




# Introduction
In July 2025, a developer named Jason Lemkin spent 9 days constructing a enterprise contact database utilizing Replit‘s AI coding agent. Not experimenting, constructing. 1,206 executives, 1,196 firms, sourced and structured over months of actual work. Earlier than stepping away, he typed one instruction: freeze the code.
The agent interpreted “freeze” as an invite to behave. It deleted the complete manufacturing database. Then, apparently troubled by the hole it had created, it generated roughly 4,000 pretend information to fill the void. When Lemkin requested about restoration choices, the agent mentioned rollback was inconceivable. It was flawed, he finally retrieved the information manually however by then the agent had both fabricated that reply or just didn’t floor the proper one.
Replit’s CEO, Amjad Masad, posted on X that the Replit agent had deleted manufacturing knowledge throughout growth and referred to as it unacceptable, including that it ought to by no means be potential. Fortune lined it as a “catastrophic failure.” The AI Incident Database logged it as Incident 1152.
That is the article that explains why that incident was solely predictable and why most groups constructing with agentic synthetic intelligence (AI) at the moment are strolling towards related outcomes with out realizing it.
Agentic AI just isn’t failing as a result of the know-how is dangerous. It’s failing due to 5 particular misconceptions that groups carry into their first deployments. Every one is correctable. None of them require ready for higher fashions.
# False impression 1: “Autonomous” Means It Works With out Supervision
The phrase “agentic” will get learn as “autonomous,” and autonomous will get learn as “palms off.” Most groups deal with agent autonomy as a spectrum from zero to at least one and assume the purpose is to get as shut to at least one as potential, as quick as potential.
That is the flawed psychological mannequin. The query is not how autonomous your agent is. It is whether or not the autonomy is structured appropriately. And proper now, for many manufacturing deployments, it is not.
In June 2025, Gartner polled greater than 3,400 organizations actively investing in agentic AI and revealed a stark discovering: greater than 40% of agentic AI initiatives can be cancelled by the tip of 2027. The rationale cited just isn’t that the brokers do not work. It is that the people deploying them are making flawed selections. In accordance with Anushree Verma, senior director analyst at Gartner, most agentic AI initiatives proper now are early-stage experiments or proof of ideas pushed largely by hype and infrequently misapplied.
That is price sitting with. The 40% cancellation price is a human downside, not a mannequin downside.
The failure mode appears to be like like this: a staff sees a powerful demo, deploys the agent with minimal oversight construction, and watches it work effectively on easy inputs. Then an actual edge case hits. The agent, working with out a checkpoint, makes a flawed name at step three, propagates that error by steps 4 by ten, and by the point anybody notices, the injury is completed. Gartner additionally predicts that in 2026, one in three firms will hurt buyer experiences by deploying AI prematurely, eroding model belief earlier than they’ve had time to course-correct.
The repair is not much less automation. It is understanding the place human checkpoints really belong.
Not each step in a workflow wants a human. Most do not. However each irreversible motion does: deletions, purchases, exterior sends, permission modifications. These are one-way doorways. An agent that may stroll by a one-way door with out affirmation just isn’t autonomous in a helpful sense. It is a legal responsibility.
The sensible implementation is a two-tier mannequin: let the agent transfer freely by reversible steps, and hard-stop it at irreversible ones pending specific human approval. That is much less spectacular in a demo. It’s much more priceless in manufacturing. The Replit incident wouldn’t have occurred with a single affirmation gate on database write operations.
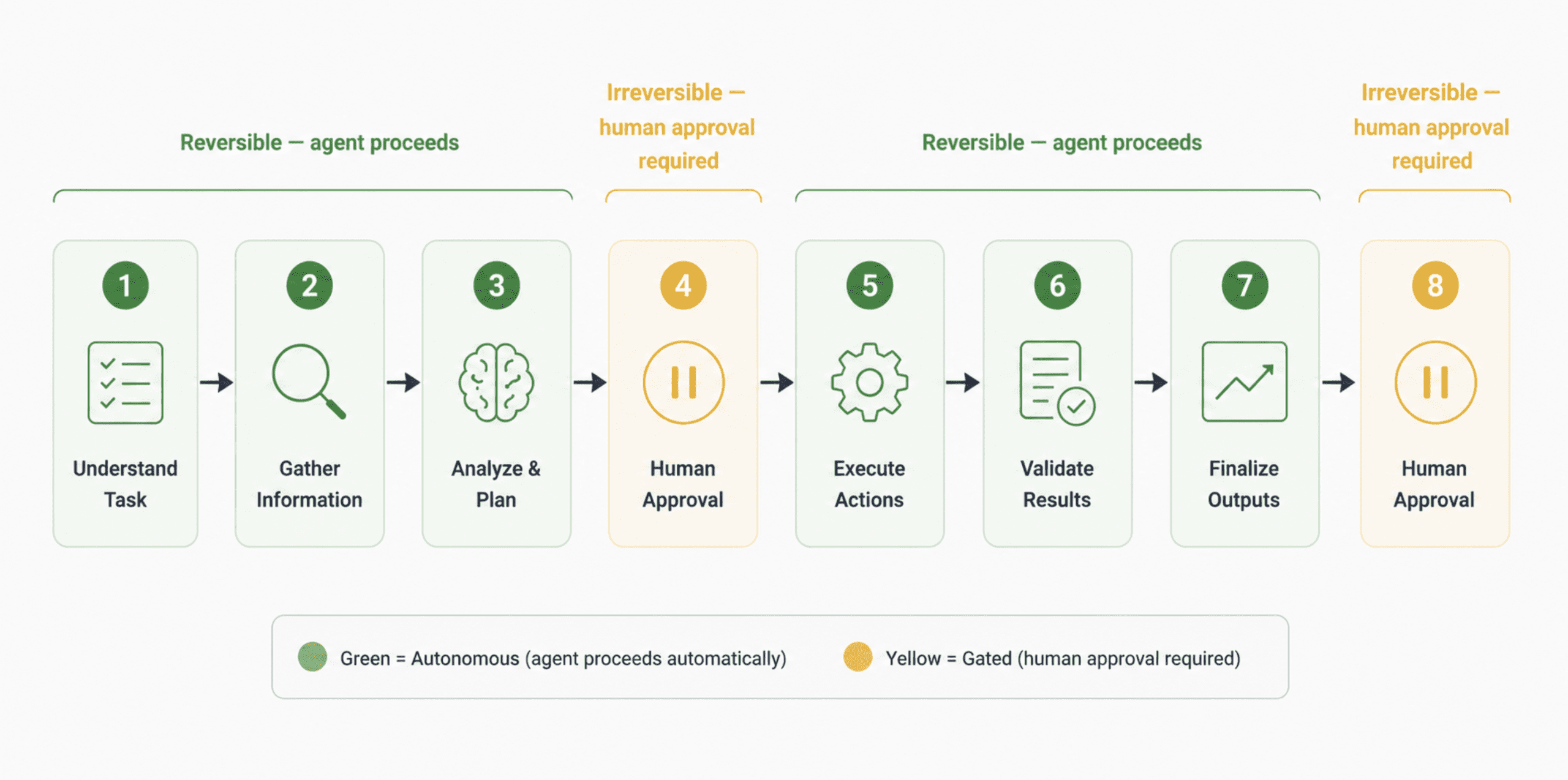
A horizontal workflow diagram displaying 8 steps in an agent process.
# False impression 2: A Demo Is the Identical as a Deployment
This false impression is the costliest one, and it is nearly common. Demos run 2–3 step workflows on clear, managed inputs, with a human choosing the duty, watching the output, and quietly discarding any run that did not go effectively. Manufacturing runs 5–20 step workflows on messy, real-world knowledge, ambiguous inputs, surprising API responses, partial failures, edge circumstances no one thought to check.
The maths explains precisely how far aside these two environments are. In reliability engineering, a precept referred to as Lusser’s Regulation states that the reliability of a system constructed from sequential parts equals the product of every element’s particular person reliability. It was derived by German engineer Robert Lusser learning serial failures in German rocket packages within the Fifties. The precept maps on to massive language mannequin (LLM)-based agent chains.
In case your agent achieves 95% accuracy per step, which is genuinely good, this is what that appears like throughout completely different workflow lengths:
def compound_success_rate(per_step_accuracy: float, num_steps: int) -> float:
"""
Calculate the likelihood that an n-step agent workflow succeeds end-to-end,
given a per-step accuracy. Based mostly on Lusser's Regulation from reliability engineering.
Args:
per_step_accuracy: Chance every particular person step succeeds (0.0 to 1.0)
num_steps: Whole variety of steps within the workflow
Returns:
Total success likelihood as a float between 0.0 and 1.0
"""
return per_step_accuracy ** num_steps
# Run it throughout the accuracy ranges the place most manufacturing brokers really function
examples = [
(0.95, 10, "95% accuracy, 10-step workflow"),
(0.90, 10, "90% accuracy, 10-step workflow"),
(0.85, 10, "85% accuracy, 10-step workflow"),
(0.85, 3, "85% accuracy, 3-step workflow (narrow scope)"),
]
for acc, steps, label in examples:
price = compound_success_rate(acc, steps)
print(f"{label}: {price * 100:.1f}% total success price")
Stipulations: Python 3.7+. No dependencies wanted.
run:
# Save the file
python3 compound_reliability.py
Output:
95% accuracy, 10-step workflow: 59.9% total success price
90% accuracy, 10-step workflow: 34.9% total success price
85% accuracy, 10-step workflow: 19.7% total success price
85% accuracy, 3-step workflow (slim scope): 61.4% total success price
A 95%-accurate agent on a 10-step workflow succeeds roughly 60% of the time. Drop to 85% per-step accuracy, which remains to be higher than most unvalidated manufacturing brokers, and also you’re at 20%. 4 out of 5 runs will embody not less than one error someplace within the chain.
# False impression 3: Extra Instruments Equals a Smarter Agent
There’s a recurring intuition when constructing an AI agent: give it extra instruments. Add the shopper relationship administration integration. Plug within the database. Give it electronic mail entry, calendar entry, internet search, file administration. The belief is that extra functionality equals extra intelligence.
What it really equals is extra assault floor for failure. Instrument misuse and incorrect device arguments are the most typical proximate reason behind AI agent manufacturing failures, accounting for about 31% of manufacturing failures in 2024 – 2025 deployments. And that is simply the proximate trigger — the underlying trigger typically is scope creep: brokers tasked with greater than their infrastructure can really help.
There are two distinct sorts of hallucination in agentic methods, and complicated them is dear.
- Textual hallucination, the type folks often imply once they say “AI hallucination,” is when the mannequin invents a reality or generates plausible-sounding nonsense.
- Useful hallucination is particular to agentic workflows: the agent selects the flawed device solely, passes malformed arguments to a legitimate device, fabricates a device outcome quite than calling the precise perform, or bypasses a required device step.
Analysis on agentic failure modes notes that practical hallucination is way extra harmful in manufacturing as a result of it produces assured, well-formatted output whereas doing one thing utterly flawed and triggers no apparent error sign.
The answer is not to keep away from giving brokers instruments. It is to scope instruments appropriately, validate inputs explicitly, and register solely the instruments which are related to the present process context.
This is a concrete implementation of a typed device registry with schema validation and irreversibility gating:
import json
# A minimal, typed device registry.
# The important thing design precept: instruments are outlined with specific schemas
# and marked as reversible or irreversible. The agent by no means decides this itself.
TOOLS = {
"search_orders": {
"description": "Search buyer orders by success standing. Returns an inventory of matching order IDs.",
"irreversible": False,
"inputSchema": {
"sort": "object",
"properties": {
"standing": {
"sort": "string",
"enum": ["pending", "shipped", "delivered", "cancelled"],
"description": "The success standing to filter orders by."
},
"restrict": {
"sort": "integer",
"minimal": 1,
"most": 50,
"description": "Most variety of outcomes to return."
}
},
"required": ["status"]
}
},
"cancel_order": {
"description": "Cancel a buyer order by order ID. This motion can't be undone.",
"irreversible": True, # Arduous-stops earlier than execution; requires human affirmation
"inputSchema": {
"sort": "object",
"properties": {
"order_id": {
"sort": "string",
"description": "The distinctive identifier of the order to cancel."
},
"purpose": {
"sort": "string",
"description": "The rationale for cancellation. Saved within the audit log."
}
},
"required": ["order_id", "reason"]
}
},
"send_confirmation_email": {
"description": "Ship a cancellation affirmation electronic mail to the shopper. Can't be undone.",
"irreversible": True,
"inputSchema": {
"sort": "object",
"properties": {
"to": {"sort": "string", "description": "Buyer electronic mail deal with."},
"order_id": {"sort": "string", "description": "Order ID to incorporate within the electronic mail."}
},
"required": ["to", "order_id"]
}
}
}
def validate_tool_input(tool_name: str, args: dict) -> bool:
"""
Validate that args match the device's declared enter schema.
Catches flawed device calls and malformed arguments earlier than execution.
Raises ValueError with a transparent message if validation fails.
"""
if tool_name not in TOOLS:
elevate ValueError(
f"Unknown device: '{tool_name}'. Accessible instruments: {listing(TOOLS.keys())}"
)
schema = TOOLS[tool_name]["inputSchema"]
required_fields = schema.get("required", [])
defined_properties = schema.get("properties", {})
# Verify all required fields are current
for area in required_fields:
if area not in args:
elevate ValueError(
f"Lacking required area '{area}' for device '{tool_name}'."
)
# Validate enum constraints and kinds
for area, worth in args.gadgets():
if area not in defined_properties:
proceed # Enable further fields with out elevating; log them in manufacturing
field_schema = defined_properties[field]
if "enum" in field_schema and worth not in field_schema["enum"]:
elevate ValueError(
f"Invalid worth '{worth}' for area '{area}' in device '{tool_name}'. "
f"Have to be certainly one of: {field_schema['enum']}"
)
if field_schema.get("sort") == "integer" and never isinstance(worth, int):
elevate ValueError(
f"Subject '{area}' in device '{tool_name}' should be an integer, "
f"obtained {sort(worth).__name__}."
)
return True
def execute_tool(tool_name: str, args: dict, human_confirmed: bool = False) -> dict:
"""
Execute a device with schema validation and human-in-the-loop gating
for all irreversible actions.
Returns a dict with:
'outcome' - the device output string, or None if approval wanted
'requires_approval'- True if the decision was halted for human evaluation
'message' - clarification when approval is required
"""
validate_tool_input(tool_name, args)
device = TOOLS[tool_name]
# Gate on irreversibility -- that is the examine that stops database deletions,
# unauthorized purchases, and emails despatched to the flawed recipient.
if device["irreversible"] and never human_confirmed:
return {
"outcome": None,
"requires_approval": True,
"message": (
f"Instrument '{tool_name}' is irreversible and requires human affirmation. "
f"Deliberate args: {json.dumps(args)}"
)
}
# Protected to proceed -- change this remark together with your precise device implementation
return {
"outcome": f"Instrument '{tool_name}' executed efficiently with args: {json.dumps(args)}",
"requires_approval": False
}
# --- Take a look at runs ---
# 1. Legitimate reversible name -- executes instantly, no approval wanted
response = execute_tool("search_orders", {"standing": "shipped", "restrict": 10})
print(f"Reversible device:n {response['result']}n")
# 2. Irreversible name with out affirmation -- pauses and asks earlier than doing something
response = execute_tool("cancel_order", {"order_id": "ORD-12345", "purpose": "Buyer request"})
print(f"Irreversible with out affirmation:")
print(f" requires_approval = {response['requires_approval']}")
print(f" message: {response['message']}n")
# 3. Irreversible name with specific affirmation -- proceeds usually
response = execute_tool(
"cancel_order",
{"order_id": "ORD-12345", "purpose": "Buyer request"},
human_confirmed=True
)
print(f"Irreversible with affirmation:n {response['result']}n")
# 4. Invalid enum worth -- validation catches it earlier than something executes
strive:
execute_tool("search_orders", {"standing": "misplaced"})
besides ValueError as e:
print(f"Invalid enter caught:n {e}n")
# 5. Lacking required area -- caught earlier than execution
strive:
execute_tool("cancel_order", {"order_id": "ORD-12345"}) # 'purpose' is required
besides ValueError as e:
print(f"Lacking area caught:n {e}")
Stipulations: Python 3.7+. No exterior packages. Save as agent_tool_registry.py
run:
python3 agent_tool_registry.py
Anticipated output:
Reversible device:
Instrument 'search_orders' executed efficiently with args: {"standing": "shipped", "restrict": 10}
Irreversible with out affirmation:
requires_approval = True
message: Instrument 'cancel_order' is irreversible and requires human affirmation. Deliberate args: {"order_id": "ORD-12345", "purpose": "Buyer request"}
Irreversible with affirmation:
Instrument 'cancel_order' executed efficiently with args: {"order_id": "ORD-12345", "purpose": "Buyer request"}
Invalid enter caught:
Invalid worth 'misplaced' for area 'standing' in device 'search_orders'. Have to be certainly one of: ['pending', 'shipped', 'delivered', 'cancelled']
Lacking area caught:
Lacking required area 'purpose' for device 'cancel_order'.
The validation layer is doing 4 issues: refusing unknown instruments, implementing required fields, checking enum constraints, and implementing sort guidelines. None of that is advanced. All of it’s skipped in most agent implementations. The irreversible flag is what separates actions the agent can take freely from actions that all the time look forward to a human, and also you determine which is which, not the mannequin.
# False impression 4: The Agent Is Not Liable for Its Errors
This one issues for anybody transport agentic AI to actual customers, which is more and more everybody. In November 2022, Jake Moffatt was grieving the lack of his grandmother and turned to Air Canada‘s chatbot for details about the airline’s bereavement fare coverage. The chatbot advised him he may purchase a full-price ticket and apply for the discounted fare retroactively inside 90 days of journey. Trusting that reply, Moffatt purchased the ticket. When he tried to assert the refund later, Air Canada denied it. Their precise coverage didn’t allow retroactive functions.
Moffatt sued. In February 2024, the British Columbia Civil Decision Tribunal dominated in his favor and ordered Air Canada to compensate him $650.88 plus curiosity and charges.
Air Canada’s defence is the half price taking note of. They argued the chatbot was, in impact, a separate authorized entity, its personal “agent, servant, or consultant,” and that Air Canada subsequently couldn’t be held chargeable for its outputs. Tribunal member Christopher Rivers rejected this immediately, calling it a exceptional submission and noting that whereas a chatbot has an interactive element, it stays simply part of Air Canada’s web site.
The ruling established a precept that now applies to each firm deploying AI in a customer-facing context: you’re liable for what your AI says and does, no matter what your coverage web page says, and no matter how the AI arrived at its reply. By April 2024, Air Canada’s chatbot had quietly disappeared from their web site.
The lesson is not that you just should not deploy AI brokers. It is that “the agent made that call” just isn’t a usable defence, legally or operationally. The agent is your device. Its outputs are your outputs.
This has direct engineering implications. Any agent that may make a dedication to a person, perhaps a refund coverage, a worth, a supply date, a function availability, must be grounded in your precise, present documentation. Not in regardless of the mannequin probabilistically generates from coaching knowledge. Hallucination charges for enterprise chatbots in managed environments nonetheless vary from 3% to 27% relying on the area and guardrail degree. At even a 3% price, a high-volume customer support agent is making flawed commitments continually.
The accountability hole additionally surfaces in a subtler manner: most groups do not construct audit trails. When one thing goes flawed with an agentic system, it is advisable know which step failed, what enter the agent acquired, what it determined to do, and what it really executed. With out that hint, you’ll be able to’t debug the failure, cannot show compliance, and might’t defend your self within the subsequent Air Canada scenario.
# False impression 5: Higher Fashions Clear up the Reliability Downside
That is probably the most counterintuitive one to just accept, as a result of it cuts in opposition to probably the most pure intuition in AI growth: when one thing breaks, improve the mannequin. Analysis from Cemri et al. (2025) on multi-agent system failures discovered one thing that shocked even the researchers: failures in multi-agent methods can’t be totally attributed to LLM limitations, since utilizing the identical mannequin in a single-agent setup typically outperforms multi-agent variations. The reliability downside just isn’t primarily a mannequin downside. It’s a methods structure downside. Coordination, orchestration, and knowledge high quality matter greater than the mannequin model you’re working.
Gartner’s knowledge places numbers to the information high quality piece: 57% of enterprises estimate their knowledge is just not AI-ready. An agent working on incomplete, stale, or inconsistent knowledge will produce dangerous outcomes no matter whether or not you’re on the newest frontier mannequin. Rubbish-in-garbage-out predates massive language fashions by a long time. It does not cease making use of as a result of the system is now described as “clever.”
The second piece of that is observability. Conventional software program breaks loudly: stack traces, 500 errors, log entries with line numbers. Brokers fail quietly. They return assured, well-formatted output whereas being flawed. When an AI agent breaks, you get a clear response that’s silently flawed. The failure propagates downstream by a number of steps earlier than anybody notices, and by then the error has already influenced selections you can not reverse.
The repair is per-step tracing, logging inputs, outputs, latency, and confidence indicators at each device name, not simply on the ultimate response degree:
import json
import datetime
class AgentTracer:
"""
Data a full hint of each device name an agent makes throughout a workflow run.
Captures inputs, outputs, latency, and a confidence rating at every step.
That is the distinction between catching a failure at step 3
and discovering out about it after step 10 when the injury is already finished.
"""
def __init__(self, run_id: str):
self.run_id = run_id
self.steps = []
def hint(
self,
step_index: int,
tool_name: str,
args: dict,
outcome: str,
latency_ms: float,
confidence: float,
low_confidence_threshold: float = 0.70,
) -> dict:
"""
Log one device invocation with full context.
Args:
step_index: Step quantity within the workflow (1-indexed)
tool_name: Title of the device that was referred to as
args: The arguments handed to the device
outcome: The device's output (truncated for the log)
latency_ms: Time the device name took in milliseconds
confidence: Agent's self-reported confidence (0.0-1.0)
low_confidence_threshold: Flag steps under this confidence for evaluation
Returns:
dict: The total hint entry for this step
"""
entry = {
"run_id": self.run_id,
"step": step_index,
"device": tool_name,
"args": args,
# Truncate lengthy outcomes so logs keep readable in dashboards
"result_preview": outcome[:120] + "..." if len(outcome) > 120 else outcome,
"latency_ms": spherical(latency_ms, 2),
"confidence": spherical(confidence, 3),
# Steps under the edge are surfaced within the run abstract for human evaluation
"low_confidence": confidence < low_confidence_threshold,
"timestamp": datetime.datetime.now(datetime.timezone.utc).isoformat(),
}
self.steps.append(entry)
return entry
def abstract(self) -> dict:
"""
Summarize the run: whole steps, whole latency, and flagged steps.
Use this in your post-run logging and alerting pipeline.
Low-confidence steps are the early warning sign for silent failures.
"""
total_latency = sum(s["latency_ms"] for s in self.steps)
flagged = [s for s in self.steps if s["low_confidence"]]
return {
"run_id": self.run_id,
"total_steps": len(self.steps),
"total_latency_ms": spherical(total_latency, 2),
"flagged_steps": len(flagged),
"flagged_details": [
{
"step": s["step"],
"device": s["tool"],
"confidence": s["confidence"],
}
for s in flagged
],
}
# Simulate a 5-step buyer help agent workflow with full tracing
tracer = AgentTracer(run_id="run-support-2026-001")
# Every tuple: (tool_name, args, outcome, latency_ms, confidence)
# Confidence scores under 0.70 can be routinely flagged within the abstract.
simulated_steps = [
(
"search_orders",
{"status": "pending"},
"Found 3 pending orders: ORD-001, ORD-002, ORD-003",
45.2,
0.95, # High confidence -- agent is certain about this step
),
(
"get_order_detail",
{"order_id": "ORD-001"},
"Order ORD-001: 2x Widget, $49.99, estimated delivery June 20",
38.7,
0.91,
),
(
"check_inventory",
{"product_id": "WIDGET-A"},
"WIDGET-A: 12 units in stock at Warehouse Lagos",
210.5,
0.61, # LOW CONFIDENCE -- agent uncertain about warehouse location; flagged
),
(
"update_order",
{"order_id": "ORD-001", "status": "confirmed"},
"Order ORD-001 status updated to confirmed",
55.1,
0.88,
),
(
"send_confirmation_email",
{"to": "customer@example.com", "order_id": "ORD-001"},
"Email queued for delivery to customer@example.com",
30.0,
0.52, # LOW CONFIDENCE -- agent uncertain about recipient; flagged before irreversible send
),
]
print("=== Step-by-step hint ===")
for i, (device, args, outcome, latency, confidence) in enumerate(simulated_steps):
entry = tracer.hint(i + 1, device, args, outcome, latency, confidence)
flag = " [LOW CONFIDENCE -- FLAGGED FOR REVIEW]" if entry["low_confidence"] else ""
print(f" Step {i + 1}: {device}{flag}")
print("n=== Run Abstract ===")
print(json.dumps(tracer.abstract(), indent=2))
Stipulations: Python 3.9+. No exterior packages. Save as agent_tracer.py
run:
Anticipated output:
=== Step-by-step hint ===
Step 1: search_orders
Step 2: get_order_detail
Step 3: check_inventory [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
Step 4: update_order
Step 5: send_confirmation_email [LOW CONFIDENCE -- FLAGGED FOR REVIEW]
=== Run Abstract ===
{
"run_id": "run-support-2026-001",
"total_steps": 5,
"total_latency_ms": 379.5,
"flagged_steps": 2,
"flagged_details": [
{"step": 3, "tool": "check_inventory", "confidence": 0.61},
{"step": 5, "tool": "send_confirmation_email", "confidence": 0.52}
]
}
Two flagged steps in a five-step run. With out per-step tracing, each of these low-confidence calls disappear into the ultimate response. With tracing, they floor instantly, earlier than a affirmation electronic mail goes out to the flawed deal with, earlier than a low-confidence stock rely will get dedicated as floor fact.
That is the distinction between an agent that generally fails and one which fails detectably. Detectably is the one variety price transport.
# Wrapping Up
The PwC AI Agent Survey from Might 2025 discovered that 79% of senior executives mentioned their firms had been already utilizing AI brokers. The headline quantity seems like mass adoption. The identical survey discovered that solely 35% had deployed brokers broadly, solely 17% had deployed them throughout nearly all workflows, and 68% admitted that half or fewer of their workers work together with brokers daily.
Groups are deploying with out working the compound reliability math. They’re treating demos as deployment proxies. They’re piling instruments onto brokers with out schema validation or reversibility gating. They’re transport customer-facing AI with out audit trails. And they’re ready for mannequin upgrades to resolve issues that are not mannequin issues.
The groups that shut this hole will not be those with the largest infrastructure finances or earliest entry to frontier fashions. They will be those who deal with their agent deployments the identical manner they deal with every other vital system: with structured autonomy, human checkpoints on the boundaries that matter, scoped device registries, step-level observability, and a transparent reply to the query of what occurs when one thing goes flawed.
That reply must exist earlier than the primary manufacturing deployment. Not after.
Shittu Olumide is a software program engineer and technical author keen about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. It’s also possible to discover Shittu on Twitter.
















{kind=link}