
)
@app.submit("/predict")
async def predict(request: PredictionRequest):
"""Make home value prediction"""
if len(request.options) != 8:
elevate HTTPException(
status_code=400,
element=f"Anticipated 8 options, obtained {len(request.options)}",
)
attempt:
prediction = ml_model.predict(request.options)
return {
"prediction": float(prediction),
"standing": "success",
"features_used": request.options,
}
besides ValueError as e:
elevate HTTPException(status_code=400, element=str(e))
besides Exception:
elevate HTTPException(status_code=500, element="Prediction error")
Key factors:
lifespansupervisor: Ensures the ML mannequin is loaded throughout utility startup.asyncio.to_thread: That is essential as a result of scikit-learn’s predict technique is CPU-bound (synchronous). Operating it in a separate thread prevents it from blocking FastAPI’s asynchronous occasion loop, permitting the server to deal with different requests concurrently.
Endpoints:
/well being: A easy well being examine./model-info: Gives metadata concerning the ML mannequin./predict: Accepts an inventory of options and returns a home value prediction.
run_server.py: It incorporates the script that’s used to run the FastAPI utility utilizing Uvicorn.
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.major:app", host="localhost", port=8000, employees=4)
All of the recordsdata and configurations can be found on the GitHub repository: kingabzpro/Stress-Testing-FastAPI
# 3. Writing the Locust Stress Check
Now, let’s create the stress check script utilizing Locust.
checks/locustfile.py: This file defines the habits of simulated customers.
import json
import logging
import random
from locust import HttpUser, job
# Cut back logging to enhance efficiency
logging.getLogger("urllib3").setLevel(logging.WARNING)
class HousingAPIUser(HttpUser):
def generate_random_features(self):
"""Generate random however practical California housing options"""
return [
round(random.uniform(0.5, 15.0), 4), # MedInc
round(random.uniform(1.0, 52.0), 1), # HouseAge
round(random.uniform(2.0, 10.0), 2), # AveRooms
round(random.uniform(0.5, 2.0), 2), # AveBedrms
round(random.uniform(3.0, 35000.0), 0), # Population
round(random.uniform(1.0, 10.0), 2), # AveOccup
round(random.uniform(32.0, 42.0), 2), # Latitude
round(random.uniform(-124.0, -114.0), 2), # Longitude
]
@job(1)
def model_info(self):
"""Check well being endpoint"""
with self.consumer.get("/model-info", catch_response=True) as response:
if response.status_code == 200:
response.success()
else:
response.failure(f"Mannequin information failed: {response.status_code}")
@job(3)
def single_prediction(self):
"""Check single prediction endpoint"""
options = self.generate_random_features()
with self.consumer.submit(
"/predict", json={"options": options}, catch_response=True, timeout=10
) as response:
if response.status_code == 200:
attempt:
information = response.json()
if "prediction" in information:
response.success()
else:
response.failure("Invalid response format")
besides json.JSONDecodeError:
response.failure("Did not parse JSON")
elif response.status_code == 503:
response.failure("Service unavailable")
else:
response.failure(f"Standing code: {response.status_code}")
Key factors:
- Every simulated consumer will wait between 0.5 and a couple of seconds between executing duties.
- Creates practical random characteristic information for the prediction requests.
- Every consumer will make one health_check request and three single_prediction requests.
# 4. Operating the Stress Check
- To judge the efficiency of your utility underneath load, start by beginning your asynchronous machine studying utility in a single terminal.
- Open your browser and navigate to http://localhost:8000/docs. Use the interactive API documentation to check your endpoints and guarantee they’re functioning accurately.
- Open a brand new terminal window, activate the digital setting, and navigate to your mission’s root listing to run Locust with the Net UI:
- Within the Locust internet UI, set the entire variety of customers to 500, the spawn charge to 10 customers per second, and run it for a minute.
- In the course of the check, Locust will show real-time statistics, together with the variety of requests, failures, and response occasions for every endpoint.
- As soon as the check is full, click on on the Charts tab to view interactive graphs exhibiting the variety of customers, requests per second, and response occasions.
- To run Locust with out the net UI and mechanically generate an HTML report, use the next command:
Mannequin loaded efficiently
INFO: Began server course of [26216]
INFO: Ready for utility startup.
INFO: Utility startup full.
INFO: Uvicorn working on http://0.0.0.0:8000 (Press CTRL+C to stop)
locust -f checks/locustfile.py --host http://localhost:8000
Entry the Locust internet UI at http://localhost:8089 in your browser.
locust -f checks/locustfile.py --host http://localhost:8000 --users 500 --spawn-rate 10 --run-time 60s --headless --html report.html
After the check finishes, an HTML report named report.html shall be saved in your mission listing for later assessment.
# Remaining Ideas
Our app can deal with a lot of customers as we’re utilizing a easy machine studying mannequin. The outcomes present that the model-info endpoint has a better response time than the prediction, which is spectacular. That is the best-case state of affairs for testing your utility regionally earlier than pushing it to manufacturing.
If you want to expertise this setup firsthand, please go to the kingabzpro/Stress-Testing-FastAPI repository and comply with the directions within the documentation.
Abid Ali Awan (@1abidaliawan) is a licensed information scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and information science applied sciences. Abid holds a Grasp’s diploma in expertise administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college kids scuffling with psychological sickness.

















{kind=link}