


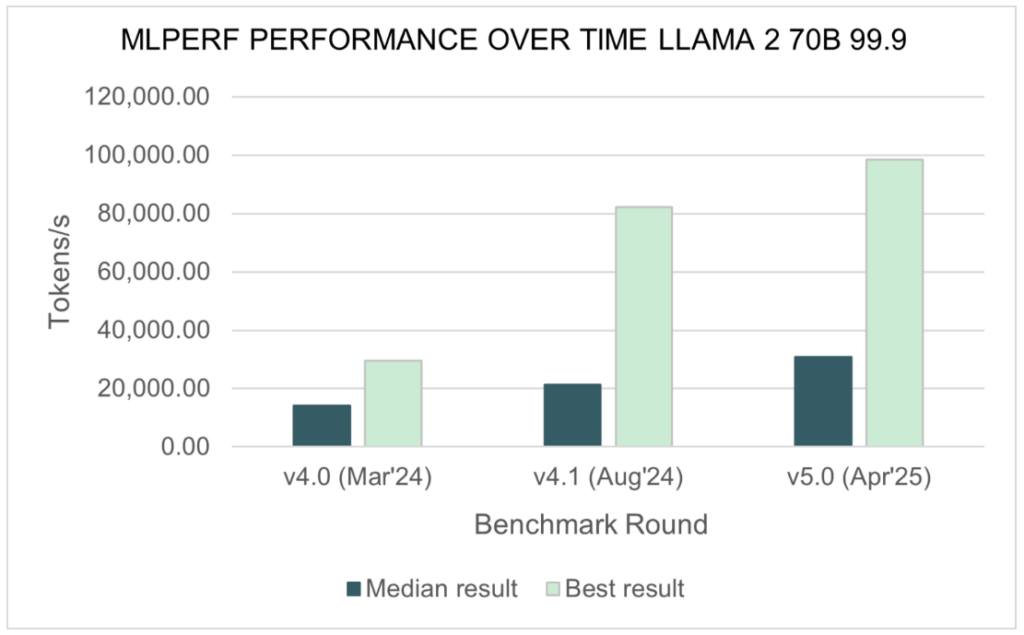
supply: MLCommons
“It’s clear now that a lot of the ecosystem is targeted squarely on deploying generative AI, and that the efficiency benchmarking suggestions loop is working,” mentioned David Kanter, head of MLPerf at MLCommons. “We’re seeing an unprecedented flood of recent generations of accelerators. The {hardware} is paired with new software program strategies, together with aligned help throughout {hardware} and software program for the FP4 information format. With these advances, the group is setting new data for generative AI inference efficiency.”
The benchmark outcomes for this spherical embody outcomes for six newly obtainable or soon-to-be-shipped processors:
- AMD Intuition MI325X
- Intel Xeon 6980P “Granite Rapids”
- Google TPU Trillium (TPU v6e)
- NVIDIA B200
- NVIDIA Jetson AGX Thor 128
- NVIDIA GB200
Consistent with advances within the AI group, MLPerf Inference v5.0 introduces a brand new benchmark using the Llama 3.1 405B mannequin, marking a brand new bar for the dimensions of a generative AI inference mannequin in a efficiency benchmark. Llama 3.1 405B incorporates 405 billion parameters in its mannequin whereas supporting enter and output lengths as much as 128,000 tokens (in comparison with solely 4,096 tokens for Llama 2 70B). The benchmark checks three separate duties: basic question-answering, math, and code technology.
“That is our most formidable inference benchmark to-date,” mentioned Miro Hodak, co-chair of the MLPerf Inference working group. “It displays the trade pattern towards bigger fashions, which may enhance accuracy and help a broader set of duties. It’s a tougher and time-consuming check, however organizations are attempting to deploy real-world fashions of this order of magnitude. Trusted, related benchmark outcomes are important to assist them make higher selections on the easiest way to provision them.”
The Inference v5.0 suite additionally provides a brand new twist to its current benchmark for Llama 2 70B with an extra check that provides low-latency necessities: Llama 2 70B Interactive. Reflective of trade developments towards interactive chatbots in addition to next-generation reasoning and agentic techniques, the benchmark requires techniques underneath check (SUTs) to fulfill extra demanding system response metrics for time to first token (TTFT) and time per output token (TPOT).
“A important measure of the efficiency of a question system or a chatbot is whether or not it feels conscious of an individual interacting with it. How shortly does it begin to reply to a immediate, and at what tempo does it ship its whole response?” mentioned Mitchelle Rasquinha, MLPerf Inference working group co-chair. “By implementing tighter necessities for responsiveness, this interactive model of the Llama 2 70B check affords new insights into the efficiency of LLMs in real-world eventualities.”
Extra data on the choice of the Llama 3.1 405B and the brand new Llama 2 70B Interactive benchmarks might be discovered on this supplemental weblog.
Additionally new to Inference v5.0 is a datacenter benchmark that implements a graph neural community (GNN) mannequin. GNNs are helpful for modeling hyperlinks and relationships between nodes in a community and are generally utilized in suggestion techniques, knowledge-graph answering, fraud-detection techniques, and different kinds of graph-based functions.
The GNN datacenter benchmark implements the RGAT mannequin, primarily based on the Illinois Graph Benchmark Heterogeneous (IGBH) dataset containing 547,306,935 nodes and 5,812,005,639 edges.
Extra data on the development of the RGAT benchmark might be discovered right here.
The Inference v5.0 benchmark introduces a brand new Automotive PointPainting benchmark for edge computing units, particularly vehicles. Whereas the MLPerf Automotive working group continues to develop the Minimal Viable Product benchmark first introduced final summer season, this check supplies a proxy for an vital edge-computing state of affairs: 3D object detection in digicam feeds for functions reminiscent of self-driving vehicles.
Extra data on the Automotive PointPainting benchmark might be discovered right here.
“We hardly ever introduce 4 new checks in a single replace to the benchmark suite,” mentioned Miro Hodak, “however we felt it was essential to greatest serve the group. The speedy tempo of development in machine studying and the breadth of recent functions are each staggering, and stakeholders want related and up-to-date information to tell their decision-making.”
MLPerf Inference v5.0 contains 17,457 efficiency outcomes from 23 submitting organizations: AMD, ASUSTeK, Broadcom, Cisco, CoreWeave, CTuning, Dell, FlexAI, Fujitsu, GATEOverflow, Giga Computing, Google, HPE, Intel, Krai, Lambda, Lenovo, MangoBoost, NVIDIA, Oracle, Quanta Cloud Know-how, Supermicro, and Sustainable Metallic Cloud.
“We wish to welcome the 5 first-time submitters to the Inference benchmark: CoreWeave, FlexAI, GATEOverflow, Lambda, and MangoBoost,” mentioned David Kanter. “The persevering with progress locally of submitters is a testomony to the significance of correct and reliable efficiency metrics to the AI group. I’d additionally like to spotlight Fujitsu’s broad set of datacenter energy benchmark submissions and GateOverflow’s edge energy submissions on this spherical, which reminds us that vitality effectivity in AI techniques is an more and more important concern in want of correct information to information decision-making.”
“The machine studying ecosystem continues to present the group ever larger capabilities. We’re growing the dimensions of AI fashions being skilled and deployed, attaining new ranges of interactive responsiveness, and deploying AI compute extra broadly than ever earlier than,” mentioned Kanter. “We’re excited to see new generations of {hardware} and software program ship these capabilities, and MLCommons is proud to current thrilling outcomes for a variety of techniques and a number of other novel processors with this launch of the MLPerf Inference benchmark. Our work to maintain the benchmark suite present, complete, and related at a time of speedy change is an actual accomplishment, and ensures that we’ll proceed to ship useful efficiency information to stakeholders.
MLCommons is the world’s chief in AI benchmarking. An open engineering consortium supported by over 125 members and associates, MLCommons has a confirmed file of bringing collectively academia, trade, and civil society to measure and enhance AI. The muse for MLCommons started with the MLPerf benchmarks in 2018, which quickly scaled as a set of trade metrics to measure machine studying efficiency and promote transparency of machine studying strategies. Since then, MLCommons has continued utilizing collective engineering to construct the benchmarks and metrics required for higher AI – in the end serving to to guage and enhance AI applied sciences’ accuracy, security, velocity, and effectivity.
















{kind=link}