



Beforehand we mentioned making use of reinforcement studying to Strange Differential Equations (ODEs) by integrating ODEs inside gymnasium. ODEs are a strong device that may describe a variety of programs however are restricted to a single variable. Partial Differential Equations (PDEs) are differential equations involving derivatives of a number of variables that may cowl a far broader vary and extra advanced programs. Typically, ODEs are particular instances or particular assumptions utilized to PDEs.
PDEs embody Maxwell’s Equations (governing electrical energy and magnetism), Navier-Stokes equations (governing fluid stream for plane, engines, blood, and different instances), and the Boltzman equation for thermodynamics. PDEs can describe programs equivalent to versatile constructions, energy grids, manufacturing, or epidemiological fashions in biology. They will signify extremely advanced conduct; the Navier Stokes equations describe the eddies of a speeding mountain stream. Their capability for capturing and revealing extra advanced conduct of real-world programs makes these equations an essential matter for research, each when it comes to describing programs and analyzing identified equations to make new discoveries about programs. Total fields (like fluid dynamics, electrodynamics, structural mechanics) will be devoted to check of only a single set of PDEs.
This elevated complexity comes with a value; the programs captured by PDEs are way more troublesome to research and management. ODEs are additionally described as lumped-parameter programs, the assorted parameters and variables that describe them are “lumped” right into a discrete level (or small variety of factors for a coupled system of ODEs). PDEs are distributed parameter programs that monitor conduct all through area and time. In different phrases, the state area for an ODE is a comparatively small variety of variables, equivalent to time and some system measurements at a particular level. For PDE/distributed parameter programs, the state area measurement can method infinite dimensions, or discretized for computation into hundreds of thousands of factors for every time step. A lumped parameter system controls the temperature of an engine based mostly on a small variety of sensors. A PDE/distributed parameter system would handle temperature dynamics throughout your complete engine.
As with ODEs, many PDEs have to be analyzed (except for particular instances) by modelling and simulation. Nonetheless, because of the greater dimensions, this modelling turns into much more advanced. Many ODEs will be solved by easy functions of algorithms like MATLAB’s ODE45 or SciPy’s solve_ivp. PDEs are modelled throughout grids or meshes the place the PDE is simplified to an algebraic equation (equivalent to by Taylor Collection enlargement) at every level on the grid. Grid technology is a area, a science and artwork, by itself and supreme (or usable) grids can fluctuate tremendously based mostly on drawback geometry and Physics. Grids (and therefore drawback state areas) can quantity within the hundreds of thousands of factors with computation time working in days or perhaps weeks, and PDE solvers are sometimes industrial software program costing tens of hundreds of {dollars}.
Controlling PDEs presents a far larger problem than ODEs. The Laplace remodel that types the idea of a lot classical management principle is a one-dimensional transformation. Whereas there was some progress in PDE management principle, the sector shouldn’t be as complete as for ODE/lumped programs. For PDEs, even primary controllability or observability assessments turn into troublesome because the state area to evaluate will increase by orders of magnitude and fewer PDEs have analytic options. By necessity, we run into design questions equivalent to what a part of the area must be managed or noticed? Can the remainder of the area be in an arbitrary state? What subset of the area does the controller must function over? With key instruments in management principle underdeveloped, and new issues introduced, making use of machine studying has been a serious space of analysis for understanding and controlling PDE programs.
Given the significance of PDEs, there was analysis into growing management methods for them. For instance, Glowinski et. all developed an analytical adjoint based mostly technique from superior useful evaluation counting on simulation of the system. Different approaches, equivalent to mentioned by Kirsten Morris, apply estimations to scale back the order of the PDE to facilitate extra conventional management approaches. Botteghi and Fasel, have begun to use machine studying to manage of those programs (word, that is solely a VERY BRIEF glimpse of the analysis). Right here we’ll apply reinforcement studying on two PDE management issues. The diffusion equation is a straightforward, linear, second order PDE with identified analytic resolution. The Kuramoto–Sivashinsky (Ok-S) equation is a way more advanced 4th order nonlinear equation that fashions instabilities in a flame entrance.
For each these equations we use a easy, small sq. area of grid factors. We goal a sinusoidal sample in a goal space of a line down the center of the area by controlling enter alongside left and proper sides. Enter parameters for the controls are the values on the goal area and the {x,y} coordinates of the enter management factors. Coaching the algorithm required modelling the system improvement by time with the management inputs. As mentioned above, this requires a grid the place the equation is solved at every level then iterated by every time step. I used the py-pde bundle to create a coaching atmosphere for the reinforcement learner (due to the developer of this bundle for his immediate suggestions and assist!). With the py-pde atmosphere, method proceeded as common with reinforcement studying: the actual algorithm develops a guess at a controller technique. That controller technique is utilized at small, discrete time steps and gives management inputs based mostly on the present state of the system that result in some reward (on this case, root imply sq. distinction between goal and present distribution).
In contrast to earlier instances, I solely current outcomes from the genetic-programming controller. I developed code to use a mushy actor critic (SAC) algorithm to execute as a container on AWS Sagemaker. Nonetheless, full execution would take about 50 hours and I didn’t need to spend the cash! I seemed for methods to scale back the computation time, however ultimately gave up as a consequence of time constraints; this text was already taking lengthy sufficient to get out with my job, army reserve responsibility, household visits over the vacations, civic and church involvement, and never leaving my spouse to deal with our child boy alone!
First we’ll focus on the diffusion equation:
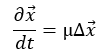
with x as a two dimensional cartesian vector and ∆ the Laplace operator. As talked about, this can be a easy second order (second spinoff) linear partial differential equation in time and two dimensional area. Mu is the diffusion coefficient which determines how briskly results journey by the system. The diffusion equation tends to wash-out (diffuse!) results on the boundaries all through the area and displays steady dynamics. The PDE is carried out as proven beneath with grid, equation, boundary situations, preliminary situations, and goal distribution:
from pde import Diffusion, CartesianGrid, ScalarField, DiffusionPDE, pde
grid = pde.CartesianGrid([[0, 1], [0, 1]], [20, 20], periodic=[False, True])
state = ScalarField.random_uniform(grid, 0.0, 0.2)
bc_left={"worth": 0}
bc_right={"worth": 0}
bc_x=[bc_left, bc_right]
bc_y="periodic"
#bc_x="periodic"
eq = DiffusionPDE(diffusivity=.1, bc=[bc_x, bc_y])
solver=pde.ExplicitSolver(eq, scheme="euler", adaptive = True)
#consequence = eq.remedy(state, t_range=dt, adaptive=True, tracker=None)
stepper=solver.make_stepper(state, dt=1e-3)
goal = 1.*np.sin(2*grid.axes_coords[1]*3.14159265)The issue is delicate to diffusion coefficient and area measurement; mismatch between these two leads to washing out management inputs earlier than they will attain the goal area except calculated over a protracted simulation time. The management enter was up to date and reward evaluated each 0.1 timestep as much as an finish time of T=15.
Resulting from py-pde bundle structure, the management is utilized to at least one column contained in the boundary. Structuring the py-pde bundle to execute with the boundary situation up to date every time step resulted in a reminiscence leak, and the py-pde developer suggested utilizing a stepper operate as a work-around that doesn’t permit updating the boundary situation. This implies the outcomes aren’t precisely bodily, however do show the essential precept of PDE management with reinforcement studying.
The GP algorithm was capable of arrive at a ultimate reward (sum imply sq. error of all 20 factors within the central column) of about 2.0 after about 30 iterations with a 500 tree forest. The outcomes are proven beneath as goal and achieved distributed within the goal area.

Now the extra fascinating and complicated Ok-S equation:
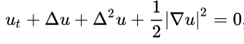
In contrast to the diffusion equation, the Ok-S equation shows wealthy dynamics (as befitting an equation describing flame conduct!). Options might embody steady equilibria or travelling waves, however with rising area measurement all options will ultimately turn into chaotic. The PDE implementation is given by beneath code:
grid = pde.CartesianGrid([[0, 10], [0, 10]], [20, 20], periodic=[True, True])
state = ScalarField.random_uniform(grid, 0.0, 0.5)
bc_y="periodic"
bc_x="periodic"
eq = PDE({"u": "-gradient_squared(u) / 2 - laplace(u + laplace(u))"}, bc=[bc_x, bc_y])
solver=pde.ExplicitSolver(eq, scheme="euler", adaptive = True)
stepper=solver.make_stepper(state, dt=1e-3)
goal=1.*np.sin(0.25*grid.axes_coords[1]*3.14159265)Management inputs are capped at +/-5. The Ok-S equation is of course unstable; if any level within the area exceeds +/- 30 the iteration terminates with a big unfavourable reward for inflicting the system to diverge. Experiments with the Ok-S equation in py-pde revealed sturdy sensitivity to area measurement and variety of grid factors. The equation was run for T=35, each with management and reward replace at dt=0.1.
For every, the GP algorithm had extra hassle arriving at an answer than within the diffusion equation. I selected to manually cease execution when the answer grew to become visually shut; once more, we’re searching for common ideas right here. For the extra advanced system, the controller works higher—probably due to how dynamic the Ok-S equation is the controller is ready to have a much bigger impression. Nonetheless, when evaluating the answer for various run occasions, I discovered it was not steady; the algorithm discovered to reach on the goal distribution at a selected time, to not stabilize at that resolution. The algorithm converged to the beneath resolution, however, because the successive time steps present, the answer is unstable and begins to diverge with rising time steps.
Cautious tuning on the reward operate would assist acquire an answer that will maintain longer, reinforcing how very important right reward operate is. Additionally, in all these instances we aren’t coming to excellent options; however, particularly for the Ok-S equations we’re getting first rate options with comparatively little effort in comparison with non-RL approaches for tackling these types of issues.
The GP resolution is taking longer to unravel with extra advanced issues and has hassle dealing with giant enter variable units. To make use of bigger enter units, the equations it generates turn into longer which make it much less interpretable and slower to compute. Answer equations had scores of phrases reasonably than the dozen or so in ODE programs. Neural community approaches can deal with giant enter variable units extra simply as enter variables solely immediately impression the dimensions of the enter layer. Additional, I believe that neural networks will be capable of deal with extra advanced and bigger issues higher for causes mentioned beforehand in earlier posts. Due to that, I did develop gymnasiums for py-pde diffusion, which might simply be tailored to different PDEs per the py-pde documentation. These gymnasiums can be utilized with completely different NN-based reinforcement studying such because the SAC algorithm I developed (which, as mentioned, runs however takes time).
Changes may be made to the genetic Programming method. For instance, vector illustration of inputs may cut back measurement of resolution equations. Duriez et al.1 all proposes utilizing Laplace remodel to introduce derivatives and integrals into the genetic programming equations, broadening the operate areas they will discover.
The power to deal with extra advanced issues is essential. As mentioned above, PDEs can describe a variety of advanced phenomena. Presently, controlling these programs normally means lumping parameters. Doing so leaves out dynamics and so we find yourself working towards such programs reasonably than with them. Efforts to manage or handle these means greater management effort, missed efficiencies, and elevated threat of failure (small or catastrophic). Higher understanding and management alternate options for PDE programs may unlock main positive factors in engineering fields the place marginal enhancements have been the usual equivalent to visitors, provide chains, and nuclear fusion as these programs behave as excessive dimensional distributed parameter programs. They’re extremely advanced with nonlinear and emergent phenomena however have giant out there knowledge units—supreme for machine studying to maneuver previous present obstacles in understanding and optimization.
For now, I’ve solely taken a really primary take a look at making use of ML to controlling PDEs. Comply with ons to the management drawback embody not simply completely different programs, however optimizing the place within the area the management is utilized, experimenting with reduced-order statement area, and optimizing the management for simplicity or management effort. Along with improved management effectivity, as mentioned in Brunton and Kutz2, machine studying will also be used to derive data-based fashions of advanced bodily programs and to find out decreased order fashions which cut back state area measurement and could also be extra amenable to evaluation and management, by conventional or machine studying strategies. Machine studying and PDEs is an thrilling space of analysis, and I encourage you to see what the professionals are doing!
















{kind=link}