


# Introduction
Agentic coding periods are costly. A single Claude Code session — studying information, writing code, operating assessments, iterating — can burn 10–50x extra tokens than a plain chat dialog. At scale, that provides up quick. Add charge limits that may interrupt a long-running workflow mid-session, and the dependency on a third-party API that may change pricing, implement stricter insurance policies, or go down at any level, and the case for native inference turns into easy.
Native fashions in 2026 are adequate. For the duties Claude Code handles day by day — code completion, refactoring, debugging, codebase clarification — a well-chosen quantized mannequin operating regionally covers the overwhelming majority of actual use circumstances at zero per-token price and with no charge limits. This text covers three inference backends (Ollama, LM Studio, and llama.cpp), the precise setting variables and configuration information to wire each to Claude Code, a curated desk of fashions price operating, and the troubleshooting fixes for the problems you’ll really hit.
# How Claude Code Connects to Any Native Mannequin
The mechanism is easier than most guides make it look. Claude Code sends requests within the Anthropic Messages API format. By default these requests go to Anthropic’s servers. Setting ANTHROPIC_BASE_URL redirects them to any server that speaks the identical format, which now contains Ollama, LM Studio, and llama.cpp natively.
In keeping with the official Claude Code setting variables documentation, the variables that matter for this setup are:
ANTHROPIC_BASE_URL: redirects all API calls from Anthropic’s servers to no matter URL you set. Set this to your native inference server handle.ANTHROPIC_API_KEY: the API key despatched within the request header. Native servers sometimes ignore authentication, so that is often set to a placeholder string like “native” or “ollama.”ANTHROPIC_AUTH_TOKEN: an alternate auth header. Some native servers examine for this as an alternative of the API key. Set it to the identical placeholder.
ANTHROPIC_DEFAULT_SONNET_MODEL, ANTHROPIC_DEFAULT_HAIKU_MODEL, and ANTHROPIC_DEFAULT_OPUS_MODEL: Claude Code internally requests totally different mannequin tiers relying on the duty. These three variables map every tier to your native mannequin’s title. With out them, Claude Code sends requests for claude-sonnet-4-20250514 to your native server, which is able to reject the request as a result of no such mannequin exists regionally.
In January 2026, Ollama added native help for the Anthropic Messages API, which was the technical change that made this workflow sensible with out translation proxies. LM Studio added a local /v1/messages endpoint in model 0.4.1. llama.cpp has had direct Anthropic API help for longer. All three now converse Claude Code’s native protocol.
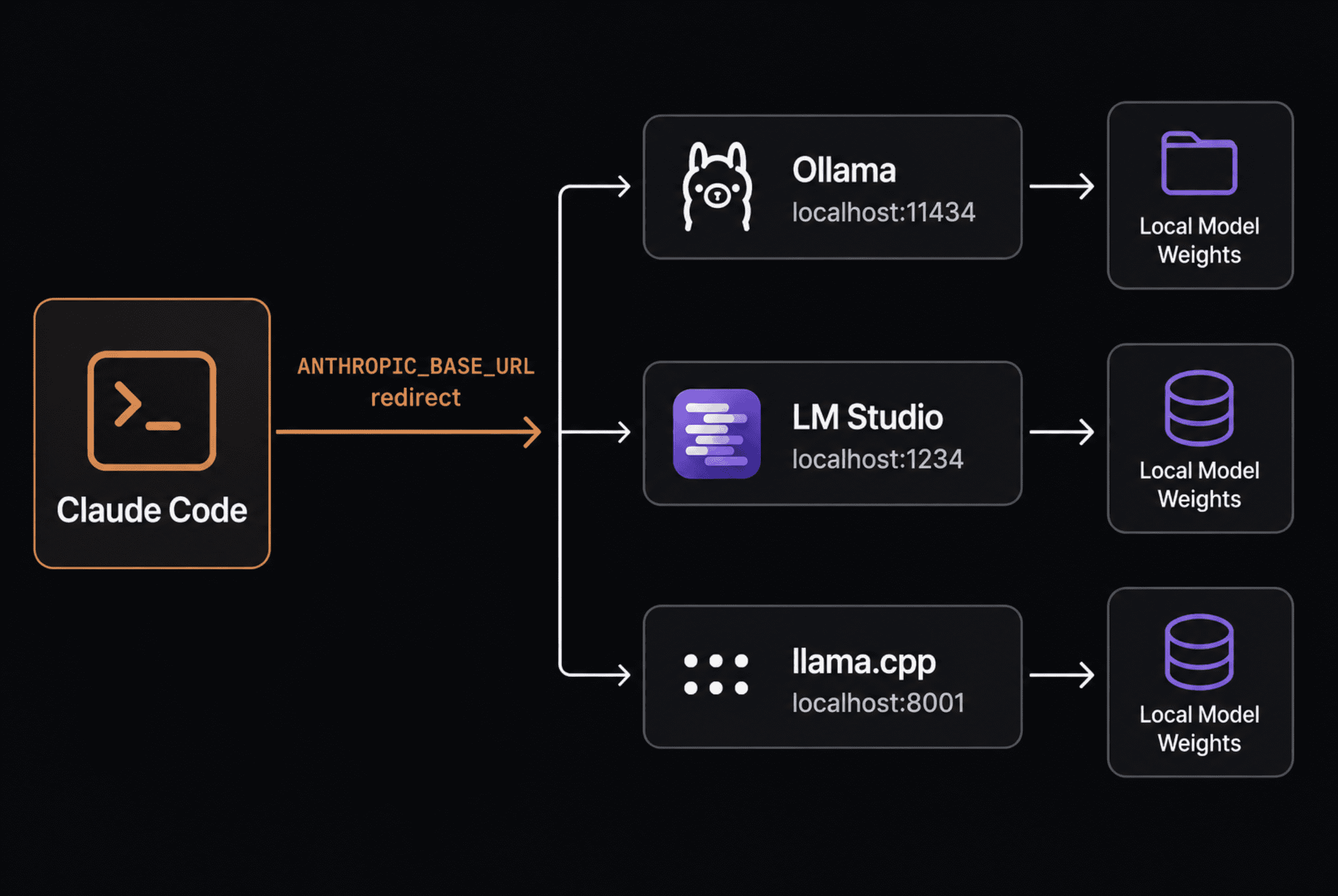
A clear structure diagram exhibiting Claude Code, Ollama, LM Studio, and llama.cpp | Picture by Writer
# Backend 1: Ollama
Ollama is the best start line. It handles all of the complexity of mannequin administration — downloading weights, quantization, GPU and CPU allocation, and serving — behind a easy command-line interface (CLI). One command to put in, one command to tug a mannequin, just a few setting variables to configure. It runs as a background service after set up, so there isn’t a guide server begin required.
Conditions
- macOS, Linux, or Home windows (WSL2 beneficial on Home windows)
- A minimum of 16 GB RAM for sensible use (32 GB beneficial)
- GPU with 8+ GB VRAM for GPU inference, or CPU-only with sufficient RAM
- Ollama v0.14.0 or later required for Anthropic Messages API help
Set up Ollama:
# macOS and Linux -- one command set up
curl -fsSL https://ollama.com/set up.sh | sh
# Confirm the model -- have to be 0.14.0+ for Claude Code compatibility
ollama model
# Anticipated: ollama model is 0.14.x or larger
# Home windows: obtain the installer from https://ollama.com
# Native Home windows help has improved considerably in current releases
After set up, Ollama begins mechanically as a background service on port 11434. You’ll be able to confirm it’s operating:
# Test the Ollama server is reside
curl http://localhost:11434
# Anticipated response:
# Ollama is operating
Pull a coding mannequin:
# GLM-4.7-Flash -- beneficial start line
# Robust device calling, 128K context, matches on 8 GB VRAM
# Apache 2.0 license
ollama pull glm-4.7-flash:newest
# Qwen3-Coder -- robust code technology and instruction following
# Requires 20+ GB VRAM for the total mannequin
ollama pull qwen3-coder
# Devstral-Small -- particularly designed for agentic coding workflows
# Neighborhood-tested for Claude Code compatibility
# 24B, requires 16+ GB VRAM
ollama pull devstral-small-2:24b
# Confirm the mannequin is downloaded and prepared
ollama listing
# Exhibits all pulled fashions with their sizes and modification dates
// Configuring Claude Code to Use Ollama
Choice 1: Shell export (present terminal session solely)
# Redirect Claude Code to your native Ollama server
export ANTHROPIC_BASE_URL="http://localhost:11434"
# Native servers don't require actual authentication
# Set these to any non-empty string -- Ollama ignores the worth
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
# Map Claude Code's mannequin tier requests to your native mannequin title
# Claude Code internally requests sonnet/haiku/opus -- these variables
# translate these tier names to no matter mannequin you will have pulled regionally
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
# Launch Claude Code -- it should now use Ollama as an alternative of the Anthropic API
claude
Choice 2: ~/.claude/settings.json (everlasting, applies to all periods)
This method survives terminal restarts and applies each time you launch Claude Code. Claude Code reads setting variables from settings.json at startup in order that they take impact regardless of how claude was launched.
Create or edit ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:newest"
}
}
Choice 3: .env file in venture listing (per-project override)
In order for you a selected venture to make use of a special mannequin whereas conserving your world settings on the Anthropic API:
# .env in your venture root -- loaded mechanically by Claude Code
ANTHROPIC_BASE_URL=http://localhost:11434
ANTHROPIC_API_KEY=ollama
ANTHROPIC_AUTH_TOKEN=ollama
ANTHROPIC_DEFAULT_SONNET_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_HAIKU_MODEL=qwen3-coder
ANTHROPIC_DEFAULT_OPUS_MODEL=qwen3-coder
Confirm the connection:
# Launch Claude Code with a easy take a look at
claude
# Inside Claude Code, run a fundamental immediate:
# > What mannequin are you operating?
# A neighborhood mannequin ought to reply with out making any Anthropic API calls.
# To substantiate no exterior calls are being made, run with verbose logging:
claude --verbose
# Search for strains exhibiting requests going to localhost:11434
# moderately than api.anthropic.com
Full working sequence from scratch:
curl -fsSL https://ollama.com/set up.sh | sh # 1. Set up Ollama
ollama pull glm-4.7-flash:newest # 2. Pull mannequin (~4 GB)
export ANTHROPIC_BASE_URL="http://localhost:11434" # 3. Redirect Claude Code
export ANTHROPIC_API_KEY="ollama" # 4. Set placeholder auth
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
claude # 5. Launch
# Backend 2: LM Studio
LM Studio is the best alternative if you would like a graphical interface for shopping and managing fashions moderately than working completely within the terminal. Since model 0.4.1, it features a native Anthropic-compatible /v1/messages endpoint — the identical path Claude Code expects — so no translation layer or proxy is required.
Conditions:
- macOS, Home windows, or Linux
- GPU with 6+ GB VRAM beneficial (CPU-only is feasible however gradual)
- Obtain from lmstudio.ai or use the CLI installer for headless servers
Set up and configure LM Studio:
# On a server or VM with out a GUI -- CLI installer
curl -fsSL https://releases.lmstudio.ai/cli/set up.sh | bash
# Or obtain the desktop app from https://lmstudio.ai for GUI use
GUI setup steps:
- Open LM Studio and seek for a coding mannequin (search “qwen coder” or “devstral”).
- Obtain the mannequin. LM Studio handles quantization choice mechanically.
- Go to the Native Server tab (the
<>icon within the left sidebar). - Set the context dimension. LM Studio recommends beginning with no less than 25,000 tokens and rising for higher outcomes.
- Click on Begin Server.
- Observe the port (default: 1234) and replica the mannequin title precisely as proven.
Observe: Copy the mannequin identifier precisely. LM Studio shows the precise string it’s worthwhile to go to
ANTHROPIC_DEFAULT_SONNET_MODEL. A mismatch right here is the most typical failure mode.
Configure Claude Code:
# Set the bottom URL to LM Studio's native server
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
# Substitute the mannequin title with what LM Studio reveals to your loaded mannequin
# Copy it precisely -- together with any model suffix or quantization tag
export ANTHROPIC_DEFAULT_SONNET_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen2.5-coder-32b-instruct"
export ANTHROPIC_DEFAULT_OPUS_MODEL="qwen2.5-coder-32b-instruct"
Or persistently in ~/.claude/settings.json:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:1234",
"ANTHROPIC_API_KEY": "lm-studio",
"ANTHROPIC_AUTH_TOKEN": "lm-studio",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen2.5-coder-32b-instruct",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen2.5-coder-32b-instruct"
}
}
Find out how to run:
# 1. Begin the LM Studio server from the GUI (Native Server tab > Begin Server)
# 2. Set setting variables
export ANTHROPIC_BASE_URL="http://localhost:1234"
export ANTHROPIC_API_KEY="lm-studio"
export ANTHROPIC_AUTH_TOKEN="lm-studio"
export ANTHROPIC_DEFAULT_SONNET_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="your-model-name-here"
export ANTHROPIC_DEFAULT_OPUS_MODEL="your-model-name-here"
# 3. Launch
claude
# Backend 3: llama.cpp
llama.cpp is the best alternative whenever you want direct management over inference parameters — quantization sort, KV cache configuration, batch dimension, thread depend — or when you’re operating on a server and need the bottom overhead. It has native Anthropic Messages API help, so no proxy or translation layer is required.
Conditions:
- A GGUF-format mannequin file (obtain from Hugging Face; seek for “GGUF” variations of any mannequin)
- CUDA-capable GPU for GPU inference, or CPU-only for slower inference
- CMake and a C++ compiler for supply builds (on Linux/CUDA, supply is beneficial)
Set up llama.cpp:
# macOS -- Homebrew is easiest
brew set up llama.cpp
# Linux with CUDA -- construct from supply for greatest GPU efficiency
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B construct -DGGML_CUDA=ON # Allow CUDA acceleration
cmake --build construct --config Launch # Construct
# Binaries in ./construct/bin/
# Linux CPU-only construct
cmake -B construct
cmake --build construct --config Launch
# Home windows -- pre-built binaries obtainable at:
# https://github.com/ggml-org/llama.cpp/releases
# Obtain the CUDA or CPU variant matching your {hardware}
Obtain a GGUF mannequin:
# Set up the Hugging Face CLI in the event you should not have it
pip set up huggingface-hub
# Obtain GLM-4.7-Flash in Q4_K_XL quantization (~4.5 GB)
# This quantization provides a very good dimension/high quality stability for coding
huggingface-cli obtain unsloth/GLM-4.7-Flash-GGUF
GLM-4.7-Flash-UD-Q4_K_XL.gguf
--local-dir ./fashions/
# Or obtain Qwen3-Coder in This autumn quantization (~15 GB for 32B)
huggingface-cli obtain Qwen/Qwen3-Coder-32B-Instruct-GGUF
qwen3-coder-32b-instruct-q4_k_m.gguf
--local-dir ./fashions/
Begin the llama.cpp server:
# Begin llama-server with Anthropic API help and a 128K context window
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash" # This title goes in ANTHROPIC_DEFAULT_SONNET_MODEL
--port 8001
--ctx-size 131072 # 128K context -- essential for big codebases
--flash-attn # Reminiscence-efficient consideration, improves velocity
--n-gpu-layers 99 # Offload all layers to GPU; take away for CPU-only
# For CPU-only inference (no GPU):
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash"
--port 8001
--ctx-size 32768 # Scale back context dimension on CPU to maintain reminiscence manageable
--threads 8 # Match your CPU core depend
Key flags defined:
--alias: the mannequin title string Claude Code will ship in requests. SetANTHROPIC_DEFAULT_SONNET_MODELto match this precisely.--ctx-size: context window in tokens. 131072 = 128K. Bigger is best for codebase evaluation however makes use of extra VRAM. Scale back in the event you get out-of-memory errors.--flash-attn: Flash Consideration reduces peak VRAM by processing consideration in smaller blocks. Allow it every time your construct helps it.--n-gpu-layers 99: offloads all transformer layers to the GPU. The server mechanically makes use of fewer layers if VRAM is tight.
Configure Claude Code:
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
# Should match the --alias you handed to llama-server precisely
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
Find out how to run:
# Terminal 1: begin the llama.cpp server
llama-server
--model ./fashions/GLM-4.7-Flash-UD-Q4_K_XL.gguf
--alias "glm-4.7-flash"
--port 8001
--ctx-size 131072
--flash-attn
--n-gpu-layers 99
# Terminal 2: configure and launch Claude Code
export ANTHROPIC_BASE_URL="http://localhost:8001"
export ANTHROPIC_API_KEY="llama-cpp"
export ANTHROPIC_AUTH_TOKEN="llama-cpp"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"
claude
# The Full settings.json
Atmosphere variable exports final solely so long as the terminal session. For a sturdy configuration, use ~/.claude/settings.json. Claude Code reads variables from this file at startup in order that they apply regardless of how Claude was launched — from the terminal, from a VS Code process, or from a script.
Here’s a production-ready settings.json with all variables defined:
{
"env": {
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": "ollama",
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:newest",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:newest",
"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"
}
}
Why CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS: "1" issues:
When utilizing Claude Code by way of non-Anthropic backends, Claude Code provides Anthropic-specific experimental beta flags to request headers — flags that third-party and native servers don’t acknowledge. This causes Error: Surprising worth(s) for the anthropic-beta header on most native inference servers. Setting this variable to "1" strips these headers earlier than the request goes out, which eliminates the error with out affecting any core Claude Code performance.
Switching between backends:
For those who work with a number of backends — Ollama for day by day use, the Anthropic API for complicated duties — the cleanest method is sustaining separate shell scripts moderately than enhancing settings.json backwards and forwards:
# use-local.sh -- swap to Ollama
export ANTHROPIC_BASE_URL="http://localhost:11434"
export ANTHROPIC_API_KEY="ollama"
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:newest"
export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:newest"
echo "Claude Code → native Ollama (glm-4.7-flash)"
# use-anthropic.sh -- swap again to the Anthropic API
unset ANTHROPIC_BASE_URL
unset ANTHROPIC_AUTH_TOKEN
unset ANTHROPIC_DEFAULT_SONNET_MODEL
unset ANTHROPIC_DEFAULT_HAIKU_MODEL
unset ANTHROPIC_DEFAULT_OPUS_MODEL
# ANTHROPIC_API_KEY ought to already be set to your actual key in your rc file
echo "Claude Code → Anthropic API"
Supply both script in your present session:
supply ./use-local.sh
claude
# Once you want the true API for a posh process:
supply ./use-anthropic.sh
claude
# Finest Native Fashions for Claude Code in 2026
{Hardware} is the primary constraint. For Claude Code with native fashions to be genuinely usable for coding duties moderately than only a demo, goal for 32 GB of RAM — Apple Silicon unified reminiscence or PC RAM. 16 GB is viable with smaller quantized fashions and CPU offload, however technology velocity will likely be noticeably slower on multi-step agentic duties.
| Mannequin | VRAM Wanted | Context | Strengths | License | Pull Command |
|---|---|---|---|---|---|
| glm-4.7-flash | 8 GB | 128K | Instrument calling, quick, low VRAM | Apache 2.0 | ollama pull glm-4.7-flash |
| devstral-small-2:24b | 16 GB | 32K | Agentic coding workflows | Apache 2.0 | ollama pull devstral-small-2:24b |
| qwen3-coder | 20 GB | 128K | Code technology, directions | Apache 2.0 | ollama pull qwen3-coder |
| qwen3.5:27b | 20 GB | 256K | Robust all-round, big context | Apache 2.0 | ollama pull qwen3.5:27b |
| gemma4:26b | 20 GB | 256K | Reasoning, 77% coding bench | Gemma License | ollama pull gemma4:26b |
# Troubleshooting Frequent Points
- Connection refused when launching Claude Code: The inference server shouldn’t be operating. That is the most typical challenge and the simplest to diagnose.
# Test if Ollama is operating curl http://localhost:11434 # Anticipated: "Ollama is operating" # Test if LM Studio server is operating curl http://localhost:1234/v1/fashions # Ought to return a JSON listing of loaded fashions # Test if llama-server is operating curl http://localhost:8001/well being # Ought to return {"standing":"okay"} # If not operating -- begin the server first, then launch Claude Code ollama serve # Ollama # LM Studio: use the GUI Native Server tab # llama.cpp: run the llama-server command from the Backend 3 part - Mannequin not discovered or unknown mannequin error: The mannequin title in your
ANTHROPIC_DEFAULT_SONNET_MODELdoesn’t match what the server is aware of.# Record all fashions Ollama has obtainable ollama listing # The mannequin title in ANTHROPIC_DEFAULT_SONNET_MODEL should match EXACTLY # together with the tag -- "glm-4.7-flash:newest" not "glm-4.7-flash" # Confirm with a direct API name to substantiate what the server sees curl http://localhost:11434/v1/fashions - Instrument calls failing or returning errors: For streaming device calls, which Claude Code makes use of when executing capabilities or scripts, Ollama model 0.14.3-rc1 or later is required. Earlier variations within the 0.14.x collection had incomplete streaming device name help.
# Test your Ollama model ollama model # If beneath 0.14.3, replace Ollama curl -fsSL https://ollama.com/set up.sh | sh anthropic-betaheader error:You will notice:
Error: Surprising worth(s) for the anthropic-beta header. This occurs as a result of Claude Code provides Anthropic-specific experimental beta flags that native servers don’t acknowledge. Repair it by including this to yoursettings.jsonenv block:"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1"- Reverting to the Anthropic API:
# Shell session -- unset the redirect variables unset ANTHROPIC_BASE_URL unset ANTHROPIC_AUTH_TOKEN unset ANTHROPIC_DEFAULT_SONNET_MODEL unset ANTHROPIC_DEFAULT_HAIKU_MODEL unset ANTHROPIC_DEFAULT_OPUS_MODEL # Then make sure that your actual API secret's set echo $ANTHROPIC_API_KEY # Ought to present your sk-ant-... key, not a placeholder # For those who used settings.json -- take away or remark out the env block # and restart Claude Code - Gradual technology velocity: For agentic Claude Code duties, technology velocity issues as a result of every device name is a spherical journey. If velocity is insufficient:
- Change to a smaller or extra aggressively quantized mannequin (Q4_K_M as an alternative of Q8).
- Allow
--flash-attnin llama.cpp if not already set. - Scale back context dimension (
--ctx-size); bigger contexts are slower to prefill. - On Ollama, set
OLLAMA_NUM_GPU_LAYERS=99in your setting to power most GPU offload.
# Conclusion
What used to require fragile adapters and hacks is now a five-step course of. Set up the inference backend, pull a mannequin, set three setting variables, and Claude Code routes to your native machine as an alternative of Anthropic’s API. The configuration takes underneath 5 minutes after getting the mannequin downloaded.
The sensible result’s a coding assistant that prices nothing to run after setup, has no charge limits, retains your code completely in your machine, and covers the overwhelming majority of actual coding use circumstances at high quality ranges that weren’t obtainable in native fashions a 12 months in the past. Begin with Ollama and glm-4.7-flash — it has the bottom {hardware} requirement, probably the most constant tool-calling help, and the quickest path to a working setup. As soon as that’s operating, scale up the mannequin primarily based in your {hardware} and the standard degree you really want.
Shittu Olumide is a software program engineer and technical author enthusiastic about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. You can even discover Shittu on Twitter.














{kind=link}