


objects round us could be barely radioactive. Americium in smoke detectors, radium in some classic watches, or uranium in classic glass; a full checklist could be lengthy. Principally, these objects are secure and can’t trigger a well being danger. It is usually attention-grabbing to determine them and research the matter on the atomic degree. And we will do that utilizing a radiation detector. In the primary half, I did an exploratory knowledge evaluation of the gamma spectroscopy knowledge. Within the second half, I created a machine studying mannequin for detecting radioactive isotopes. That is the final third half, and it’s time so as to add a created mannequin to the true app!
On this story, I’ll take a look at two approaches:
- I’ll create a public Streamlit app that will likely be hosted totally free on Streamlit Cloud (the app hyperlink is added to the tip of the article).
- As a extra versatile and common answer, I’ll create a Python HTMX-based app that may talk with actual {hardware} and make predictions in actual time.
In the identical method as within the earlier half, I’ll use a Radiacode scintillation detector to get the info (disclaimer: the system used on this take a look at was offered by the producer; I don’t get any business revenue from their gross sales, and I didn’t get any editorial enter about all of the exams). Readers who don’t have a Radiacode {hardware} will be capable of take a look at the app and the mannequin utilizing recordsdata accessible on Kaggle.
Let’s get began!
1. Isotopes Classification Mannequin
This mannequin was described within the earlier half. It’s based mostly on XGBoost, and I educated the mannequin utilizing totally different radioactive samples. I used samples that may be legally bought, like classic uranium glass or outdated watches with radium dials made within the Nineteen Fifties. As talked about earlier than, I additionally used a Radiacode scintillation detector, which permits me to get the gamma spectrum of the article. Solely 10-20 years in the past, a lot of these detectors had been accessible solely in large labs; at present, they are often bought for the worth of a mid-range smartphone.
The mannequin comprises three elements:
- The XGBoost-based mannequin itself.
- An inventory of radioactive isotopes (like Lead-214 or Actinium-228), on which the mannequin was educated. The Radiacode scintillation detector returns 1024 spectrum values, and 23 of them had been used for the mannequin.
- A label encoder to transform checklist indexes into human-readable names.
Let’s wrap all this right into a single Python class:
from xgboost import XGBClassifier
from sklearn.preprocessing import LabelEncoder
class IsotopesClassificationModel:
""" Gamma Spectrum Classification Mannequin """
def __init__(self):
""" Load fashions """
path = self._get_models_path()
self._classifier = self._load_model(path + "/XGBClassifier.json")
self._isotopes = self._load_isotopes(path + "/isotopes.json")
self._labels_encoder = self._load_labels_encoder(path + "/LabelEncoder.npy")
def predict(self, spectrum: Spectrum) -> str:
""" Predict the isotope """
options = SpectrumPreprocessing.convert_to_features(
spectrum, self._isotopes
)
preds = self._classifier.predict([features])
preds = self._labels_encoder.inverse_transform(preds)
return preds[0]
@staticmethod
def _load_model(filename: str) -> XGBClassifier:
""" Load mannequin from file """
bst = XGBClassifier()
bst.load_model(filename)
return bst
@staticmethod
def _load_isotopes(filename: str) -> Checklist:
with open(filename, "r") as f_in:
return json.load(f_in)
@staticmethod
def _load_labels_encoder(filename: str) -> LabelEncoder:
le = LabelEncoder()
le.classes_ = np.load(filename)
return le
@staticmethod
def _get_models_path() -> str:
""" Get path to fashions. Mannequin recordsdata are saved in
'fashions/V1/' folder """
parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
return parent_dir + f"/fashions/{IsotopesClassificationModel.VERSION}"A Spectrum class comprises the spectrum knowledge we get from a radiation detector:
@dataclass
class Spectrum:
""" Radiation spectrum knowledge """
period: datetime.timedelta
a0: float
a1: float
a2: float
counts: checklist[int]Right here, counts is a gamma spectrum, which is represented by a listing of 1024 channel values. Spectrum knowledge could be exported utilizing the official Radiacode Android app or retrieved immediately from a tool utilizing a radiacode Python library.
To load the spectrum into the mannequin, I created a SpectrumPreprocessing class:
class SpectrumPreprocessing:
""" Gamma Spectrum Preprocessing """
@staticmethod
def convert_to_features(spectrum: Spectrum, isotopes: Checklist) -> np.array:
""" Convert the spectrum to the checklist of options for prediction """
sp_norm = SpectrumPreprocessing._normalize(spectrum)
energies = [energy for _, energy in isotopes]
channels = [SpectrumPreprocessing.energy_to_channel(spectrum, energy) for energy in energies]
return np.array([sp_norm.counts[ch] for ch in channels])
@staticmethod
def load_from_xml_file(file_path: str) -> Spectrum:
""" Load spectrum from a Radiacode Android app file """Right here, I skip some code blocks that had been already revealed within the earlier half. Extracting options from the gamma spectrum was additionally defined there, and I extremely advocate studying that half first.
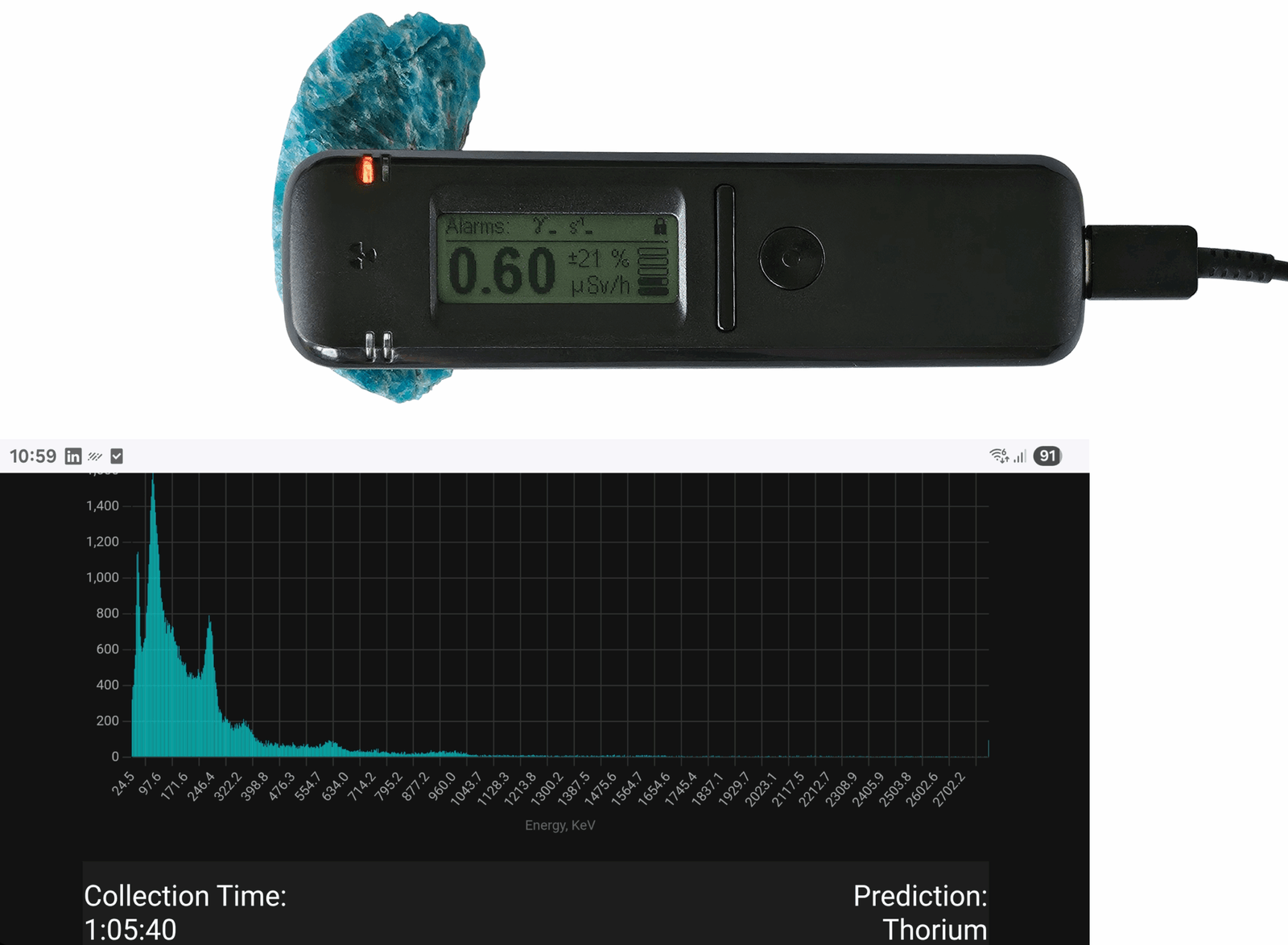
Now, let’s take a look at the mannequin! I took a Radiacode detector and picked up a gamma spectrum inside 10 minutes:

This Chinese language pendant was marketed as “ion-generated,” and it’s barely radioactive. Its gamma spectrum, collected within the official Radiacode Android app, seems like this:

After ready for ~10 minutes, I exported the spectrum into an XML file. Now, we will run the mannequin:
from spectrum import SpectrumPreprocessing
from ml_models import IsotopesClassificationModel
sp = SpectrumPreprocessing.load_from_file("spectrum.xml")
mannequin = IsotopesClassificationModel()
consequence = mannequin.predict(sp)
print(consequence)
#> ThoriumAs we will see, the mannequin works effectively. We are able to evaluate the peaks with spectra of recognized isotopes (for instance, right here or right here) and ensure that the spectrum belongs to thorium.
2. Streamlit
The mannequin works; nevertheless, we stay within the XXI century, and virtually no one will run the console app to get the outcomes. As an alternative, we will make the app accessible on-line, so all Radiacode customers will be capable of run it.
There are a lot of Python frameworks for making browser-based apps, and Streamlit might be the most well-liked within the knowledge science group. And what’s necessary for us, a Streamlit Group Cloud platform permits everybody to publish their apps utterly totally free. To do that, let’s make the app first.
2.1 Streamlit App
A Streamlit framework is comparatively simple to make use of, not less than if a standard-looking app is sweet for us. Personally, I’m not a fan of this strategy. These frameworks disguise all low-level implementation particulars from customers. It’s easy to make a prototype, however the UI logic will likely be tightly coupled with a really area of interest framework and can’t be reused wherever else. Doing every part non-standard, which isn’t supported by the framework, could be virtually not possible or exhausting to implement with out digging into tons of abstractions and pages of code. Nonetheless, in our case, the prototype is all we want.
Usually, a Streamlit code is easy, and we simply want to explain the logical hierarchy of our web page:
import streamlit as st
import logging
logger = logging.getLogger(__name__)
def is_xml_valid(xml_data: str) -> bool:
""" Examine if the XML has legitimate measurement and knowledge """
return len(xml_data) < 65535 and xml_data.startswith(" Elective[Spectrum]:
""" Load spectrum from the StringIO stream """
xml_data = stringio.learn()
if is_xml_valid(xml_data):
return SpectrumPreprocessing.load_from_xml(xml_data)
return None
def foremost():
""" Predominant app """
st.set_page_config(page_title="Gamma Spectrum")
st.title("Radiacode Spectrum Detection")
st.textual content(
"Export the spectrum to XML utilizing the Radiacode app, and "
"add it to see the outcomes."
)
# File Add
uploaded_file = st.file_uploader(
"Select the XML file", kind="xml", key="uploader",
)
if uploaded_file just isn't None:
stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
if sp := get_spectrum(stringio):
# Prediction
mannequin = IsotopesClassificationModel()
consequence = mannequin.predict(sp)
logger.information(f"Spectrum prediction: {consequence}")
# Present consequence
st.success(f"Prediction End result: {consequence}")
# Draw
fig = get_spectrum_barchart(sp)
st.pyplot(fig)
if __name__ == "__main__":
logger.setLevel(logging.INFO)
foremost()As we will see, the total app requires a minimal quantity of Python code. Streamlit will render all HTML for us, with title, file add, and outcomes. As a bonus, I will even show a spectrum utilizing Matplotlib:
def get_spectrum_barchart(sp: Spectrum) -> plt.Determine:
""" Get Matplotlib's barchart """
counts = SpectrumPreprocessing.get_counts(sp)
power = [
SpectrumPreprocessing.channel_to_energy(sp, x) for x in range(len(counts))
]
fig, ax = plt.subplots(figsize=(9, 6))
ax.spines["top"].set_color("lightgray")
ax.spines["right"].set_color("lightgray")
# Bars
ax.bar(power, counts, width=3.0, label="Counts")
# X values
ticks_x = [SpectrumPreprocessing.channel_to_energy(sp, ch) for ch in range(0, len(counts), len(counts) // 20)]
labels_x = [f"{int(ch)}" for ch in ticks_x]
ax.set_xticks(ticks_x, labels=labels_x, rotation=45)
ax.set_xlim(power[0], power[-1])
ax.set_ylim(0, None)
ax.set_title("Gamma spectrum")
ax.set_xlabel("Vitality, keV")
ax.set_ylabel("Counts")
return figNow we will run the app regionally:
streamlit run st-app.pyAfter that, our app is absolutely operational and could be examined in a browser:

As talked about earlier than, I’m not a fan of very high-level frameworks and like to have a greater understanding of how issues work “beneath the hood.” Nonetheless, contemplating that I spent solely about 100 traces of code to make a totally useful internet app, I can’t complain – for prototyping, it really works effectively.
2.2 Streamlit Group Cloud
When the app is examined regionally, it’s time to make it public! A Streamlit Cloud is a free service, and clearly, it has a variety of limitations:
- The app runs in a Docker-like container. Your GitHub account have to be linked to Streamlit. When the container begins, it pulls your code from GitHub and runs it.
- On the time of scripting this textual content, container assets are restricted to 2 cores and as much as 2,7 GB of RAM. It will be too constrained to run a 70B measurement LLM, however for a small XGBoost mannequin, it’s greater than sufficient.
- Streamlit doesn’t present any everlasting storage. After shutdown or restart, all logs and short-term recordsdata will likely be misplaced (you should use API secrets and techniques and hook up with another cloud storage out of your Python code if wanted).
- After a interval of inactivity (about half-hour), the container will likely be stopped, and all short-term recordsdata will even be misplaced. If somebody opens the app hyperlink, it can run once more.
As readers can guess, an inactive app prices Streamlit virtually nothing as a result of it shops solely a small configuration file. And it’s a good answer for a free service – it permits us to publish the app with none prices and provides folks a hyperlink to run it.
To publish the app in Streamlit, we have to carry out three easy steps.
First, we have to commit our Python app to GitHub. A necessities.txt file can also be obligatory. Streamlit container makes use of it to put in required Python dependencies. In my case, it seems like this:
xgboost==3.0.2
scikit-learn==1.6.1
numpy==1.26.4
streamlit==1.47.0
pillow==11.1.0
matplotlib==3.10.3
xmltodict==0.14.2Server settings could be modified utilizing a .streamlit/config.toml file. In my case, I restricted the uploaded file measurement to 1 MB as a result of all spectra recordsdata are smaller:
[server]
# Max measurement, in megabytes, for recordsdata uploaded with the file_uploader.
# Default: 200
maxUploadSize = 1Second, we have to log in to share.streamlit.io utilizing a GitHub account and provides permission to entry the supply code.
Lastly, we will create a brand new Streamlit mission. Within the mission settings, we will additionally choose the specified URL and atmosphere:

If every part was carried out accurately, we will see our app operating:

At this second, customers worldwide may entry our app! In my case, I chosen a gammaspectrumdetection title, and the app is out there utilizing this URL.
3. FastAPI + HTMX App
As readers can see, Streamlit is a pleasant answer for a easy prototype. Nonetheless, within the case of the radiation detector, I wish to see knowledge coming from actual Radiacode {hardware}. This could be not possible to do in Streamlit; this library simply was not designed for that. As an alternative, I’ll use a number of production-grade frameworks:
- An HTMX framework permits us to make a totally useful internet interface.
- FastAPI will run the server.
- The ML mannequin will course of the info retrieved in real-time from a radiation detector utilizing a Radiacode library.
As talked about earlier than, these readers who don’t have a Radiacode {hardware} will be capable of replay the info utilizing uncooked log recordsdata, saved from an actual system. A hyperlink to the app and all recordsdata is out there on the finish of the article.
Let’s get into it!
3.1 HTML/HTMX
The app is linked to a Radiacode detector, and I made a decision to point out a connection standing, radiation degree, and a spectrum graph on the web page. On the backside, a spectrum assortment time and an ML mannequin prediction will likely be displayed.
An index.html file for this structure seems like this:
Gamma Spectrum & Monitoring
Assortment Time:
n/a
Prediction:
n/a
















{kind=link}