



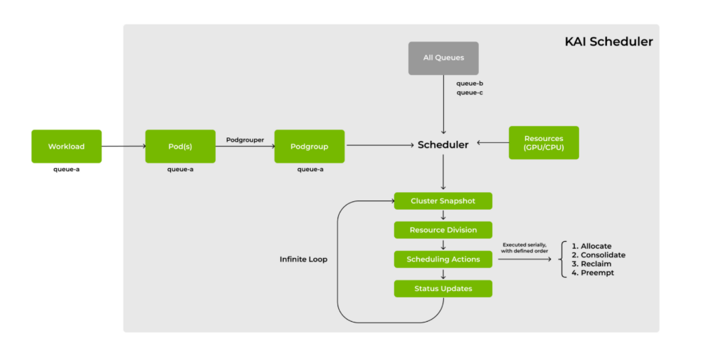
KAI Scheduler workflow (credit score: NVIDIA)
In the present day, NVIDIA posted a weblog saying the open-source launch of the KAI Scheduler, a Kubernetes-native GPU scheduling resolution, now out there below the Apache 2.0 license.
Initially developed inside the Run:ai platform, KAI Scheduler is now out there to the neighborhood whereas additionally persevering with to be packaged and delivered as a part of the NVIDIA Run:ai platform.
NVIDIA mentioned this initiative underscores a dedication to advancing each open-source and enterprise AI infrastructure, fostering an lively and collaborative neighborhood, encouraging contributions, suggestions, and innovation.
In its submit, NVIDIA gives an outline of KAI Scheduler’s technical particulars, spotlight its worth for IT and ML groups, and clarify the scheduling cycle and actions.
Managing AI workloads on GPUs and CPUs presents numerous challenges that conventional useful resource schedulers typically fail to satisfy. The scheduler was developed to particularly deal with these points:
- Managing fluctuating GPU calls for
- Lowered wait instances for compute entry
- Useful resource ensures or GPU allocation
- Seamlessly connecting AI instruments and frameworks
Managing fluctuating GPU calls for: AI workloads can change quickly. As an illustration, you may want just one GPU for interactive work (for instance, for knowledge exploration) after which abruptly require a number of GPUs for distributed coaching or a number of experiments. Conventional schedulers battle with such variability.
The KAI Scheduler repeatedly recalculates fair-share values and adjusts quotas and limits in actual time, routinely matching the present workload calls for. This dynamic method helps guarantee environment friendly GPU allocation with out fixed handbook intervention from directors.
Lowered wait instances for compute entry: For ML engineers, time is of the essence. The scheduler reduces wait instances by combining gang scheduling, GPU sharing, and a hierarchical queuing system that allows you to submit batches of jobs after which step away, assured that duties will launch as quickly as assets can be found and in alignment of priorities and equity.
To optimize useful resource utilization, even within the face of fluctuating demand, the scheduler employs two efficient methods for each GPU and CPU workloads:
- Bin-packing and consolidation: Maximizes compute utilization by combating useful resource fragmentation—packing smaller duties into partially used GPUs and CPUs—and addressing node fragmentation by reallocating duties throughout nodes.
- Spreading: Evenly distributes workloads throughout nodes or GPUs and CPUs to attenuate the per-node load and maximize useful resource availability per workload.
Useful resource ensures or GPU allocation: In shared clusters, some researchers safe extra GPUs than mandatory early within the day to make sure availability all through. This observe can result in underutilized assets, even when different groups nonetheless have unused quotas.
KAI Scheduler addresses this by implementing useful resource ensures. It ensures that AI practitioner groups obtain their allotted GPUs, whereas additionally dynamically reallocating idle assets to different workloads. This method prevents useful resource hogging and promotes general cluster effectivity.
Seamlessly connecting AI instruments and frameworks: Connecting AI workloads with numerous AI frameworks may be daunting. Historically, groups face a maze of handbook configurations to tie collectively workloads with instruments like Kubeflow, Ray, Argo, and the Coaching Operator. This complexity delays prototyping.
KAI Scheduler addresses this by that includes a built-in podgrouper that routinely detects and connects with these instruments and frameworks—decreasing configuration complexity and accelerating growth.
For the remainder of this NVIDIA weblog submit, go to: https://developer.nvidia.com/weblog/nvidia-open-sources-runai-scheduler-to-foster-community-collaboration/

















{kind=link}