




Picture by Editor | Midjourney
This tutorial demonstrates the way to use Hugging Face’s Datasets library for loading datasets from totally different sources with just some traces of code.
Hugging Face Datasets library simplifies the method of loading and processing datasets. It offers a unified interface for hundreds of datasets on Hugging Face’s hub. The library additionally implements varied efficiency metrics for transformer-based mannequin analysis.
Preliminary Setup
Sure Python improvement environments might require putting in the Datasets library earlier than importing it.
!pip set up datasets
import datasets
Loading a Hugging Face Hub Dataset by Title
Hugging Face hosts a wealth of datasets in its hub. The next perform outputs an inventory of those datasets by title:
from datasets import list_datasets
list_datasets()
Let’s load certainly one of them, particularly the feelings dataset for classifying feelings in tweets, by specifying its title:
information = load_dataset("jeffnyman/feelings")
In the event you wished to load a dataset you got here throughout whereas looking Hugging Face’s web site and are not sure what the appropriate naming conference is, click on on the “copy” icon beside the dataset title, as proven under:

The dataset is loaded right into a DatasetDict object that comprises three subsets or folds: prepare, validation, and take a look at.
DatasetDict({
prepare: Dataset({
options: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
options: ['text', 'label'],
num_rows: 2000
})
take a look at: Dataset({
options: ['text', 'label'],
num_rows: 2000
})
})
Every fold is in flip a Dataset object. Utilizing dictionary operations, we will retrieve the coaching information fold:
train_data = all_data["train"]
The size of this Dataset object signifies the variety of coaching situations (tweets).
Resulting in this output:
Getting a single occasion by index (e.g. the 4th one) is as simple as mimicking an inventory operation:
which returns a Python dictionary with the 2 attributes within the dataset performing because the keys: the enter tweet textual content, and the label indicating the emotion it has been categorised with.
{'textual content': 'i'm ever feeling nostalgic concerning the fire i'll know that it's nonetheless on the property',
'label': 2}
We will additionally get concurrently a number of consecutive situations by slicing:
This operation returns a single dictionary as earlier than, however now every key has related an inventory of values as an alternative of a single worth.
{'textual content': ['i didnt feel humiliated', ...],
'label': [0, ...]}
Final, to entry a single attribute worth, we specify two indexes: one for its place and one for the attribute title or key:
Loading Your Personal Information
If as an alternative of resorting to Hugging Face datasets hub you wish to use your personal dataset, the Datasets library additionally lets you, by utilizing the identical ‘load_dataset()’ perform with two arguments: the file format of the dataset to be loaded (resembling “csv”, “textual content”, or “json”) and the trail or URL it’s positioned in.
This instance hundreds the Palmer Archipelago Penguins dataset from a public GitHub repository:
url = "https://uncooked.githubusercontent.com/allisonhorst/palmerpenguins/grasp/inst/extdata/penguins.csv"
dataset = load_dataset('csv', data_files=url)
Flip Dataset Into Pandas DataFrame
Final however not least, it’s generally handy to transform your loaded information right into a Pandas DataFrame object, which facilitates information manipulation, evaluation, and visualization with the in depth performance of the Pandas library.
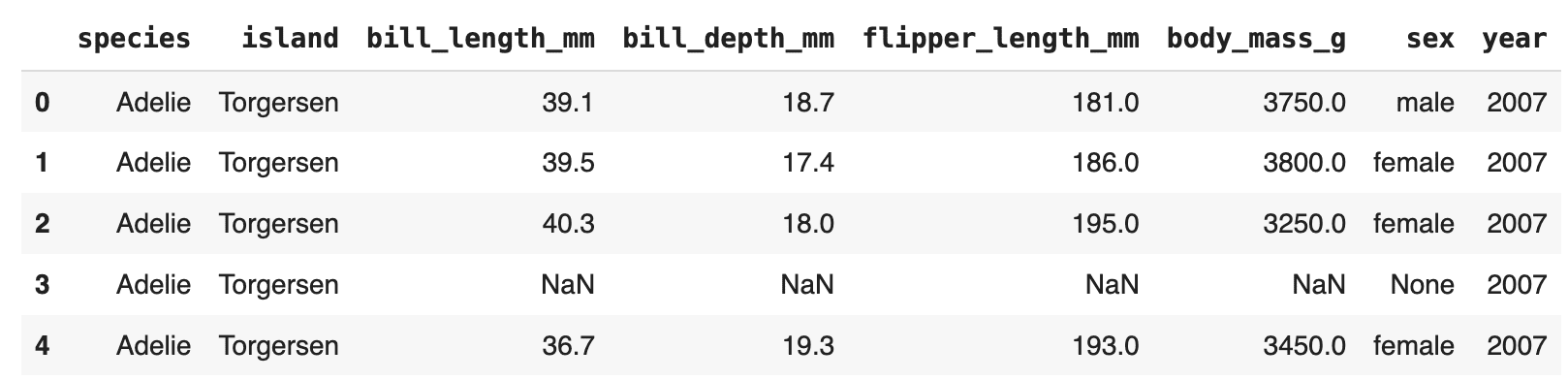
penguins = dataset["train"].to_pandas()
penguins.head()
Now that you’ve realized the way to effectively load datasets utilizing Hugging Face’s devoted library, the subsequent step is to leverage them by utilizing Giant Language Fashions (LLMs).
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.
Picture by Editor | Midjourney
This tutorial demonstrates the way to use Hugging Face’s Datasets library for loading datasets from totally different sources with just some traces of code.
Hugging Face Datasets library simplifies the method of loading and processing datasets. It offers a unified interface for hundreds of datasets on Hugging Face’s hub. The library additionally implements varied efficiency metrics for transformer-based mannequin analysis.
Preliminary Setup
Sure Python improvement environments might require putting in the Datasets library earlier than importing it.
!pip set up datasets
import datasets
Loading a Hugging Face Hub Dataset by Title
Hugging Face hosts a wealth of datasets in its hub. The next perform outputs an inventory of those datasets by title:
from datasets import list_datasets
list_datasets()
Let’s load certainly one of them, particularly the feelings dataset for classifying feelings in tweets, by specifying its title:
information = load_dataset("jeffnyman/feelings")
In the event you wished to load a dataset you got here throughout whereas looking Hugging Face’s web site and are not sure what the appropriate naming conference is, click on on the “copy” icon beside the dataset title, as proven under:
The dataset is loaded right into a DatasetDict object that comprises three subsets or folds: prepare, validation, and take a look at.
DatasetDict({
prepare: Dataset({
options: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
options: ['text', 'label'],
num_rows: 2000
})
take a look at: Dataset({
options: ['text', 'label'],
num_rows: 2000
})
})
Every fold is in flip a Dataset object. Utilizing dictionary operations, we will retrieve the coaching information fold:
train_data = all_data["train"]
The size of this Dataset object signifies the variety of coaching situations (tweets).
Resulting in this output:
Getting a single occasion by index (e.g. the 4th one) is as simple as mimicking an inventory operation:
which returns a Python dictionary with the 2 attributes within the dataset performing because the keys: the enter tweet textual content, and the label indicating the emotion it has been categorised with.
{'textual content': 'i'm ever feeling nostalgic concerning the fire i'll know that it's nonetheless on the property',
'label': 2}
We will additionally get concurrently a number of consecutive situations by slicing:
This operation returns a single dictionary as earlier than, however now every key has related an inventory of values as an alternative of a single worth.
{'textual content': ['i didnt feel humiliated', ...],
'label': [0, ...]}
Final, to entry a single attribute worth, we specify two indexes: one for its place and one for the attribute title or key:
Loading Your Personal Information
If as an alternative of resorting to Hugging Face datasets hub you wish to use your personal dataset, the Datasets library additionally lets you, by utilizing the identical ‘load_dataset()’ perform with two arguments: the file format of the dataset to be loaded (resembling “csv”, “textual content”, or “json”) and the trail or URL it’s positioned in.
This instance hundreds the Palmer Archipelago Penguins dataset from a public GitHub repository:
url = "https://uncooked.githubusercontent.com/allisonhorst/palmerpenguins/grasp/inst/extdata/penguins.csv"
dataset = load_dataset('csv', data_files=url)
Flip Dataset Into Pandas DataFrame
Final however not least, it’s generally handy to transform your loaded information right into a Pandas DataFrame object, which facilitates information manipulation, evaluation, and visualization with the in depth performance of the Pandas library.
penguins = dataset["train"].to_pandas()
penguins.head()
Now that you’ve realized the way to effectively load datasets utilizing Hugging Face’s devoted library, the subsequent step is to leverage them by utilizing Giant Language Fashions (LLMs).
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.















{kind=link}