



(LLMs) are bettering in effectivity and are actually in a position to perceive completely different information codecs, providing potentialities for myriads of purposes in several domains. Initially, LLMs have been inherently in a position to course of solely textual content. The picture understanding function was built-in by coupling an LLM with one other picture encoding mannequin. Nevertheless, gpt-4o was educated on each textual content and pictures and is the primary true multimodal LLM that may perceive each textual content and pictures. Different modalities corresponding to audio are built-in into trendy LLMs by way of different AI fashions, e.g., OpenAI’s Whisper fashions.
LLMs are actually getting used extra as data processors the place they will course of information in several codecs. Integrating a number of modalities into LLMs opens areas of quite a few purposes in schooling, Enterprise, and different sectors. One such software is the processing of instructional movies, documentaries, webinars, shows, enterprise conferences, lectures, and different content material utilizing LLMs and interacting with this content material extra naturally. The audio modality in these movies accommodates wealthy data that may very well be utilized in various purposes. In instructional settings, it may be used for customized studying, enhancing accessibility of scholars with particular wants, examine help creation, distant studying help with out requiring a instructor’s presence to know content material, and assessing college students’ information a few matter. In enterprise settings, it may be used for coaching new staff with onboarding movies, extracting and producing information from recording conferences and shows, personalized studying supplies from product demonstration movies, and extracting insights from recorded business conferences with out watching hours of movies, to call a couple of.
This text discusses the event of an software to work together with movies in a pure manner and create studying content material from them. The applying has the next options:
- It takes an enter video both by way of a URL or from an area path and extracts audio from the video
- Transcribes the audio utilizing OpenAI’s state-of-the-art mannequin
gpt-4o-transcribe, which has demonstrated improved Phrase Error Price (WER) efficiency over present Whisper fashions throughout a number of established benchmarks - Creates a vector retailer of the transcript and develops a retrieval increase era (RAG) to ascertain a dialog with the video transcript
- Reply to customers’ questions in textual content and speech utilizing completely different voices, selectable from the applying’s UI.
- Creates studying content material corresponding to:
- Hierarchical illustration of the video contents to supply customers with fast insights into the principle ideas and supporting particulars
- Generate quizzes to rework passive video watching into energetic studying by difficult customers to recall and apply data offered within the video.
- Generates flashcards from the video content material that help energetic recall and spaced repetition studying strategies
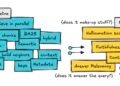
Your entire workflow of the applying is proven within the following determine.

The entire codebase, together with detailed directions for set up and utilization, is obtainable on GitHub.
Right here is the construction of the GitHub repository. The primary Streamlit software implements the GUI interface and calls a number of different features from different function and helper modules (.py recordsdata).

As well as, you possibly can visualize the codebase by opening the “codebase visualization” HTML file in a browser, which describes the buildings of every module.

Let’s delve into the step-by-step improvement of this software. I can’t focus on your entire code, however solely its main half. The entire code within the GitHub repository is sufficiently commented.
Video Enter and Processing
Video enter and processing logic are applied in transcriber.py. When the applying hundreds, it verifies whether or not FFMPEG is current (verify_ffmpeg) within the software’s root listing. FFMPEG is required for downloading a video (if the enter is a URL) and extracting audio from the video which is then used to create a transcript.
def verify_ffmpeg():
"""Confirm that FFmpeg is obtainable and print its location."""
# Add FFmpeg to PATH
os.environ['PATH'] = FFMPEG_LOCATION + os.pathsep + os.environ['PATH']
# Verify if FFmpeg binaries exist
ffmpeg_path = os.path.be a part of(FFMPEG_LOCATION, 'ffmpeg.exe')
ffprobe_path = os.path.be a part of(FFMPEG_LOCATION, 'ffprobe.exe')
if not os.path.exists(ffmpeg_path):
increase FileNotFoundError(f"FFmpeg executable not discovered at: {ffmpeg_path}")
if not os.path.exists(ffprobe_path):
increase FileNotFoundError(f"FFprobe executable not discovered at: {ffprobe_path}")
print(f"FFmpeg discovered at: {ffmpeg_path}")
print(f"FFprobe discovered at: {ffprobe_path}")
# Attempt to execute FFmpeg to verify it really works
strive:
# Add shell=True for Home windows and seize errors correctly
consequence = subprocess.run([ffmpeg_path, '-version'],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True, # This can assist with permission points on Home windows
examine=False)
if consequence.returncode == 0:
print(f"FFmpeg model: {consequence.stdout.decode().splitlines()[0]}")
else:
error_msg = consequence.stderr.decode()
print(f"FFmpeg error: {error_msg}")
# Verify for particular permission errors
if "Entry is denied" in error_msg:
print("Permission error detected. Making an attempt different method...")
# Attempt an alternate method - simply examine file existence with out execution
if os.path.exists(ffmpeg_path) and os.path.exists(ffprobe_path):
print("FFmpeg recordsdata exist however execution check failed as a consequence of permissions.")
print("WARNING: The app might fail when making an attempt to course of movies.")
# Return paths anyway and hope for the perfect when truly used
return ffmpeg_path, ffprobe_path
increase RuntimeError(f"FFmpeg execution failed: {error_msg}")
besides Exception as e:
print(f"Error checking FFmpeg: {e}")
# Fallback choice if verification fails however recordsdata exist
if os.path.exists(ffmpeg_path) and os.path.exists(ffprobe_path):
print("WARNING: FFmpeg recordsdata exist however verification failed.")
print("Making an attempt to proceed anyway, however video processing might fail.")
return ffmpeg_path, ffprobe_path
increase
return ffmpeg_path, ffprobe_path
The video enter is within the type of a URL (as an illustration, YouTube URL) or an area file path. The process_video perform determines the enter sort and routes it accordingly. If the enter is a URL, the helper features get_video_info and get_video_id extract video metadata (title, description, length) with out downloading it utilizing yt_dlp package deal.
#Operate to find out the enter sort and route it appropriately
def process_video(youtube_url, output_dir, api_key, mannequin="gpt-4o-transcribe"):
"""
Course of a YouTube video to generate a transcript
Wrapper perform that mixes obtain and transcription
Args:
youtube_url: URL of the YouTube video
output_dir: Listing to save lots of the output
api_key: OpenAI API key
mannequin: The mannequin to make use of for transcription (default: gpt-4o-transcribe)
Returns:
dict: Dictionary containing transcript and file paths
"""
# First obtain the audio
print("Downloading video...")
audio_path = process_video_download(youtube_url, output_dir)
print("Transcribing video...")
# Then transcribe the audio
transcript, transcript_path = process_video_transcribe(audio_path, output_dir, api_key, mannequin=mannequin)
# Return the mixed outcomes
return {
'transcript': transcript,
'transcript_path': transcript_path,
'audio_path': audio_path
}
def get_video_info(youtube_url):
"""Get video data with out downloading."""
# Verify native cache first
world _video_info_cache
if youtube_url in _video_info_cache:
return _video_info_cache[youtube_url]
# Extract data if not cached
with yt_dlp.YoutubeDL() as ydl:
data = ydl.extract_info(youtube_url, obtain=False)
# Cache the consequence
_video_info_cache[youtube_url] = data
# Additionally cache the video ID individually
_video_id_cache[youtube_url] = data.get('id', 'video')
return data
def get_video_id(youtube_url):
"""Get simply the video ID with out re-extracting if already identified."""
world _video_id_cache
if youtube_url in _video_id_cache:
return _video_id_cache[youtube_url]
# If not in cache, extract from URL straight if doable
if "v=" in youtube_url:
video_id = youtube_url.break up("v=")[1].break up("&")[0]
_video_id_cache[youtube_url] = video_id
return video_id
elif "youtu.be/" in youtube_url:
video_id = youtube_url.break up("youtu.be/")[1].break up("?")[0]
_video_id_cache[youtube_url] = video_id
return video_id
# If we won't extract straight, fall again to full data extraction
data = get_video_info(youtube_url)
video_id = data.get('id', 'video')
return video_id
After the video enter is given, the code in app.py checks whether or not a transcript for the enter video already exists (within the case of URL enter). That is achieved by calling the next two helper features from transcriber.py.
def get_transcript_path(youtube_url, output_dir):
"""Get the anticipated transcript path for a given YouTube URL."""
# Get video ID with caching
video_id = get_video_id(youtube_url)
# Return anticipated transcript path
return os.path.be a part of(output_dir, f"{video_id}_transcript.txt")
def transcript_exists(youtube_url, output_dir):
"""Verify if a transcript already exists for this video."""
transcript_path = get_transcript_path(youtube_url, output_dir)
return os.path.exists(transcript_path)If transcript_exists returns the trail of an present transcript, the subsequent step is to create the vector retailer for the RAG. If no present transcript is discovered, the subsequent step is to obtain audio from the URL and convert it to a normal audio format. The perform process_video_download downloads audio from the URL utilizing the FFMPEG library and converts it to .mp3 format. If the enter is an area video file, app.py proceeds to transform it to .mp3 file.
def process_video_download(youtube_url, output_dir):
"""
Obtain audio from a YouTube video
Args:
youtube_url: URL of the YouTube video
output_dir: Listing to save lots of the output
Returns:
str: Path to the downloaded audio file
"""
# Create output listing if it would not exist
os.makedirs(output_dir, exist_ok=True)
# Extract video ID from URL
video_id = None
if "v=" in youtube_url:
video_id = youtube_url.break up("v=")[1].break up("&")[0]
elif "youtu.be/" in youtube_url:
video_id = youtube_url.break up("youtu.be/")[1].break up("?")[0]
else:
increase ValueError("Couldn't extract video ID from URL")
# Set output paths
audio_path = os.path.be a part of(output_dir, f"{video_id}.mp3")
# Configure yt-dlp choices
ydl_opts = {
'format': 'bestaudio/greatest',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'mp3',
'preferredquality': '192',
}],
'outtmpl': os.path.be a part of(output_dir, f"{video_id}"),
'quiet': True
}
# Obtain audio
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.obtain([youtube_url])
# Confirm audio file exists
if not os.path.exists(audio_path):
# Attempt with an extension that yt-dlp may need used
potential_paths = [
os.path.join(output_dir, f"{video_id}.mp3"),
os.path.join(output_dir, f"{video_id}.m4a"),
os.path.join(output_dir, f"{video_id}.webm")
]
for path in potential_paths:
if os.path.exists(path):
# Convert to mp3 if it isn't already
if not path.endswith('.mp3'):
ffmpeg_path = verify_ffmpeg()[0]
output_mp3 = os.path.be a part of(output_dir, f"{video_id}.mp3")
subprocess.run([
ffmpeg_path, '-i', path, '-c:a', 'libmp3lame',
'-q:a', '2', output_mp3, '-y'
], examine=True, capture_output=True)
os.take away(path) # Take away the unique file
audio_path = output_mp3
else:
audio_path = path
break
else:
increase FileNotFoundError(f"Couldn't discover downloaded audio file for video {video_id}")
return audio_pathAudio Transcription Utilizing OpenAI’s gpt-4o-transcribe Mannequin
After extracting audio and changing it to a normal audio format, the subsequent step is to transcribe the audio to textual content format. For this function, I used OpenAI’s newly launched gpt-4o-transcribe speech-to-text mannequin accessible by way of speech-to-text API. This mannequin has outperformed OpenAI’s Whisper fashions when it comes to each transcription accuracy and strong language protection.
The perform process_video_transcribe in transcriber.py receives the transformed audio file and interfaces with gpt-4o-transcribe mannequin with OpenAI’s speech-to-text API. The gpt-4o-transcribe mannequin at present has an audio file restrict of 25MB and 1500 length. To beat this limitation, I break up the longer recordsdata into a number of chunks and transcribe these chunks individually. The process_video_transcribe perform checks whether or not the enter file exceeds the dimensions and/or length restrict. If both threshold is exceeded, it calls split_and_transcribe perform, which first calculates the variety of chunks wanted primarily based on each measurement and length and takes the utmost of those two as the ultimate variety of chunks for transcription. It then finds the beginning and finish occasions for every chunk and extracts these chunks from the audio file. Subsequently, it transcribes every chunk utilizing gpt-4o-transcribe mannequin with OpenAI’s speech-to-text API after which combines transcripts of all chunks to generate the ultimate transcript.
def process_video_transcribe(audio_path, output_dir, api_key, progress_callback=None, mannequin="gpt-4o-transcribe"):
"""
Transcribe an audio file utilizing OpenAI API, with automated chunking for big recordsdata
At all times makes use of the chosen mannequin, with no fallback
Args:
audio_path: Path to the audio file
output_dir: Listing to save lots of the transcript
api_key: OpenAI API key
progress_callback: Operate to name with progress updates (0-100)
mannequin: The mannequin to make use of for transcription (default: gpt-4o-transcribe)
Returns:
tuple: (transcript textual content, transcript path)
"""
# Extract video ID from audio path
video_id = os.path.basename(audio_path).break up('.')[0]
transcript_path = os.path.be a part of(output_dir, f"{video_id}_transcript.txt")
# Setup OpenAI shopper
shopper = OpenAI(api_key=api_key)
# Replace progress
if progress_callback:
progress_callback(10)
# Get file measurement in MB
file_size_mb = os.path.getsize(audio_path) / (1024 * 1024)
# Common chunking thresholds - apply to each fashions
max_size_mb = 25 # 25MB chunk measurement for each fashions
max_duration_seconds = 1500 # 1500 seconds chunk length for each fashions
# Load the audio file to get its length
strive:
audio = AudioSegment.from_file(audio_path)
duration_seconds = len(audio) / 1000 # pydub makes use of milliseconds
besides Exception as e:
print(f"Error loading audio to examine length: {e}")
audio = None
duration_seconds = 0
# Decide if chunking is required
needs_chunking = False
chunking_reason = []
if file_size_mb > max_size_mb:
needs_chunking = True
chunking_reason.append(f"measurement ({file_size_mb:.2f}MB exceeds {max_size_mb}MB)")
if duration_seconds > max_duration_seconds:
needs_chunking = True
chunking_reason.append(f"length ({duration_seconds:.2f}s exceeds {max_duration_seconds}s)")
# Log the choice
if needs_chunking:
reason_str = " and ".be a part of(chunking_reason)
print(f"Audio wants chunking as a consequence of {reason_str}. Utilizing {mannequin} for transcription.")
else:
print(f"Audio file is inside limits. Utilizing {mannequin} for direct transcription.")
# Verify if file wants chunking
if needs_chunking:
if progress_callback:
progress_callback(15)
# Break up the audio file into chunks and transcribe every chunk utilizing the chosen mannequin solely
full_transcript = split_and_transcribe(
audio_path, shopper, mannequin, progress_callback,
max_size_mb, max_duration_seconds, audio
)
else:
# File is sufficiently small, transcribe straight with the chosen mannequin
with open(audio_path, "rb") as audio_file:
if progress_callback:
progress_callback(30)
transcript_response = shopper.audio.transcriptions.create(
mannequin=mannequin,
file=audio_file
)
if progress_callback:
progress_callback(80)
full_transcript = transcript_response.textual content
# Save transcript to file
with open(transcript_path, "w", encoding="utf-8") as f:
f.write(full_transcript)
# Replace progress
if progress_callback:
progress_callback(100)
return full_transcript, transcript_path
def split_and_transcribe(audio_path, shopper, mannequin, progress_callback=None,
max_size_mb=25, max_duration_seconds=1500, audio=None):
"""
Break up an audio file into chunks and transcribe every chunk
Args:
audio_path: Path to the audio file
shopper: OpenAI shopper
mannequin: Mannequin to make use of for transcription (is not going to fall again to different fashions)
progress_callback: Operate to name with progress updates
max_size_mb: Most file measurement in MB
max_duration_seconds: Most length in seconds
audio: Pre-loaded AudioSegment (non-compulsory)
Returns:
str: Mixed transcript from all chunks
"""
# Load the audio file if not offered
if audio is None:
audio = AudioSegment.from_file(audio_path)
# Get audio length in seconds
duration_seconds = len(audio) / 1000
# Calculate the variety of chunks wanted primarily based on each measurement and length
file_size_mb = os.path.getsize(audio_path) / (1024 * 1024)
chunks_by_size = math.ceil(file_size_mb / (max_size_mb * 0.9)) # Use 90% of max to be secure
chunks_by_duration = math.ceil(duration_seconds / (max_duration_seconds * 0.95)) # Use 95% of max to be secure
num_chunks = max(chunks_by_size, chunks_by_duration)
print(f"Splitting audio into {num_chunks} chunks primarily based on measurement ({chunks_by_size}) and length ({chunks_by_duration})")
# Calculate chunk length in milliseconds
chunk_length_ms = len(audio) // num_chunks
# Create temp listing for chunks if it would not exist
temp_dir = os.path.be a part of(os.path.dirname(audio_path), "temp_chunks")
os.makedirs(temp_dir, exist_ok=True)
# Break up the audio into chunks and transcribe every chunk
transcripts = []
for i in vary(num_chunks):
if progress_callback:
# Replace progress: 20% for splitting, 60% for transcribing
progress_percent = 20 + int((i / num_chunks) * 60)
progress_callback(progress_percent)
# Calculate begin and finish occasions for this chunk
start_ms = i * chunk_length_ms
end_ms = min((i + 1) * chunk_length_ms, len(audio))
# Extract the chunk
chunk = audio[start_ms:end_ms]
# Save the chunk to a brief file
chunk_path = os.path.be a part of(temp_dir, f"chunk_{i}.mp3")
chunk.export(chunk_path, format="mp3")
# Log chunk data
chunk_size_mb = os.path.getsize(chunk_path) / (1024 * 1024)
chunk_duration = len(chunk) / 1000
print(f"Chunk {i+1}/{num_chunks}: {chunk_size_mb:.2f}MB, {chunk_duration:.2f}s")
# Transcribe the chunk
strive:
with open(chunk_path, "rb") as chunk_file:
transcript_response = shopper.audio.transcriptions.create(
mannequin=mannequin,
file=chunk_file
)
# Add to our record of transcripts
transcripts.append(transcript_response.textual content)
besides Exception as e:
print(f"Error transcribing chunk {i+1} with {mannequin}: {e}")
# Add a placeholder for the failed chunk
transcripts.append(f"[Transcription failed for segment {i+1}]")
# Clear up the momentary chunk file
os.take away(chunk_path)
# Clear up the momentary listing
strive:
os.rmdir(temp_dir)
besides:
print(f"Notice: Couldn't take away momentary listing {temp_dir}")
# Mix all transcripts with correct spacing
full_transcript = " ".be a part of(transcripts)
return full_transcriptThe next screenshot of the Streamlit app exhibits the video processing and transcribing workflow for one in all my webinars, “Integrating LLMs into Enterprise,” obtainable on my YouTube channel.

Retrieval Augmented Era (RAG) for Interactive Conversations
After producing the video transcript, the applying develops a RAG to facilitate each textual content and speech-based interactions. The conversational intelligence is applied by way of VideoRAG class in rag_system.py which initializes chunk measurement and overlap, OpenAI embeddings, ChatOpenAI occasion to generate responses with gpt-4o mannequin, and ConversationBufferMemory to take care of chat historical past for contextual continuity.
The create_vector_store technique splits the paperwork into chunks and creates a vector retailer utilizing the FAISS vector database. The handle_question_submission technique processes textual content questions and appends every new query and its reply to the dialog historical past. The handle_speech_input perform implements the entire voice-to-text-to-voice pipeline. It first information the query audio, transcribes the query, processes the question by way of the RAG system, and synthesizes speech for the response.
class VideoRAG:
def __init__(self, api_key=None, chunk_size=1000, chunk_overlap=200):
"""Initialize the RAG system with OpenAI API key."""
# Use offered API key or attempt to get from surroundings
self.api_key = api_key if api_key else st.secrets and techniques["OPENAI_API_KEY"]
if not self.api_key:
increase ValueError("OpenAI API secret's required both as parameter or surroundings variable")
self.embeddings = OpenAIEmbeddings(openai_api_key=self.api_key)
self.llm = ChatOpenAI(
openai_api_key=self.api_key,
mannequin="gpt-4o",
temperature=0
)
self.chunk_size = chunk_size
self.chunk_overlap = chunk_overlap
self.vector_store = None
self.chain = None
self.reminiscence = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
def create_vector_store(self, transcript):
"""Create a vector retailer from the transcript."""
# Break up the textual content into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=self.chunk_size,
chunk_overlap=self.chunk_overlap,
separators=["nn", "n", " ", ""]
)
chunks = text_splitter.split_text(transcript)
# Create vector retailer
self.vector_store = FAISS.from_texts(chunks, self.embeddings)
# Create immediate template for the RAG system
system_template = """You're a specialised AI assistant that solutions questions on a selected video.
You might have entry to snippets from the video transcript, and your function is to supply correct data ONLY primarily based on these snippets.
Tips:
1. Solely reply questions primarily based on the data offered within the context from the video transcript, in any other case say that "I do not know. The video would not cowl that data."
2. The query might ask you to summarize the video or inform what the video is about. In that case, current a abstract of the context.
3. Do not make up data or use information from outdoors the offered context
4. Maintain your solutions concise and straight associated to the query
5. If requested about your capabilities or identification, clarify that you just're an AI assistant that makes a speciality of answering questions on this particular video
Context from the video transcript:
{context}
Chat Historical past:
{chat_history}
"""
user_template = "{query}"
# Create the messages for the chat immediate
messages = [
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template(user_template)
]
# Create the chat immediate
qa_prompt = ChatPromptTemplate.from_messages(messages)
# Initialize the RAG chain with the customized immediate
self.chain = ConversationalRetrievalChain.from_llm(
llm=self.llm,
retriever=self.vector_store.as_retriever(
search_kwargs={"ok": 5}
),
reminiscence=self.reminiscence,
combine_docs_chain_kwargs={"immediate": qa_prompt},
verbose=True
)
return len(chunks)
def set_chat_history(self, chat_history):
"""Set chat historical past from exterior session state."""
if not self.reminiscence:
return
# Clear present reminiscence
self.reminiscence.clear()
# Convert customary chat historical past format to LangChain message format
for message in chat_history:
if message["role"] == "consumer":
self.reminiscence.chat_memory.add_user_message(message["content"])
elif message["role"] == "assistant":
self.reminiscence.chat_memory.add_ai_message(message["content"])
def ask(self, query, chat_history=None):
"""Ask a query to the RAG system."""
if not self.chain:
increase ValueError("Vector retailer not initialized. Name create_vector_store first.")
# If chat historical past is offered, replace the reminiscence
if chat_history:
self.set_chat_history(chat_history)
# Get response
response = self.chain.invoke({"query": query})
return response["answer"]See the next snapshot of the Streamlit app, exhibiting the interactive dialog interface with the video.

The next snapshot exhibits a dialog with the video with speech enter and textual content+speech output.

Characteristic Era
The applying generates three options: hierarchical abstract, quiz, and flashcards. Please seek advice from their respective commented codes within the GitHub repo.
The SummaryGenerator class in abstract.py supplies structured content material summarization by making a hierarchical illustration of the video content material to supply customers with fast insights into the principle ideas and supporting particulars. The system retrieves key contextual segments from the transcript utilizing RAG. Utilizing a immediate (see generate_summary), it creates a hierarchical abstract with three ranges: details, sub-points, and extra particulars. The create_summary_popup_html technique transforms the generated abstract into an interactive visible illustration utilizing CSS and JavaScript.
# abstract.py
class SummaryGenerator:
def __init__(self):
go
def generate_summary(self, rag_system, api_key, mannequin="gpt-4o", temperature=0.2):
"""
Generate a hierarchical bullet-point abstract from the video transcript
Args:
rag_system: The RAG system with vector retailer
api_key: OpenAI API key
mannequin: Mannequin to make use of for abstract era
temperature: Creativity stage (0.0-1.0)
Returns:
str: Hierarchical bullet-point abstract textual content
"""
if not rag_system:
st.error("Please transcribe the video first earlier than making a abstract!")
return ""
with st.spinner("Producing hierarchical abstract..."):
# Create LLM for abstract era
summary_llm = ChatOpenAI(
openai_api_key=api_key,
mannequin=mannequin,
temperature=temperature # Decrease temperature for extra factual summaries
)
# Use the RAG system to get related context
strive:
# Get broader context since we're summarizing the entire video
relevant_docs = rag_system.vector_store.similarity_search(
"summarize the details of this video", ok=10
)
context = "nn".be a part of([doc.page_content for doc in relevant_docs])
immediate = """Based mostly on the video transcript, create a hierarchical bullet-point abstract of the content material.
Construction your abstract with precisely these ranges:
• Details (use • or * at the beginning of the road for these top-level factors)
- Sub-points (use - at the beginning of the road for these second-level particulars)
* Further particulars (use areas adopted by * for third-level factors)
For instance:
• First primary level
- Necessary element concerning the first level
- One other vital element
* A selected instance
* One other particular instance
• Second primary level
- Element about second level
Be per the precise formatting proven above. Every bullet stage should begin with the precise character proven (• or *, -, and areas+*).
Create 3-5 details with 2-4 sub-points every, and add third-level particulars the place applicable.
Give attention to a very powerful data from the video.
"""
# Use the LLM with context to generate the abstract
messages = [
{"role": "system", "content": f"You are given the following context from a video transcript:nn{context}nnUse this context to create a hierarchical summary according to the instructions."},
{"role": "user", "content": prompt}
]
response = summary_llm.invoke(messages)
return response.content material
besides Exception as e:
# Fallback to the common RAG system if there's an error
st.warning(f"Utilizing customary abstract era as a consequence of error: {str(e)}")
return rag_system.ask(immediate)
def create_summary_popup_html(self, summary_content):
"""
Create HTML for the abstract popup with correctly formatted hierarchical bullets
Args:
summary_content: Uncooked abstract textual content with markdown bullet formatting
Returns:
str: HTML for the popup with correctly formatted bullets
"""
# As an alternative of counting on markdown conversion, let's manually parse and format the bullet factors
traces = summary_content.strip().break up('n')
formatted_html = []
in_list = False
list_level = 0
for line in traces:
line = line.strip()
# Skip empty traces
if not line:
proceed
# Detect if this can be a markdown header
if line.startswith('# '):
if in_list:
# Shut any open lists
for _ in vary(list_level):
formatted_html.append('')
in_list = False
list_level = 0
formatted_html.append(f'')
proceed
# Verify line for bullet level markers
if line.startswith('• ') or line.startswith('* '):
# High stage bullet
content material = line[2:].strip()
if not in_list:
# Begin a brand new record
formatted_html.append('')
in_list = True
list_level = 1
elif list_level > 1:
# Shut nested lists to get again to high stage
for _ in vary(list_level - 1):
formatted_html.append('
')
list_level = 1
else:
# Shut earlier record merchandise if wanted
if formatted_html and never formatted_html[-1].endswith('') and in_list:
formatted_html.append('')
formatted_html.append(f'{content material}')
elif line.startswith('- '):
# Second stage bullet
content material = line[2:].strip()
if not in_list:
# Begin new lists
formatted_html.append('- Second stage gadgets')
formatted_html.append('
')
in_list = True
list_level = 2
elif list_level == 1:
# Add a nested record
formatted_html.append('')
list_level = 2
elif list_level > 2:
# Shut deeper nested lists to get to second stage
for _ in vary(list_level - 2):
formatted_html.append('
')
list_level = 2
else:
# Shut earlier record merchandise if wanted
if formatted_html and never formatted_html[-1].endswith('
') and list_level == 2:
formatted_html.append('')
formatted_html.append(f'{content material}')
elif line.startswith(' * ') or line.startswith(' * '):
# Third stage bullet
content material = line.strip()[2:].strip()
if not in_list:
# Begin new lists (all ranges)
formatted_html.append('- High stage')
formatted_html.append('
- Second stage')
formatted_html.append('
')
in_list = True
list_level = 3
elif list_level == 2:
# Add a nested record
formatted_html.append('')
list_level = 3
elif list_level < 3:
# We missed a stage, regulate
formatted_html.append('- Lacking stage
')
formatted_html.append('')
list_level = 3
else:
# Shut earlier record merchandise if wanted
if formatted_html and never formatted_html[-1].endswith('
') and list_level == 3:
formatted_html.append('
')
formatted_html.append(f'- {content material}')
else:
# Common paragraph
if in_list:
# Shut any open lists
for _ in vary(list_level):
formatted_html.append('
')
if list_level > 1:
formatted_html.append(' ')
in_list = False
list_level = 0
formatted_html.append(f'{line}
')
# Shut any open lists
if in_list:
# Shut remaining merchandise
formatted_html.append('')
# Shut any open lists
for _ in vary(list_level):
if list_level > 1:
formatted_html.append('')
else:
formatted_html.append('')
summary_html = 'n'.be a part of(formatted_html)
html = f"""
"""
return html
Discuss-to-Movies app generates quizzes from the video by way of the QuizGenerator class in quiz.py. The quiz generator creates multiple-choice questions focusing on particular details and ideas offered within the video. Not like RAG, the place I take advantage of a zero temperature, I elevated the LLM temperature to 0.4 to encourage some creativity in quiz era. A structured immediate guides the quiz era course of. The parse_quiz_response technique extracts and validates the generated quiz components to ensure that every query has all of the required parts. To stop the customers from recognizing the sample and to advertise actual understanding, the quiz generator shuffles the reply choices. Questions are offered one by one, adopted by fast suggestions on every reply. After finishing all questions, the calculate_quiz_results technique assesses consumer solutions and the consumer is offered with an general rating, a visible breakdown of appropriate versus incorrect solutions, and suggestions on the efficiency stage. On this manner, the quiz era performance transforms passive video watching into energetic studying by difficult customers to recall and apply data offered within the video.
# quiz.py
class QuizGenerator:
def __init__(self):
go
def generate_quiz(self, rag_system, api_key, transcript=None, mannequin="gpt-4o", temperature=0.4):
"""
Generate quiz questions primarily based on the video transcript
Args:
rag_system: The RAG system with vector store2
api_key: OpenAI API key
transcript: The total transcript textual content (non-compulsory)
mannequin: Mannequin to make use of for query era
temperature: Creativity stage (0.0-1.0)
Returns:
record: Record of query objects
"""
if not rag_system:
st.error("Please transcribe the video first earlier than making a quiz!")
return []
# Create a brief LLM with barely increased temperature for extra inventive questions
creative_llm = ChatOpenAI(
openai_api_key=api_key,
mannequin=mannequin,
temperature=temperature
)
num_questions = 10
# Immediate to generate quiz
immediate = f"""Based mostly on the video transcript, generate {num_questions} multiple-choice questions to check understanding of the content material.
For every query:
1. The query ought to be particular to data talked about within the video
2. Embrace 4 choices (A, B, C, D)
3. Clearly point out the proper reply
Format your response precisely as follows for every query:
QUESTION: [question text]
A: [option A]
B: [option B]
C: [option C]
D: [option D]
CORRECT: [letter of correct answer]
Make sure that all questions are primarily based on details from the video."""
strive:
if transcript:
# If we've the total transcript, use it
messages = [
{"role": "system", "content": f"You are given the following transcript from a video:nn{transcript}nnUse this transcript to create quiz questions according to the instructions."},
{"role": "user", "content": prompt}
]
response = creative_llm.invoke(messages)
response_text = response.content material
else:
# Fallback to RAG method if no transcript is offered
relevant_docs = rag_system.vector_store.similarity_search(
"what are the principle matters lined on this video?", ok=5
)
context = "nn".be a part of([doc.page_content for doc in relevant_docs])
# Use the inventive LLM with context to generate questions
messages = [
{"role": "system", "content": f"You are given the following context from a video transcript:nn{context}nnUse this context to create quiz questions according to the instructions."},
{"role": "user", "content": prompt}
]
response = creative_llm.invoke(messages)
response_text = response.content material
besides Exception as e:
# Fallback to the common RAG system if there's an error
st.warning(f"Utilizing customary query era as a consequence of error: {str(e)}")
response_text = rag_system.ask(immediate)
return self.parse_quiz_response(response_text)
# The remainder of the category stays unchanged
def parse_quiz_response(self, response_text):
"""
Parse the LLM response to extract questions, choices, and proper solutions
Args:
response_text: Uncooked textual content response from LLM
Returns:
record: Record of parsed query objects
"""
quiz_questions = []
current_question = {}
for line in response_text.strip().break up('n'):
line = line.strip()
if line.startswith('QUESTION:'):
if current_question and 'query' in current_question and 'choices' in current_question and 'appropriate' in current_question:
quiz_questions.append(current_question)
current_question = {
'query': line[len('QUESTION:'):].strip(),
'choices': [],
'appropriate': None
}
elif line.startswith(('A:', 'B:', 'C:', 'D:')):
option_letter = line[0]
option_text = line[2:].strip()
current_question.setdefault('choices', []).append((option_letter, option_text))
elif line.startswith('CORRECT:'):
current_question['correct'] = line[len('CORRECT:'):].strip()
# Add the final query
if current_question and 'query' in current_question and 'choices' in current_question and 'appropriate' in current_question:
quiz_questions.append(current_question)
# Randomize choices for every query
randomized_questions = []
for q in quiz_questions:
# Get the unique appropriate reply
correct_letter = q['correct']
correct_option = None
# Discover the proper choice textual content
for letter, textual content in q['options']:
if letter == correct_letter:
correct_option = textual content
break
if correct_option is None:
# If we won't discover the proper reply, maintain the query as is
randomized_questions.append(q)
proceed
# Create an inventory of choices texts and shuffle them
option_texts = [text for _, text in q['options']]
# Create a duplicate of the unique letters
option_letters = [letter for letter, _ in q['options']]
# Create an inventory of (letter, textual content) pairs
options_pairs = record(zip(option_letters, option_texts))
# Shuffle the pairs
random.shuffle(options_pairs)
# Discover the brand new place of the proper reply
new_correct_letter = None
for letter, textual content in options_pairs:
if textual content == correct_option:
new_correct_letter = letter
break
# Create a brand new query with randomized choices
new_q = {
'query': q['question'],
'choices': options_pairs,
'appropriate': new_correct_letter
}
randomized_questions.append(new_q)
return randomized_questions
def calculate_quiz_results(self, questions, user_answers):
"""
Calculate quiz outcomes primarily based on consumer solutions
Args:
questions: Record of query objects
user_answers: Dictionary of consumer solutions keyed by question_key
Returns:
tuple: (outcomes dict, appropriate rely)
"""
correct_count = 0
outcomes = {}
for i, query in enumerate(questions):
question_key = f"quiz_q_{i}"
user_answer = user_answers.get(question_key)
correct_answer = query['correct']
# Solely rely as appropriate if consumer chosen a solution and it matches
is_correct = user_answer is just not None and user_answer == correct_answer
if is_correct:
correct_count += 1
outcomes[question_key] = {
'user_answer': user_answer,
'correct_answer': correct_answer,
'is_correct': is_correct
}
return outcomes, correct_count
Discuss-to-Movies additionally generates flashcards from the video content material, which help energetic recall and spaced repetition studying strategies. That is achieved by way of the FlashcardGenerator class in flashcards.py, which creates a mixture of completely different flashcards specializing in key time period definitions, conceptual questions, fill-in-the-blank statements, and true/False questions with explanations. A immediate guides the LLM to output flashcards in a structured JSON format, with every card containing distinct “entrance” and “again” components. The shuffle_flashcards produces a randomized presentation, and every flashcard is validated to make sure that it accommodates each back and front parts earlier than being offered to the consumer. The reply to every flashcard is initially hidden. It’s revealed on the consumer’s enter utilizing a basic flashcard reveal performance. Customers can generate a brand new set of flashcards for extra observe. The flashcard and quiz techniques are interconnected with one another in order that customers can swap between them as wanted.
# flashcards.py
class FlashcardGenerator:
"""Class to generate flashcards from video content material utilizing the RAG system."""
def __init__(self):
"""Initialize the flashcard generator."""
go
def generate_flashcards(self, rag_system, api_key, transcript=None, num_cards=10, mannequin="gpt-4o") -> Record[Dict[str, str]]:
"""
Generate flashcards primarily based on the video content material.
Args:
rag_system: The initialized RAG system with video content material
api_key: OpenAI API key
transcript: The total transcript textual content (non-compulsory)
num_cards: Variety of flashcards to generate (default: 10)
mannequin: The OpenAI mannequin to make use of
Returns:
Record of flashcard dictionaries with 'entrance' and 'again' keys
"""
# Import right here to keep away from round imports
from langchain_openai import ChatOpenAI
# Initialize language mannequin
llm = ChatOpenAI(
openai_api_key=api_key,
mannequin=mannequin,
temperature=0.4
)
# Create the immediate for flashcard era
immediate = f"""
Create {num_cards} instructional flashcards primarily based on the video content material.
Every flashcard ought to have:
1. A entrance aspect with a query, time period, or idea
2. A again aspect with the reply, definition, or clarification
Give attention to a very powerful and academic content material from the video.
Create a mixture of various kinds of flashcards:
- Key time period definitions
- Conceptual questions
- Fill-in-the-blank statements
- True/False questions with explanations
Format your response as a JSON array of objects with 'entrance' and 'again' properties.
Instance:
[
{{"front": "What is photosynthesis?", "back": "The process by which plants convert light energy into chemical energy."}},
{{"front": "The three branches of government are: Executive, Legislative, and _____", "back": "Judicial"}}
]
Make sure that your output is legitimate JSON format with precisely {num_cards} flashcards.
"""
strive:
# Decide the context to make use of
if transcript:
# Use the total transcript if offered
# Create messages for the language mannequin
messages = [
{"role": "system", "content": f"You are an educational content creator specializing in creating effective flashcards. Use the following transcript from a video to create educational flashcards:nn{transcript}"},
{"role": "user", "content": prompt}
]
else:
# Fallback to RAG system if no transcript is offered
relevant_docs = rag_system.vector_store.similarity_search(
"key factors and academic ideas within the video", ok=15
)
context = "nn".be a part of([doc.page_content for doc in relevant_docs])
# Create messages for the language mannequin
messages = [
{"role": "system", "content": f"You are an educational content creator specializing in creating effective flashcards. Use the following context from a video to create educational flashcards:nn{context}"},
{"role": "user", "content": prompt}
]
# Generate flashcards
response = llm.invoke(messages)
content material = response.content material
# Extract JSON content material in case there's textual content round it
json_start = content material.discover('[')
json_end = content.rfind(']') + 1
if json_start >= 0 and json_end > json_start:
json_content = content material[json_start:json_end]
flashcards = json.hundreds(json_content)
else:
# Fallback in case of improper JSON formatting
increase ValueError("Did not extract legitimate JSON from response")
# Confirm we've the anticipated variety of playing cards (or regulate as wanted)
actual_cards = min(len(flashcards), num_cards)
flashcards = flashcards[:actual_cards]
# Validate every flashcard has required fields
validated_cards = []
for card in flashcards:
if 'entrance' in card and 'again' in card:
validated_cards.append({
'entrance': card['front'],
'again': card['back']
})
return validated_cards
besides Exception as e:
# Deal with errors gracefully
print(f"Error producing flashcards: {str(e)}")
# Return a couple of primary flashcards in case of error
return [
{"front": "Error generating flashcards", "back": f"Please try again. Error: {str(e)}"},
{"front": "Tip", "back": "Try regenerating flashcards or using a different video"}
]
def shuffle_flashcards(self, flashcards: Record[Dict[str, str]]) -> Record[Dict[str, str]]:
"""Shuffle the order of flashcards"""
shuffled = flashcards.copy()
random.shuffle(shuffled)
return shuffled
Potential Extensions and Enhancements
This software will be prolonged and improved in various methods. For example:
- Integration of visible options in video (corresponding to keyframes) could also be explored with audio to extract extra significant data.
- Staff-based studying experiences will be enabled the place workplace colleagues or classmates can share notes, quiz scores, and summaries.
- Creating navigable transcripts that enable customers to click on on particular sections to leap to that time within the video
- Creating step-by-step motion plans for implementing ideas from the video in actual enterprise settings
- Modifying the RAG immediate to elaborate on the solutions and supply less complicated explanations to troublesome ideas.
- Producing questions that stimulate metacognitive abilities in learners by stimulating them to consider their pondering course of and studying methods whereas participating with video content material.
That’s all people! If you happen to favored the article, please observe me on Medium and LinkedIn.
















{kind=link}