



A language mannequin is a mathematical mannequin that describes a human language as a likelihood distribution over its vocabulary. To coach a deep studying community to mannequin a language, you have to determine the vocabulary and be taught its likelihood distribution. You possibly can’t create the mannequin from nothing. You want a dataset in your mannequin to be taught from.
On this article, you’ll study datasets used to coach language fashions and find out how to supply frequent datasets from public repositories.
Let’s get began.

Datasets for Coaching a Language Mannequin
Picture by Dan V. Some rights reserved.
A Good Dataset for Coaching a Language Mannequin
A great language mannequin ought to be taught right language utilization, freed from biases and errors. In contrast to programming languages, human languages lack formal grammar and syntax. They evolve repeatedly, making it not possible to catalog all language variations. Due to this fact, the mannequin must be skilled from a dataset as a substitute of crafted from guidelines.
Organising a dataset for language modeling is difficult. You want a big, various dataset that represents the language’s nuances. On the similar time, it have to be prime quality, presenting right language utilization. Ideally, the dataset must be manually edited and cleaned to take away noise like typos, grammatical errors, and non-language content material similar to symbols or HTML tags.
Creating such a dataset from scratch is dear, however a number of high-quality datasets are freely accessible. Widespread datasets embody:
- Widespread Crawl. A large, repeatedly up to date dataset of over 9.5 petabytes with various content material. It’s utilized by main fashions together with GPT-3, Llama, and T5. Nonetheless, because it’s sourced from the online, it accommodates low-quality and duplicate content material, together with biases and offensive materials. Rigorous cleansing and filtering are required to make it helpful.
- C4 (Colossal Clear Crawled Corpus). A 750GB dataset scraped from the online. In contrast to Widespread Crawl, this dataset is pre-cleaned and filtered, making it simpler to make use of. Nonetheless, count on potential biases and errors. The T5 mannequin was skilled on this dataset.
- Wikipedia. English content material alone is round 19GB. It’s large but manageable. It’s well-curated, structured, and edited to Wikipedia requirements. Whereas it covers a broad vary of common data with excessive factual accuracy, its encyclopedic type and tone are very particular. Coaching on this dataset alone might trigger fashions to overfit to this type.
- WikiText. A dataset derived from verified good and featured Wikipedia articles. Two variations exist: WikiText-2 (2 million phrases from tons of of articles) and WikiText-103 (100 million phrases from 28,000 articles).
- BookCorpus. A couple of-GB dataset of long-form, content-rich, high-quality ebook texts. Helpful for studying coherent storytelling and long-range dependencies. Nonetheless, it has recognized copyright points and social biases.
- The Pile. An 825GB curated dataset from a number of sources, together with BookCorpus. It mixes completely different textual content genres (books, articles, supply code, and tutorial papers), offering broad topical protection designed for multidisciplinary reasoning. Nonetheless, this range leads to variable high quality, duplicate content material, and inconsistent writing kinds.
Getting the Datasets
You possibly can seek for these datasets on-line and obtain them as compressed information. Nonetheless, you’ll want to grasp every dataset’s format and write customized code to learn them.
Alternatively, seek for datasets within the Hugging Face repository at https://huggingface.co/datasets. This repository supplies a Python library that allows you to obtain and browse datasets in actual time utilizing a standardized format.
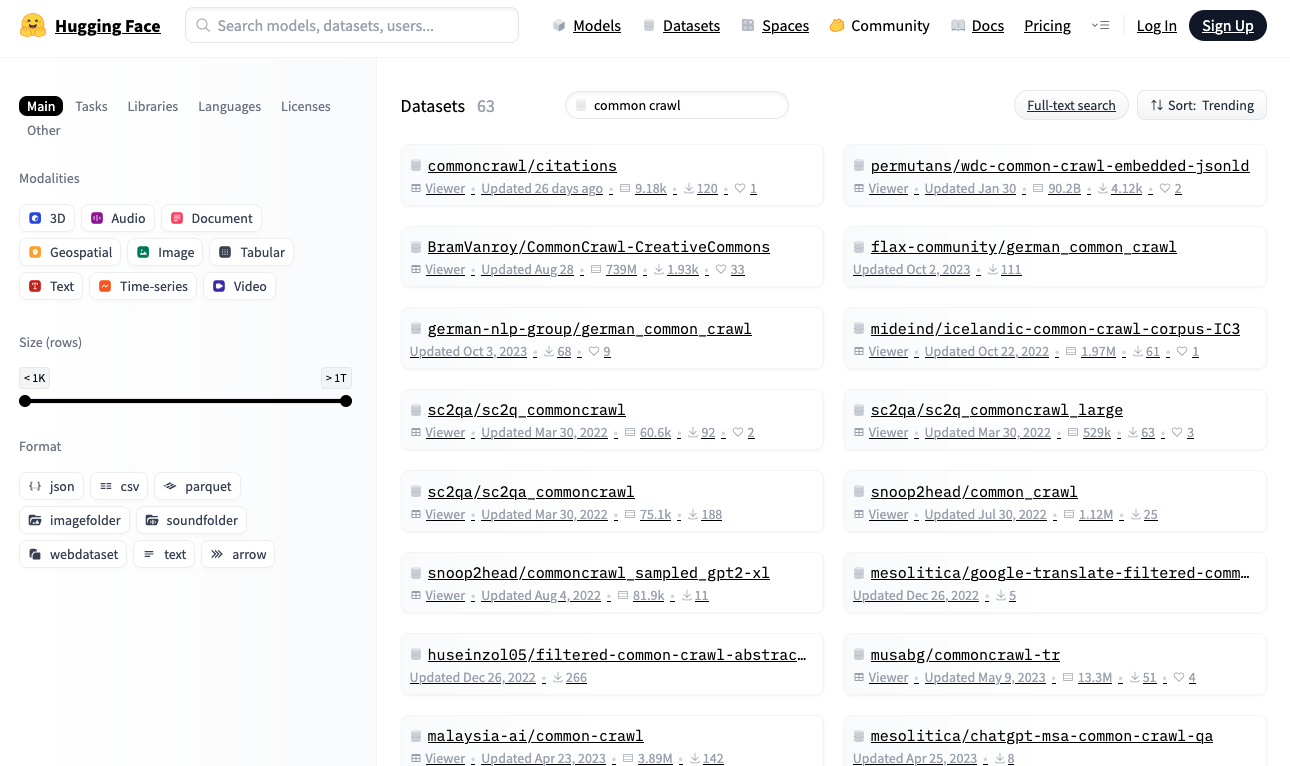
Hugging Face Datasets Repository
Let’s obtain the WikiText-2 dataset from Hugging Face, one of many smallest datasets appropriate for constructing a language mannequin:
|
import random from datasets import load_dataset
dataset = load_dataset(“wikitext”, “wikitext-2-raw-v1”) print(f“Measurement of the dataset: {len(dataset)}”) # print a couple of samples n = 5 whereas n > 0: idx = random.randint(0, len(dataset)–1) textual content = dataset[idx][“text”].strip() if textual content and not textual content.startswith(“=”): print(f“{idx}: {textual content}”) n -= 1 |
The output might seem like this:
|
Measurement of the dataset: 36718 31776: The Missouri ‘s headwaters above Three Forks lengthen a lot farther upstream than … 29504: Regional variants of the phrase Allah happen in each pagan and Christian pre @-@ … 19866: Pokiri ( English : Rogue ) is a 2006 Indian Telugu @-@ language motion movie , … 27397: The primary flour mill in Minnesota was inbuilt 1823 at Fort Snelling as a … 10523: The music trade took notice of Carey ‘s success . She received two awards on the … |
When you haven’t already, set up the Hugging Face datasets library:
Whenever you run this code for the primary time, load_dataset() downloads the dataset to your native machine. Guarantee you’ve sufficient disk house, particularly for big datasets. By default, datasets are downloaded to ~/.cache/huggingface/datasets.
All Hugging Face datasets observe a typical format. The dataset object is an iterable, with every merchandise as a dictionary. For language mannequin coaching, datasets sometimes comprise textual content strings. On this dataset, textual content is saved below the "textual content" key.
The code above samples a couple of components from the dataset. You’ll see plain textual content strings of various lengths.
Submit-Processing the Datasets
Earlier than coaching a language mannequin, you could wish to post-process the dataset to wash the info. This consists of reformatting textual content (clipping lengthy strings, changing a number of areas with single areas), eradicating non-language content material (HTML tags, symbols), and eradicating undesirable characters (further areas round punctuation). The particular processing depends upon the dataset and the way you wish to current textual content to the mannequin.
For instance, if coaching a small BERT-style mannequin that handles solely lowercase letters, you’ll be able to cut back vocabulary dimension and simplify the tokenizer. Right here’s a generator operate that gives post-processed textual content:
|
def wikitext2_dataset(): dataset = load_dataset(“wikitext”, “wikitext-2-raw-v1”) for merchandise in dataset: textual content = merchandise[“text”].strip() if not textual content or textual content.startswith(“=”): proceed # skip the empty traces or header traces yield textual content.decrease() # generate lowercase model of the textual content |
Creating a superb post-processing operate is an artwork. It ought to enhance the dataset’s signal-to-noise ratio to assist the mannequin be taught higher, whereas preserving the flexibility to deal with sudden enter codecs {that a} skilled mannequin might encounter.
Additional Readings
Under are some sources that you could be discover them helpful:
Abstract
On this article, you discovered about datasets used to coach language fashions and find out how to supply frequent datasets from public repositories. That is simply a place to begin for dataset exploration. Contemplate leveraging present libraries and instruments to optimize dataset loading velocity so it doesn’t turn out to be a bottleneck in your coaching course of.
A language mannequin is a mathematical mannequin that describes a human language as a likelihood distribution over its vocabulary. To coach a deep studying community to mannequin a language, you have to determine the vocabulary and be taught its likelihood distribution. You possibly can’t create the mannequin from nothing. You want a dataset in your mannequin to be taught from.
On this article, you’ll study datasets used to coach language fashions and find out how to supply frequent datasets from public repositories.
Let’s get began.
Datasets for Coaching a Language Mannequin
Picture by Dan V. Some rights reserved.
A Good Dataset for Coaching a Language Mannequin
A great language mannequin ought to be taught right language utilization, freed from biases and errors. In contrast to programming languages, human languages lack formal grammar and syntax. They evolve repeatedly, making it not possible to catalog all language variations. Due to this fact, the mannequin must be skilled from a dataset as a substitute of crafted from guidelines.
Organising a dataset for language modeling is difficult. You want a big, various dataset that represents the language’s nuances. On the similar time, it have to be prime quality, presenting right language utilization. Ideally, the dataset must be manually edited and cleaned to take away noise like typos, grammatical errors, and non-language content material similar to symbols or HTML tags.
Creating such a dataset from scratch is dear, however a number of high-quality datasets are freely accessible. Widespread datasets embody:
- Widespread Crawl. A large, repeatedly up to date dataset of over 9.5 petabytes with various content material. It’s utilized by main fashions together with GPT-3, Llama, and T5. Nonetheless, because it’s sourced from the online, it accommodates low-quality and duplicate content material, together with biases and offensive materials. Rigorous cleansing and filtering are required to make it helpful.
- C4 (Colossal Clear Crawled Corpus). A 750GB dataset scraped from the online. In contrast to Widespread Crawl, this dataset is pre-cleaned and filtered, making it simpler to make use of. Nonetheless, count on potential biases and errors. The T5 mannequin was skilled on this dataset.
- Wikipedia. English content material alone is round 19GB. It’s large but manageable. It’s well-curated, structured, and edited to Wikipedia requirements. Whereas it covers a broad vary of common data with excessive factual accuracy, its encyclopedic type and tone are very particular. Coaching on this dataset alone might trigger fashions to overfit to this type.
- WikiText. A dataset derived from verified good and featured Wikipedia articles. Two variations exist: WikiText-2 (2 million phrases from tons of of articles) and WikiText-103 (100 million phrases from 28,000 articles).
- BookCorpus. A couple of-GB dataset of long-form, content-rich, high-quality ebook texts. Helpful for studying coherent storytelling and long-range dependencies. Nonetheless, it has recognized copyright points and social biases.
- The Pile. An 825GB curated dataset from a number of sources, together with BookCorpus. It mixes completely different textual content genres (books, articles, supply code, and tutorial papers), offering broad topical protection designed for multidisciplinary reasoning. Nonetheless, this range leads to variable high quality, duplicate content material, and inconsistent writing kinds.
Getting the Datasets
You possibly can seek for these datasets on-line and obtain them as compressed information. Nonetheless, you’ll want to grasp every dataset’s format and write customized code to learn them.
Alternatively, seek for datasets within the Hugging Face repository at https://huggingface.co/datasets. This repository supplies a Python library that allows you to obtain and browse datasets in actual time utilizing a standardized format.
Hugging Face Datasets Repository
Let’s obtain the WikiText-2 dataset from Hugging Face, one of many smallest datasets appropriate for constructing a language mannequin:
|
import random from datasets import load_dataset
dataset = load_dataset(“wikitext”, “wikitext-2-raw-v1”) print(f“Measurement of the dataset: {len(dataset)}”) # print a couple of samples n = 5 whereas n > 0: idx = random.randint(0, len(dataset)–1) textual content = dataset[idx][“text”].strip() if textual content and not textual content.startswith(“=”): print(f“{idx}: {textual content}”) n -= 1 |
The output might seem like this:
|
Measurement of the dataset: 36718 31776: The Missouri ‘s headwaters above Three Forks lengthen a lot farther upstream than … 29504: Regional variants of the phrase Allah happen in each pagan and Christian pre @-@ … 19866: Pokiri ( English : Rogue ) is a 2006 Indian Telugu @-@ language motion movie , … 27397: The primary flour mill in Minnesota was inbuilt 1823 at Fort Snelling as a … 10523: The music trade took notice of Carey ‘s success . She received two awards on the … |
When you haven’t already, set up the Hugging Face datasets library:
Whenever you run this code for the primary time, load_dataset() downloads the dataset to your native machine. Guarantee you’ve sufficient disk house, particularly for big datasets. By default, datasets are downloaded to ~/.cache/huggingface/datasets.
All Hugging Face datasets observe a typical format. The dataset object is an iterable, with every merchandise as a dictionary. For language mannequin coaching, datasets sometimes comprise textual content strings. On this dataset, textual content is saved below the "textual content" key.
The code above samples a couple of components from the dataset. You’ll see plain textual content strings of various lengths.
Submit-Processing the Datasets
Earlier than coaching a language mannequin, you could wish to post-process the dataset to wash the info. This consists of reformatting textual content (clipping lengthy strings, changing a number of areas with single areas), eradicating non-language content material (HTML tags, symbols), and eradicating undesirable characters (further areas round punctuation). The particular processing depends upon the dataset and the way you wish to current textual content to the mannequin.
For instance, if coaching a small BERT-style mannequin that handles solely lowercase letters, you’ll be able to cut back vocabulary dimension and simplify the tokenizer. Right here’s a generator operate that gives post-processed textual content:
|
def wikitext2_dataset(): dataset = load_dataset(“wikitext”, “wikitext-2-raw-v1”) for merchandise in dataset: textual content = merchandise[“text”].strip() if not textual content or textual content.startswith(“=”): proceed # skip the empty traces or header traces yield textual content.decrease() # generate lowercase model of the textual content |
Creating a superb post-processing operate is an artwork. It ought to enhance the dataset’s signal-to-noise ratio to assist the mannequin be taught higher, whereas preserving the flexibility to deal with sudden enter codecs {that a} skilled mannequin might encounter.
Additional Readings
Under are some sources that you could be discover them helpful:
Abstract
On this article, you discovered about datasets used to coach language fashions and find out how to supply frequent datasets from public repositories. That is simply a place to begin for dataset exploration. Contemplate leveraging present libraries and instruments to optimize dataset loading velocity so it doesn’t turn out to be a bottleneck in your coaching course of.
















{kind=link}