



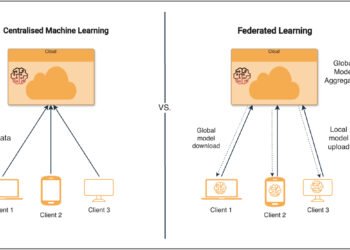
Impressed by Andrej Kapathy’s current youtube video on Let’s reproduce GPT-2 (124M), I’d wish to rebuild it with many of the coaching optimizations in Jax. Jax is constructed for extremely environment friendly computation pace, and it’s fairly attention-grabbing to check Pytorch with its current coaching optimization, and Jax with its associated libraries like Flax (Layers API for neural community coaching for Jax)and Optax (a gradient processing and optimization library for JAX). We are going to rapidly study what’s Jax, and rebuild the GPT with Jax. In the long run, we are going to evaluate the token/sec with multiGPU coaching between Pytorch and Jax!

What’s Jax?
Primarily based on its readthedoc, JAX is a Python library for accelerator-oriented array computation and program transformation, designed for high-performance numerical computing and large-scale machine studying. I want to introduce JAX with its title. Whereas somebody calls it Simply One other XLA (Accelerated Linear Algibra), I want to name it J(it) A(utograd) X(LA) to display its functionality of excessive effectivity.
J — Simply-in-time (JIT) Compilation. While you run your python perform, Jax converts it right into a primitive set of operation referred to as Jaxpr. Then the Jaxpr expression might be transformed into an enter for XLA, which compiles the lower-level scripts to provide an optimized exutable for goal gadget (CPU, GPU or TPU).
A — Autograd. Computing gradients is a crucial a part of fashionable machine studying strategies, and you’ll simply name jax.grad() to get gradients which allows you to optimize the fashions.
X — XLA. It is a open-source machine studying compiler for CPU, GPU and ML accelerators. Typically, XLA performs a number of built-in optimization and evaluation passes on the StableHLO graph, then sends the HLO computation to a backend for additional HLO-level optimizations. The backend then performs target-specific code technology.
These are just a few key options of JAX, nevertheless it additionally has many consumer pleasant numpy-like APIs in jax.numpy , and computerized vectorization with jax.vmap , and parallize your codes into a number of units by way of jax.pmap . We are going to cowl extra Jax ideas nd functions within the futher blogs, however now let’s reproduct the NanoGPT with Jax!
From Consideration to Transformer
GPT is a decoder-only transformer mannequin, and the important thing constructing block is Consideration module. We will first outline a mannequin config dataclass to avoid wasting the mannequin hyperparameters of the mannequin, in order that the mannequin module can eat it effectively to initialize the mannequin structure. Just like the 124M GPT mannequin, right here we initialize a 12-layer transformer decoder with 12 heads and vocab dimension as 50257 tokens, every of which has 768 embedding dimension. The block dimension for the eye calculation is 1024.
from dataclasses import dataclass@dataclass
class ModelConfig:
vocab_size: int = 50257
n_head: int = 12
n_embd: int = 768
block_size: int = 1024
n_layer: int = 12
dropout_rate: float = 0.1
Subsequent involves the important thing constructing block of the transformer mannequin — Consideration. The thought is to course of the inputs into three weight matrics: Key, Question, and Worth. Right here we depend on the flax , a the Jax Layer and coaching API library to initialize the three weight matrix, by simply name the flax.linen.Dense . As talked about, Jax has many numpy-like APIs, so we reshape the outputs after the load matrix with jax.numpy.reshape from [batch_size, sequence_length, embedding_dim] to [batch_size, sequence_length, num_head, embedding_dim / num_head]. Since we have to do matrix multiplication on the important thing and worth matrics, jax additionally has jax.numpy.matmul API and jax.numpy.transpose (transpose the important thing matrix for multiplication).

Notice that we have to put a masks on the eye matrix to keep away from info leakage (forestall the earlier tokens to have entry to the later tokens), jax.numpy.tril helps construct a decrease triangle array, and jax.numpy.the place can fill the infinite quantity for us to get 0 after softmax jax.nn.softmax . The complete codes of multihead consideration might be discovered under.
from flax import linen as nn
import jax.numpy as jnpclass CausalSelfAttention(nn.Module):
config: ModelConfig
@nn.compact
def __call__(self, x, deterministic=True):
assert len(x.form) == 3
b, l, d = x.form
q = nn.Dense(self.config.n_embd)(x)
ok = nn.Dense(self.config.n_embd)(x)
v = nn.Dense(self.config.n_embd)(x)
# q*ok / sqrt(dim) -> softmax -> @v
q = jnp.reshape(q, (b, l, d//self.config.n_head , self.config.n_head))
ok = jnp.reshape(ok, (b, l, d//self.config.n_head , self.config.n_head))
v = jnp.reshape(v, (b, l, d//self.config.n_head , self.config.n_head))
norm = jnp.sqrt(record(jnp.form(ok))[-1])
attn = jnp.matmul(q,jnp.transpose(ok, (0,1,3,2))) / norm
masks = jnp.tril(attn)
attn = jnp.the place(masks[:,:,:l,:l], attn, float("-inf"))
probs = jax.nn.softmax(attn, axis=-1)
y = jnp.matmul(probs, v)
y = jnp.reshape(y, (b,l,d))
y = nn.Dense(self.config.n_embd)(y)
return y
You could discover that there is no such thing as a __init__ or ahead strategies as you possibly can see within the pytorch. That is the particular factor for jax, the place you possibly can explicitly outline the layers with setup strategies, or implicitly outline them withn the ahead move by including nn.compact on high of __call__ technique. [ref]
Subsequent let’s construct the MLP and Block layer, which incorporates Dense layer, Gelu activation perform, LayerNorm and Dropout. Once more flax.linen has the layer APIs to assist us construct the module. Notice that we’ll move a deterministic boolean variable to regulate completely different behaviors throughout coaching or analysis for some layers like Dropout.
class MLP(nn.Module):config: ModelConfig
@nn.compact
def __call__(self, x, deterministic=True):
x = nn.Dense(self.config.n_embd*4)(x)
x = nn.gelu(x, approximate=True)
x = nn.Dropout(price=self.config.dropout_rate)(x, deterministic=deterministic)
x = nn.Dense(self.config.n_embd)(x)
x = nn.Dropout(price=self.config.dropout_rate)(x, deterministic=deterministic)
return x
class Block(nn.Module):
config: ModelConfig
@nn.compact
def __call__(self, x):
x = nn.LayerNorm()(x)
x = x + CausalSelfAttention(self.config)(x)
x = nn.LayerNorm()(x)
x = x + MLP(self.config)(x)
return x
Now Let’s use the above blocks to construct the NanoGPT:
Given the inputs of a sequence token ids, we use the flax.linen.Embed layer to get place embeddings and token embeddings. Them we move them into the Block module N instances, the place N is variety of the layers outlined within the Mannequin Config. In the long run, we map the outputs from the final Block into the possibilities for every token within the vocab to foretell the subsequent token. In addition to the ahead __call__ technique, let’s additionally create a init strategies to get the dummy inputs to get the mannequin’s parameters.
class GPT(nn.Module):config: ModelConfig
@nn.compact
def __call__(self, x, deterministic=False):
B, T = x.form
assert T <= self.config.block_size
pos = jnp.arange(0, T)[None]
pos_emb = nn.Embed(self.config.block_size, self.config.n_embd)(pos)
wte = nn.Embed(self.config.vocab_size, self.config.n_embd)
tok_emb = wte(x)
x = tok_emb + pos_emb
for _ in vary(self.config.n_layer):
x = Block(self.config)(x)
x = nn.LayerNorm()(x)
logits = nn.Dense(config.n_embd, config.vocab_size)
# logits = wte.attend(x) # parameter sharing
return logits
def init(self, rng):
tokens = jnp.zeros((1, self.config.block_size), dtype=jnp.uint16)
params = jax.jit(tremendous().init, static_argnums=(2,))(rng, tokens, True)
return params
Now let’s varify the variety of parameters: We first initialize the mannequin config dataclass and the random key, then create a dummy inputs and feed in into the GPT mannequin. Then we make the most of the jax.util.treemap API to create a depend parameter perform. We received 124439808 (124M) parameters, similar quantity as Huggingface’s GPT2, BOOM!


DataLoader and Coaching Loop
Let’s now overfit a small dataset. To make it comparable inAndrej’s video on Pytorch NanoGPT, let’s use the toy dataset that he shared in his video. We use the GPT2′ tokenizer from tiktoken library to tokenize all of the texts from the enter file, and convert the tokens into jax.numpy.array for Jax’s mannequin coaching.
class DataLoader:
def __init__(self, B, T):
self.current_position = 0
self.B = B
self.T = Twith open("enter.txt","r") as f:
textual content = f.learn()
enc = tiktoken.get_encoding("gpt2")
self.tokens = jnp.array(enc.encode(textual content))
print(f"loaded {len(self.tokens)} tokens within the datasets" )
print(f" 1 epoch = {len(self.tokens)//(B*T)} batches")
def next_batch(self):
B,T = self.B, self.T
buf = self.tokens[self.current_position:self.current_position+B*T+1]
x,y = jnp.reshape(buf[:-1],(B,T)), jnp.reshape(buf[1:],(B,T))
self.current_position += B*T
if self.current_position + B*T+1 > len(self.tokens):
self.current_position = 0
return x,y

Subsequent, let’s neglect distributed coaching and optimization first, and simply create a naive coaching loop for a sanity test. The very first thing after intialize the mannequin is to create a TrainState, a mannequin state the place we will replace the parameters and gradients. The TrainState takes three vital inputs: apply_fn (mannequin ahead perform), params (mannequin parameters from the init technique), and tx (an Optax gradient transformation).
Then we use the train_step perform to replace the mannequin state (gradients and parameters) to proceed the mannequin coaching. Optax present the softmax cross entropy because the loss perform for the subsequent token prediction job, and jax.value_and_grad calculates the gradients and the loss worth for the loss perform. Lastly, we replace the mannequin’s state with the brand new parameters utilizing the apply_gradients API. [ref] Don’t neglect to jit the train_step perform to scale back the computation overhead!
def init_train_state(key, config) -> TrainState:
mannequin = GPT(config)
params = mannequin.init(key)
optimizer = optax.adamw(3e-4, b1=0.9, b2=0.98, eps=1e-9, weight_decay=1e-1)
train_state = TrainState.create(
apply_fn=mannequin.apply,
params=params,
tx=optimizer)
return train_state@jax.jit
def train_step(state: TrainState, x: jnp.ndarray, y: jnp.ndarray) -> Tuple[jnp.ndarray, TrainState]:
def loss_fn(params: FrozenDict) -> jnp.ndarray:
logits = state.apply_fn(params, x, False)
loss = optax.softmax_cross_entropy_with_integer_labels(logits, y).imply()
return loss
loss, grads = jax.value_and_grad(loss_fn, has_aux=False)(state.params)
new_state = state.apply_gradients(grads=grads)
return loss, new_state
Now all the things is prepared for the poorman’s coaching loop.. Let’s test the loss worth. The mannequin’s prediction needs to be higher than the random guess, so the loss needs to be decrease than -ln(1/50257)≈10.825. What we count on from the overfitting a single batch is that: at first the loss is near 10.825, then it goes down to shut to 0. Let’s take a batch of (x, y) and run the coaching loop for 50 instances. I additionally add related log to calculate the coaching pace.

As we will see, the loss worth is strictly what we count on, and the coaching throughput is round 400–500 ok token/sec. Which is already 40x quicker than Pytorch’s preliminary model with none optimization in Andrej’s video. Notice that we run the Jax scripts in 1 A100 GPU which ought to take away the {hardware} distinction for the pace comparability. There is no such thing as a .to(gadget) stuff to maneuver your mannequin or knowledge from host CPU to gadget GPU, which is without doubt one of the advantages from Jax!
In order that’s it and we made it. We are going to make the coaching 10x extra quicker in Half 2 with extra optimizations…
Half 2: The journey of coaching optimization to 1350k tokens/sec in a single GPU!
“Except in any other case famous, all photos are by the writer”














{kind=link}