


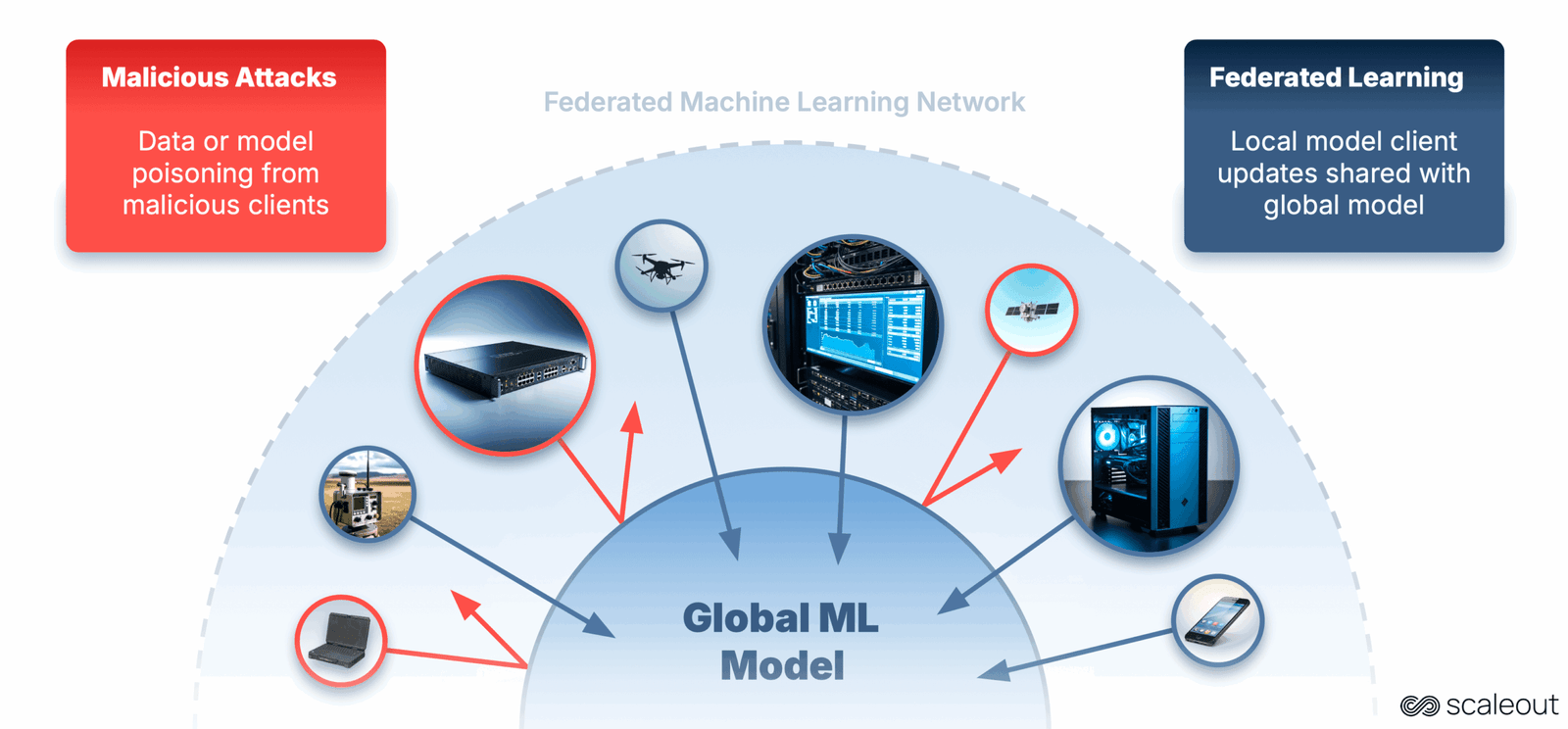
Federated Studying (FL) is we prepare AI fashions. As a substitute of sending all of your delicate knowledge to a central location, FL retains the info the place it’s, and solely shares mannequin updates. This preserves privateness and permits AI to run nearer to the place the info is generated.
Nevertheless, with computation and knowledge unfold throughout many units, new safety challenges come up. Attackers can be part of the coaching course of and subtly affect it, resulting in degraded accuracy, biased outputs or hidden backdoors within the mannequin.
On this undertaking, we got down to examine how we are able to detect and mitigate such assaults in FL. To do that, we constructed a multi node simulator that allows researchers and trade professionals to breed assaults and check defences extra effectively.
Why This Issues
- A non-technical Instance: Consider a shared recipe guide that cooks from many eating places contribute to. Every chef updates just a few recipes with their very own enhancements. A dishonest chef might intentionally add the mistaken substances to sabotage the dish, or quietly insert a particular flavour that solely they know how one can repair. If nobody checks the recipes fastidiously, all future diners throughout all eating places might find yourself with ruined or manipulated meals.
- A Technical Instance: The identical idea seems in FL as knowledge poisoning (manipulating coaching examples) and mannequin poisoning (altering weight updates). These assaults are particularly damaging when the federation has non IID knowledge distributions, imbalanced knowledge partitions or late becoming a member of shoppers. Up to date defences akin to Multi KRUM, Trimmed Imply and Divide and Conquer can nonetheless fail in sure situations.
Constructing the Multi Node FL Assault Simulator
To judge the resilience of federated studying in opposition to real-world threats, we constructed a multi-node assault simulator on prime of the Scaleout Techniques FEDn framework. This simulator makes it doable to breed assaults, check defences, and scale experiments with tons of and even 1000’s of shoppers in a managed surroundings.
Key capabilities:
- Versatile deployment: runs distributed FL jobs utilizing Kubernetes, Helm and Docker.
- Real looking knowledge settings: Helps IID/non-IID label distributions, imbalanced knowledge partitions and late becoming a member of shoppers.
- Assault injection: Consists of implementation of frequent poisoning assaults (Label Flipping, Little is Sufficient) and permits new assaults to be outlined with ease.
- Protection benchmarking: Integrates current aggregation methods (FedAvg, Trimmed Imply, Multi-KRUM, Divide and Conquer) and permits for experimentation and testing of a variety of defensive methods and aggregation guidelines.
- Scalable experimentation: Simulation parameters akin to variety of shoppers, malicious share and participation patterns may be tuned from one single configuration file.
Utilizing FEDn’s structure signifies that the simulations profit from the strong coaching orchestration, consumer administration and permits visible monitoring via the Studio internet interface.
It’s also necessary to notice that the FEDn framework helps Server Capabilities. This characteristic makes it doable to implement new aggregation methods and consider them utilizing the assault simulator.
To start out with the primary instance undertaking utilizing FEDn, right here is the quickstart information.
The FEDn framework is free for all educational and analysis tasks, in addition to for industrial testing and trials.
The assault simulator is obtainable and able to use as an open supply software program.
The Assaults We Studied
- Label Flipping (Information Poisoning) – Malicious shoppers flip labels of their native datasets, akin to altering “cat” to “canine” to scale back accuracy.
- Little is Sufficient (Mannequin Poisoning) – Attackers make small however focused changes to their mannequin updates to shift the worldwide mannequin output towards their very own objectives. On this thesis we utilized the Little is Sufficient assault each third spherical.
Past Assaults — Understanding Unintentional Affect
Whereas this examine focuses on deliberate assaults, it’s equally worthwhile for understanding the consequences of marginal contributions attributable to misconfigurations or system malfunctions in large-scale federations.
In our recipe instance, even an trustworthy chef may unintentionally use the mistaken ingredient as a result of their oven is damaged or their scale is inaccurate. The error is unintentional, however it nonetheless modifications the shared recipe in ways in which might be dangerous if repeated by many contributors.
In cross-device or fleet studying setups, the place 1000’s or tens of millions of heterogeneous units contribute to a shared mannequin, defective sensors, outdated configurations or unstable connections can degrade mannequin efficiency in comparable methods to malicious assaults. Finding out assault resilience additionally reveals how one can make aggregation guidelines strong to such unintentional noise.
Mitigation Methods Defined
In FL, aggregation guidelines determine how one can mix mannequin updates from shoppers. Strong aggregation guidelines goal to scale back the affect of outliers, whether or not attributable to malicious assaults or defective units. Listed below are the methods we examined:
- FedAvg (baseline) – Merely averages all updates with out filtering. Very weak to assaults.
- Trimmed Imply (TrMean) – Kinds every parameter throughout shoppers, then discards the very best and lowest values earlier than averaging. Reduces excessive outliers however can miss refined assaults.
- Multi KRUM – Scores every replace by how shut it’s to its nearest neighbours in parameter house, protecting solely these with the smallest complete distance. Very delicate to the variety of updates chosen (ok).
- EE Trimmed Imply (Newly developed) – An adaptive model of TrMean that makes use of epsilon–grasping scheduling to determine when to check totally different consumer subsets. Extra resilient to altering consumer behaviour, late arrivals and non IID distributions.
tables and plots introduced on this put up have been initially designed by the Scaleout crew.
Experiments
Throughout 180 experiments we evaluated totally different aggregation methods below various assault varieties, malicious consumer ratios and knowledge distributions. For additional particulars, please learn the full thesis right here .

The desk above reveals one of many collection of experiments utilizing label-flipping assault with non-IID label distributed and partially imbalanced knowledge partitions. The desk reveals Take a look at Accuracy and Take a look at Loss AUC, computed over all collaborating shoppers. Every aggregation technique’s outcomes are proven in two rows, comparable to the 2 late-policies (benign shoppers collaborating from the fifth spherical or malicious shoppers collaborating from the fifth spherical). Columns separate the outcomes on the three malicious proportions, yielding six experiment configurations per aggregation technique. The most effective lead to every configuration is proven in daring.
Whereas the desk reveals a comparatively homogeneous response throughout all protection methods, the person plots current a very totally different view. In FL, though a federation might attain a sure degree of accuracy, it’s equally necessary to look at consumer participation—particularly, which shoppers efficiently contributed to the coaching and which have been rejected as malicious. The next plots illustrate consumer participation below totally different protection methods.

With 20% malicious shoppers below a label-flipping assault on non-IID, partially imbalanced knowledge, Trimmed Imply (Fig-1) maintained general accuracy however by no means totally blocked any consumer from contributing. Whereas coordinate trimming decreased the influence of malicious updates, it filtered parameters individually fairly than excluding whole shoppers, permitting each benign and malicious individuals to stay within the aggregation all through coaching.
In a situation with 30% late-joining malicious shoppers and non-IID , imbalanced knowledge, Multi-KRUM (Fig-2) mistakenly chosen a malicious replace from spherical 5 onward. Excessive knowledge heterogeneity made benign updates seem much less comparable, permitting the malicious replace to rank as probably the most central and persist in one-third of the aggregated mannequin for the remainder of coaching.

Why we want adaptive aggregation methods
Present strong aggregation guidelines, typically depend on static thresholds to determine which consumer replace to incorporate in aggregating the brand new world mannequin. This highlights a shortcoming of present aggregation methods, which might make them weak to late collaborating shoppers, non-IID knowledge distributions or knowledge quantity imbalances between shoppers. These insights led us to develop EE-Trimmed Imply (EE-TrMean).
EE-TrMean: An epsilon grasping aggregation technique
EE-TrMean construct on the classical Trimmed Imply, however provides an exploration vs. exploitation, epsilon grasping layer for consumer choice.
- Exploration section: All shoppers are allowed to contribute and a traditional Trimmed Imply aggregation spherical is executed.
- Exploitation section: The shoppers which were trimmed the least will likely be included into the exploitation section, via a mean rating system based mostly on earlier rounds it participated.
- The swap between the 2 phases is managed by the epsilon-greedy coverage with a decaying epsilon and an alpha ramp.
Every consumer earns a rating based mostly on whether or not its parameters survive trimming in every spherical. Over time the algorithm will more and more favor the very best scoring shoppers, whereas sometimes exploring others to detect modifications in behaviour. This adaptive strategy permits EE-TrMean to extend resilience in circumstances the place the info heterogeneity and malicious exercise is excessive.

In a label-flipping situation with 20% malicious shoppers and late benign joiners on non-IID, partially imbalanced knowledge, EE-TrMean (Fig-3) alternated between exploration and exploitation phases—initially permitting all shoppers, then selectively blocking low-scoring ones. Whereas it sometimes excluded a benign consumer as a consequence of knowledge heterogeneity (nonetheless significantly better than the identified methods), it efficiently recognized and minimized the contributions of malicious shoppers throughout coaching. This easy but highly effective modification improves the consumer’s contributions. The literature stories that so long as the vast majority of shoppers are trustworthy, the mannequin’s accuracy stays dependable.

















{kind=link}